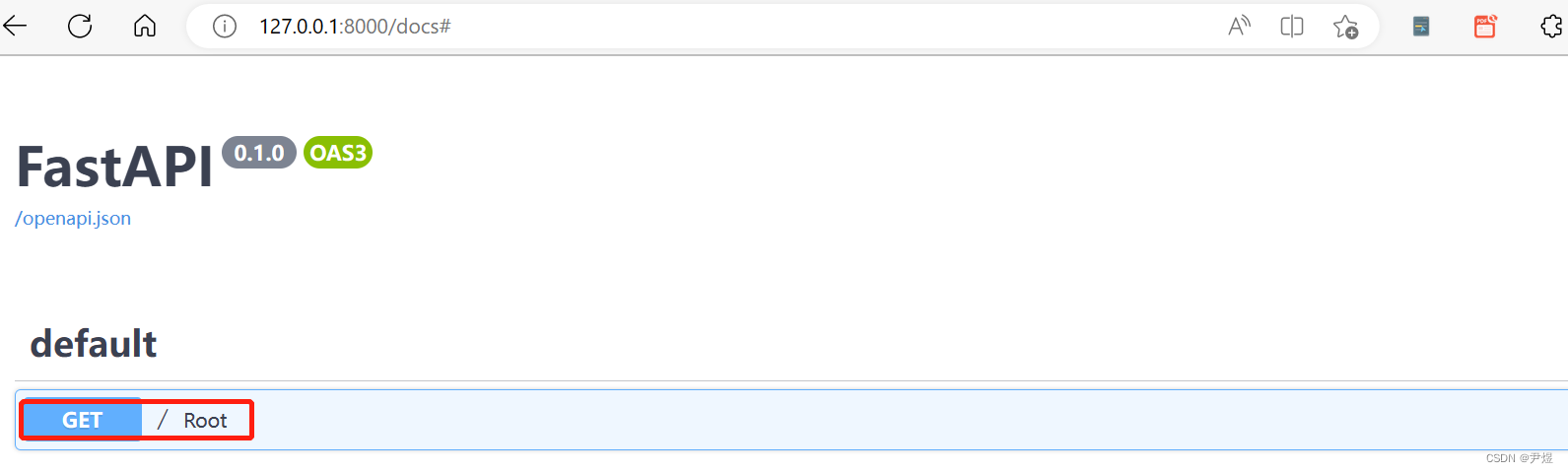
“可以将 LlamaIndex 视为外部数据和 LLM 连接在一起的黑匣子。”在 Zilliz 组织的网络研讨会中,LlamaIndex 的联合创始人兼首席执行官 Jerry Liu 曾这样说道。
对于 Jerry Liu 的这个比喻,熟悉 LLMs 的开发者会觉得颇为贴切,尤其是对于那些想要用私有数据要训练自己大模型的开发者而言,LlamaIndex 绝对是提升大模型性能,让其更加易用、流畅的不二选择。
为了方便更多开发者了解和使用 LlamaIndex,我们今天将从概念谈起,着重介绍它的索引部分及使用方法。
什么是 LlamaIndex?
在使用 LLMs 的过程中,开发者往往会遇到诸多挑战,例如 LLM 缺乏特定领域的知识。为此,我们引入了 CVP Stack,以便将不同领域的知识注入 LLM 应用之中。和 CVP Stack 一样,LlamaIndex 通过注入数据来帮助解决 LLM 对特定领域认知不足的情况。可以说,LlamaIndex 是开发者和 LLM 交互的一种工具。LlamaIndex 接收输入数据并为其构建索引,随后会使用该索引来回答与输入数据相关的任何问题。不止如此,LlamaIndex 还可以根据手头的任务构建许多类型的索引,例如向量索引、树索引、列表索引或关键字索引。
LlamaIndex 中的各式索引
本质上,LlamaIndex 中的所有索引类型都由“节点”组成,节点代表了文档中的一段文本。接下来,我们可以详细了解一下 LlamaIndex 构建的索引类型、索引工作流程、以及不同索引的适配场景。
-
列表索引

顾名思义,列表索引是一种以列表形式来表示的索引。首先,输入数据被分成节点;随后这些节点会按顺序排列。如果在查询时未指定其他参数,则会按照同一个节点顺序进行查询。除了基本顺序查询之外,我们还可以使用关键字或 embedding 来查询节点。
列表索引为用户提供了一种根据输入顺序进行查询的方法,即使超出了 LLM 的 token 限制,LlamaIndex 也会提供一种接口,能够自动使用输入数据的所有内容。原理是什么?事实上,LlamaIndex 会使用每个节点的文本进行查询,并根据附加数据逐步优化答案。
-
向量存储索引
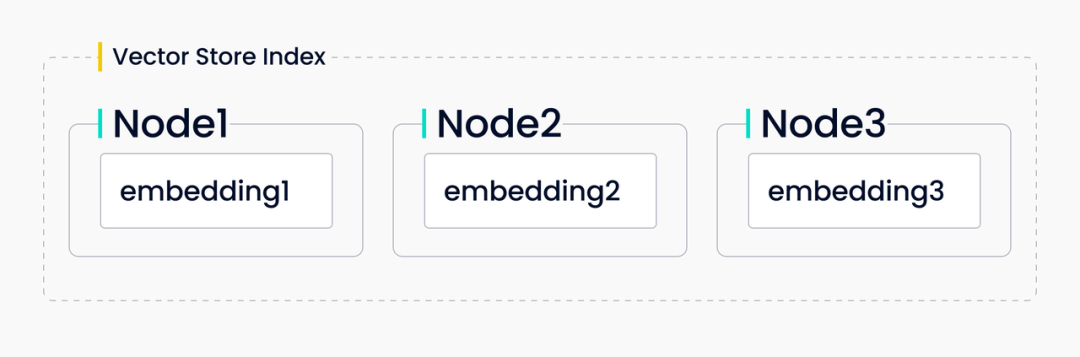
向量存储索引将节点存储为向量嵌入,而 LlamaIndex 可以支持这些向量 embedding 进行本地存储或使用专门的向量数据库(如 Milvus)存储。在查询时,LlamaIndex 会查找与节点最相似的 top_k 节点,并将其返回给响应合成器。
简言之,使用向量存储索引可以为 LLM 应用引入相似性检索,当使用者需要比较文本的语义相似性时,向量存储索引最为合适,例如,对特定类型的开源软件提问[1]。
-
树索引
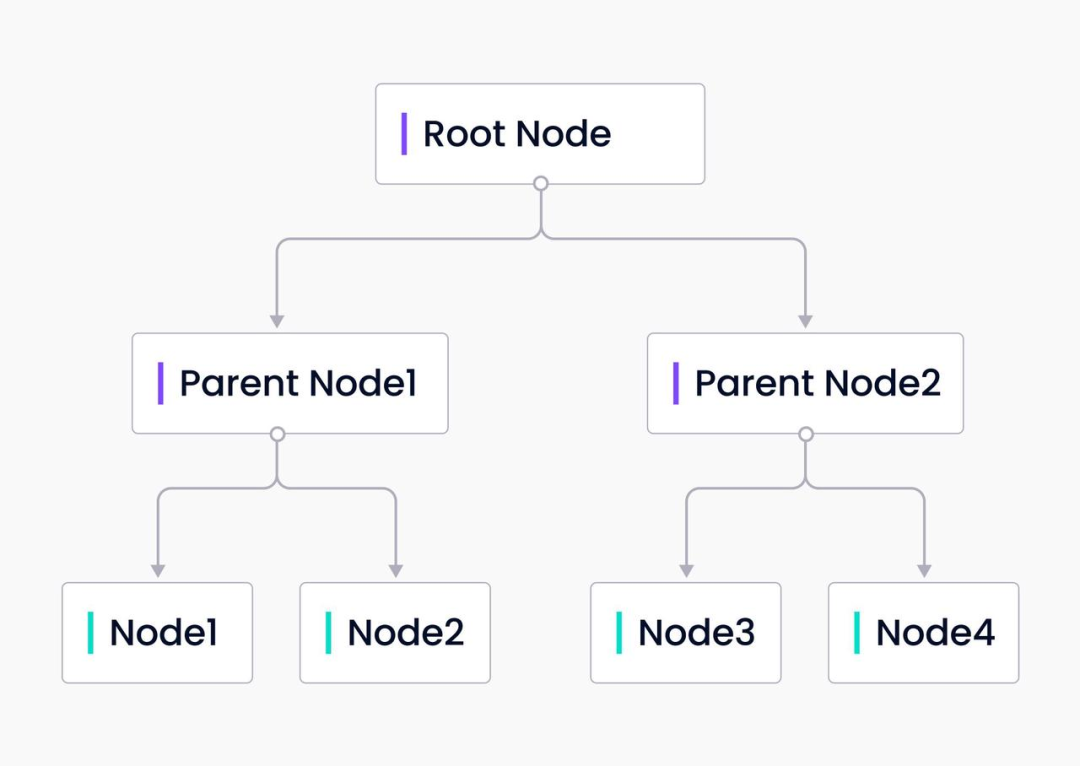
LlamaIndex 的树形索引根据用户的输入数据构建树形结构。树形索引从叶节点即原始输入数据块开始自下而上构建,每个父节点包含叶节点。LlamaIndex 用 GPT 对节点进行总结来构建树形结构,在构建响应查询时,树形索引可以从根节点向下遍历到叶节点或直接从选择的叶节点构建。
树形索引不仅对于查询长文本块行之有效,还可以从文本的不同部分提取信息。与列表索引不同,树形索引不需要按顺序查询。
-
关键词索引
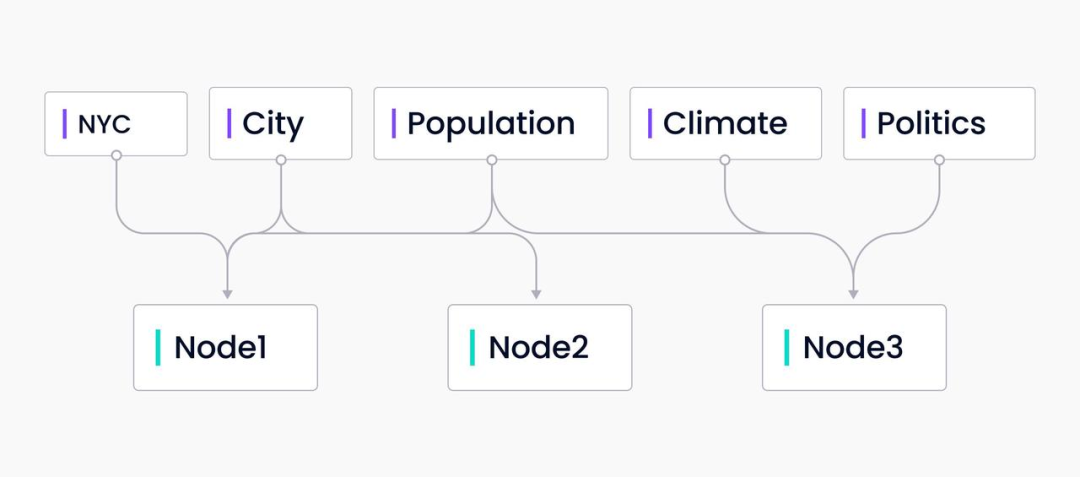
关键词索引是关键词到包含这些关键词的节点的映射。它是多对多的映射,每个关键词可能指向多个节点,每个节点可能有多个映射到它的关键词。在查询时,从查询中提取关键词,只查询映射的节点。
关键词索引适合查询大量数据中的特定关键词,尤其是在知晓用户的查询偏好时颇为适用。例如,用户在查询与健康保健相关的文件进行查询,且只关心与 COVID 19 相关的文档,此时选择关键词索引再合适不过了。
使用 LlamaIndex 的准备工作
首先,获取相关代码,我们把它们放在了 Google Colab[2] 笔记本,大家可以先获取提供的数据或者克隆 LlamaIndex repo[3],并打开 examples/paul_graham_essay 使用提供的示例代码。
其次,需要一个能够访问的 LLM。默认情况下,LlamaIndex 使用 GPT。大家可以从 OpenAI 网站获得 OpenAI API 密钥[4]。在示例代码中,我们是从 .env 文件中加载 OpenAI API 密钥的。不过,大家也可以直接在本地示例中输入密钥。无论上传到任何地方,记得先从代码中删除你的密钥!
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
from dotenv import load_dotenv
import os
load_dotenv()
open_api_key = os.getenv("OPENAI_API_KEY")
随后,需要从 LlamaIndex 导入两个库,即GPTVectorStoreIndex和SimplyDirectoryReader。
接下来的示例用的是 LlamaIndex 仓库所提供的 Paul Graham Essay example[5] 的数据和文件夹结构。如果没有克隆该 repo,需要在工作目录中创建一个名为data 的文件夹,以便下面的代码能够正常运行。
加载数据。我们调用 SimplyDirectoryReader 中的 load_data()函数,并传入包含数据的目录名称。在本例中,是 data。可以在此处传入绝对或相对文件路径。
接下来,需要索引。可以通过在刚刚加载的文档上调用 GPTVectorStoreIndex中的from_documents 来创建索引。
documents = SimpleDirectoryReader('data').load_data()
index = GPTVectorStoreIndex.from_documents(documents)
查询 LlamaIndex 向量存储索引
我已经在上文中提到,向量存储索引非常适用于相似性搜索。
例如,我们提出了这样一个问题“作者成长过程中做了什么?”。这需要 LlamaIndex 解读文本并理解“成长过程中”是什么意思,随后再进行查询。
query_engine = index.as_query_engine()
response=query_engine.query("What did the author do growing up?")
print(response)
响应如下:
The author grew up writing short stories, programming on an IBM 1401, and nagging his father to buy a TRS-80 microcomputer. …
保存和加载索引
在实际应用中,大多数情况下都需要用户保存索引。保存索引可以节省 GPT token,并降低 LLM 使用成本。
保存索引非常容易,只需在索引上调用.storage_context.persist()。
index.storage_context.persist()
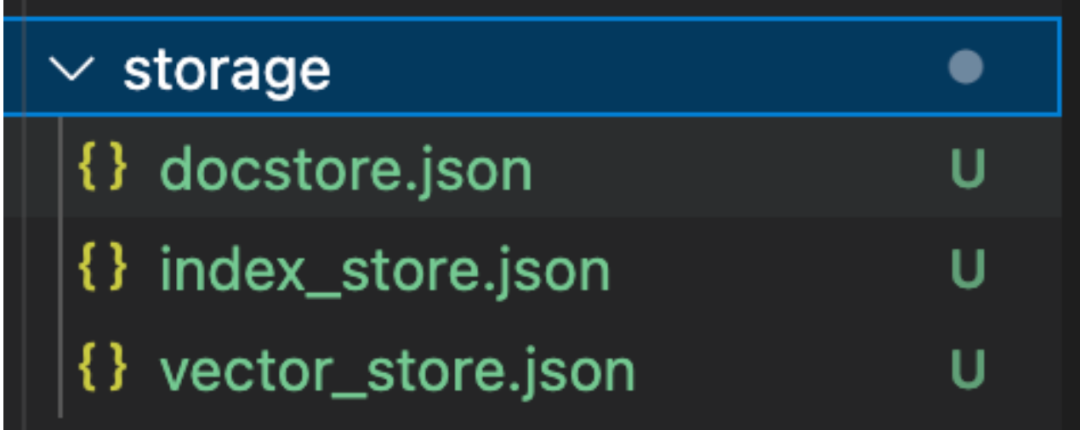
调用后,将创建一个名为storage的文件夹,其中包含三个文件:docstore.json、index_store.json和vector_store.json。这些文件分别包含文档、索引元数据和向量 embedding。如果需要可扩展的版本,可能需要将向量数据库作为向量索引存储。
如果想要加载索引,需要从llama_index导入另外两个模块StorageContext和load_index_from_storage,并将持久存储目录传给StorageContext类。一旦加载了存储的上下文,就可以在上面调用load_index_from_storage函数重新加载索引。
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="./storage")
# load indexindex = load_index_from_storage(storage_context)
当然,除了在不同场景下构建各式索引,LlamaIndex 还可以构建许多不同类型的项目,例如问答机器人、全栈 Web 应用程序、文本分析项目等。想要了解更多 LlamaIndex 构建的应用程序[6],可参考相关链接进行查询。
-
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。 • -
欢迎关注微信公众号“Zilliz”,了解最新资讯。 • 
本文由 mdnice 多平台发布