目录
一、分组查询
1.基本语法 :
2.代码演示 :
二、分页查询
1.基本语法 :
2.代码演示 :
三、多表查询
1.定义 :
2.语法 :
3.演示 :
四、嵌套查询
1.定义 :
2.单行子查询 :
1° 特点
2° 演示
3.多行子查询 :
1° 特点
2° 演示
4.临时表 :
1° 定义
2° 演示
5.多列子查询 :
1° 定义
2° 演示
五、合并查询
1.概述 :
2.演示 :
一、分组查询
1.基本语法 :
SELECT column_1, column_2...column_n
FROM table_name
GROUP BY column_1,column_2...
HAVING...;
注意事项——
1° GROUP BY 用于对查询得到的结果进行分组统计,其本质就是以指定的列为标准,对行(记录)进行分类和合并;
2° HAVING的作用相当于WHERE,用于限制分组的显示结果,但分组查询时不用WHERE。
2.代码演示 :
先来建三张表,分别是employee员工表、department部门表和salary工资表。
创建员工表的代码如下 :
CREATE TABLE IF NOT EXISTS `employee`(
`eno` MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
`ename` VARCHAR(20) NOT NULL DEFAULT '',
`ecareer` VARCHAR(20) NOT NULL DEFAULT '',
`mgr` MEDIUMINT UNSIGNED,
`hiredate` DATE NOT NULL,
`esalary` DECIMAL(8,2),
`ebonus` DECIMAL(8,2),
`deptno` MEDIUMINT UNSIGNED NOT NULL DEFAULT 0
) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin ENGINE INNODB;
INSERT INTO `employee`
VALUES(5000, 'Cyan', 'Full_Stack', 2000, '2002-1-1', 9000, NULL, '20'),
(5001, 'Five', 'Back_End', 2000, '2002-1-1', 9000, 10000, '20'),
(5534, 'Raina', 'Sale', 2766, '2003-3-1', 5000, 5000, '30'),
(5537, 'Ice', 'Back_End', 2000, '2003-6-12', 9000, 10000, '20'),
(5600, 'Kyrie', 'Fore_End', 2000, '2004-9-1', 9500, 20000, '20'),
(5611, 'James', 'Sale', 2766, '2004-9-13', 5500, 10000, '30'),
(5612, 'Bob', 'Sale', 2766, '2004-9-15', 5500, 10000, '30'),
(5700, 'Alice', 'Manage', 1088, '2004-10-1', 20000, 30000, '10'),
(6111, 'Fiven', 'Manage', 1088, '2006-1-11', 20000, 30000, '10'),
(6113, 'Cyana', 'Fore_End', 2000, '2006-1-11', 11000, 20000, '20'),
(6150, 'Peter', 'Accounting', 1760, '2006-3-1', 6000, 20000, '40'),
(6300, 'White', 'Accounting', 1760, '2009-6-6', 7000, 20000, '40'),
(6381, 'Frank', 'Manage', 1900, '2010-1-3', 25000, 50000, '10');
SELECT * FROM `employee`;员工表效果如下 :

创建部门表的代码如下 :
CREATE TABLE IF NOT EXISTS `department`(
`dno` MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
`dname` VARCHAR(20) NOT NULL DEFAULT '',
`dloc` VARCHAR(20) NOT NULL DEFAULT ''
) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin ENGINE INNODB;
INSERT INTO `department`
VALUES(10, 'ADMINISTRATION', 'HONGKONG'), /*管理部门 */
(20, 'R&D', 'SUZHOU'), /*研发部门 */
(30, 'SALES', 'BEIJING'), /*销售部门 */
(40, 'FINANCE', 'NANJING'); /*财务部门 */
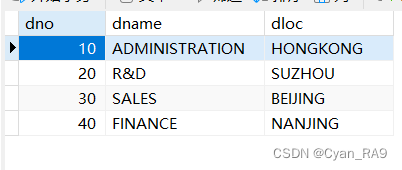
SELECT * FROM `department`;部门表效果如下 :
创建工资表的代码如下 :
CREATE TABLE IF NOT EXISTS `salary`(
`grade` MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
`lowsal` DECIMAL(20,2) NOT NULL,
`higsal` DECIMAL(20,2) NOT NULL
) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin ENGINE INNODB;
INSERT INTO `salary`
VALUES(1, 4500, 6500),
(2, 6500, 8500),
(3, 8500, 15000),
(4, 15000, 25000),
(5, 25000, 99999);
SELECT * FROM `salary`;
工资表效果如下 :

现要求——
①查询员工表中每个部门的平均工资和最高工资;
代码如下 :
SELECT AVG(`esalary`), MAX(`esalary`), `deptno`
FROM `employee`
GROUP BY `deptno`
ORDER BY `deptno`;查询效果 :

②查询员工表中每个部门每个岗位(工作) 的平均工资和最高工资;
代码如下 :
SELECT AVG(`esalary`), MAX(`esalary`), `deptno`, `ecareer`
FROM `employee`
GROUP BY `deptno`, `ecareer`
ORDER BY `deptno`; 查询结果 :

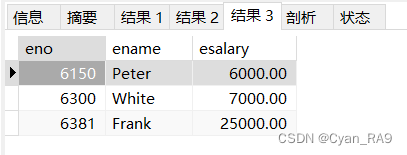
③查询平均工资低于15000的部门号及其平均工资;
代码如下 :
# 使用别名可以提高查询的效率
SELECT AVG(`esalary`) AS `avg_sal`, `deptno`
FROM `employee`
GROUP BY `deptno`
HAVING `avg_sal` < 15000
ORDER BY `deptno`;查询效果 :

二、分页查询
1.基本语法 :
SELECT ...
LIMIT start, rows;
注意事项——
1° LIMIT语句表示从(start + 1)行开始取,共取出rows行记录;其中,start从0开始计算。
2° start = 每页显示的行数 * (当前页码 - 1),但start必须是一个提前算出来的确切的结果,不可以是一个表达式,否则报错;
rows = 每页显示的行数 (记录数)。3° SELECT语句正常格式,LIMIT语句位于SELECT语句的末尾。
2.代码演示 :
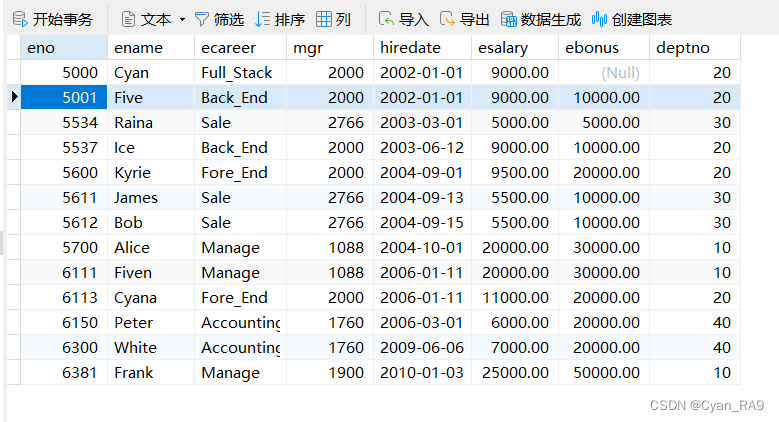
仍对employee, salary, department这三张表来进行操作,其中employee表如下 :
现要求——
查询出雇员编号大于5500的所有雇员的编号,姓名,和工资;并按照每页4条记录来分页展示。
# 第一页
SELECT `eno`, `ename`, `esalary` FROM `employee`
WHERE `eno` > 5500
LIMIT 0, 4;
# 第二页
SELECT `eno`, `ename`, `esalary` FROM `employee`
WHERE `eno` > 5500
LIMIT 4, 4;
# 第三页
SELECT `eno`, `ename`, `esalary` FROM `employee`
WHERE `eno` > 5500
LIMIT 8, 4;第一页 :

第二页 :

第三页 : (共查到11条编号大于5500的记录,每页四条记录,因此第三页只剩3条)
三、多表查询
1.定义 :
多表查询是指基于两个或两个以上的表的查询。在实际应用中,单表的查询往往无法满足需求,便考虑使用多表查询。
2.语法 :
1° 若直接SELECT * FROM table_1, table_2...;默认会对查询的多表进行笛卡尔积——即前一张表的每一条记录,都要和后一张表的每一条记录进行组合;一共返回的记录数 = 第一张表的记录数 * 第二张表的记录数 * ... * 第n张表的记录数。因此,多表查询的关键就是写出正确的过滤条件语句。
2° 利用WHERE条件语句,可以过滤掉无意义的记录,需要用到“表名.字段名”的格式,eg : employee.deptno = department.dno; PS : 多表查询中的条件不能少于表的个数 - 1,否则会出现笛卡尔积。
3° 若要指定查询的字段,要在查询时进行声明"SELECT column_1, column_2...",但要注意,若两个表中有相同的字段名,必须通过"表名.字段名"的格式来声明要查询的字段是哪个表中的,否则报错。
3.演示 :
演示Ⅰ—— 不采取过滤条件,直接查询多表
查询employee, department这两张表,如下 :
SELECT * FROM `employee`, `department`;
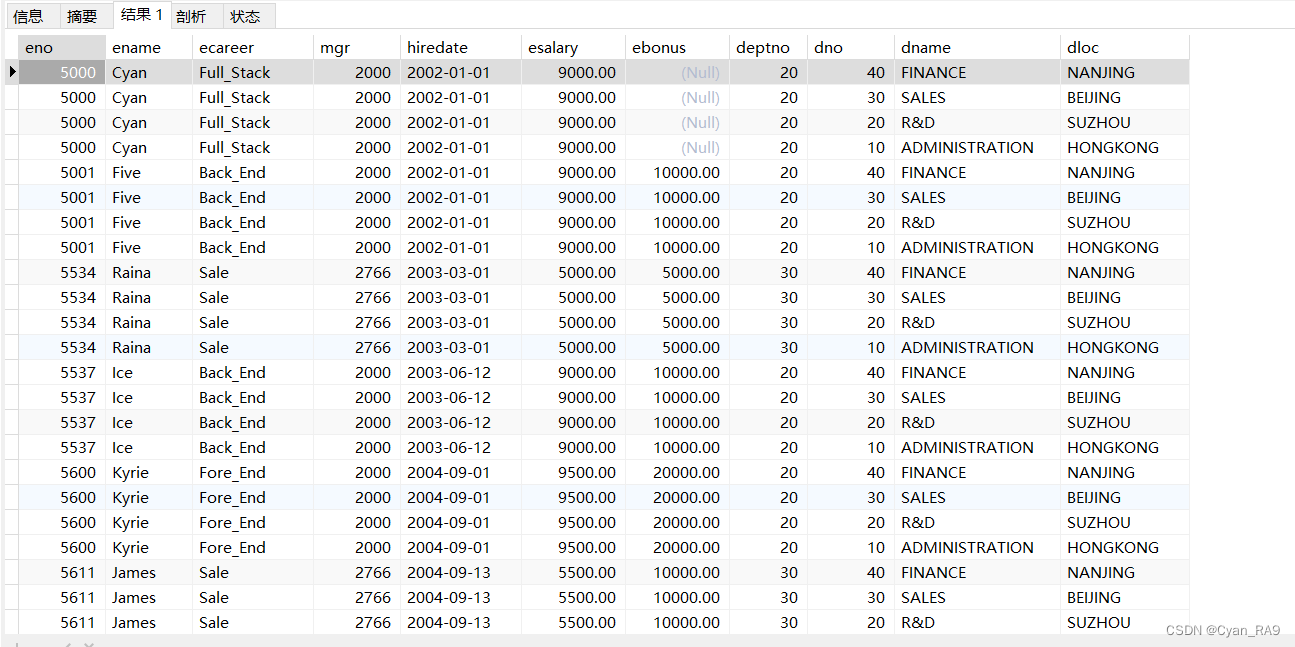
图片并没显示完全,可以通过COUNT(*) 函数来统计表中共有多少条记录,如下 :
SELECT COUNT(*) FROM `employee`, `department`;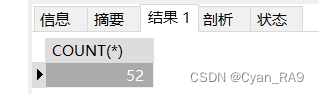
演示Ⅱ—— 采取过滤条件,剔除无效数据
增加过滤条件,要求两个表的部门号要相等,如下 :
SELECT * FROM `employee`, `department`
WHERE `employee`.deptno = `department`.dno;
演示Ⅲ—— 限定查询的列,精简查询结果
要求查询所有员工的员工号,员工姓名,员工的工资,员工的部门号以及对应部门的名称,如下 :
SELECT eno,ename,esalary,`employee`.deptno,`department`.dname
FROM `employee`, `department`
WHERE `employee`.deptno = `department`.dno
ORDER BY `deptno`;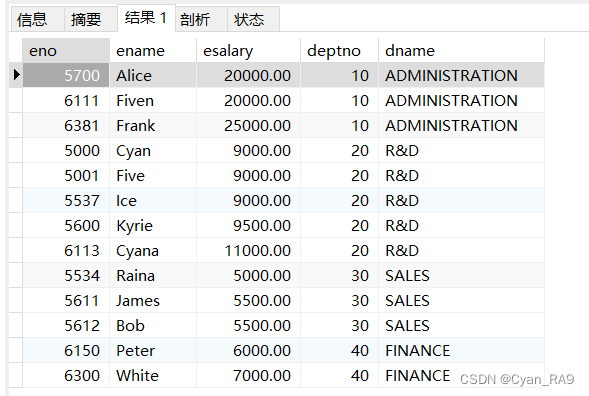
练习 —— 三张表的查询,要求剔除无效数据,指定查询字段
请查询出工资高于8000的员工的员工姓名,员工部门号及对应的部门名称,员工工资及对应的工资水平等级;并要求按照工资排序。如下 :
SELECT `ename`,`employee`.`deptno`,`department`.`dname`,`esalary`,`salary`.grade
FROM `employee`, `department`, `salary`
WHERE `employee`.`deptno` = `department`.`dno`
AND `employee`.`esalary` BETWEEN `salary`.`lowsal` AND `salary`.`higsal`
AND `employee`.`esalary` > 8000
ORDER BY `employee`.`esalary` ASC;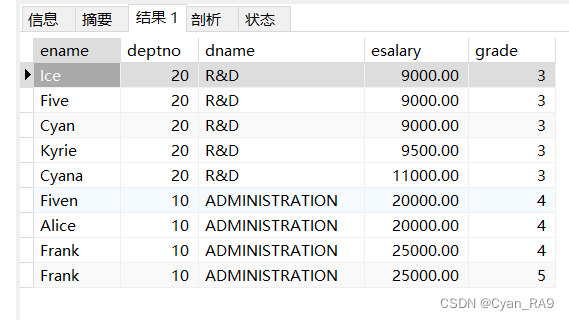
四、嵌套查询
1.定义 :
嵌套查询是指嵌入在其他SQL中SELECT语句,也称为子查询。根据查询返回的结果,又可分为单行子查询和多行子查询。
2.单行子查询 :
1° 特点
单行子查询是指只返回一行数据(一条记录)的子查询语句。
2° 演示
仍以employee表来操作,如下 :

现要求——
①查询与Cyan同一个部门的所有员工;
SELECT *
FROM `employee`
WHERE `deptno` = (
SELECT `deptno`
FROM `employee`
WHERE `ename` = 'Cyan'
);
3.多行子查询 :
1° 特点
多行子查询是指返回多行数据(多条记录)的子查询语句,需要使用IN,ALL或ANY关键字。
其中——
IN表示条件为在子查询查询到的范围内;
ALL表示条件为必须大于或小于(自己决定)子查询查询到的全部结果;
ANY表示条件为存在大于或小于子查询查询到的全部结果中的一个即可。
2° 演示
演示Ⅰ——IN关键字的使用
要求查询工作岗位属于20部门范畴的员工的姓名,工作岗位,以及工作部门的名称。
SELECT `ename`,`ecareer`,`dname`,`esalary`
FROM `employee`, `department`
WHERE `employee`.`deptno` = `department`.`dno`
AND `employee`.`ecareer` IN (
SELECT DISTINCT `ecareer`
FROM `employee`
WHERE `deptno` = 20
);
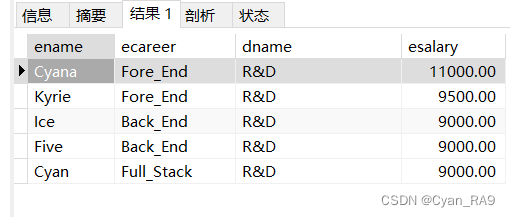
演示Ⅱ——ALL和ANY关键字的使用
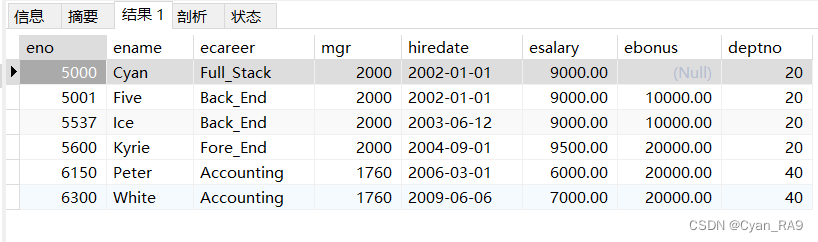
要求查询工资大于30部门所有员工的工资,并且小于20部门任一员工的工资的所有员工。如下 :
SELECT *
FROM `employee`
WHERE `esalary` > ALL(
SELECT `esalary`
FROM `employee`
WHERE `deptno` = 30
)
AND `esalary` < ANY(
SELECT `esalary`
FROM `employee`
WHERE `deptno` = 20
);
4.临时表 :
1° 定义
MySQL中,常常会将某个查询语句的结果作为一张临时表,来与其他表进行连接操作,以更轻松地完成查询需求。
格式如下 :
SELECT column_n...
FROM (
SELECT... # 子查询语句
) 临时表表名, 其他表表名
WHERE...;
2° 演示
要求查询出员工表中各个部门工资最高的员工。(即最终要求查出的所有字段都必须是员工表中已经存在的)
/*
1.先利用嵌套查询得知每个部门中最高工资具体是多少,作为临时表;
2.然后利用多表查询,只要临时表中每条记录的部门号和员工表中的某位
员工的部门号相同,并且该条记录的最高工资和某位员工的工资相等,
就可以找到该员工。相应地,就可以找到各个部分中工资最高的员工。
*/
SELECT `eno`,`ename`,`esalary`, employee.`deptno`
FROM (
SELECT MAX(`esalary`) AS max_sal, `deptno`
FROM `employee`
GROUP BY `deptno`
ORDER BY `deptno` ASC
) temp, `employee`
WHERE temp.`deptno` = `employee`.deptno
AND temp.max_sal = `employee`.esalary
ORDER BY employee.`deptno` ASC;
5.多列子查询 :
1° 定义
多列子查询指返回多个字段的数据的子查询语句。
注意:
多列子查询在定义上不同于单行子查询和多行子查询,因为多列子查询并不要求返回结果的行数(记录数),而是返回结果的列数(字段数),因此,多列子查询的返回结果既可以是单行的也可以是多行的;并且,嵌套查询的最终目的是服务于主查询语句,因此,多列子查询最终的目的就是对主查询语句中的多个字段进行限制。
格式如下 :
SELECT * / column_n...
FROM table_name
WHERE (column_1,column_2...) = (
SELECT... # 子查询语句
);
2° 演示
仍然操作员工表,如下 :

要求查询与James同一部门且同一岗位的员工,并且查询结果中排除James自己。
SELECT *
FROM `employee`
WHERE (`ecareer`, `deptno`) = (
SELECT `ecareer`, `deptno`
FROM `employee`
WHERE `ename` = 'James'
) AND `ename` != 'James';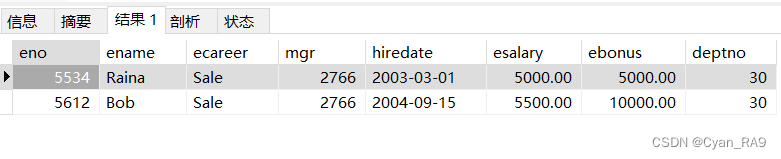
五、合并查询
1.概述 :
某些情况下,需要合并多个SELECT语句的结果。这时可以用到UNION和UNION ALL。
注意事项——
①UNION ALL可以对多个SELECT语句的结果取并集,并且不会去重;②UNION的作用与UNION ALL 相同,但UNION会对查询到的记录进行去重操作。
2.演示 :
仍然操作员工表,如下 :

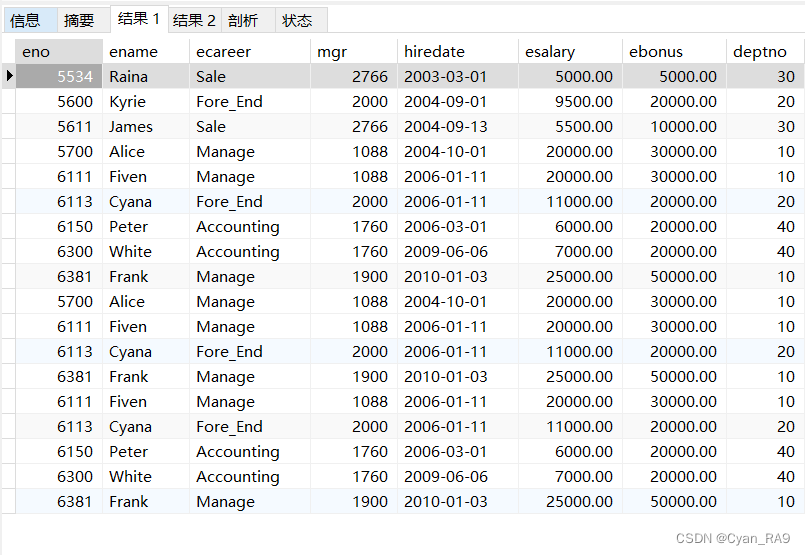
现要求,分别统计——
①员工姓名不小于五个字符长度的所有员工;
②员工工资高于10000的所有员工;
③员工编号不小于6000的所有员工;
要求对统计得到的结果分别使用不去重合并和去重合并进行整理。
代码如下 :
SELECT * FROM `employee` WHERE LENGTH(`ename`) >= LENGTH('.....')
UNION ALL
SELECT * FROM `employee` WHERE `esalary` > 10000
UNION ALL
SELECT * FROM `employee` WHERE `eno` >= 6000;
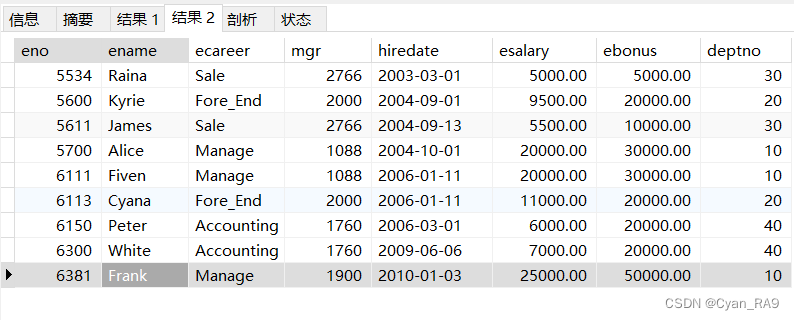
SELECT * FROM `employee` WHERE LENGTH(`ename`) >= LENGTH('.....')
UNION
SELECT * FROM `employee` WHERE `esalary` > 10000
UNION
SELECT * FROM `employee` WHERE `eno` >= 6000;查询结果 :
System.out.println("END---------------------------------------------------------------------------");