视频链接:https://www.youtube.com/watch?v=dymfkWtVUdo&list=PLJV_el3uVTsO07RpBYFsXg-bN5Lu0nhdG&index=8&ab_channel=Hung-yiLee
课件链接:https://speech.ee.ntu.edu.tw/~tlkagk/courses/DLHLP20/ASR3.pdf
1. Language Model
LM的作用是预测token sequence出现的概率。对于输出文本的模型,LM通常都是很有帮助的。

N-gram LM 有smooth的问题,然后,引出Continuous LM,再进一步扩展到Deep Learning based LM.
2. N-gram LM
传统的LM是N-gram LM,下面介绍一下N-gram LM的技术细节。
2.1 N-gram细节
常见的N-gram有2-gram,3-gram,。。。

2.2 N-gram LM的局限
局限是什么?估计的概率可能并不准确。
- N越大,问题越明显;
- 在训练集中,n-grams并没有出现。

如何解决?使用的技术叫做language model smoothing
3. Continuous LM
在Deep Learning技术出现之前,使用的方法叫continuous LM,这是一个源于推荐系统的技术。
在推荐系统中,使用Matrix Factorization的技术,为用户进行推荐。如下图的B用户,推荐蓝色框的内容。

借助上面说的Matrix Factorzation技术,就可以引出Continuous LM的设计思路了。
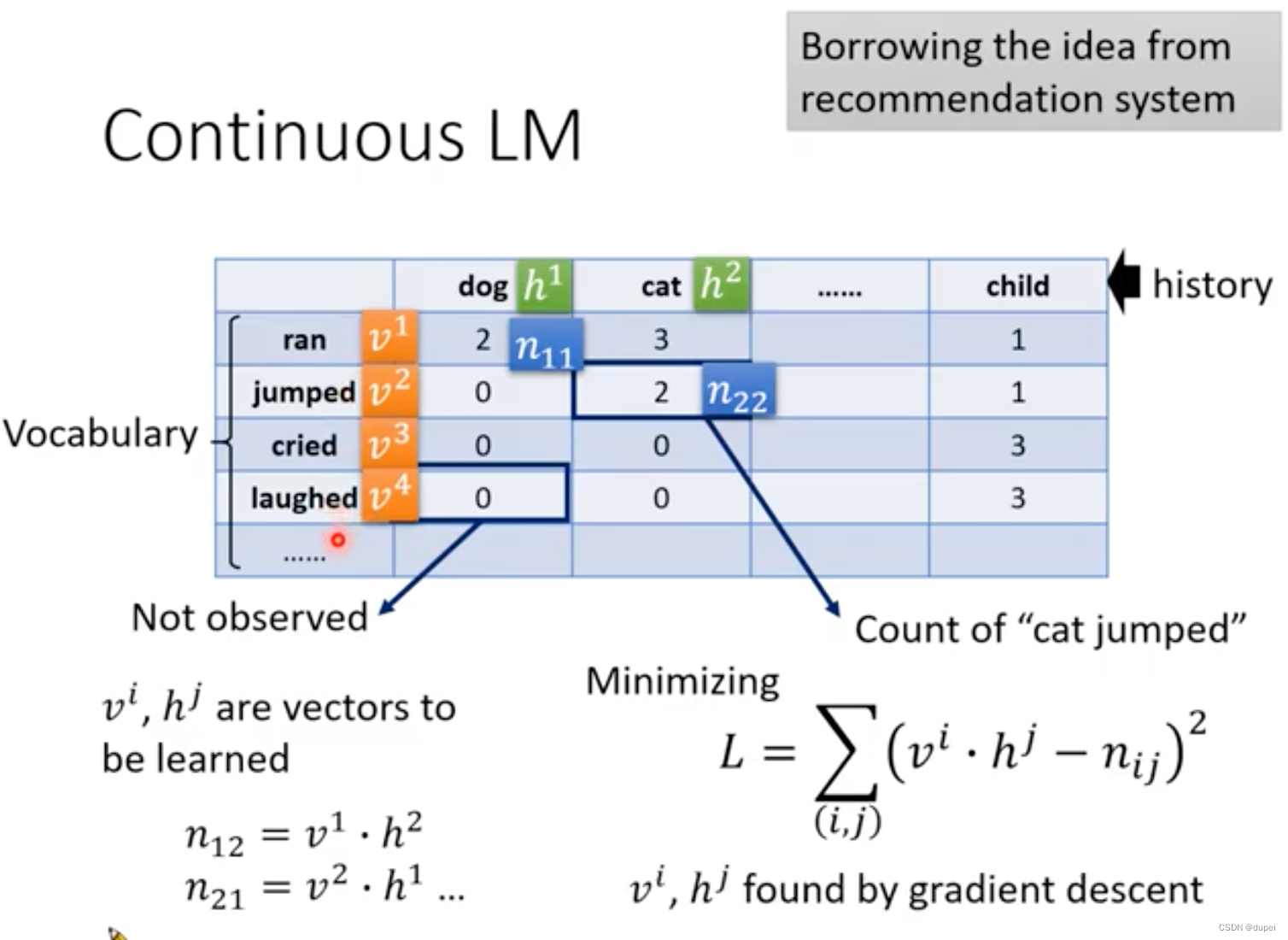
下图中表格里的纵轴和横轴都是词典里所有的词汇,每个词汇是需要用一个向量表示,这个向量是需要在后面学习出来的。表格中的值是根据收集到的文章进行的统计值,其中,0是没有出现的组合。
假设
n
i
j
=
v
i
.
h
j
n_{ij}=v^i.h^j
nij=vi.hj,那么,我们需要做的就是最小化下面这个损失函数。
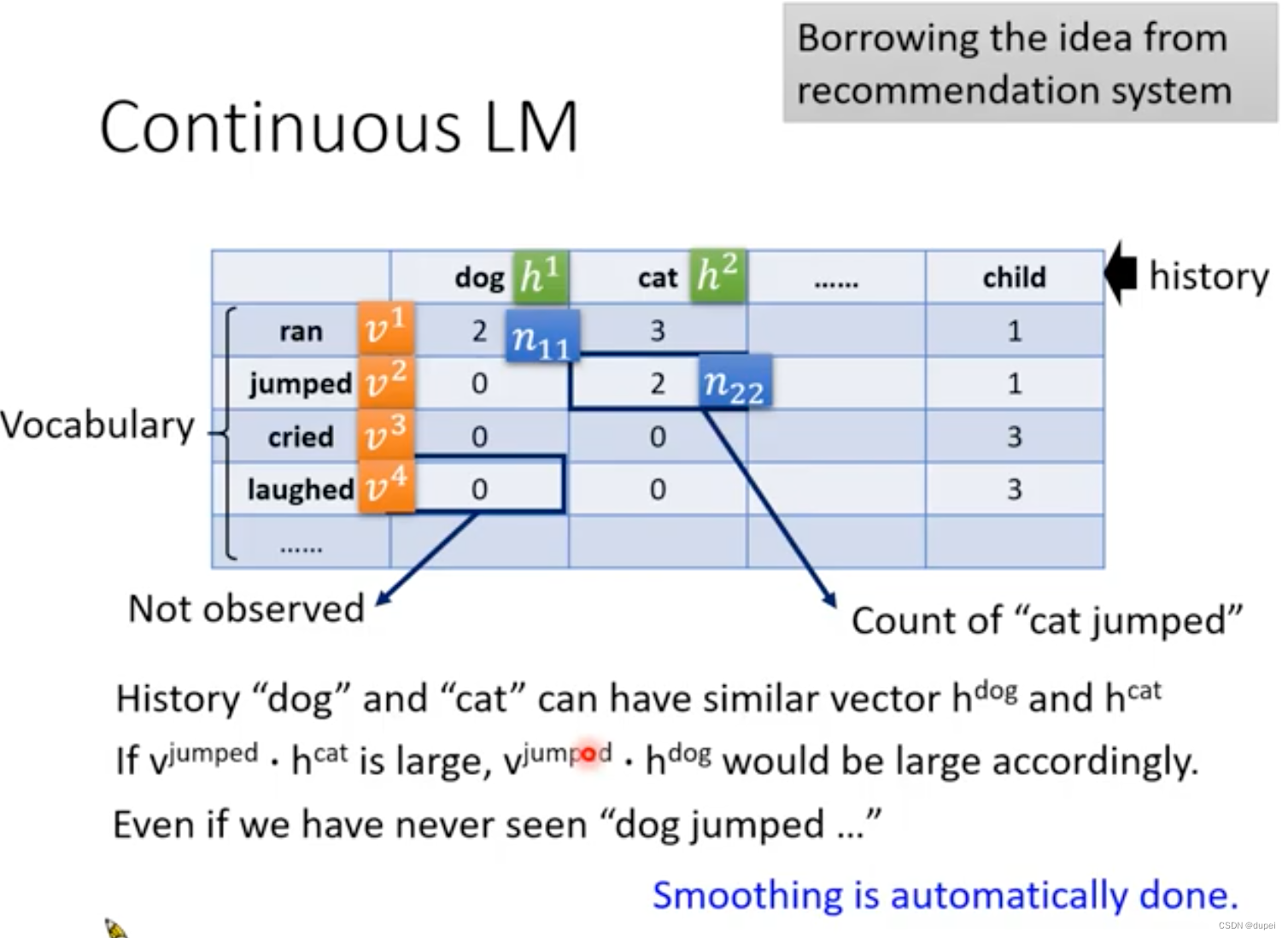
在使用的过程中,假设"dog"和"cat"的vector学习以后比较相近,那么,即使"dog jumped"从来没有见过,也可以通过vector计算出一个非0的值。
下面从另外一个视角看一下Continuous LM的样子,可以将Continuous LM看做是只有一个hidden layer的NN,如下:
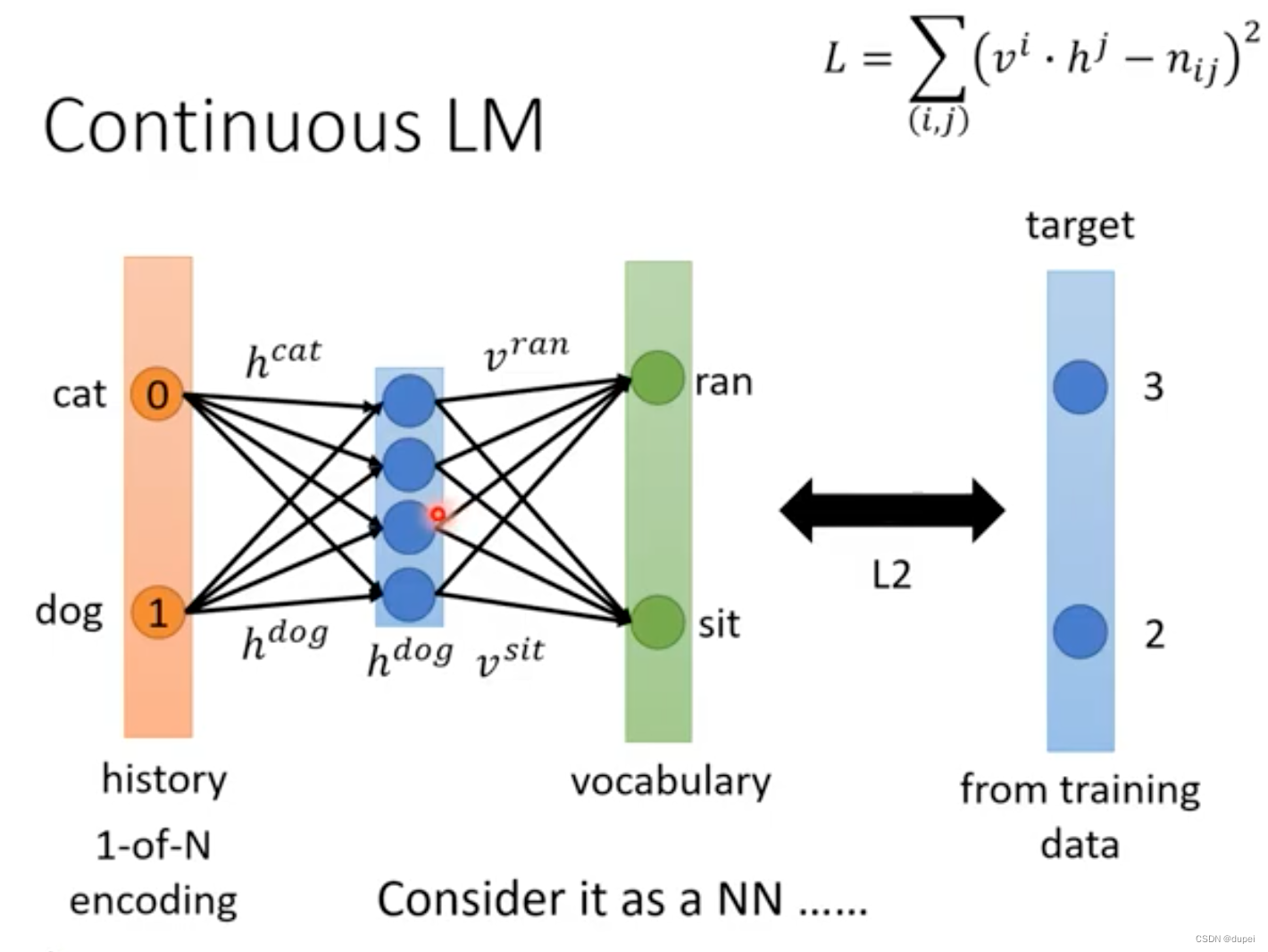
这样,就可以很自然地想到可以使用更深层的NN来构建LM。
4. NN-based LM
NN-based LM最初是用于解决N-gram的问题,用于预测下一个word输出的概率。
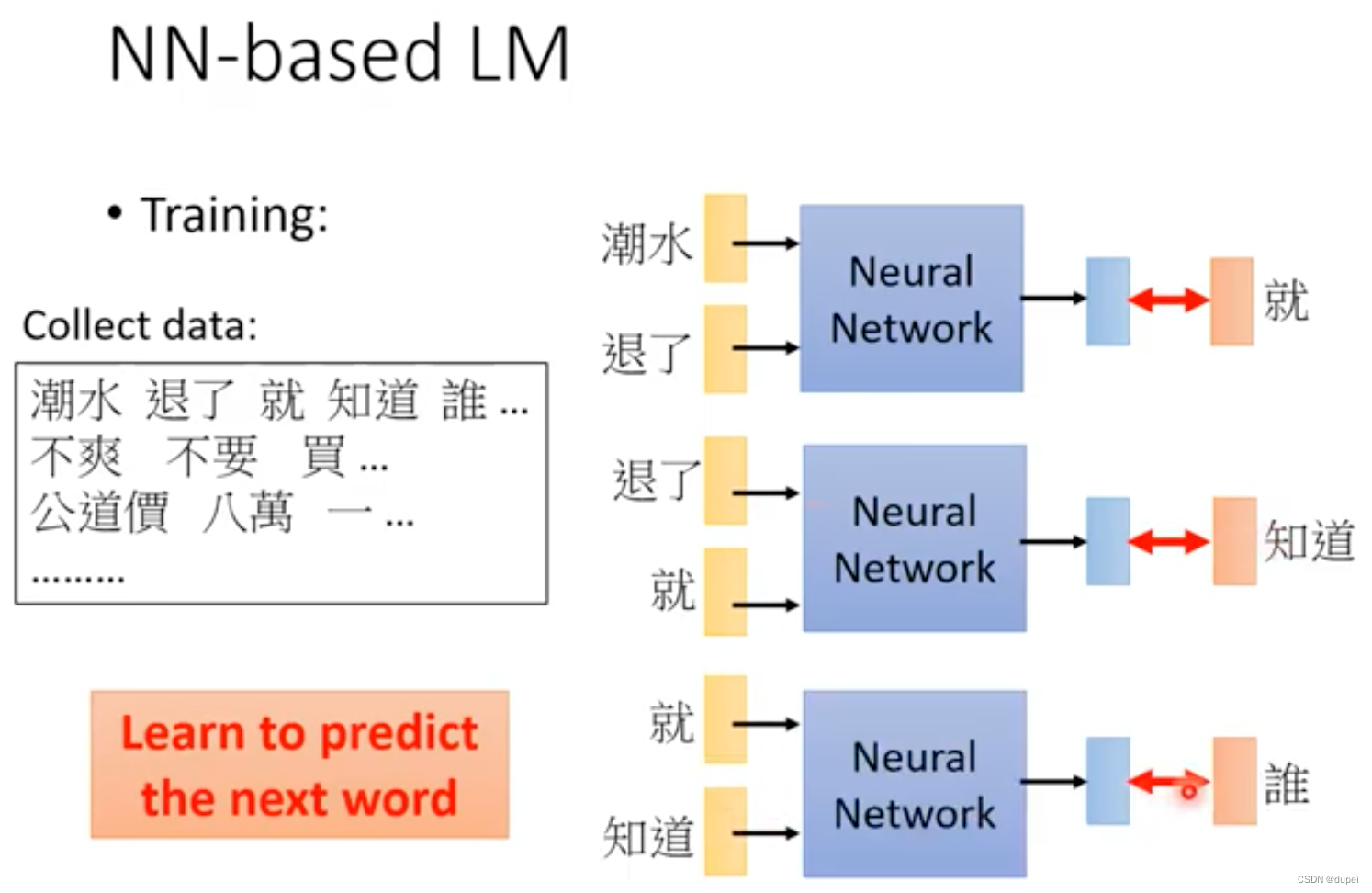
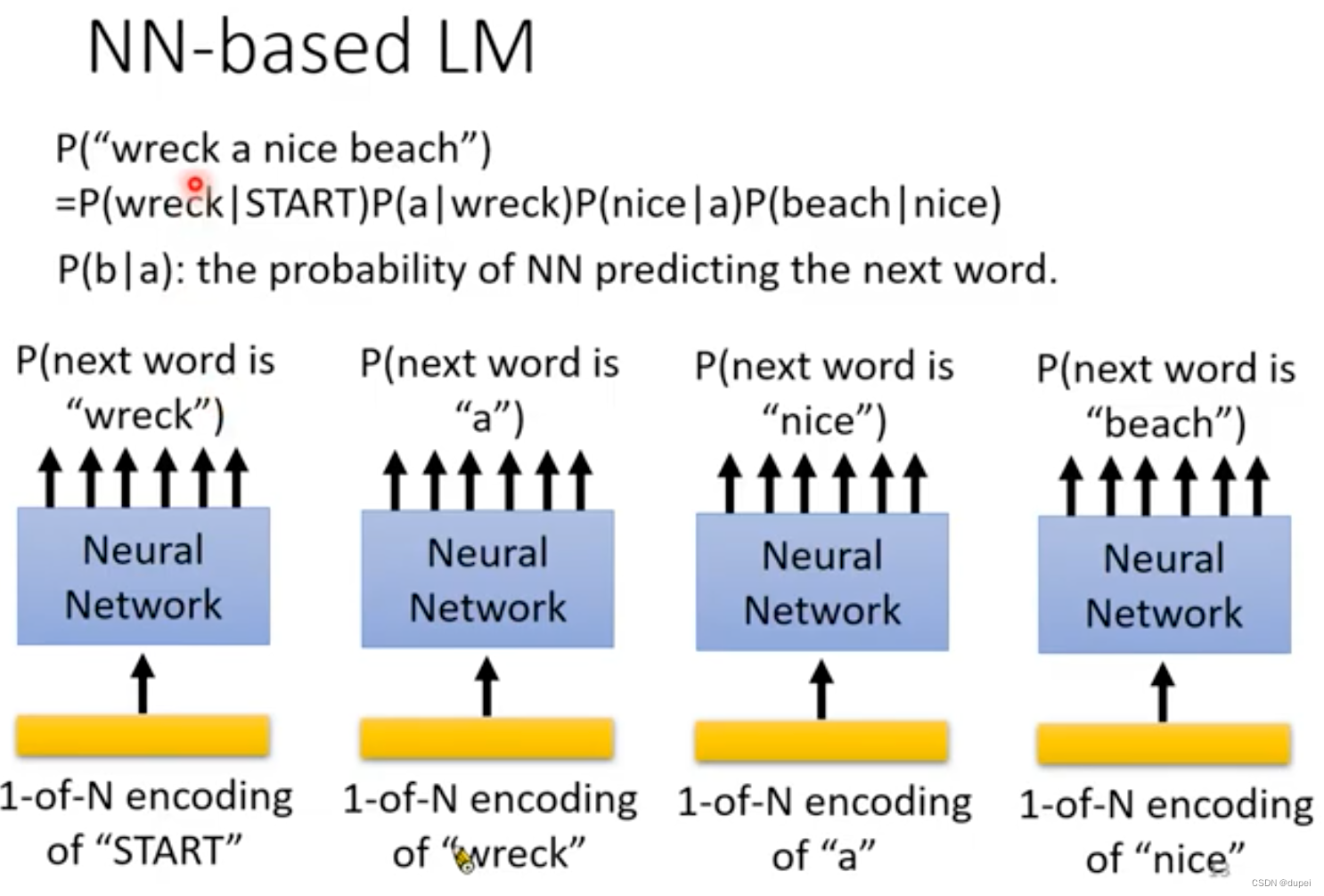
为了使用很多的word作为前置词汇,来预测后续出现词汇的概率,这里,就引入了RNN-based LM。这种能力是N-gram无法企及的!
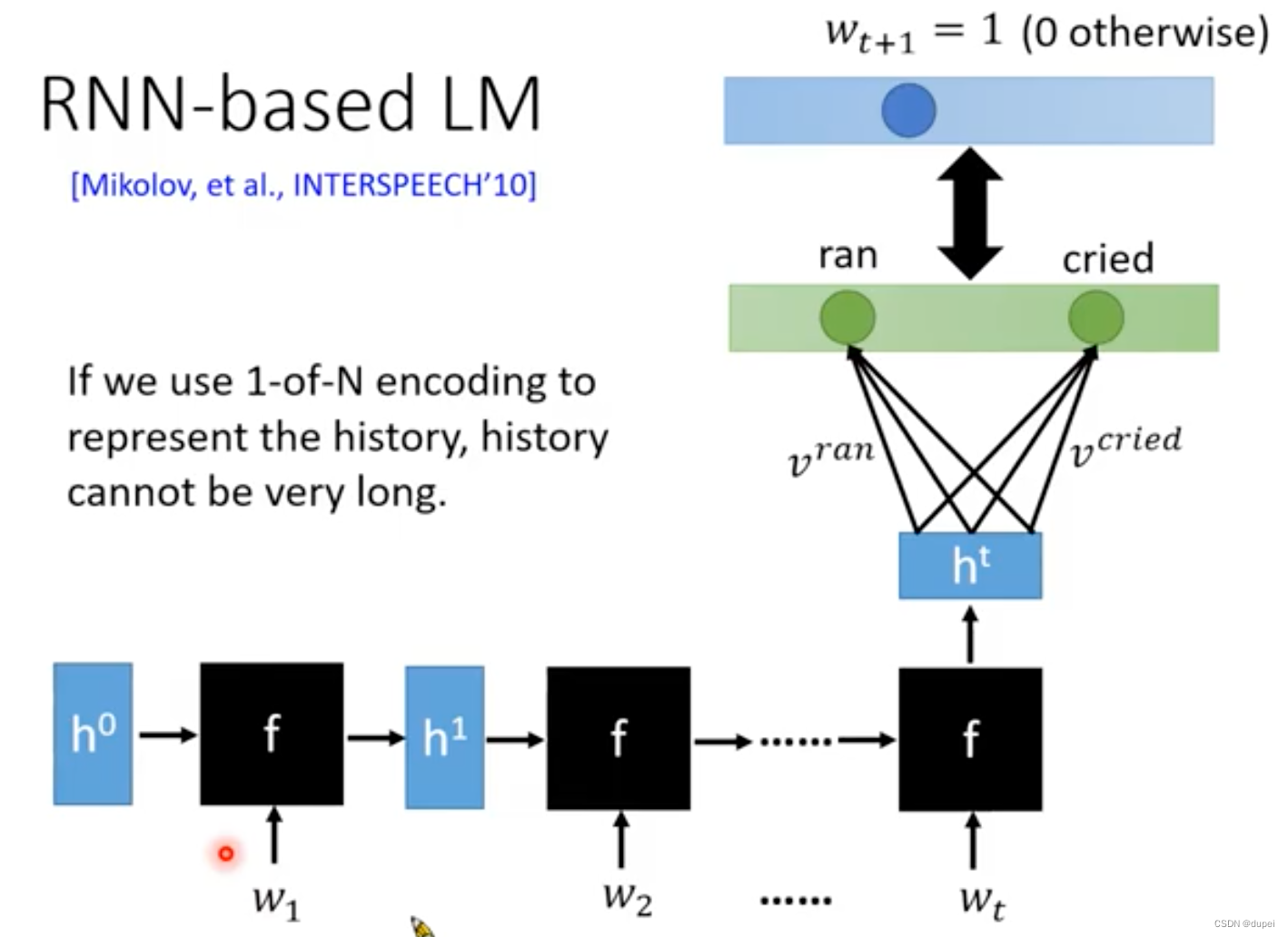
RNN-based LM可以很复杂,但是,研究表明:只需要使用LSTM,再配上合适的optimization和regularization,就可以得到很好的结果了。
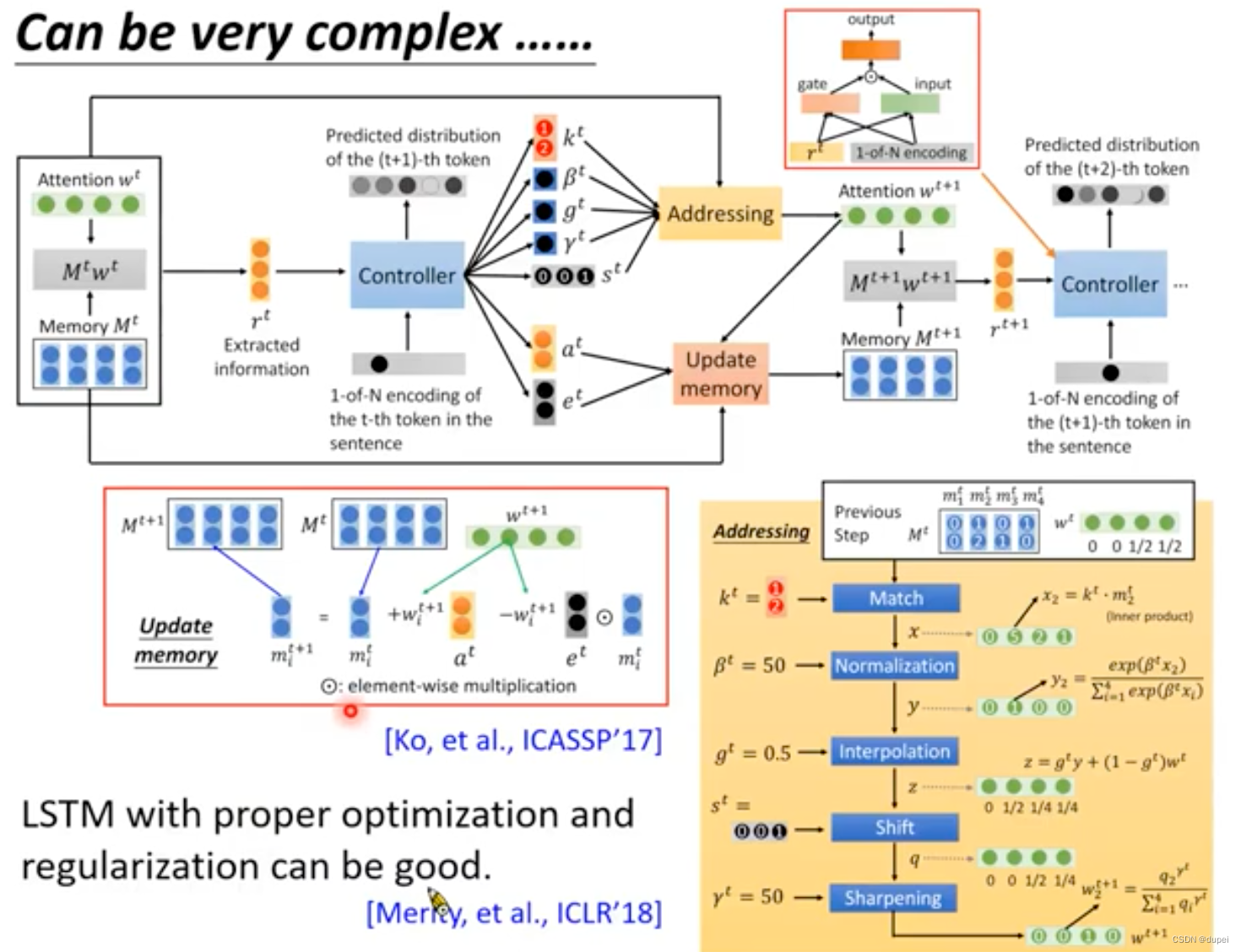
5. 如何使用LM提升语音识别?
这里以LAS为例,简单介绍一下常见的几种结合方式:

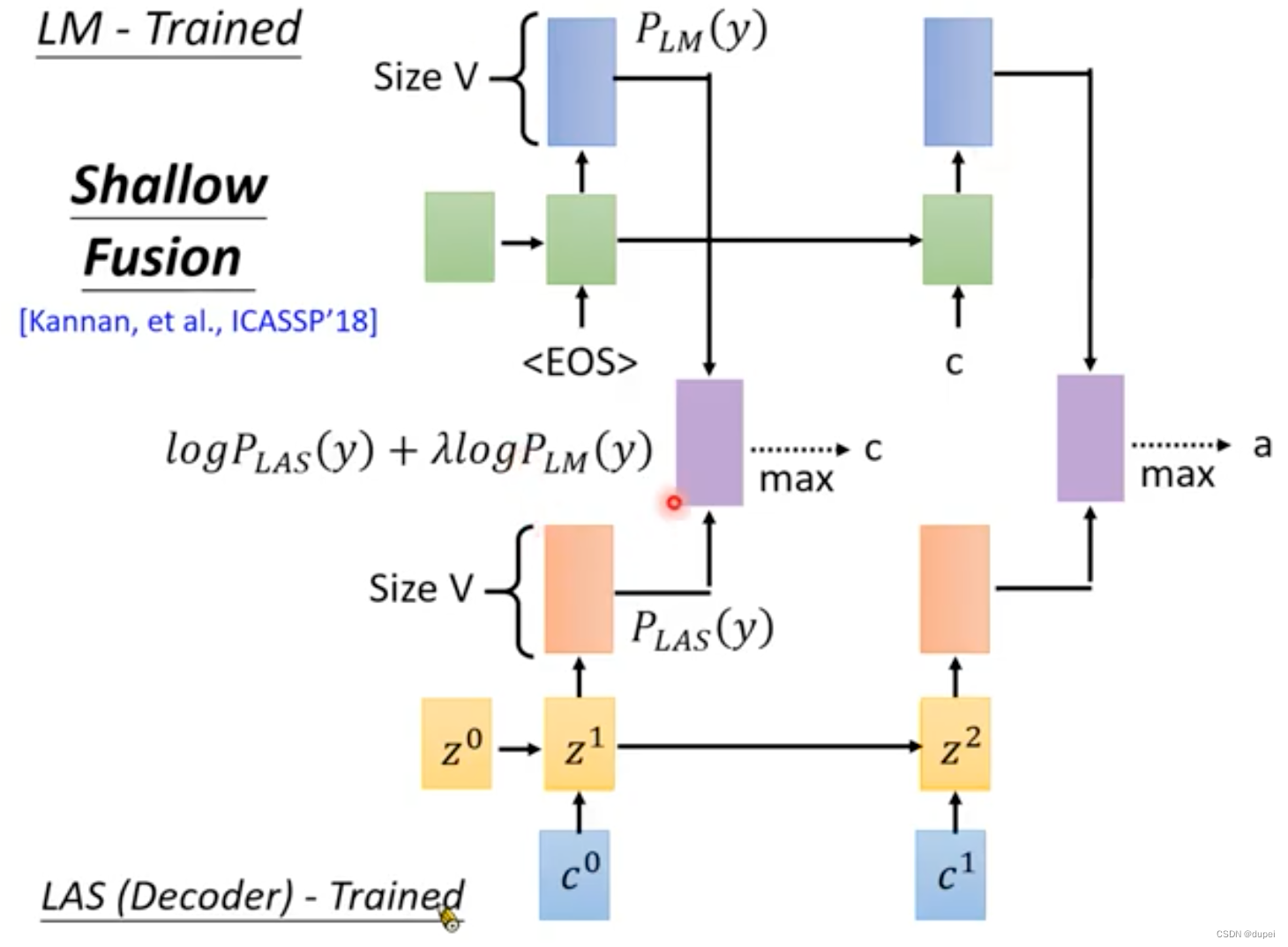
5.1 Shallow Fusion
Shallow Fusion是将已经训练好的LM和LAS Decoder放在一起使用,将两者的输出整合起来。
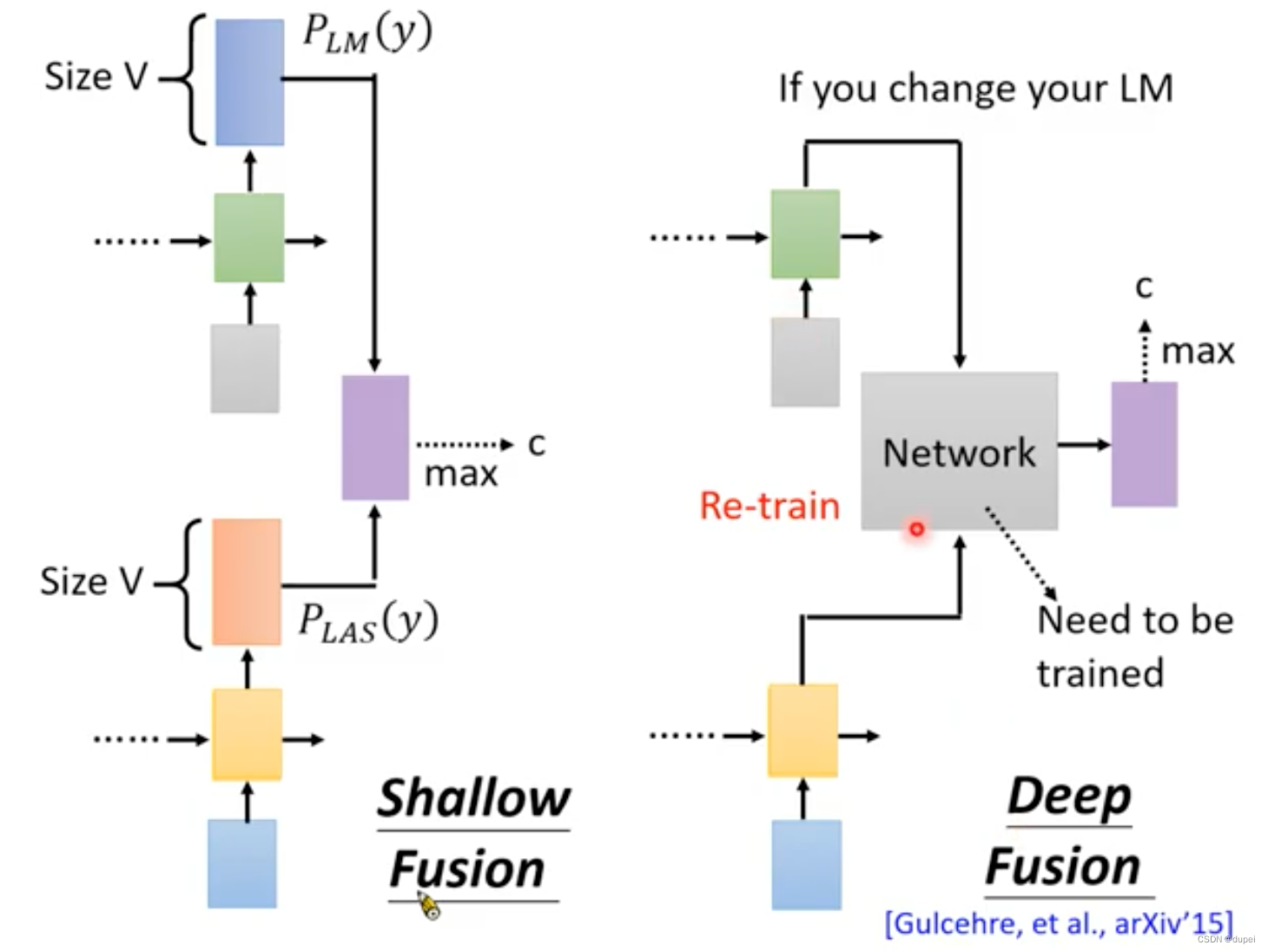
5.2 Deep Fusion
Deep Fusion是将LAS的输出和LM的输出,作为一个新network的输入,来训练这个network,可以视为使用Network代替上述的整合公式。
这种方式存在一个问题:Network训练好以后,对应的LM就不能随意更换了。
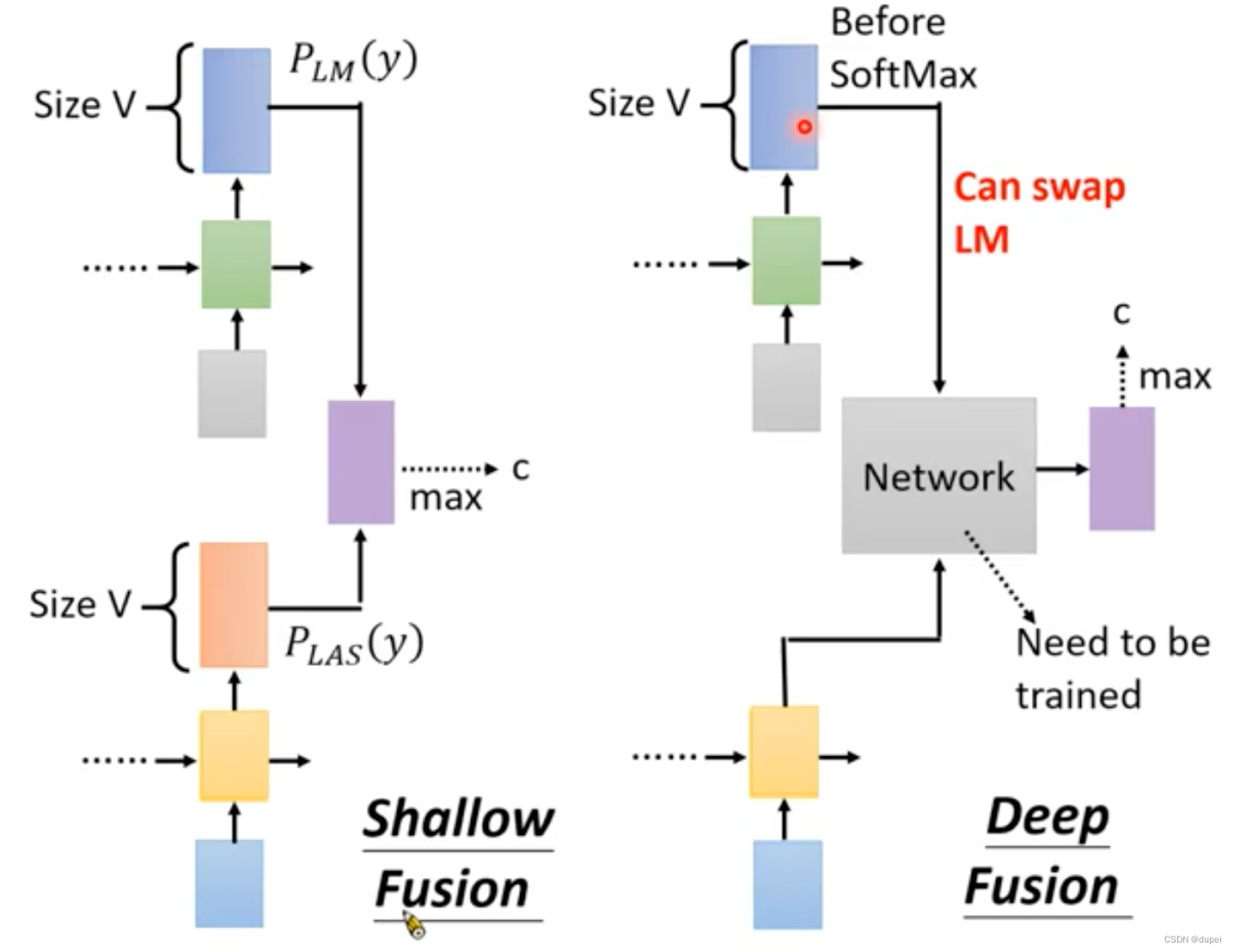
课程中,李宏毅老师说,使用下面的方式,可以解决上述的问题。
使用LM在softmax前的特征作为Network的输入,可以解决network重训练的问题,尚未理解。
5.3 Cold Fusion
Cold Fusion的思路是在训练LAS和Network时,使用已经训练好的LM。
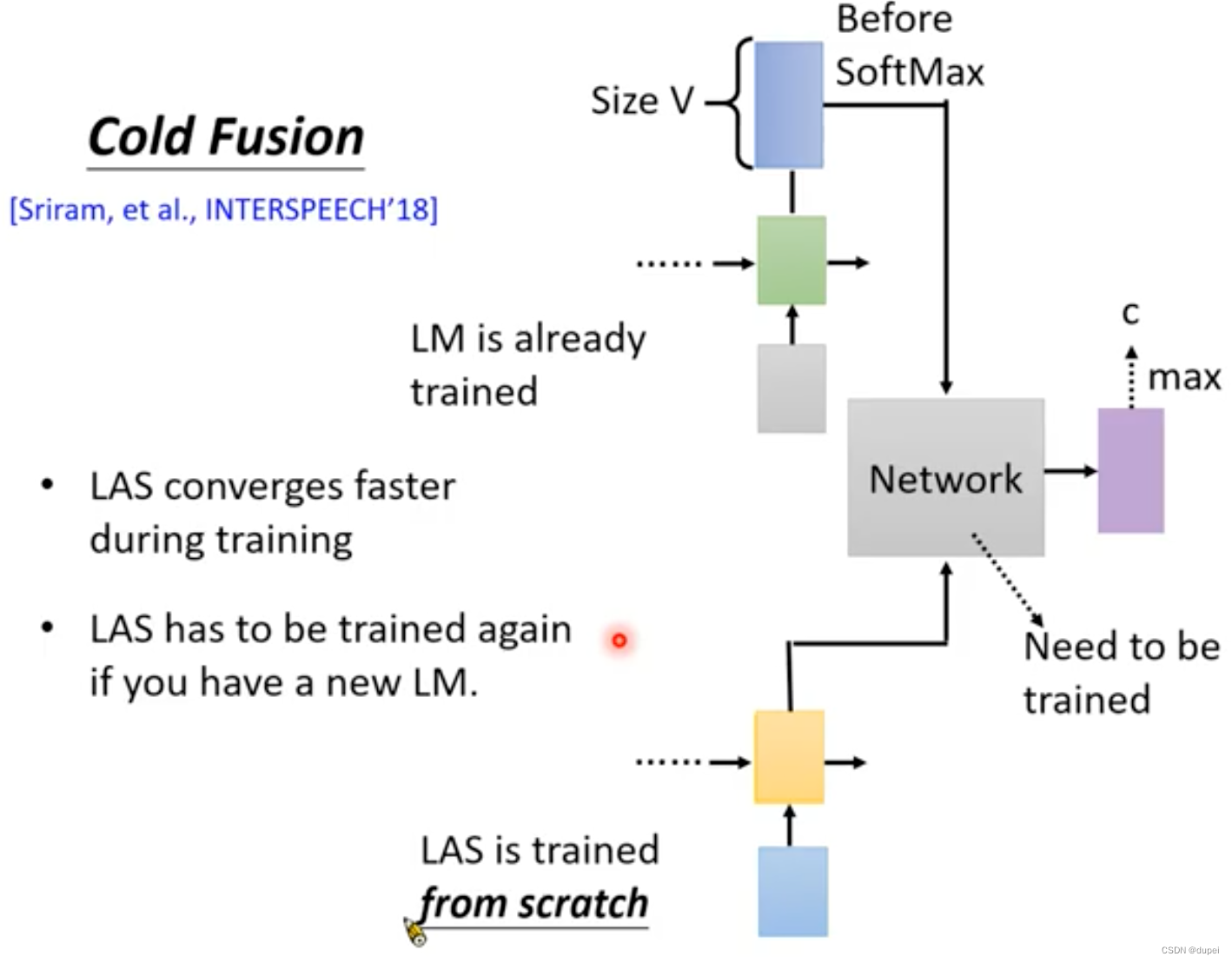
这种方式的好处是可以使LAS训练过程快速收敛。
但是,这样做的话,一点更换LM,整个LAS都需要重新训练。
![[附源码]Python计算机毕业设计Django基于Java的图书购物商城](https://img-blog.csdnimg.cn/75a75284f55246019277cdc82bd71054.png)









![[附源码]计算机毕业设计学生疫情防控信息填报系统Springboot程序](https://img-blog.csdnimg.cn/f826243a9bad4b7ea497fb04306e1586.png)