ChatGPT 中文指南(大全)
内容包含:如何开通chatgpt、chatgpt的同类站点、prompts 、AI绘图、ChatGPT 工具、相关报告论文、ChatGPT应用项目等
链接:ChatGPT 中文指南(大全) 指令指南,精选资源清单,更好的使用 chatGPT 让你的生产力up up up!
一、快速排序
快速排序(Quick Sort)是一种基于分治思想的排序算法,由英国计算机科学家 Tony Hoare 在 1960 年提出。快速排序的基本思想是通过一趟排序将待排序序列分割成两部分,其中一部分的所有元素都比另一部分的所有元素小,然后再按照此方法对这两部分分别进行快速排序,直到整个序列有序。
快速排序的具体实现过程如下:
-
选择一个基准元素(pivot),通常选择待排序序列的第一个元素或最后一个元素。
-
将待排序序列分成两部分,一部分的所有元素都比基准元素小,另一部分的所有元素都比基准元素大。
-
对两部分分别进行快速排序,递归地进行上述操作。
-
合并两部分的结果,得到最终的排序结果。
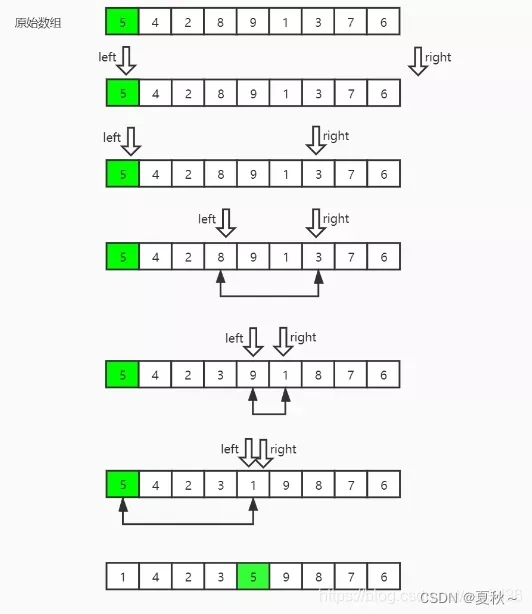
快速排序的时间复杂度为 O(nlogn),空间复杂度为 O(logn),是一种高效的排序算法。快速排序的性能受到基准元素的选择和待排序序列的初始状态的影响,最坏情况下时间复杂度为 O(n^2)。
为了避免最坏情况的发生,通常采用以下优化措施:
-
随机选择基准元素,避免选择到最大或最小的元素。
-
三数取中法,即选择待排序序列的第一个、中间和最后一个元素的中位数作为基准元素。
-
对于小规模的子序列,使用插入排序或选择排序等简单排序算法进行排序。
总之,快速排序是一种高效的排序算法,具有时间复杂度为 O(nlogn)、空间复杂度为 O(logn) 的优点。但是快速排序的性能受到基准元素的选择和待排序序列的初始状态的影响,需要采取一些优化措施来避免最坏情况的发生。
二、快速排序的性质
快速排序是一种高效的排序算法,具有原地排序、分治、时间复杂度为 O(nlogn)、空间复杂度为 O(logn) 的优点。
-
快速排序是一种原地排序算法,不需要额外的空间,可以在空间有限的情况下进行排序。
-
快速排序是一种分治算法,它将待排序序列分成两部分,一部分的所有元素都比基准元素小,另一部分的所有元素都比基准元素大。
-
快速排序的时间复杂度为 O(nlogn),空间复杂度为 O(logn)。
-
快速排序的性能受到基准元素的选择和待排序序列的初始状态的影响,最坏情况下时间复杂度为 O(n^2)。
-
快速排序是一种不稳定排序算法,相同的元素可能会被交换到不同的位置。
三、快速排序的变种
快速排序有多种变种,以下是其中几种常见的变种:
-
随机化快速排序(Randomized Quick Sort):在选择基准元素时,随机选择待排序序列中的一个元素作为基准元素,避免选择到最大或最小的元素,从而避免最坏情况的发生。
-
双路快速排序(Two-way Quick Sort):双路快速排序是一种优化的快速排序算法,它使用两个指针分别从序列的左右两端开始扫描,将待排序序列分成两部分,一部分的所有元素都比基准元素小,另一部分的所有元素都比基准元素大,从而避免了在某些情况下出现的分区不均衡的问题。
-
三路快速排序(Three-way Quick Sort):三路快速排序是一种针对待排序序列中存在大量重复元素的情况下的优化算法,它将待排序序列分成三部分,一部分的所有元素都比基准元素小,一部分的所有元素都等于基准元素,另一部分的所有元素都比基准元素大,从而避免了在存在大量重复元素的情况下出现的分区不均衡的问题。
-
原地快速排序(In-Place Quick Sort):原地快速排序是一种优化的快速排序算法,它不需要额外的空间,可以在原地对待排序序列进行排序,从而避免了空间复杂度较高的问题。
快速排序的变种算法可以针对不同的情况进行优化,以提高排序的效率和稳定性。在实际应用中,需要根据具体的情况选择合适的快速排序算法。
四、Java 实现
以下是 Java 实现快速排序的示例代码:
public class QuickSort {
public static void sort(int[] arr, int low, int high) {
if (low < high) {
int pivot = partition(arr, low, high); // 分区操作,将数组分为两部分
sort(arr, low, pivot - 1); // 递归排序左子数组
sort(arr, pivot + 1, high); // 递归排序右子数组
}
}
private static int partition(int[] arr, int low, int high) {
int pivot = arr[low]; // 基准元素
while (low < high) {
while (low < high && arr[high] >= pivot) {
high--;
}
arr[low] = arr[high]; // 比基准元素小的移到低端
while (low < high && arr[low] <= pivot) {
low++;
}
arr[high] = arr[low]; // 比基准元素大的移到高端
}
arr[low] = pivot; // 基准元素移到中间,分区完成
return low; // 返回基准元素的位置
}
public static void main(String[] args) {
int[] arr = {6, 5, 3, 1, 8, 7, 2, 4}; // 待排序数组
sort(arr, 0, arr.length - 1); // 排序
System.out.println(Arrays.toString(arr)); // 输出排序结果
}
}
在上述代码中,sort() 方法是快速排序的主方法,它通过递归调用 partition() 方法来实现分区操作和排序。partition() 方法是分区操作的实现,它通过指针 low 和 high 来将数组分为两部分,一部分的所有元素都比基准元素小,另一部分的所有元素都比基准元素大。在分区操作完成后,partition() 方法返回基准元素的位置,以便于递归调用 sort() 方法对左右子数组进行排序。最终,sort() 方法将数组排序完成后输出排序结果。
五、快速排序的应用场景
快速排序是一种高效的排序算法,适用于大规模数据的排序。以下是快速排序的一些应用场景:
-
数据库中的排序:在数据库中,需要对大量数据进行排序,快速排序是一种高效的排序算法,可以快速对大量数据进行排序,提高数据库的查询效率。
-
操作系统中的文件排序:在操作系统中,需要对大量文件进行排序,快速排序是一种高效的排序算法,可以快速对大量文件进行排序,提高文件系统的读写效率。
-
数组中的排序:在数组中,需要对大量数据进行排序,快速排序是一种高效的排序算法,可以快速对大量数据进行排序,提高程序的执行效率。
-
统计学中的排序:在统计学中,需要对大量数据进行排序,快速排序是一种高效的排序算法,可以快速对大量数据进行排序,提高数据分析的效率。
六、快速排序在spring 中的应用
在 Spring 框架中,快速排序主要应用于对集合类型的数据进行排序。Spring 框架提供了 Sort 接口和 SortUtils 工具类来实现快速排序。
Sort 接口是 Spring 框架中的排序接口,它定义了排序的方法和排序的方向。SortUtils 工具类是 Spring 框架中的排序工具类,它提供了对集合类型的数据进行排序的方法。
以下是 Spring 框架中快速排序的示例代码:
List<User> userList = new ArrayList<>();
// 添加用户数据
userList.add(new User(1, "Tom"));
userList.add(new User(2, "Jerry"));
userList.add(new User(3, "Lucy"));
userList.add(new User(4, "Jack"));
// 创建排序对象
Sort sort = Sort.by(Sort.Direction.ASC, "id");
// 对用户列表进行排序
List<User> sortedList = SortUtils.sortList(userList, sort);
在上述代码中,我们首先创建了一个用户列表 userList,然后使用 Sort 接口创建了一个排序对象 sort,指定了排序的方向和排序的字段。最后,使用 SortUtils 工具类对用户列表进行排序,得到了排序后的列表 sortedList。
需要注意的是,在实际应用中,我们需要根据具体的需求选择合适的排序算法和排序字段,以提高排序的效率和稳定性。