C++判断大端小端
1. 基础知识
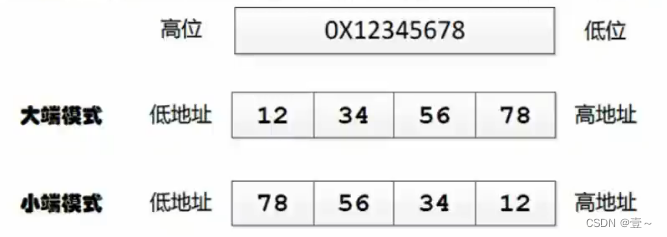
大端小端其实表示的是数据在存储器中的存放顺序。
大端模式:数据的高字节存放在内存的低地址中,而低字节则存放在高地址中。地址由小到大增加,数据则从高位向低位存放,这种存放方式符合人类的正常思维。
小端模式:数据的高字节存放在内存的高地址中,而数据的低字节存放在低地址中。这种存储模式将地址的高低和数据位权结合起来,高地址部分权值高,低地址部分权值低,符合计算机的运算。
总结:采用大小模式对数据进行存放的主要区别在于字节的存放顺序,大端方式将高位存放在低地址,小端方式将高位存放在高地址。
2. 判断大小端的多种方法
- 使用联合体:
#include <stdio.h>
union endian {
int i;
char c[4];
}u;
int is_big_endian() {
u.i = 1;
return (u.c[0] == 0);
}
int main(){
if (is_big_endian()) {
printf("This is a big-endian machine\n");
} else {
printf("This is a little-endian machine\n");
}
return 0;
}
联合体里的数据会共用一片内存,所占空间大小由最大的那个数据和内存对齐方式决定。如上面代码所示,联合体u的大小为4个字节。
当执行is_big_endian()时,u.i = 1则u.i = 0x00000001,因为联合体内的数据共用一片内存,所以当我们访问u.c时,u.c里存放的也是0x00000001。
当系统采用的是大端存储时,则在系统中是按照0x00000001存储,所以u.c[0]=0x00,也就是0。
当系统采用的是小端存储时,则在系统中是按照0x01000000存储,所以u.c[0]=0x01,也就是1。
- 使用位运算判断:
#include <stdio.h>
int is_big_endian() {
int i = 1;
return (*(char*)&i == 0);
}
int main(){
if (is_big_endian()) {
printf("This is a big-endian machine\n");
} else {
printf("This is a little-endian machine\n");
}
return 0;
}
is_big_endian()中的 i 也是四个字节,当执行int i = 1时,i = 0x00000001,&i 表示 i 的引用,也就是取 i 的地址,(char*)&i 表示把 i 强转成 char* 类型。
当系统采用大端存储时,i 是按照0x00000001存储的,所以 *(char*)&i 指向的内容是 i 的第一个字节,也就是0x00,就是0。
当系统采用大端存储时,i 是按照0x01000000存储的,所以 *(char*)&i 指向的内容是 i 的第一个字节,也就是0x01,就是1。
- 使用预定义的宏:
在宏中判断大小端可以使用预定义宏,在C语言中可以使用__BYTE_ORDER__宏来获取当前机器的字节序。__BYTE_ORDER__是C语言标准库中提供的一个预定义宏,可以用来判断当前机器的字节序。如果值为__ORDER_LITTLE_ENDIAN__,表示当前机器为小端字节序,如果值为__ORDER_BIG_ENDIAN__,则表示当前机器为大端字节序。
例如,可以使用以下的宏定义来判断大小端:
#if __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__
#define LITTLE_ENDIAN
#elif __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
#define BIG_ENDIAN
#else
#error "Unknown byte order"
#endif
这里我们使用了预定义宏__BYTE_ORDER__来判断大小端,如果是小端则定义LITTLE_ENDIAN宏,如果是大端则定义BIG_ENDIAN宏,否则报错。
在程序中使用宏进行大小端判断时,可以根据定义的宏来进行判断。例如:
#if defined(LITTLE_ENDIAN)
// 代码片段
#elif defined(BIG_ENDIAN)
// 代码片段
#endif
这样,我们就可以编写跨平台的代码,支持不同的字节序。