目录
- 1. 作者介绍
- 2. K近邻算法介绍
- 2.1 K基本原理
- 2.2 算法优缺点
- 3. KNN红酒数据集分类实验
- 3.1 获取红酒数据集
- 3.2 KNN算法
- 3.3 完整代码
- 4. 问题分析
- 参考链接(可供参考的链接和引用文献)
1. 作者介绍
路治东,男,西安工程大学电子信息学院,2022级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:206307079527@qq.com
2. K近邻算法介绍
2.1 K基本原理
原理:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,那么该样本也属于这个类别。简单来说就是,求两点之间的距离,看距离谁是最近的,以此来区分我们要预测的这个数据是属于哪个分类。
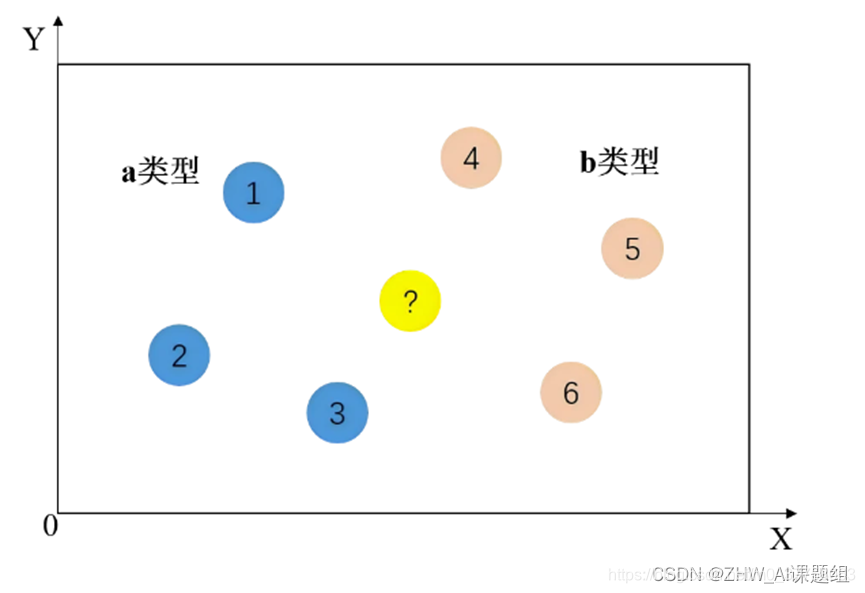
我们看图来理解一下。蓝色点是属于a类型的样本点,粉色点是属于b类型的样本点。此时新来了一个点(黄色点),怎么判断是属于它是a类型还是b类型呢。
方法是:新点找距离自身最近的k个点(k可变)。分别计算新点到其他各个点的距离,按距离从小到大排序,找出距离自身最近的k个点。统计在这k个点中,有多少点属于a类,有多少点属于b类。在这k个点中,如果属于b类的点更多,那么这个新点也属于b分类。距离计算公式也是我们熟悉的勾股定理。
2.2 算法优缺点
算法优点:简单易理解、无需估计参数、无需训练。适用于几千-几万的数据量。
算法缺点:对测试样本计算时的计算量大,内存开销大,k值要不断地调整来达到最优效果。k值取太小容易受到异常点的影响,k值取太多产生过拟合,影响准确性。
3. KNN红酒数据集分类实验
3.1 获取红酒数据集
首先导入sklearn的本地数据集库,变量wine获取红酒数据,由于wine接收的返回值是.Bunch类型的数据,因此我用wine_data接收所有特征值数据,它是178行13列的数组,每一列代表一种特征。wine_target用来接收所有的目标值,本数据集中的目标值(红酒类别)为0、1、2三类红酒。
然后把我们需要的数据转换成DataFrame类型的数据。为了使预测更具有一般性,我们把这个数据集打乱。操作如下:
from sklearn import datasets
wine = datasets.load_wine() # 获取葡萄酒数据
wine_data = wine.data #获取葡萄酒的索引data数据,178行13列
wine_target = wine.target #获取分类目标值
# 将数据转换成DataFrame类型
wine_data = pd.DataFrame(data = wine_data)
wine_target = pd.DataFrame(data = wine_target)
# 将wine_target插入到第一列,并给这一列的列索引取名为'class'
wine_data.insert(0,'class',wine_target)
# ==1== 变量.sample(frac=1) 表示洗牌,重新排序
# ==2== 变量.reset_index(drop=True) 使index从0开始排序
wine = wine_data.sample(frac=1).reset_index(drop=True) #把DataFrame的行顺序打乱
3.2 KNN算法
一般采用75%的数据用于训练,25%用于测试,因此在数据进行预测之前,先要对数据划分。
划分方式:
使用sklearn.model_selection.train_test_split 模块进行数据分割。
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=数据占比)
train_test_split() 括号内的参数:
x:数据集特征值(features)
y:数据集目标值(targets)
test_size: 测试数据占比,用小数表示,如0.25表示,75%训练train,25%测试test。
train_test_split() 的返回值:
x_train:训练部分特征值
x_test: 测试部分特征值
y_train:训练部分目标值
y_test: 测试部分目标值
# 划分测试集和训练集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(features,targets,test_size=0.25)
3.3 完整代码
import pandas as pd
from sklearn import datasets
wine = datasets.load_wine() # 获取葡萄酒数据
wine_data = wine.data #获取葡萄酒的索引data数据,178行13列
wine_target = wine.target #获取分类目标值
wine_data = pd.DataFrame(data = wine_data) #转换成DataFrame类型数据
wine_target = pd.DataFrame(data = wine_target)
# 将target插入到第一列
wine_data.insert(0,'class',wine_target)
# ==1== 变量.sample(frac=1) 表示洗牌,重新排序
# ==2== 变量.reset_index(drop=True) 使index从0开始排序,可以省略这一步
wine = wine_data.sample(frac=1).reset_index(drop=True)
# 拿10行出来作验证
wine_predict = wine[-10:].reset_index(drop=True)
wine_predict_feature = wine_predict.drop('class',axis=1) #用于验证的特征值,输入到predict()函数中
wine_predict_target = wine_predict['class'] #目标值,用于和最终预测结果比较
wine = wine[:-10] #删除后10行
features = wine.drop(columns=['class'],axis=1) #删除class这一列,产生返回值,这个是特征值
targets = wine['class'] #class这一列就是目标值
# 相当于13个特征值对应1个目标
# 划分测试集和训练集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(features,targets,test_size=0.25)
# 先标准化再预测
from sklearn.preprocessing import StandardScaler #导入标准化缩放方法
scaler = StandardScaler() #变量scaler接收标准化方法
# 传入特征值进行标准化
x_train = scaler.fit_transform(x_train) #对训练的特征值标准化
x_test = scaler.fit_transform(x_test) #对测试的特征值标准化
wine_predict_feature = scaler.fit_transform(wine_predict_feature)
# 使用K近邻算法分类
from sklearn.neighbors import KNeighborsClassifier #导入k近邻算法库
# k近邻函数
knn = KNeighborsClassifier(n_neighbors=5,algorithm='auto')
# 训练,把训练的特征值和训练的目标值传进去
knn.fit(x_train,y_train)
# 检测模型正确率--传入测试的特征值和目标值
# 评分法,根据x_test预测结果,把结果和真实的y_test比较,计算准确率
accuracy = knn.score(x_test,y_test)
# 预测,输入预测用的x值
result = knn.predict(wine_predict_feature)
4. 问题分析
若遇到安装库不完整问题,见如下所图示的错误,可检测相关库是否安装或环境问

参考链接(可供参考的链接和引用文献)
[1]K近邻算法:原理、实例应用]https://blog.csdn.net/dgvv4/article/details/121316823
[2]案例:红酒数据集分析]https://blog.csdn.net/qq_42374697/article/details/108073110


![【Linux系列P4】Linux需要什么?编辑器?软件包?一文帮你了解掌握 [yum][vim]———基础开发工具篇](https://img-blog.csdnimg.cn/e32ce7a4ec304e7389ad519a53a2866b.png)