一、寄存器
1.1 通用寄存器
一个x86-64的中央处理单元(CPU)包含一组16个存储64位值的通用寄存器。这些寄存器用来存储整数数据和指针。下图显示了这16个寄存器。它们的名字都以%r开头,不过后面还跟着不同命名规则的名字,这是由于指令集历史演化造成的。最初的8086中有8个16位的寄存器,即图中的%ax到%bp。每个寄存器都有特殊的用途,它们的名字就反映了这些不同的用途。扩展到IA32架构时,这些寄存器也扩展成32位寄存器,标号从%eax到%ebp。扩招到x86-64后,原来的8个寄存器扩展成64位,标号从%rax到%rbp。除此之外,还增加了8个新的寄存器,它们的标号是按照新的命名规则制定的:从%r8到%r15。

如上图中嵌套的方框表明的,指令可以对这16个寄存器的低位字节中存放的不同大小的数据进行操作。字节级操作可以访问最低的字节,16位操作可以访问最低的2个字节,32位操作可以访问最低的4个字节,而64位操作可以访问整个寄存器。
Tips:当指令以寄存器作为目标时,对于生成小于8字节结果的指令,寄存器中剩下的字节如何处理,有两条规则:
- 生成1字节和2字节数字的指令会保持剩下的字节不变
- 生成4字节的指令会把高位4字节置为0。
后面这条规则是作为从IA32到x86-64的扩展的一部分而采用的。
1.2 标志寄存器EFLAFS
EFLAGS标志寄存器包含有状态标志位、控制标志位以及系统标志位,处理器在初始化时将EFLAGS标志寄存器赋值为00000002H。
下图描绘了EFLAGS标志寄存器各位的功能,其中的第1、3、5、15以及22~31位保留未使用。由于64位模式不再支持VM和NT标志位,所以处理器不应该再置位这两个标志位。

TIPs:在64位模式中,EFLAGS标志寄存器已从32位扩展为64位,被称作RFLAGS寄存器。其中高32位保留未使用,低32位与EFLAGS相同。
接下来,我们会根据标志位功能将EFLAGS划分位状态标志、方向标志、系统标志和IOPL区域等几部分,并对各部分的标志位功能进行逐一讲解。(请参考Intel官方白皮书Volumn 1的3.4.3节)。
1.2.1 状态标志
EFLAGS标志寄存器的状态标志(位0、2、4、6、7和11)可以反映出汇编指令计算结果的状态,像add、sub、mul、div等汇编指令计算结果的奇偶性、溢出状态、正负值皆可从上述状态找那个反映出来。
下表是这些状态标志的功能描述:
| 缩写 | 全称 | 名称 | 位置 | 描述 |
|---|---|---|---|---|
| CF | Carry Flag | 进位标志 | 0 | 运算中,当数值的最高位产生了进位或者借位,CF位都会置1,否则为0。它可用于检测无符号整数运算结果是否溢出。也可用于多精度运算中。 |
| PF | Parity Flag | 奇偶标志 | 2 | 用于标记结果低8位中1的个数,如果为偶数, PF位为1,否则为0 。注意,是最低的那8位,不管操作数是16位,还是32位。奇偶校验经常用于数据传输开始时和结束后的对比,判断传输过程中是否出现错误。 |
| AF | Auxiliary Carry Flag | 辅助进位标志 | 4 | 辅助进位标志,用来记录运算结果低4位的进、借位情况,即若低半字节有进、借位,AF为1,否则为0。 |
| ZF | Zero Flag | 零值标志 | 6 | 若计算结果为0,此标志位置1,否则为0。 |
| SF | Sign Flag | 符号标志 | 7 | 若运算结果为负,则SF位为1,否则为0。 |
| OF | Overflow Flag | 溢出标志 | 11 | 用来标识计算的结果是否超过了数据类型可以表示的范围,若OF为1,表示有溢出,为0则未溢出。专门用于检测有符号整数运算结果是否溢出。 |
这些标志位可反映出三种数据类型的计算结果:无符号整数、有符号整数和BCD整数(Binary-coded decimal integers)。其中CF标志位可反映出无符号整数运算结果的溢出状态;OF标志位可反映出有符号整数(补码表示)运算结果的溢出状态;AF标志位表示BCD整数运算结果的溢出状态;SF标志位反应出有符号整数运算结果的正负值;ZF标志位反映出有符号或无符号整数运算的结果是否为0。
以上这些标志位,只有CF标志位可通过stc、clc和cmc(Complement Carry Flag,计算原CF位的补码)汇编指令更改位值。它也可借助位操作指令(bt、bts、btr和btc指令)将指定位值复制到CF标志位。而且,CF标志位还可在多倍精度整数计算时,结合adc指令(含进位的加法计算)或sbb指令(含借位的减减法)将进位计算或借位计算扩展到下次计算中。
至于状态跳转指令Jcc、状态字节置位指令SETcc、状态循环指令LOOPcc以及状态移动指令CMOVcc,它们可将一个或多个状态标志位作为判断条件,进程分支跳转、字节置位以及循环计数。
1.2.2 方向标志
DF方向标志位(Direction Flag)位于EFLAGS标志寄存器的第 10 位,它控制着字符串指令(诸如movs、cmps、scas、lods、stos等)的操作方向。置位DF标志位可使字符串指令按从高到低的地址方向(自减)操作数据,复位DF标志位可使字符串指令按从低到高的地址方向(自增)操作数据。汇编指令std和cld可用于置位和复位DF方向标志。
1.2.3 系统标志和IOPL区域
第 8 位为TF位,即Trap Flag,意为陷阱标志位。此位若为1,用于让CPU进入单步运行方式,若为0,则为连续工作的方式。平时我们用的debug程序,在单步调试时,原理上就是让TF位为1。
第 9 位为IF位,即Interrupt Flag,意为中断标志位。若IF位为1,表示中断开启,CPU可响应外部可屏蔽中断。若为0,表示中断关闭,CPU不再响应来自CPU外部的可屏蔽中断,但CPU内部的异常还是要响应的。
第 12~13 位为IOPL,即 Input Output Privilege Level,这用在有特权级概念的CPU中。有4个任务特权级,即特权级0~3,故IOPL要占用2位来表示这4种特权级。
第 14 位为NT,即 Nest Task,意为任务嵌套标志位。8088支持多任务,一个任务就是一个进程。当一个任务中又嵌套调用了另一个任务时,此NT位为1,否则为0。
第 16 位为RF位,即 Resume Flag,意为恢复标志位。该标志位用于程序调试,指示是否接受调试故障,它需要与调试寄存器一起使用。当RF为1时忽略调试故障,为0时接受。
第 17 位为VM位,即 Virtual 8086 Model,意为虚拟8086模式。
第 18 位为AC位,即 Alignment Check / Access Control,意为对齐检查。若AC位为1时,则进行地址对齐检查,位0时不检查。
第 19 位为VIF位,即 Virtual Interrupt Flag,意为虚拟终端标志位,虚拟模式下的中断标志。
第 20 位为VIP位,即 Virtual Interrupt Pending Flag,意为虚拟中断挂起标志位。在多任务情况下,为操作系统提供的虚拟中断挂起信息,需要与 VIF 位配合。
第 21 位为ID位,即 Identification Flag,意为识别标志位。系统经常要判断CPU型号,若ID位为1,表示当前CPU支持CPUID指令,这样便能获取CPU的型号、厂商信息等;若ID位为0,则表示当前CPU不支持CPUID指令。
1.3 段寄存器
x86-64架构,拥有6个16位段寄存器(CS、DS、SS、ES、FS和GS),用于保存16位段选择子。段选择子是一种特殊的指针,用于标识内存中的段。要访问内存中的特定段,该段的段选择子必须存在于相应的段寄存器中。
在平坦内存模型中,段选择子指向线性地址空间的地址0;在分段内存模型中,每个分段寄存器通常加载有不同的段选择子,以便每个分段寄存器指向线性地址空间内的不同分段。
每一个段寄存器表示三种存储类型之一:代码,数据,栈。
CS寄存器保存了代码段(code segment)选择子。代码段存储的是需要执行的指令,处理器使用CS寄存器内的代码段选择子和RIP/EIP寄存器的内容生成的线性地址来从代码段查询指令。RIP/EIP寄存器存储的是下一条要执行的指令在代码段上的偏移。
DS、ES、FS和GS寄存器指向了四个数据段(data segment)。
SS寄存器包含栈段(stack segment)的段选择子,其中存储当前正在执行的程序、任务或处理程序的过程堆栈。
1.4 控制寄存器
目前,Intel处理器共拥有6个控制寄存器(CR0、CR1、CR2、CR3、CR4、CR8),它们有若干个标志位组成,通过这些标志位可以控制处理器的运行模式、开启扩展特性以及记录异常状态等功能。
1.5 指令指针寄存器
RIP/EIP寄存器,即指令指针寄存器,有时称为程序计数器。指令指针(RIP/EIP)寄存器包含当前代码段中要执行的下一条指令的偏移量。
1.6 MSR寄存器组
MSR(Model-Specific Register)寄存器组可提供性能监测、运行轨迹跟踪与调试以及其它处理器功能。在使用MSR寄存器组之前,我们应该通过CPUID.01h:EAX[5]来检测处理器是否支持MSR寄存器组。处理器可以使用RDMSR和WRMSR对MSR寄存器组进行访问,整个访问过程借助ECX寄存器索引寄存器地址,再由EDX:EAX组成的64位寄存器保持访问值。(在处理器支持64位模式下,RCX、RAX和RDX寄存器的高32位将会被忽略)。
二、指令集
2.1 操作数和指令后缀
2.1.1 操作数
x86指令可以有0到3个操作数,多个操作数之间以逗号(“,”)分隔。对于有两个操作数的指令,第一个是源操作数,第二个是目的操作数,指令的执行结果保存到第二个操作数表示的寄存器或内存地址中。
源数据值可以以常数形式给出,或是从寄存器或内存中读取。结果可以存放在寄存器或内存中。因此,操作数被分为三种类型:
- 立即数(immediate),用来表示常数值。立即数通过在整数前加一个“$”来表示。比如,$-577或$0x1F;
- 寄存器(register),它表示某个寄存器的内容,通过在寄存器名声前加上“%”来表示。比如:%eax或%al;
- 内存引用,它会根据计算出来的地址(通常称为有效地址)访问某个内存位置。内存引用的语法:segment:offset(base, index, scale)。
- segment 可以是 x86 架构的任意段寄存器。segment 是可选的,如果指定的话,后面要跟上冒号(“:”)来与offset隔离开;如果未指定指定的话,默认为数据段寄存器--%ds。
- offset 是一个立即数偏移量,是可选的。
- base表示基址寄存器,可以是16个通用寄存器中的任意一个。
- index表示变址寄存器,可以是16个通用寄存器中的任意一个。
- scale表示比例因子,scale会与index相乘再加上base来表示内存地址。比例因子必须是1、2、4、或者8,若果比例因子未指定,默认为1。
有效地址被计算为:D[segment]+offset+R[base]+R[index]*scale,其中D[]表示对应段寄存器的数据,R[]表示通用寄存器里的数据。我们用M[addr]来表示内存地址addr。
内存地址操作示例:
| 指令 | 说明 |
|---|---|
| movl var, %eax | 把内存地址M[var]处的数据传送到eax寄存器 |
| movl %cs:var, %eax | 把代码段偏移量为var处的内存数据传送到eax寄存器 |
| movl $var, %eax | 把立即数var传送到eax寄存器 |
| movl var(%esi), %eax | 把内存地址 M[R[%esi] + var] 处的数据传送到eax寄存器 |
| movl (%ebx, %esi, 4), %eax | 把内存地址 M[R[%ebx] + R[%esi]*4] 处的数据传送到eax寄存器 |
| movl var(%ebx, %esi, 4), %eax | 把内存地址 M[var+R[%ebx] + R[%esi]*4] 处的数据传送到eax寄存器 |
2.1.2 指令后缀
由于是从16位体系结构扩展成32位的,Intel用术语“字(word)”表示16位数据类型。因此,称32位为“双字(double words)”,称64位数为“四字(quad words)”。标准int值存储为双字(32位)。指针存储为8字节的四字。x86-64中,数据类型long实现为64位。x86-64指令集同样包括完整的针对字节、字和双字的指令。
下表给出了C语言基本数据类型对应的x86-64表示。在64位机器中,指针长8字节。
| C声明 | Intel数据类型 | 汇编代码后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char * | 四字(指针) | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
浮点数主要有两种形式:单精度(4字节)值,对应于C语言数据类型float;双精度(8字节)值,对应于C语言数据类型double。
如上表所示,大多数汇编代码指令都有一个字符的后缀,表明操作数的大小。例如:数据传送指令有四个变种:movb(传送字节)、movw(传送字)、movl(传送双字)和movq(传送四字)。注意,虽然汇编代码使用后缀“l”来表示4字节整数和8字节浮点数,但并不会产生歧义,因为浮点使用的是一组完全不同的指令和寄存器。
2.2 数据传送指令
2.2.1 简单传送指令
最简单形式的数据传送指令是MOV类。这些指令把数据从源位置复制到目的位置,不做任何变化。MOV类由四条指令组成:movb、movw、movl和movq。这些指令都执行同样的操作,主要区别在于他们操作的数据大小不同:分别是1、2、4和8字节。下表列出了MOV类指令:
| 指令 | 效果 | 描述 |
|---|---|---|
| MOV S, D | S → D | 传送 |
| movb | 传送字节 | |
| movw | 传送字 | |
| movl | 传送双字 | |
| movq | 传送四字 | |
| movabsq I, R | I → R | 传送绝对的四字 |
源操作数指定的值是一个立即数,存储在寄存器或者内存中。目的操作数指定一个位置,可以是寄存器或内存地址。x86-64加了一条限制,传送指令的两个操作数不能都指向内存位置。大多数情况下,MOV指令只会更新目的操作数指定的那些寄存器字节或内存位置。唯一的例外是movl指令以寄存器作为目的时,它会把该寄存器的高位4字节设置为0。
movabsq指令是处理64位立即数数据的。常规的movq指令只能以表示为32位补码数字的立即数作为源操作数,然后把这个值符号扩展得到64位的值,放到目的位置。movabsq指令能够以任意64位立即数作为源操作数,并且只能以寄存器作为目的。
代码示例:
movl $0x4050, %eax # 立即数 --> 寄存器,4字节
movw %bp, %sp # 寄存器 --> 寄存器,4字节
movb (%rbi, %rcx), %al # 内存 --> 寄存器,1字节
movb $-17, (%rsp) # 立即数 --> 内存,1字节
movq %rax, -12(%rap) # 寄存器 --> 内存,4字节理解数据传送如何改变目的寄存器:
1 movabsq $0x0011223344556677, %rax # %rax = 0x0011223344556677
2 movb $-1, %al # %rax = 0x00112233445566FF
3 movw $-1, %ax # %rax = 0x001122334455FFFF
4 movl $-1, %eax # %rax = 0x00000000FFFFFFFF
5 movq $-1, %rax # %rax = 0xFFFFFFFFFFFFFFFF在这个例子中,第一行的指令把寄存器%rax初始化为位模式 0011223344556677。剩下的指令源操作数是立即数-1。因此 movb 指令把%rax的低位字节设置为 FF,而 movw 指令把低 2 位字节设置为 FFFF,剩下的字节保持不变。movl 指令将低 4 个字节设置为 FFFFFFFF,同时把高位 4 字节设置为 00000000。最后 movq 指令把整个寄存器设置为 FFFFFFFFFFFFFFFF。
内核资料领取,Linux内核源码学习地址。
2.2.2 扩展传送指令
MOVZ和MOVS是另外两类数据移动指令,在将较小的源值复制到较大的目的时使用。MOVZ类中的指令把目的中剩余的字节填充位0,而MOVS类中的指令通过符号扩展来填充,把源操作数的最高位进行复制。这两类指令分别如下表所示。
零扩展的传送指令:
| 指令 | 效果 | 描述 |
|---|---|---|
| MOVZ S, R | 零扩展(S) → R | 以零扩展进行传送 |
| movzbw | 将做了零扩展的字节传送到字 | |
| movzbl | 将做了零扩展的字节传送到双字 | |
| movzbq | 将做了零扩展的字节传送到四字 | |
| movzwl | 将做了零扩展的字传送到双字 | |
| movzwq | 将做了零扩展的字传送到四字 |
符号扩展的传送指令:
| 指令 | 效果 | 描述 |
|---|---|---|
| MOVS S, R | 符号扩展(S) → R | 传送符号扩展的字节 |
| movsbw | 将做了符号扩展的字节传送到字 | |
| movsbl | 将做了符号扩展的字节传送到双字 | |
| movsbq | 将做了符号扩展的字节传送到四字 | |
| movswl | 将做了符号扩展的字传送到双字 | |
| movswq | 将做了符号扩展的字传送到四字 |
位扩展传送指令:
| 指令 | 效果 | 描述 |
|---|---|---|
| cbtw | 符号扩展(R[%al]) → R[%ax] | 把%al符号扩展到%ax |
| cwtl | 符号扩展(R[%ax]) → R[%eax] | 把%ax符号扩展到%eax |
| cwtd | 符号扩展(R[%ax]) → R[%dx]: R[%ax] | 把%ax符号扩展到%dx:%ax |
| cltq | 符号扩展(R[%eax]) → R[%rax] | 把%eax符号扩展到%rax |
| cltd | 符号扩展(R[%eax]) → R[%edx]: R[%eax] | 把%eax符号扩展到%edx:%eax |
| cqto | 符号扩展(R[%rax]) → R[%rdx]: R[%rax] | 把%rax符号扩展为八字 |
| cqtd | 符号扩展(R[%rax]) → R[%rdx]: R[%rax] | 把%rax符号扩展为八字 |
字节传送指令比较:
1 movabsq $0x0011223344556677, %rax # %rax = 0x0011223344556677
2 movb $0xAA, %dl # %dl = 0xAA
3 movb %dl, %al # %rax = 0x00112233445566AA
4 movsbq %dl, %rax # %rax = 0xFFFFFFFFFFFFFFAA
5 movzbq %dl, %rax # %rax = 0x00000000000000AA代码的头 2 行将寄存器 %rax 和 %dl 分别初始化为 0x0011223344556677 和 0xAA。剩下的指令都是将 %rdx的低位字节复制到 %rax的低位字节。movb 指令不改变其它字节。根据源字节的最高位,movsbq 指令将其它 7 个字节设为全 1 或全 0。由于十六进制 A 表示的二进制值为 1010,符号扩展会把高位字节都设置为 FF。movzbq 指令总是将其它 7 个字节全都设置为 0。
2.2.3 压入和弹出栈数据
栈相关指令如下表所示:
| 指令 | 效果 | 描述 |
|---|---|---|
| pushq S | R[%rsp]-8 → R[%rsp]; S → M[R[%rsp]] | 将四字压入栈 |
| popq D | M[R[%rsp]] → D; R[%rsp] + 8 → R[%rsp] | 将四字弹出栈 |
pushq 指令的功能是把数据压入到栈上,而 popq 指令是弹出数据。这些指令都只有一个操作数--压入的数据源和弹出的数据目的。
将一个四字值压入栈中,首先要将栈指针减 8,然后将值写到新的栈顶地址。因此,指令 pushq %rbp的行为等价于下面两条指令:
subq $8, %rsp
movq %rbp, (%rsp)弹出一个四字的操作包括从栈顶位置读出数据,然后将栈指针加 8。因此,指令 popq %rax 等价于下面两条指令:
movq (%rsp), %rax
addq $8, %rsp2.2.4 加载有效地址
leaq 指令格式如下:
| 指令 | 效果 | 描述 |
|---|---|---|
| leaq S, D | &S → D | 加载有效地址 |
加载有效地址(load effective address)指令 leaq 实际上是 movq 指令的变形。它的指令形式是从内存读数据到寄存器,但实际上它根本没有引用内存。它的第一个操作数看上去是一个内存引用,但该指令不是从指定的位置读入数据,而是将有效地址写入到目的操作数。例如,如果寄存器 %rdx 的值为 x,那么指令leaq 7(%rdx, %dx, 4), %rax将寄存器 %rax 的值为 5x+7。
2.3 算术和逻辑运算指令
2.3.1 算术运算指令
算术运算指令如下:
| 指令 | 效果 | 描述 |
|---|---|---|
| inc{bwlq} D | D+1 → D | 加 1 |
| dec{bwlq} D | D-1 → D | 减 1 |
| neg{bwlq} D | -D → D | 取负 |
| add{bwlq} S, D | D + S → D | 加 |
| sub{bwlq} S, D | D - S → D | 减 |
| imul{bwlq} S, D | D * S → D | 乘 |
2.3.2 逻辑运算指令
逻辑运算指令如下:
| 指令 | 效果 | 描述 |
|---|---|---|
| not{bwlq} D | ~D → D | 逻辑非 |
| or{bwlq} S, D | D | S → D | 逻辑或 |
| and{bwlq} S, D | D & S → D | 逻辑与 |
| xor{bwlq} S, D | D ^ S → D | 逻辑异或 |
2.3.3 移位运算
| 指令 | 效果 | 描述 |
|---|---|---|
| sal{bwlq} k, D | D << k → D | 左移 |
| shl{bwlq} k, D | D << k → D | 左移(等同于asl) |
| sar{bwlq} k, D | D >>_A k → D | 算术右移 |
| shr{bwlq} k, D | D >>_L k → D | 逻辑右移 |
移位操作第一个操作数是移位量,第二个操作数是要移位的数。可以进行算术和逻辑移位。移位量可以是一个8位立即数,或者放在单字节寄存器%cl中。(这些指令很特别,因为只允许以这个特定的寄存器作为操作数。)原则上来说,1个字节的移位量使得移位量的编码范围可以达到2^8 - 1 = 255。x86-64中,移位操作对 w 位长的数据值进行操作,移位量是由%cl寄存器的低 m 位决定的,这里2^m = w,高位会被忽略。所以,例如当寄存器 %cl 的十六进制值为 0xFF 时,指令 salb 会移 7 位,salw 会移 15 位, sall 会移 31 位, 而 salq 会移 63 位。
左移指令有两个名字:sal 和 shl。两者的效果是一样的,都是将右边填上0.右移指令不同,sar 执行算术移位(填上符号位),而 shr 执行逻辑移位(填上0)。移位操作的目的操作数可以是一个寄存器或者是一个内存位置。
代码示例:
salq $4, %rax # 把 %rax里的数据左移4位(乘以16),即 %rax = %rax * 162.3.4 特殊的算术操作
imul指令有两种不同的形式。其中一种,如 2.3.1 节所示,有两个操作数,这种形式的imul指令是一个“双操作数”乘法指令。但是,x86-64还提供了两条不同的“单操作数”乘法指令。根据操作数大小,这类指令把源操作数与 %rax 对应大小的寄存器内容相乘,结果放入 %rax 对应的寄存器中。而imulq指令,由于两个64位数相乘,结果可能为128位,所以使用了%rdx寄存器来保存运算结果的高64位,%rax保存运算结果的低64位。
另外,x86-64提供的除法指令,也是单操作数的。这类操作,根据操作数大小,以 %rdx 对应的寄存器保存余数, %rax对应的寄存器保存商。其中 idivb 和 idiv是个例外,它们的余数保存在 %ah 寄存器,商保存在 %al寄存器。
| 指令 | 效果 | 描述 |
|---|---|---|
| imulb S | S × R[%al] → R[%ax] | 8位有符号乘法 |
| imulw S | S × R[%ax] → R[%eax] | 16位有符号乘法 |
| imull S | S × R[%eax] → R[%rax] | 32位有符号乘法 |
| imulq S | S × R[%rax] → R[%rdx]: R[%rax] | 64位有符号乘法 |
| mulb S | S × R[%al] → R[%ax] | 8位无符号乘法 |
| mulw S | S × R[%ax] → R[%eax] | 16位无符号乘法 |
| mull S | S × R[%eax] → R[%rax] | 32位无符号乘法 |
| mulq S | S × R[%rax] → R[%rdx]: R[%rax] | 64位无符号乘法 |
| idivb S | R[%ax] mod S → R[%ah] R[%ax] ÷ S → R[%al] | 8位有符号除法 |
| idivw S | R[%dx]: R[%ax] mod S → R[%dx] R[%dx]: R[%ax] ÷ S → R[%ax] | 16位有符号除法 |
| idivl S | R[%edx]: R[%eax] mod S → R[%edx] R[%edx]: R[%eax] ÷ S → R[%eax] | 32位有符号除法 |
| idivq S | R[%rdx]: R[%rax] mod S → R[%rdx] R[%rdx]: R[%rax] ÷ S → R[%rax] | 64位有符号除法 |
| divb S | R[%ax] mod S → R[%ah] R[%ax] ÷ S → R[%al] | 8位无符号除法 |
| divw S | R[%dx]: R[%ax] mod S → R[%dx] R[%dx]: R[%ax] ÷ S → R[%ax] | 16位无符号除法 |
| divl S | R[%edx]: R[%eax] mod S → R[%edx] R[%edx]: R[%eax] ÷ S --> R[%eax] | 32位无符号除法 |
| divq S | R[%rdx]: R[%rax] mod S → R[%rdx] R[%rdx]: R[%rax] ÷ S → R[%rax] | 64位无符号除法 |
2.4 控制指令
2.4.1 条件码
除了整数寄存器(通用寄存器)外,CPU还维护者一组单个位的条件码寄存器(EFLAGS),它们描述了最近的算术或逻辑运算操作的属性。条件码的详细描述详见 1.2 节,这里我们列出最常用的条件码:
- CF:进位标志。最近的操作使最高位产生了进位或借位,用来检查无符号操作的溢出。
- ZF:零标志。最近的操作得出的结果是 0。
- SF:符号标志。最近的操作的得到的结果是否为负数。
- OF:溢出标志。最近的操作导致一个补码溢出,用来检查有符号溢出。
比如说,假设我们用一条 ADD 指令完成等价于 C 表达式 t = a + b 的功能,这里变量 a、b 和 t 都是整型的。然后,根据下面的C表达式来设置条件码:
CF (unsigned)t < (unsigned)a # 无符号溢出
ZF (t == 0) # 零
SF (t < 0) # 负数
OF (a<0 == b<0) && (t<0 != a<0) # 有符号溢出 2.3 节列出的所有指令都会设置条件码。对应逻辑操作,如 XOR,进位标志和溢出标志会设置成0。对于移位操作,进位标志将设置为最后一个被移出的位,而溢出标志设置为0。INC 和 DEC 指令会设置溢出和零标志,但是不会改变进位标志。
条件码通常不会直接读取,常用的使用方法有三种:
- 可以根据条件码的某种组合,将一个字节设置为 0 或者 1;
- 可以条件跳转到程序的某个地方
- 可以有条件的传送数据
2.4.2 CMP 和 TEST 指令
除了 2.3 节列出的指令会设置条件码,还有两类指令( CMP 和 TEST),它们只设置条件码而不改变任何其他寄存器。CMP 指令根据两个操作数之差来设置条件码。除了只设置条件码而不更新目的寄存器之外,CMP 指令与 SUB 指令的行为是一样的。如果两个操作数相等,这些指令会将零标志设置为1,而其他标志可以用来确定两个操作数之间的大小关系。 TEST 指令的行为与 AND 指令一样,除了它们只设置条件码而不改变目的寄存器。
| 指令 | 基于 | 描述 |
|---|---|---|
| CMP S1, S2 | S2 - S1 | 比较 |
| cmpb | 比较字节 | |
| cmpw | 比较字 | |
| cmpl | 比较双字 | |
| cmpq | 比较四字 | |
| TEST S1, S2 | S1 & S2 | 测试 |
| testb | 测试字节 | |
| testw | 测试字 | |
| testl | 测试双字 | |
| testq | 测试四字 |
2.4.3 SET指令
SET 指令根据条件码的某种组合,将一个字节设置为 0 或者 1。SET 指令是一组指令,指令的后缀表明了他们所考虑的条件码组合。例如:指令 setl 和 setb 表示 “小于时设置(set less)”和“低于时设置(set blow)”。SET 指令的目的操作数是低位单字节寄存器或是一个字节的内存地址,指令会将这个字节设置成 0 或者 1。
SET 指令列表如下:
| 指令 | 同义指令 | 设置条件 | 条件说明 |
|---|---|---|---|
| sete D | setz | ZF | 相等/零(set equal) |
| setne D | setnz | ~ZF | 不等/非零(set not equal) |
| sets D | SF | 负数 | |
| setns D | ~SF | 非负数 | |
| setg D | setnle | ~(SF ^ OF) & ~ZF | 大于(有符号 > ) |
| setge D | setnl | ~(SF ^ OF) | 大于等于(有符号 >= ) |
| setl D | setnge | SF ^ OF | 小于(有符号小于 < ) |
| setle D | setng | (SF ^ OF) | ZF | 小于等于(有符号 <= ) |
| seta D | setnbe | ~CF & ~ZF | 超过(无符号 > ) |
| setae D | setnb | ~CF | 超过或相等(无符号 >=) |
| setb D | setnae | CF | 低于(无符号 < ) |
| setbe D | setna | CF | ZF | 低于或相等(无符号 <=) |
2.4.4 跳转指令
跳转指令分为无条件跳转和有条件跳转。
2.4.4.1 无条件跳转
无条件跳转指令 jmp,可以是直接跳转,即跳转目标是作为指令一部分编码的;也可以是间接跳转,即跳转目标是从寄存器或内存位置中读取的。汇编语言中,直接跳转是给出一个标号作为跳转目标的。间接跳转的写法是 “*” 后面跟一个操作数指示符。直接跳转和间接跳转示例如下:
######################### 直接跳转示例 ##########################
movq $0, %rax
jmp .L1 # 直接跳转
movq (%rax), %rdx
.L1:
popq %rdx
######################### 间接跳转示例 ##########################
jmp *%rax # 用寄存器 %rax 中的值作为跳转目的
jmp *(%rax) # 以 %rax中的值作为读取地址,从内存中读出跳转目标
2.4.4.2 有条件跳转
下表中所示的跳转指令都是有条件的,它们根据条件码的某种组合,要么跳转,要么不跳转继续执行一条指令。条件跳转只能是直接跳转。
| 指令 | 同义指令 | 跳转条件 | 描述 |
|---|---|---|---|
| je Label | jz | ZF | 相等/零 |
| jne Lable | jnz | ~ZF | 不相等/非零 |
| js Label | SF | 负数 | |
| jns Label | ~SF | 非负数 | |
| jg Label | jnle | ~(SF ^ OF) & ~ZF | 大于(有符号 > ) |
| jge Label | jnl | ~(SF ^ OF) | 大于等于(有符号 >= ) |
| jl Label | jnge | SF ^ OF | 小于(有符号小于 < ) |
| jle Label | jng | (SF ^ OF) | ZF | 小于等于(有符号 <= ) |
| ja Label | jnbe | ~CF & ~ZF | 超过(无符号 > ) |
| jae Label | jnb | ~CF | 超过或相等(无符号 >=) |
| jb Label | jnae | CF | 低于(无符号 < ) |
| jbe Label | jna | CF | ZF | 低于或相等(无符号 <=) |
2.4.5 条件传送指令
| 指令 | 同义指令 | 传送条件 | 说明 |
|---|---|---|---|
| cmove | cmovz | ZF | 相等/零 |
| cmovne | cmovnz | ~ZF | 不相等/非零 |
| cmovs | SF | 负数 | |
| cmovns | ~SF | 非负数 | |
| cmovo | OF | 有溢出 | |
| cmovno | ~OF | 无溢出 | |
| cmovc | CF | 有进位 | |
| cmovnc | ~CF | 无进位 | |
| cmovp | cmovpe | PF | PF = 1 |
| cmovnp | cmovpo | ~PF | PF != 1 |
| cmovg | cmovnle | ~(SF ^ OF) & ~ZF | 大于(有符号 > ) |
| cmove | cmovnl | ~(SF ^ OF) | 大于等于(有符号 >= ) |
| cmovl | cmovnge | SF ^ OF | 小于(有符号小于 < ) |
| cmovle | cmovng | (SF ^ OF) | ZF | 小于等于(有符号 <= ) |
| cmova | cmovnbe | ~CF & ~ZF | 超过(无符号 > ) |
| cmovae | cmovnb | ~CF | 超过或相等(无符号 >=) |
| cmovb | cmovnae | CF | 低于(无符号 < ) |
| cmovbe | cmovna | CF | ZF | 低于或相等(无符号 <=) |
2.5 过程调用
x86-64的过程实现包括一组特殊的指令和一些对机器资源(例如寄存器和程序内存)使用规则的约定。
2.5.1 运行时栈
x86-64的栈向低地址方向增长,而栈指针 %rsp 指向栈顶元素。可以用 push 和 pop 相关指令将数据存入栈中或是从栈中取出数据。将栈指针减小一个适当的量可以为数据在栈上分配空间;类似的,可以通过增加栈指针来释放空间。
当过程 P 调用过程 Q 时,其栈内结构如下图所示:
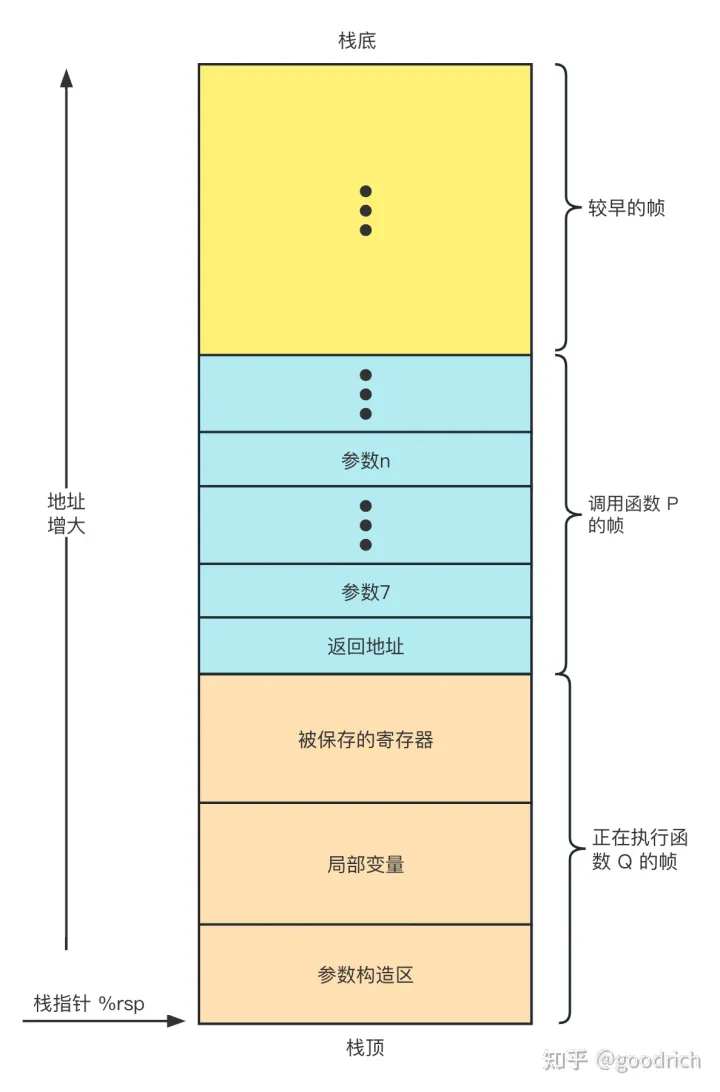
当前正在执行的过程的栈帧总是在栈顶。当 过程 P 调用过程 Q 时,会把返回地址压入栈中,指明当 Q 返回时,要从 P 程序的哪个位置继续执行。Q 的代码会扩展到当前栈的边界,分配它所需要的栈帧空间。在这个空间中,它可以保存寄存器的值,分配局部变量空间,为它调用的过程设置参数。通过寄存器,过程 P 可以传递最多 6 个整数值(包括指针和整数),如果 Q 需要更过参数时,P 可以在调用 Q 之前在自己的栈帧里存储好这些参数。
2.5.2 过程调用惯例
2.5.2.1 参数传递
x86-64中,最多允许 6 个参数通过寄存器来传递,多出的参数需要通过栈来传递,正如 2.5.1 节描述的那样;传递参数时,参数的顺序与寄存器的关系对应如下:
| 操作数大小(位) | 参数1 | 参数2 | 参数3 | 参数4 | 参数5 | 参数6 |
|---|---|---|---|---|---|---|
| 64 | %rdi | %rsi | %rdx | %rcx | %r8 | %r9 |
| 32 | %edi | %esi | %edx | %ecx | %r8d | %r9d |
| 16 | %di | %si | %dx | %cx | %r8w | %r9w |
| 8 | %dil | %sil | %dl | %cl | %r8b | %r9b |
如果一个函数 Q 有 n (n > 6)个整数参数,如果过程 P 调用过程 Q,需要把参数 1 ~ 6复制到对应的寄存器,把参数 7 ~ n放到栈上,而参数 7 位于栈顶。通过栈传递参数时,所有的数据大小都向 8 的倍数对齐。参数到位以后,程序就可以指向 call 指令将控制转移到 Q 了。
2.5.2.2 返回值
被调用函数返回时,把返回结果放入 %rax中,供调用函数来获取。
2.5.2.3 寄存器的其它约定
根据惯例,寄存器的 %rbx、%rbp和 %r12~%r15被划分位被调用者保存寄存器。当过程 P 调用过程 Q 时,Q 必须保证这些寄存器的值在被调用前和返回时是一致的。也就是说, Q 要么不去使用它,要么先把寄存器原始值压入栈,在使用完成后,返回到 P 之前再把这些寄存器的值从栈中恢复。
所有其它寄存器,除了栈指针 %rsp,都分类为调用者保存寄存器。这就意味着任何函数都能修改它们。可以这样来理解“调用者保存”这个名字:过程 P 在某个此类寄存器中存有数据,然后调用过程 Q。因为 Q 可以随意修改这个寄存器,所以在调用之前首先保存好这个数据时 P (调用者)的责任。
2.5.3 控制转移
过程调用时,通过一下指令来进行调用及返回:
| 指令 | 描述 |
|---|---|
| call Label | 过程调用 |
| call *Operand | 过程调用 |
| ret | 从过程调用返回 |
call 指令有一个目标,即指明被调用过程起始的指令地址。同跳转指令一样,调用可以是直接的,也可以是间接的。
当 call 指令执行时,调用者 P 已经按 2.5.2 的约定,把被调用者 Q 所需要的参数准备好了。该指令执行时,会把返回地址 A 压入栈中,并将PC (%rip)设置为 Q 的起始地址。对应的,ret 指令会从栈中弹出返回地址 A,并把PC(%rip)设置为 A,程序从 A 处继续执行。
2.6 字符串指令
字符串指令用于对字符串进行操作,这些操作包括在把字符串存入内存、从内存中加载字符串、比较字符串以及扫描字符串以查找子字符串。
2.6.1 movs、cmps类指令
movs 指令用于把字符串从内存中的一个位置拷贝到另一个位置。cmps 指令用于字符串比较。
在老的运行模式中,这些指令把字符串从 %ds: %(e)si 表示的内存地址拷贝到 %es: %(e)di 表示的内存地址。在64位模式中,这些指令把字符串从 %(r|e)si 表示的内存地址处拷贝到 %(r|e)di 表示的内存地址处。
当操作完成后, %(r|e)si 和 %(r|e)di 寄存器的值会根据 DF 标志位的值自动增加或减少。当 DF 位为 0 时,%(r|e)si 和 %(r|e)di 寄存器的值会增加,当 DF 为 1 时,寄存器的值会减少。根据移动的字符串是字节、字、双字、四字,寄存器会分别减少或增加1、2、4、8。
movs类指令:
| 指令 | 描述 |
|---|---|
| movsb | move byte string |
| movsw | move word string |
| movsl | move doubleword string |
| movsq | move qword string |
cmps类指令:
| 指令 | 描述 |
|---|---|
| cmpsb | compare byte string |
| cmpsw | compare word string |
| cmpsl | compare doubleword string |
| cmpsq | compare qword string |
2.6.2 lods指令
lods 指令把源操作数加载到 %al,%ax,%eax 或 %rax 寄存器,源操作数是一个内存地址。在老的模式下,这个地址会从 %ds:%esi 或者 %ds:%si读取(根据操作数地址属性是32还是16来决定使用不同的寄存器);在64位模式下内存地址从寄存器 %(r)si 处读取。
在数据加载完成后,%(r|e)si 寄存器会根据 DF 标志位自动增加或减少(如果 DF 为0,%(r|e)si 寄存器会增加;如果DF 为 1,%(r|e)si 寄存器会减少 )。根据移动的字符串是字节、字、双字、四字,寄存器会分别减少或增加1、2、4、8。
| 指令 | 描述 | 说明 |
|---|---|---|
| lodsb | load byte string | For legacy mode, Load byte at address DS:(E)SI into AL. For 64-bit mode load byte at address (R)SI into AL. |
| lodsw | load word string | For legacy mode, Load word at address DS:(E)SI into AX. For 64-bit mode load word at address (R)SI into AX. |
| lodsl | load doubleword string | For legacy mode, Load dword at address DS:(E)SI into EAX. For 64-bit mode load dword at address (R)SI into EAX. |
| lodsq | load qword string | Load qword at address (R)SI into RAX. |
2.6.3 stos 指令
stos 指令把 %al,%ax,%eax 或 %rax 寄存器里的字节、字、双字、四字数据,保存到目的操作数,目的操作数是一个内存地址。在老的模式下,这个地址会从 %ds:%esi 或者 %ds:%si读取(根据操作数地址属性是32还是16来决定使用不同的寄存器);在64位模式下内存地址从寄存器 %rdi 或 %edi 处读取。
在数据加载完成后,%(r|e)di 寄存器会根据 DF 标志位自动增加或减少(如果 DF 为0,寄存器会增加;如果DF 为 1, 寄存器会减少 )。根据移动的字符串是字节、字、双字、四字,寄存器会分别减少或增加1、2、4、8。
| 指令 | 描述 | 说明 |
|---|---|---|
| stosb | store byte string | For legacy mode, store AL at address ES:(E)DI; For 64-bit mode store AL at address RDI or EDI. |
| stosw | store word string | For legacy mode, store AX at address ES:(E)DI; For 64-bit mode store AX at address RDI or EDI. |
| stosl | store dowble word string | For legacy mode, store EAX at address ES:(E)DI; For 64-bit mode store EAX at address RDI or EDI. |
| stosq | store qword string | Store RAX at address RDI or EDI. |
2.6.4 REP相关指令
上面几节提到的字符串相关指令,都是单次执行的指令。可以在这些指令前面添加 rep 类前缀,让指令重复执行。重复执行的次数通过计数寄存器-- %(r|e)cx 来指定,或者根据ZF 标志位是否满足条件进行判断。
rep 类前缀包括: rep(repeat),repe(repeat while qeual),repne(repeat while not qeual),repz(repeat while zero) 和 repnz(repeat while not zero)。 rep 前缀可以放置在 ins,outs,movs,lods和stos指令前面;而repe、repne、repz和repnz前缀可以放置在 cmps 和 scas指令前面。
repe、repne、repz和repnz 前缀指令在每一次迭代执行后,会检查 ZF 标志是否满足中止条件,如果满足则中止循环。
中止条件:
| 前缀格式 | 中止条件1 | 中止条件2 |
|---|---|---|
| rep | %rcx 或 %(e)cx = 0 | 无 |
| repe/repz | %rcx 或 %(e)cx = 0 | ZF = 0 |
| repne/repnz | %rcx 或 %(e)cx = 0 | ZF = 1 |
三、汇编器指令
这部分指令是跟x86指令集无关的指令,这些指令以"."开头。
3.1 段相关指令
| 指令 | 描述 |
|---|---|
| .text | 代码段 |
| .rodata | 只读数据段 |
| .data | 数据段 |
| .bss | 未初始化数据段。bss段用于本地通用变量存储。您可以在bss段分配地址空间,但在程序执行之前,您不能指定要加载到其中的数据。当程序开始运行时,bss段的所有内容都被初始化为零。 |
3.2 数据相关指令
数据相关指令在.bss段无效。
| 指令 | 描述 |
|---|---|
| .ascii | 文本字符串,末尾不会自动添加‘‘\0’字符 |
| .asciz | 除了会在字符串末尾自动添加‘\0’字符外,同.ascii |
| .byte | 8位整数 |
| .short | 16位整数 |
| .int | 32位整数 |
| .long | 32位整数 (same as .int) |
| .quad | 8字节整数 |
| .octa | 16字节整数 |
| .single | 单精度浮点数 |
| .float | 单精度浮点数 |
| double | 双精度浮点数 |
代码示例:
.byte 74, 0112, 092, 0x4A, 0X4a # All the same value.
.ascii "Ring the bell\7" # A string constant.
.octa 0x123456789abcdef0123456789ABCDEF0 # A bignum.
.float 0f-314159265358979323846264338327\
95028841971.693993751E-40 # - pi, a flonum.