1 数据模型
我们以风电场物联网场景为例,说明如何在IoTDB中创建一个正确的数据模型。
根据企业组织结构和设备实体层次结构,我们将其物联网数据模型表示为如下图所示的属性层级组织结构,即电力集团层-风电场层-实体层-物理量层。
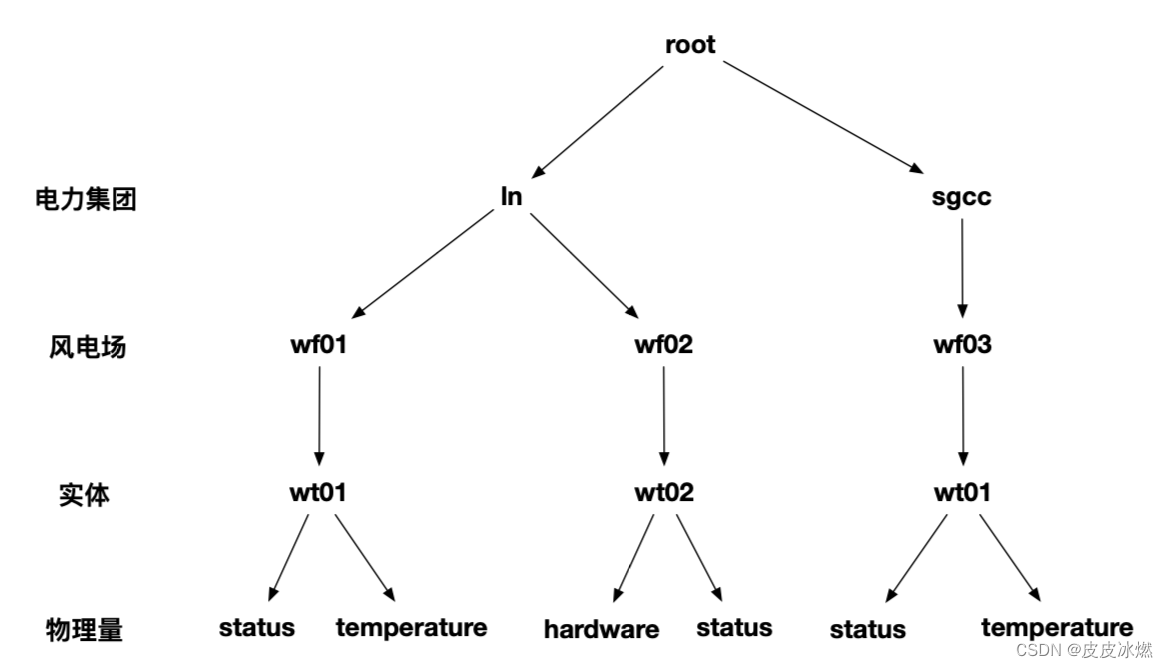
其中ROOT为根节点,物理量层的每一个节点为叶子节点。
IoTDB采用树形结构定义数据模式,以从ROOT节点到叶子节点的路径来命名一个时间序列,层次间以“.”连接。
例如,上图最左侧路径对应的时间序列名称为ROOT.ln.wf01.wt01.status。
在上图所描述的实际场景中,有许多实体所采集的物理量相同,即具有相同的工况名称和类型,因此,可以声明一个元数据模板来定义可采集的物理量集合。在实践中,元数据模板的使用可帮助减少元数据的资源占用。
1.1 物理量(Measurement)
物理量,也称工况或字段(field),是在实际场景中检测装置所记录的测量信息,且可以按一定规律变换成为电信号或其他所需形式的信息输出并发送给IoTDB。
在IoTDB当中,存储的所有数据及路径,都是以物理量为单位进行组织。
1.2 实体(Entity)
一个物理实体,也称设备(device),是在实际场景中拥有物理量的设备或装置。在IoTDB当中,所有的物理量都有其对应的归属实体。
1.3 数据库(Database)
用户可以将任意前缀路径设置成数据库。
如有4条时间序列:
root.ln.wf01.wt01.status,
root.ln.wf01.wt01.temperature,
root.ln.wf02.wt02.hardware,
root.ln.wf02.wt02.status。
路径root.ln下的两个实体wt01, wt02可能属于同一个业主,或者同一个制造商,这时候就可以将前缀路径root.ln指定为一个数据库。未来root.ln下增加了新的实体,也将属于该数据库。
一个database中的所有数据会存储在同一批文件夹下,不同database的数据会存储在磁盘的不同文件夹下,从而实现物理隔离。
(1)注意1:不允许将一个完整路径(如上例的root.ln.wf01.wt01.status))设置成database。
(2)注意2:一个时间序列其前缀必须属于某个database。在创建时间序列之前,用户必须设定该序列属于哪个database。只有设置了database的时间序列才可以被持久化在磁盘上。
(3)注意3:被设置为数据库的路径总字符数不能超过64,包括路径开头的root.这5个字符。
(4)注意4:一个前缀路径一旦被设定成database后就不可以再更改这个database的设定。
(5)注意5:一个database设定后,其对应的前缀路径的祖先层级与孩子及后裔层级也不允许再设置database。
例如root.ln设置database后,root层级与root.ln.wf01不允许被设置为 database。
(6)注意6:Database节点名只支持中英文字符、数字和下划线的组合。
例如root.数据库_1 。
1.4 路径(Path)
路径(path)是指符合以下约束的表达式:
path
: nodeName ('.' nodeName)*
;
nodeName
: wildcard? identifier wildcard?
| wildcard
;
wildcard 通配符
: '*'
| '**'
;
我们称一个路径中由'.'分割的部分叫做路径结点名(nodeName)。
例如:root.a.b.c为一个层级为4的路径。
下面是对路径结点名(nodeName)的约束:
(1)约束1:root作为一个保留字符,它只允许出现在下文提到的时间序列的开头,若其他层级出现root,则无法解析,提示报错。
(2)约束2:除了时间序列的开头的层级(root)外,其他的层级支持的字符如下:
[ 0-9 a-z A-Z _ ] (字母,数字,下划线)
['\u2E80'..'\u9FFF'] (UNICODE 中文字符)
(3)约束3:如果系统在Windows系统上部署,那么database路径结点名是大小写不敏感的。例如,同时创建root.ln和root.LN是不被允许的。
(4)约束4:如果需要在路径结点名中用特殊字符,可以用反引号引用路径结点名,具体使用方法可以参考语法约定。
1.5 路径模式(Path Pattern)
为了使得在表达多个时间序列的时候更加方便快捷,IoTDB为用户提供带通配符*或**的路径。用户可以利用两种通配符构造出期望的路径模式。通配符可以出现在路径中的任何层。
(1)*在路径中表示一层。
例如root.vehicle.*.sensor1代表的是
以root.vehicle为前缀,以sensor1为后缀,层次等于4层的路径。
(2)**在路径中表示是(*)+,即为一层或多层*。
例如root.vehicle.device1.**代表的是
root.vehicle.device1.*,
root.vehicle.device1.*.*,
root.vehicle.device1.*.*.*
等所有以root.vehicle.device1为前缀路径的大于等于4层的路径;
例如root.vehicle.**.sensor1代表的是
以root.vehicle为前缀,以sensor1为后缀,层次大于等于4层的路径。
(3)注意:*和**不能放在路径开头。
1.6 时间序列(Timeseries)
(1)时间戳 (Timestamp)
时间戳是一个数据到来的时间点,其中包括绝对时间戳和相对时间戳。
(2)数据点(Data Point)
一个“时间戳-值”对。
(3)时间序列(Timeseries)
一个物理实体的某个物理量在时间轴上的记录,是数据点的序列。
一个实体的一个物理量对应一个时间序列,即实体+物理量=时间序列。
时间序列也被称测点(meter)、时间线(timeline),实时数据库中常被称作标签(tag)、参数(parameter)。
例如,ln电力集团、wf01风电场的实体wt01有名为status的物理量,则它的时间序列可以表示为:root.ln.wf01.wt01.status。
1.7 对齐时间序列(Aligned Timeseries)
在实际应用中,存在某些实体的多个物理量同时采样,形成一组时间列相同的时间序列,这样的一组时间序列在Apache IoTDB中可以建模为对齐时间序列。
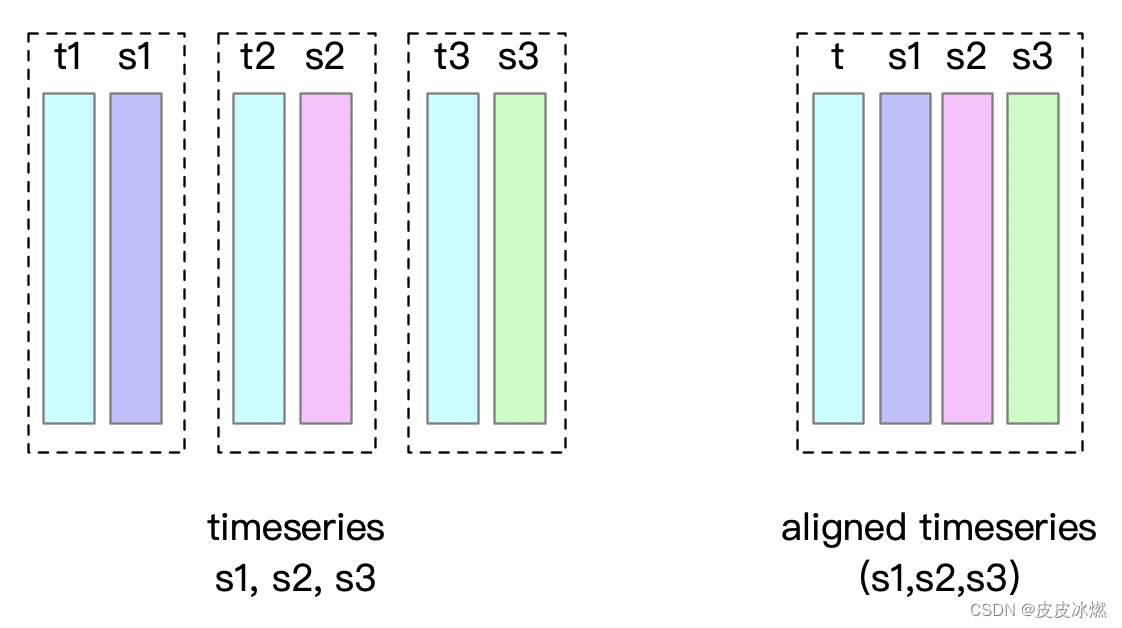
(1)在插入数据时,一组对齐序列的时间戳列在内存和磁盘中仅需存储一次,而不是每个时间序列存储一次。
(2)对齐的一组时间序列最好同时创建。
(3)不可以在对齐序列所属的实体下创建非对齐的序列,不可以在非对齐序列所属的实体下创建对齐序列。
(4)查询数据时,可以对于每一条时间序列单独查询。
(5)插入数据时,对齐的时间序列中某列的某些行允许有空值。
2 元数据模板(Schema template)
2.1 概念
一、问题背景
对于大量的同类型的实体,每一个实体下的物理量都相同,为每个序列注册时间序列一方面时间序列的元数据将占用较多的内存资源,另一方面,大量序列的维护工作也会十分复杂。
为了实现同类型不同实体的物理量元数据共享,减少元数据内存占用,同时简化同类型实体的管理,IoTDB引入元数据模板功能。
一个燃油车场景的数据模型,各地区的多台燃油车的速度、油量、加速度、角速度四个物理量将会被采集,显然这些燃油车实体具备相同的物理量。
二、概念定义
元数据模板(Schema template)
实际应用中有许多实体所采集的物理量相同,即具有相同的工况名称和类型,可以声明一个元数据模板来定义可采集的物理量集合。
将元数据模版挂载在树形数据模式的任意节点上,表示该节点下的所有实体具有相同的物理量集合。
目前每一条路径节点仅允许挂载一个元数据模板,即当一个节点被挂载元数据模板后,它的祖先节点和后代节点都不能再挂载元数据模板。实体将使用其自身或祖先的元数据模板作为有效模板。
特别需要说明的是,挂载模板与使用模板的概念不同。一个节点挂载模板后,其所有后代节点都可以使用这个模板,因此可以通过向同类实体的祖先节点挂载模板来简化操作。当系统向挂载模板的节点(或其后代节点)插入模板中定义的物理量时,这个节点就被设置为“正在使用模板”。
使用元数据模板后,所有的物理量元数据仅在模板中保存一份,所有的实体共享模板中的元数据。
三、生命周期
了解元数据的生命周期及相关名词,有助于更顺畅地使用元数据模板。在描述这一概念时,有六个关键词分别指向特定的过程,分别是“创建”、“挂载”、“激活”、“解除”、“卸载”、和“删除”。下图展示了一个模板从创建、挂到删除的全部过程。当用户操作执行其中任一过程时,系统都会执行对应条件检查,如条件检查通过,则操作成功,否则,操作会被拒绝:
(1)创建模板时,检查确认正在创建的模板名称与所有已存在的模板不重复;
(2)在某节点挂载模板,需检查该节点的所有祖先节点与子孙节点,确认均未挂载任何模板;
(3)在某节点激活模板,需检查确认该节点或其祖先已挂载对应模板,且该节点下不存在与模板中同名的物理量;
(4)在某节点解除模板时,需确认该节点已经激活了模板,请注意,解除模板会删除该节点通过模板实例化的物理量及其数据点;
(5)在某节点卸载模板时,需检查确认该节点曾挂载该模板,且其所有子孙节点均不处于模板激活状态;
(6)删除模板时,需检查确认模板没有挂载在任何一个节点上。
最后需要补充的是,对挂载模板与激活模板进行区分,是为了服务一种常见的场景:在 Apache IoTDB 元数据模型 MTree 中,经常需要在数量众多的节点上“应用”元数据模板,而这些节点一般拥有共同的祖先节点。因此,可以在其共同祖先节点挂载模板,而不必对其大量的孩子节点进行挂载操作。对于需要“应用”模板的节点,则应该使用激活模板的操作。
2.2 使用
目前,用户可以通过Session编程接口或IoTDB-SQL来使用元数据模板,包括模板的创建、修改、挂载与卸载等。Session编程接口的详细文档可参见此处,IoTDB-SQ 的详细文档可参加此处。下文将以 Session 中使用方法为例,进行简要介绍。
2.2.1 创建元数据模板
在 Session 中创建元数据模板,可以通过先后创建 Template、MeasurementNode 的对象,构造模板内部物理量结构,并通过以下接口创建模板。
public void createSchemaTemplate(Template template);
Class Template {
private String name;
private boolean directShareTime;
Map<String, Node> children;
public Template(String name, boolean isShareTime);
public void addToTemplate(Node node);
public void deleteFromTemplate(String name);
public void setShareTime(boolean shareTime);
}
Abstract Class Node {
private String name;
public void addChild(Node node);
public void deleteChild(Node node);
}
Class MeasurementNode extends Node {
TSDataType dataType;
TSEncoding encoding;
CompressionType compressor;
public MeasurementNode(String name,
TSDataType dataType,
TSEncoding encoding,
CompressionType compressor);
}
2.2.2 构造元数据模板
构造上图中的元数据模板,并挂载到对应节点,可参考如下代码。请注意,我们强烈建议您将模板设置在 database 或 database 下层的节点中,以更好地适配未来地更新及各模块的协作。
MeasurementNode nodeV = new MeasurementNode("velocity", TSDataType.FLOAT, TSEncoding.RLE, CompressionType.SNAPPY);
MeasurementNode nodeF = new MeasurementNode("fuel_amount", TSDataType.FLOAT, TSEncoding.RLE, CompressionType.SNAPPY);
MeasurementNode nodeA = new MeasurementNode("acceleration", TSDataType.DOUBLE, TSEncoding.GORILLA, CompressionType.SNAPPY);
MeasurementNode nodeAng = new MeasurementNode("angular_velocity", TSDataType.DOUBLE, TSEncoding.GORILLA, CompressionType.SNAPPY);
Template template = new Template("template");
template.addToTemplate(nodeV);
template.addToTemplate(nodeF);
template.addToTemplate(nodeA);
template.addToTemplate(nodeAng);
createSchemaTemplate(template);
setSchemaTemplate("template", "root.Beijing");
挂载元数据模板后,即可进行数据的写入。如按上述代码创建并挂载模板,并在 root.Beijing 路径上设置了 database 后,即可写入例如 root.Beijing.petro_vehicle.velocity 等时间序列数据,系统将自动创建 petro_vehicle 节点,并设置其“正在使用模板”,对写入数据应用模板中为 velocity 定义的元数据信息。
3 数据类型
3.1 基本数据类型
IoTDB一共支持六种数据类型:
BOOLEAN(布尔值)
INT32(整型)
INT64(长整型)
FLOAT(单精度浮点数)
DOUBLE(双精度浮点数)
TEXT(字符串)
其中FLOAT与DOUBLE类型的序列,如果编码方式采用RLE或TS_2DIFF可以指定MAX_POINT_NUMBER,该项为浮点数的小数点后位数,若不指定则系统会根据配置文件iotdb-datanode.properties文件中的float_precision项配置。
当系统中用户输入的数据类型与该时间序列的数据类型不对应时,系统会提醒类型错误。
3.2 时间戳类型
时间戳是一个数据到来的时间点,其中包括绝对时间戳和相对时间戳。
3.2.1 绝对时间戳
IOTDB中绝对时间戳分为二种,一种为LONG类型,一种为DATETIME 类型(包含 DATETIME-INPUT, DATETIME-DISPLAY 两个小类)。
在用户在输入时间戳时,可以使用 LONG 类型的时间戳或 DATETIME-INPUT 类型的时间戳,其中 DATETIME-INPUT 类型的时间戳支持格式如表所示:
一、DATETIME-INPUT类型支持格式
yyyy-MM-dd HH:mm:ss
yyyy/MM/dd HH:mm:ss
yyyy.MM.dd HH:mm:ss
yyyy-MM-dd HH:mm:ssZZ
yyyy/MM/dd HH:mm:ssZZ
yyyy.MM.dd HH:mm:ssZZ
yyyy/MM/dd HH:mm:ss.SSS
yyyy-MM-dd HH:mm:ss.SSS
yyyy.MM.dd HH:mm:ss.SSS
yyyy-MM-dd HH:mm:ss.SSSZZ
yyyy/MM/dd HH:mm:ss.SSSZZ
yyyy.MM.dd HH:mm:ss.SSSZZ
ISO8601 standard time format
IoTDB 在显示时间戳时可以支持 LONG 类型以及 DATETIME-DISPLAY 类型,其中 DATETIME-DISPLAY 类型可以支持用户自定义时间格式。
二、DATETIME-DISPLAY自定义时间格式的语法
Symbol Meaning Presentation Examples
G era era era
C century of era (>=0) number 20
Y year of era (>=0) year 1996
x weekyear year 1996
w week of weekyear number 27
e day of week number 2
E day of week text Tuesday; Tue
y year year 1996
D day of year number 189
M month of year month July; Jul; 07
d day of month number 10
a halfday of day text PM
K hour of halfday(0~11) number 0
h clockhour of halfday(1~12) number 12
H hour of day (0~23) number 0
k clockhour of day (1~24) number 24
m minute of hour number 30
s second of minute number 55
S fraction of second millis 978
z time zone text Pacific Standard Time; PST
Z time zone offset/id zone -0800; -08:00; America/Los_Angeles
' escape for text delimiter
'' single quote literal '
3.2.2 相对时间戳
相对时间是指与服务器时间now()和DATETIME类型时间相差一定时间间隔的时间。
形式化定义为:
Duration = (Digit+ ('Y'|'MO'|'W'|'D'|'H'|'M'|'S'|'MS'|'US'|'NS'))+
RelativeTime = (now() | DATETIME) ((+|-) Duration)+
Symbol Meaning Presentation Examples
y year 1y=365 days 1y
mo month 1mo=30 days 1mo
w week 1w=7 days 1w
d day 1d=1 day 1d
h hour 1h=3600 seconds 1h
m minute 1m=60 seconds 1m
s second 1s=1 second 1s
ms millisecond 1ms=1000_000 nanoseconds 1ms
us microsecond 1us=1000 nanoseconds 1us
ns nanosecond 1ns=1 nanosecond 1ns
例如
now() - 1d2h //比服务器时间早 1 天 2 小时的时间
now() - 1w //比服务器时间早 1 周的时间
注意:'+'和'-'的左右两边必须有空格
4 编码方式
4.1 基本编码方式
为了提高数据的存储效率,需要在数据写入的过程中对数据进行编码,从而减少磁盘空间的使用量。在写数据以及读数据的过程中都能够减少I/O操作的数据量从而提高性能。IoTDB支持多种针对不同类型的数据的编码方法:
一、PLAIN编码(PLAIN)
PLAIN编码,默认的编码方式,即不编码,支持多种数据类型,压缩和解压缩的时间效率较高,但空间存储效率较低。
二、二阶差分编码(TS_2DIFF)
二阶差分编码,比较适合编码单调递增或者递减的序列数据,不适合编码波动较大的数据。
三、游程编码(RLE)
游程编码,比较适合存储某些数值连续出现的序列,不适合编码大部分情况下前后值不一样的序列数据。
游程编码也可用于对浮点数进行编码,但在创建时间序列的时候需指定保留小数位数(MAX_POINT_NUMBER,具体指定方式参见本文 SQL 参考文档)。比较适合存储某些浮点数值连续出现的序列数据,不适合存储对小数点后精度要求较高以及前后波动较大的序列数据。
游程编码(RLE)和二阶差分编码(TS_2DIFF)对float和double的编码是有精度限制的,默认保留2位小数。推荐使用GORILLA。
四、GORILLA 编码(GORILLA)
GORILLA编码是一种无损编码,它比较适合编码前后值比较接近的数值序列,不适合编码前后波动较大的数据。
当前系统中存在两个版本的 GORILLA 编码实现,推荐使用GORILLA,不推荐使用GORILLA_V1(已过时)。
使用限制:使用 Gorilla 编码 INT32 数据时,需要保证序列中不存在值为Integer.MIN_VALUE的数据点;使用 Gorilla 编码 INT64 数据时,需要保证序列中不存在值为Long.MIN_VALUE的数据点。
五、字典编码 (DICTIONARY)
字典编码是一种无损编码。它适合编码基数小的数据(即数据去重后唯一值数量小)。不推荐用于基数大的数据。
六、频域编码(FREQ)
频域编码是一种有损编码,它将时序数据变换为频域,仅保留部分高能量的频域分量。该编码适合于具有明显周期性的数据。
频域编码在配置文件中包括两个参数:freq_snr指定了编码的信噪比,该参数增大会同时降低压缩比和精度损失;freq_block_size指定了编码进行时频域变换的分组大小,推荐不对默认值进行修改。参数影响的实验结果和分析详见设计文档。
七、ZIGZAG编码
ZigZag编码将有符号整型映射到无符号整型,适合比较小的整数。
4.2 数据类型与编码的对应关系
前文介绍的七种编码适用于不同的数据类型,若对应关系错误,则无法正确创建时间序列。数据类型与支持其编码的编码方式对应关系总结如表格。
数据类型 支持的编码
BOOLEAN PLAIN, RLE
INT32 PLAIN, RLE, TS_2DIFF, GORILLA, FREQ, ZIGZAG
INT64 PLAIN, RLE, TS_2DIFF, GORILLA, FREQ, ZIGZAG
FLOAT PLAIN, RLE, TS_2DIFF, GORILLA, FREQ
DOUBLE PLAIN, RLE, TS_2DIFF, GORILLA, FREQ
TEXT PLAIN, DICTIONARY
5 压缩方式
当时间序列写入并按照指定的类型编码为二进制数据后,IoTDB会使用压缩技术对该数据进行压缩,进一步提升空间存储效率。
虽然编码和压缩都旨在提升存储效率,但编码技术通常只适合特定的数据类型(如二阶差分编码只适合与INT32或者INT64编码,存储浮点数需要先将他们乘以10m以转换为整数),然后将它们转换为二进制流。压缩方式(SNAPPY)针对二进制流进行压缩,因此压缩方式的使用不再受数据类型的限制。
一、基本压缩方式
IoTDB允许在创建一个时间序列的时候指定该列的压缩方式。
现阶段IoTDB支持以下几种压缩方式:
UNCOMPRESSED(不压缩)
SNAPPY 压缩
LZ4 压缩
GZIP 压缩
二、压缩比统计信息
压缩比统计信息文件:
data/system/compression_ratio/Ratio-{ratio_sum}-{memtable_flush_time}
ratio_sum: memtable压缩比的总和
memtable_flush_time: memtable刷盘的总次数
通过 ratio_sum / memtable_flush_time 可以计算出平均压缩比
![[附源码]计算机毕业设计JAVA校园期刊网络投稿系统](https://img-blog.csdnimg.cn/c8d304ba0f1247fb80e236c77d4ad29f.png)