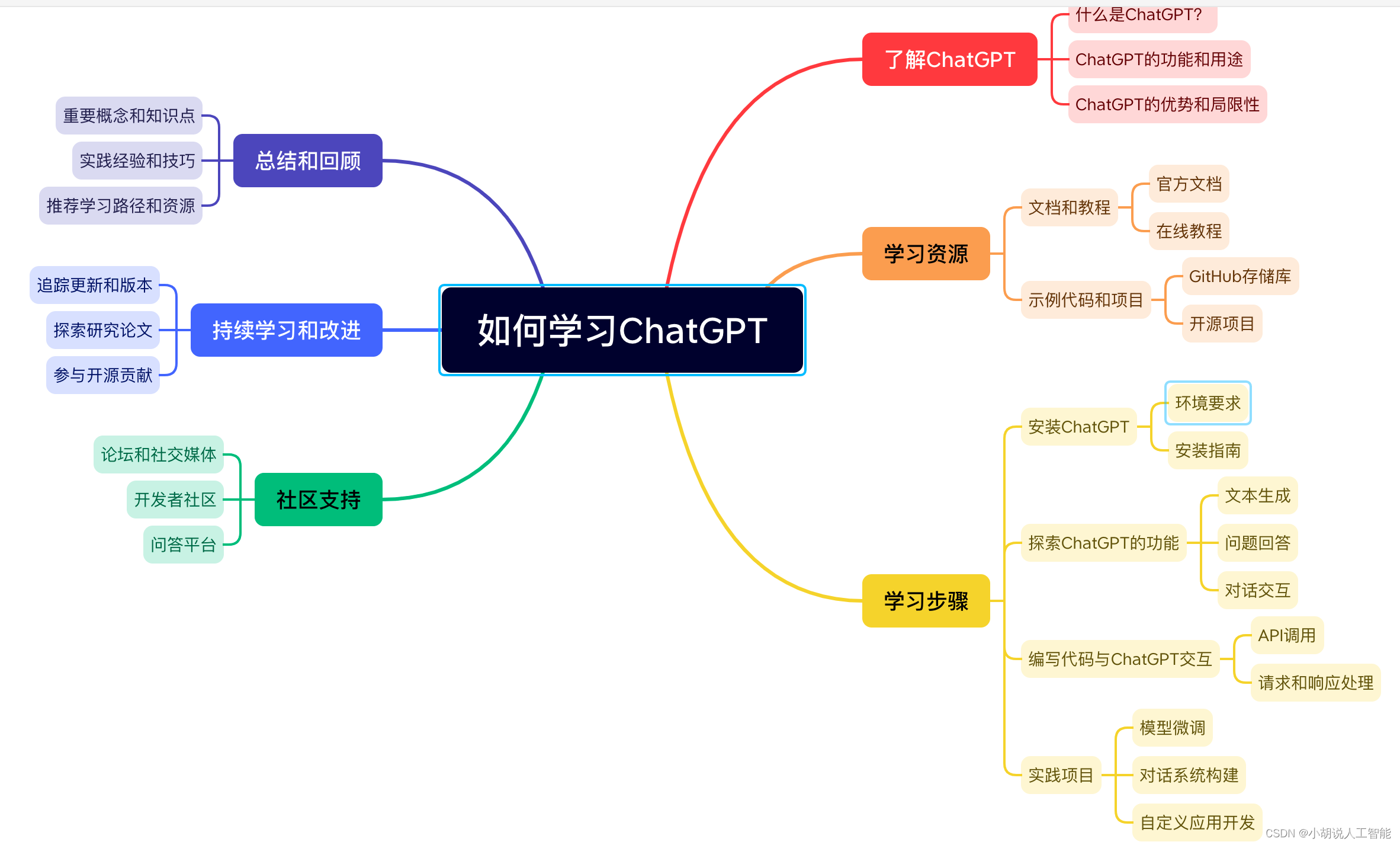
Dubbo源码篇07---SPI神秘的面纱---原理篇---下
- 引言
- 根据name获取扩展实例对象
- 获取默认扩展实例对象
- 按条件批量获取扩展实例对象
- 实例演示
引言
上篇文章: Dubbo源码篇06—SPI神秘的面纱—原理篇—上 我们追踪了getAdaptiveExtension获取自适应扩展点的整个流程,整个流程核心如下:
private T createAdaptiveExtension() {
T instance = (T) getAdaptiveExtensionClass().newInstance();
instance = postProcessBeforeInitialization(instance, null);
injectExtension(instance);
instance = postProcessAfterInitialization(instance, null);
initExtension(instance);
return instance;
}
private Class<?> getAdaptiveExtensionClass() {
getExtensionClasses();
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
因为自适应扩展点在dubbo中的用意是用来实现运行时动态选择实现类的,所以不会对自适应扩展点赋予AOP能力,从上面的流程中我们也没有发现哪里存在Wrapper机制的处理。
所以本文我们顺着普通扩展类加载流程,来过一遍dubbo对AOP的处理过程:
ApplicationModel applicationModel = ApplicationModel.defaultModel();
ExtensionLoader<FrameWork> extensionLoader = applicationModel.getExtensionLoader(FrameWork.class);
FrameWork frameWork = extensionLoader.getExtension("guice");
根据name获取扩展实例对象
根据传入的name作为serviceKey去加载对应的扩展实现:
public T getExtension(String name) {
//第二个参数表明是否对当前扩展类启动Wrapper装饰
T extension = getExtension(name, true);
if (extension == null) {
throw new IllegalArgumentException("Not find extension: " + name);
}
return extension;
}
public T getExtension(String name, boolean wrap) {
...
//如果name为true,那么去获取默认扩展实现
if ("true".equals(name)) {
return getDefaultExtension();
}
String cacheKey = name;
if (!wrap) {
cacheKey += "_origin";
}
//查询缓存--没有新建一个Holder返回
final Holder<Object> holder = getOrCreateHolder(cacheKey);
Object instance = holder.get();
//缓存有,直接返回,否则进入创建逻辑
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
//创建扩展类的核心方法
instance = createExtension(name, wrap);
holder.set(instance);
}
}
}
return (T) instance;
}
private T createExtension(String name, boolean wrap) {
//getExtensionClasses方法上篇文章解析过了,这里跳过
Class<?> clazz = getExtensionClasses().get(name);
//如果没有key=name的扩展实现,则抛出异常
if (clazz == null || unacceptableExceptions.contains(name)) {
throw findException(name);
}
try {
// 判断对应的扩展实现类型是否已经创建过了实例对象--确保单例性
T instance = (T) extensionInstances.get(clazz);
//如果只是解析了SPI文件,构成了<name,class>缓存,下一步就是为当前扩展类型构建<class,signleInstance>缓存
if (instance == null) {
//利用instantiationStrategy实例化扩展实例对象---具体逻辑在InstantiationStrategy中
//实例化逻辑比较简单: 要不就是默认构造,要么构造函数可以有参数,但是参数类型必须是ScopeModel子类
extensionInstances.putIfAbsent(clazz, createExtensionInstance(clazz));
instance = (T) extensionInstances.get(clazz);
//前后置处理--依赖注入
instance = postProcessBeforeInitialization(instance, name);
injectExtension(instance);
instance = postProcessAfterInitialization(instance, name);
}
//和自适应扩展点创建的不同逻辑: 判断是否需要对当前扩展实例进行装饰
if (wrap) {
List<Class<?>> wrapperClassesList = new ArrayList<>();
//当前扩展类相关wrapper类型搜集工作在getExtensionClasses中完成
if (cachedWrapperClasses != null) {
wrapperClassesList.addAll(cachedWrapperClasses);
wrapperClassesList.sort(WrapperComparator.COMPARATOR);
Collections.reverse(wrapperClassesList);
}
//wrapper class搜集是满足存在一个单参数的拷贝构造函数,并且参数类型为当前扩展类类型
if (CollectionUtils.isNotEmpty(wrapperClassesList)) {
//不断循环,套娃创建一层层的装饰器对象
for (Class<?> wrapperClass : wrapperClassesList) {
//Wrapper注解用于实现按条件装饰
Wrapper wrapper = wrapperClass.getAnnotation(Wrapper.class);
//如果wrapper class类上不存在Wrapper注解,那么表示装饰不需要满足任何条件
//否则,需要判断条件是否满足,满足才会进行装饰
boolean match = (wrapper == null) ||
((ArrayUtils.isEmpty(wrapper.matches()) || ArrayUtils.contains(wrapper.matches(), name)) &&
!ArrayUtils.contains(wrapper.mismatches(), name));
if (match) {
//满足则进入装饰流程
//1.实例化当前装饰类,采用的是单参的拷贝构造函数
//2.执行依赖注入流程
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
//3.执行后置处理流程
instance = postProcessAfterInitialization(instance, name);
}
}
}
}
// Warning: After an instance of Lifecycle is wrapped by cachedWrapperClasses, it may not still be Lifecycle instance, this application may not invoke the lifecycle.initialize hook.
//调用初始化接口---注意上面警告信息,也就是说经过包装后,我们的包装对象未必继承lifecycle接口,因此初始化调用也就不会发生了
initExtension(instance);
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " +
type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}
获取默认扩展实例对象
采用@SPI注解中的val值,作为serviceKey去加载对应的扩展实现:
public T getDefaultExtension() {
//加载SPI文件,构建相关缓存,如: <name,class>
getExtensionClasses();
//cachedDefaultName来自@SPI注解中的val值
if (StringUtils.isBlank(cachedDefaultName) || "true".equals(cachedDefaultName)) {
return null;
}
//这个流程上面讲过了
return getExtension(cachedDefaultName);
}
按条件批量获取扩展实例对象
到现在为止,我们还差extensionLoader.getActivateExtensions()流程没有讲解,下面我们来看看按条件批量获取扩展实例对象是怎样实现的:
public List<T> getActivateExtension(URL url, String key, String group) {
//根据传入的key从url中提取出value值
String value = url.getParameter(key);
//如果value不为空,则按照","分割,作为serviceKey
return getActivateExtension(url, StringUtils.isEmpty(value) ? null : COMMA_SPLIT_PATTERN.split(value), group);
}
public List<T> getActivateExtension(URL url, String[] values, String group) {
checkDestroyed();
// solve the bug of using @SPI's wrapper method to report a null pointer exception.
Map<Class<?>, T> activateExtensionsMap = new TreeMap<>(activateComparator);
List<String> names = values == null ? new ArrayList<>(0) : asList(values);
Set<String> namesSet = new HashSet<>(names);
if (!namesSet.contains(REMOVE_VALUE_PREFIX + DEFAULT_KEY)) {
//集合条件缓存构建: <serviceKey,groups> 和 <serviceKey,keyParis>
if (cachedActivateGroups.size() == 0) {
synchronized (cachedActivateGroups) {
// cache all extensions
if (cachedActivateGroups.size() == 0) {
//加载当前扩展类对应的SPI资源文件,并建立好相关缓存映射,此处主要为cachedActivates映射
//cachedActivates缓存了<serviceKey,@Activate注解> (serviceKey就是我们在SPI文件: serviceKey=serivceImpl全类名)
//如果配置文件中没有指定serviceKey,那么为@Extension注解中指定的val值,如果没有注解,那么就为实现类的简单类名
getExtensionClasses();
//依次处理当前扩展类下所有标注了@Activate注解的实现类
for (Map.Entry<String, Object> entry : cachedActivates.entrySet()) {
//key为serviceKey
String name = entry.getKey();
//activate注解
Object activate = entry.getValue();
String[] activateGroup, activateValue;
//提取注解中的值
if (activate instanceof Activate) {
activateGroup = ((Activate) activate).group();
activateValue = ((Activate) activate).value();
} else if (activate instanceof com.alibaba.dubbo.common.extension.Activate) {
activateGroup = ((com.alibaba.dubbo.common.extension.Activate) activate).group();
activateValue = ((com.alibaba.dubbo.common.extension.Activate) activate).value();
} else {
continue;
}
//缓存<serviceKey,groups>映射,即激活当前实现类,需要满足哪些分组要求(满足其一即可)
cachedActivateGroups.put(name, new HashSet<>(Arrays.asList(activateGroup)));
//缓存<serviceKey,keyParis>映射
//activate注解中的value属性有两种写法: key1:val1 或者 key2
//前者表示URL中存在key1=val1的键值对才算满足条件
//后置表示URL中存在key2即满足条件
String[][] keyPairs = new String[activateValue.length][];
for (int i = 0; i < activateValue.length; i++) {
if (activateValue[i].contains(":")) {
keyPairs[i] = new String[2];
String[] arr = activateValue[i].split(":");
keyPairs[i][0] = arr[0];
keyPairs[i][1] = arr[1];
} else {
keyPairs[i] = new String[1];
keyPairs[i][0] = activateValue[i];
}
}
cachedActivateValues.put(name, keyPairs);
}
}
}
}
// traverse all cached extensions
//遍历<serviceKey,groups>映射
cachedActivateGroups.forEach((name, activateGroup) -> {
// 如果函数调用中传入的group匹配条件为空,或者group存在于groups集合,则满足分组匹配这个条件
if (isMatchGroup(group, activateGroup)
//nameSet是从传入函数中的key,从url中获取value后,按照","分割,得到的集合
//这里去掉serviceKey=name的处理,因为该逻辑会在下面被处理
&& !namesSet.contains(name)
&& !namesSet.contains(REMOVE_VALUE_PREFIX + name)
//从<serviceKey,keyParis>集合中获取激活当前扩展实现类,需要满足哪些用户自定义条件
//这里判断逻辑就是: 如果用户指定的是形如@Active(value="key1:value1, key2:value2")
//那么会从url先中取出key1的值,与value1进行比较,相等直接返回true,否则取出key2值继续判断,也就是说这里是任意条件满足就返回true
//如果用户注解中只指定了@Active(value="key1"),那么只要url中存在key1,就满足条件
&& isActive(cachedActivateValues.get(name), url)) {
//如果分组条件和用户自定义条件都满足,则加入activateExtensionsMap集合<class,Instance>
activateExtensionsMap.put(getExtensionClass(name), getExtension(name));
}
});
}
if (namesSet.contains(DEFAULT_KEY)) {
...
} else {
// add extensions, will be sorted by its order
for (int i = 0; i < names.size(); i++) {
String name = names.get(i);
if (!name.startsWith(REMOVE_VALUE_PREFIX)
&& !namesSet.contains(REMOVE_VALUE_PREFIX + name)) {
if (!DEFAULT_KEY.equals(name)) {
//<serviceKey,class>集合中包含serviceKey=name
if (containsExtension(name)) {
//则将serviceKey=name的扩展实现类也加入结果集合
activateExtensionsMap.put(getExtensionClass(name), getExtension(name));
}
}
}
}
//返回最终得到的集合扩展实现类集合
return new ArrayList<>(activateExtensionsMap.values());
}
}
上面这一大段看下来可能会比较懵逼,但是没关系,下图详细解释了按照激活条件筛选的整个流程:
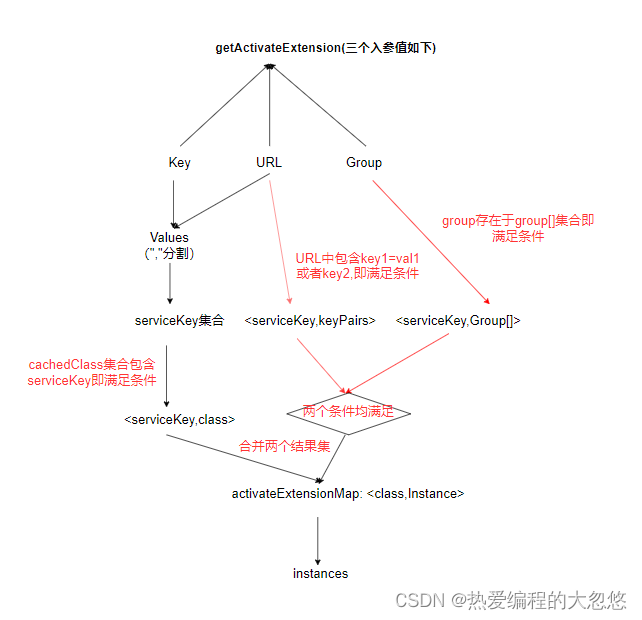
- 如果某个serviceKey对应的keyParis为空,也就是说用户没有自定义匹配条件,那么该条件分支默认返回true。
- 如果函数传入的group为空,那么不考虑分组匹配条件,该条件分支默认返回true
注意: 放入结果前时,扩展类的获取时调用的getExtension方法,意味着按条件批量获取扩展实例对象场景下,实现类是享有AOP(Wrapper机制)支持的:
activateExtensionsMap.put(getExtensionClass(name), getExtension(name));
实例演示
- 扩展接口,及其实现类
@SPI("spring")
public interface FrameWork {
@Adaptive
String getName(URL url);
String getInfo();
}
@Activate(value = {"name:dhy","age:18"},group = "test")
public class Guice implements FrameWork{
@Override
public String getName(URL url) {
return "guice";
}
@Override
public String getInfo() {
return "google 开源的轻量级IOC框架";
}
}
@Activate(value = {"name","sex"},group = "test")
public class Spring implements FrameWork{
@Override
public String getName(URL url) {
return "spring";
}
@Override
public String getInfo() {
return "流行的Spring框架";
}
}
@Activate(group = "prod")
public class SpringBoot implements FrameWork{
@Override
public String getName(URL url) {
return "springBoot";
}
@Override
public String getInfo() {
return "自动化的SpringBoot框架";
}
}
- SPI文件内容
spring=com.adaptive.Spring
springBoot=com.adaptive.SpringBoot
guice=com.adaptive.Guice
- 测试类
class ActivateTest {
@Test
void activateTest() {
ApplicationModel applicationModel = ApplicationModel.defaultModel();
ExtensionLoader<FrameWork> extensionLoader = applicationModel.getExtensionLoader(FrameWork.class);
List<FrameWork> frameWorkList = extensionLoader.getActivateExtension(URL.valueOf("dubbo://127.0.0.1:80/?age=18"), "", "test");
frameWorkList.forEach(frameWork -> {
System.out.println(frameWork.getInfo());
});
}
}
大家可自行更多参数条件,测试其他分支。