K8s in Action 阅读笔记——【3】Pods: running containers in Kubernetes
3.1 Introducing pods
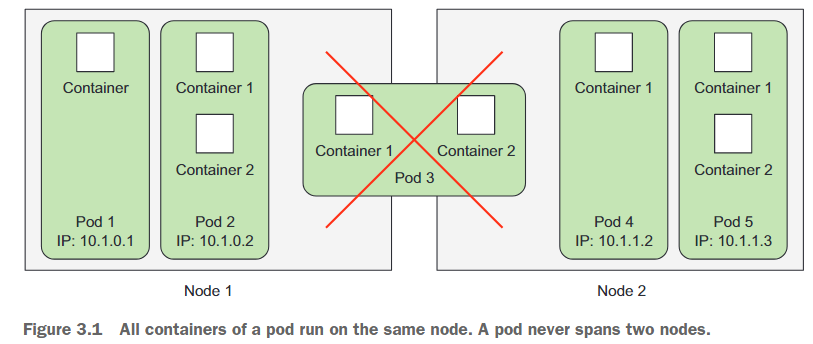
在Kubernetes中,Pod是基本构建块之一,由容器集合组成。与独立部署容器不同,你总是要部署和操作一个Pod。Pod并不总是包含多个容器,仅包含一个容器也很常见。Pod的关键在于,当确实包含多个容器时,所有这些容器都在同一工作节点上运行,而不会跨越多个节点(见图3.1)。
3.1.1 Understanding why we need pods
为什么我们需要Pod呢?我们不能直接使用容器吗?我们为什么需要同时运行多个容器?难道我们不能将所有进程放入一个容器中吗?现在来回答这些问题。
想象一个由多个进程组成的应用程序,它们通过IPC(进程间通信)或通过本地存储的文件进行通信,这需要它们在同一台机器上运行。因为在Kubernetes中你总是在容器中运行进程,每个容器就像一个隔离的机器,所以你可能认为在一个单一容器中运行多个进程是有意义的,但你不应该这样做。容器的设计是为了每个容器只运行一个进程(除非该进程本身生成子进程)。如果你在一个单一容器中运行多个不相关的进程,那么你需要负责保持所有这些进程的运行、管理它们的日志等。例如,你需要包含一个机制,以便在进程崩溃时自动重启各个进程。另外,所有这些进程都会记录到相同的标准输出,因此你可能很难确定哪个进程记录了什么信息。
因此,你需要在每个容器中运行各自的进程,这是Docker和Kubernetes的使用方式。
3.1.2 Understanding pods
不应将多个进程组合到一个容器中,因此需要另一个高级结构来绑定容器并将它们作为单个单元进行管理,这就是Pod为何存在。Pod允许你运行相关的进程,它们提供(几乎)相同的环境,就像它们在单个容器中运行一样,同时保持一定隔离。这种方式可以充分发挥容器提供的所有功能,同时让进程看起来一起运行,是一种折中方案。
了解同一POD容器之间的部分隔离
在先前的章节中,你了解到容器是完全隔离的,但是现在你却希望隔离一组容器而不是一个一个隔离。你希望每个组内的容器共享某些资源,但并不是全部共享,以便它们并不是完全隔离的。Kubernetes通过配置Docker使Pod的所有容器共享同一组Linux命名空间来实现这一点,而不是每个容器各自拥有一组命名空间。
因为Pod的所有容器都在同一网络和``UTS-namespace下运行(我们在这里讨论的是Linux命名空间),所以它们都共享相同的主机名和网络接口。同样地,Pod的所有容器都在同一IPC-namespace下运行,可以通过IPC进行通信。在最新的Kubernetes和Docker版本中,它们还可以共享相同的PID-namespace`,但这个功能不是默认启用的。
但就文件系统而言,情况有些不同。由于大多数容器文件系统来自容器镜像,默认情况下,每个容器的文件系统都是完全隔离的。但是,可以使用Kubernetes中的一个叫做Volume的概念来共享文件目录。
了解容器如何共享相同的IP和端口空间
这里要强调的一点是,因为 Pod 中的容器运行在相同的网络命名空间中,它们共享相同的 IP 地址和端口空间。这意味着运行在同一 Pod 的容器中的进程需要小心不要绑定到相同的端口号,否则它们会遇到端口冲突。但这只涉及相同 Pod 中的容器。不同 Pod 的容器永远不会遇到端口冲突,因为每个 Pod 都有独立的端口空间。所有 Pod 中的容器也都有相同的回环网络接口,因此容器可以通过本地主机与同一 Pod 中的其他容器通信。
扁平POD间网络简介
Kubernetes 集群中的所有 Pod 均驻留在单一、共享的扁平网络地址空间中(如图3.2所示),这意味着每个 Pod 都可以以另一个 Pod 的 IP 地址访问任何其他 Pod。它们之间不存在 NAT (网络地址转换)网关。当两个 Pod 之间发送网络数据包时,它们将分别将另一个 Pod 的实际 IP 地址视为数据包中的源 IP。

因此,Pod 之间的通信非常简便。无论两个 Pod 是被调度到一个工作节点还是不同的工作节点,这些 Pod 中的容器都可以像局域网(LAN)上的计算机一样,在没有 NAT 的扁平网络中相互通信,无论实际的节点间网络拓扑如何。像在 LAN 上的计算机一样,每个 Pod 都拥有自己的 IP 地址,并且可以通过专门为 Pod 建立的网络与其他所有 Pod 通信。这通常是通过在实际网络之上运行的另一个软件定义网络来实现的。
3.1.3 Organizing containers across pods properly
将多层应用程序分解为多个 Pod
尽管将前端服务器和数据库置于一个容器数为2的 Pod 中运行没有问题,但这并不是最佳实践。我们前面已经提到,同一 Pod 中的所有容器总是在同一位置运行,但 Web 服务器和数据库真的需要在同一台主机上运行吗?很明显不需要,因此它们不应该放在同一 Pod 中。
如果将前端和后端都放在同一个 Pod,那么它们将永远在同一台主机上运行。如果你的 Kubernetes 集群有两个节点,且只有该 Pod,那么你将只使用一个工作节点,并未充分利用第二个节点上可用的计算资源(CPU 和内存)。将 Pod 分成两个可以使 Kubernetes 将前端和后端分别调度到不同的节点上,从而提高基础设施的利用率。
拆分成多个Pod以实现单独扩展
Pod 是扩展的基本单元。Kubernetes 无法水平扩展单个容器,而是扩展整个 Pod。如果 Pod 包含前端和后端容器,当将Pod 的实例数量扩展到两个时,会得到两个前端容器和两个后端容器。
通常来说,前端组件与后端完全不同,因此我们倾向于将它们分别进行扩展。另外,后端如数据库通常比上下文无关(无状态)的前端 Web 服务器难以扩展。如果需要单独扩展容器,则明显表明它需要部署到一个单独的 Pod 中。
了解何时在POD中使用多个容器
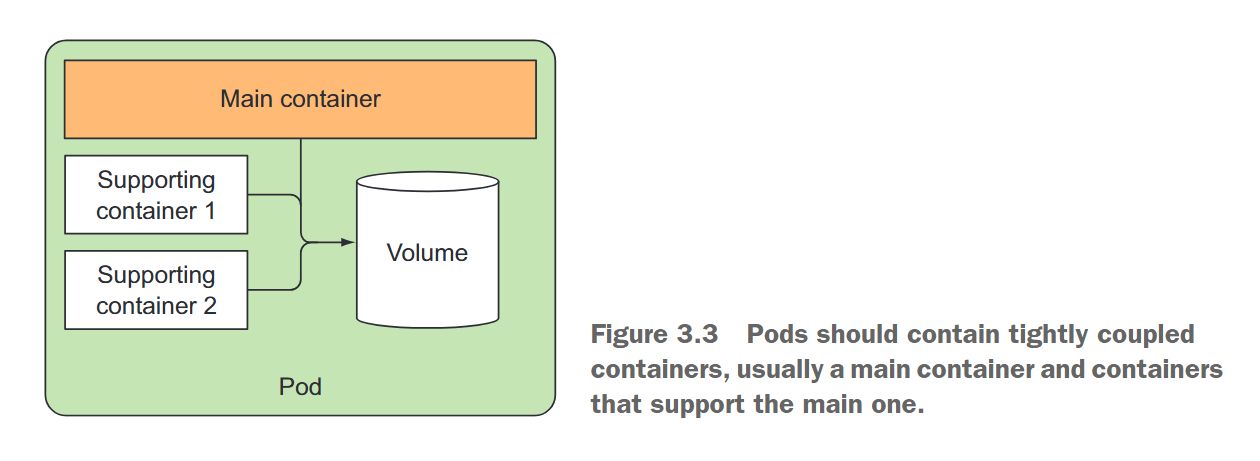
将多个容器放入单个 Pod 中的主要原因是应用程序由一个主进程和一个或多个辅助进程组成,如图3.3所示。例如,在一个 Pod 中,主容器可能是一个 Web 服务器,负责从某个文件目录中提供文件。此外,可能还有一个 sidecar 容器,定期从外部源下载内容并将其存储到 Web 服务器目录中。
决定何时在POD中使用多个容器
- 它们是否需要同时运行,还是可以在不同的主机上运行?
- 它们是否代表一个整体,还是独立的组件?
- 它们是否必须一起或分别进行扩展?
应该始终倾向于在不同的Pod中运行容器,除非特定的原因要求它们属于同一Pod
3.2 Creating pods from YAML or JSON descriptors
Pod 和其他 Kubernetes 资源通常是通过将 JSON 或 YAML 描述文件发布到 Kubernetes REST API 端点来创建的。ttp://kubernetes.io/docs/reference/)。
3.2.1 Examining a YAML descriptor of an existing pod
将已创建的Pod信息导出到YAML文件中
root@yjq-k8s1:~# kubectl get pod -n k8s-in-action kubia -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2023-05-22T08:16:44Z"
labels:
run: kubia
name: kubia
namespace: k8s-in-action
resourceVersion: "1598004"
uid: fd353a99-2a43-4c2a-9a9a-c694edd83b40
spec:
containers:
- image: yijunquan/kubia
imagePullPolicy: Always
name: kubia
ports:
- containerPort: 8080
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-4m2qs
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: yjq-k8s3
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: kube-api-access-4m2qs
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2023-05-22T08:16:44Z"
status: "True"
type: Initialized
- lastProbeTime: null
lastTransitionTime: "2023-05-22T08:17:03Z"
status: "True"
type: Ready
- lastProbeTime: null
lastTransitionTime: "2023-05-22T08:17:03Z"
status: "True"
type: ContainersReady
- lastProbeTime: null
lastTransitionTime: "2023-05-22T08:16:44Z"
status: "True"
type: PodScheduled
containerStatuses:
- containerID: docker://0fbd5260a1f5f18035bf919d52c6b755733d5a3a3734a3ca7a2c5092a71f8771
image: yijunquan/kubia:latest
imageID: docker-pullable://yijunquan/kubia@sha256:bf61996e401e52a9b054844ee7026c2d27c40ba33b7eb5bee2ae8f9cd1118419
lastState: {}
name: kubia
ready: true
restartCount: 0
started: true
state:
running:
startedAt: "2023-05-22T08:17:02Z"
hostIP: 33.33.33.147
phase: Running
podIP: 10.244.2.60
podIPs:
- ip: 10.244.2.60
qosClass: BestEffort
startTime: "2023-05-22T08:16:44Z
Pod定义由几个部分组成。首先,YAML中使用的Kubernetes API版本和YAML描述的资源类型。然后,在几乎所有的Kubernetes资源中都可以找到三个重要部分
Metadata包括Pod的名称、命名空间、标签和其他信息。Spec包含Pod内容的实际描述,例如Pod的容器、卷和其他数据。Status包含正在运行的实例的当前信息,例如实例处于什么状态、每个容器的描述和状态、实例的内部IP等基本信息。
3.2.2 Creating a simple YAML descriptor for a pod
用下面的YAML文件创建一个简单的Pod
apiVersion: v1 # k8s API版本
kind: Pod
metadata:
name: kubia-manual #Pod的名称
spec:
containers:
- image: yijunquan/kubia # 镜像名称
name: kubia
ports:
- containerPort: 8080 # 容器监听的端口
protocol: TCP
3.2.3 Using kubectl create to create the pod
用如下命令创建Pod
$ kubectl create -f kubia-manual.yaml
pod/kubia-manual created
查看创建好的Pod
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
kubia-manual 1/1 Running 0 2m38s
3.2.4 Viewing application logs
Node.js 应用程序会记录到进程的标准输出。容器化应用程序通常会将日志记录到标准输出和标准错误流中,而不是将其写到文件中。这是为了让用户以一种简单、标准的方式查看不同应用程序的日志。 容器运行时(本文中是 Docker)将这些流重定向到文件,并允许你通过运行命令来获取容器的日志。
$ docker logs <container id>
k8s提供了一个更方便的方式看Pod中的日志:
$ kubectl logs kubia-manual
Kubia server starting...
容器日志每天会自动进行轮换,每当日志文件达到10MB时也会进行轮换。kubectl logs命令仅显示最后一次轮换后的日志条目。
如果你的Pod包含多个容器,则在运行kubectl logs时必须显式指定容器名称,即添加-c <容器名称>选项。在你的kubia-manual Pod中,你将容器的名称设置为kubia,因此如果Pod中存在其他容器,你需要按如下方式获取其日志:
$ kubectl logs kubia-manual -c kubia
Kubia server starting...
请注意,只能检索仍然存在的实例的容器日志。删除实例时,其日志也会被删除。要使Pod的日志即使在Pod被删除后仍可用,需要设置集中的、集群范围的日志记录,它将所有日志存储到中央存储中。(后面的章节会提及)
3.2.5 Sending requests to the pod
可以使用port forwading来访问Pod,将本地网络端口转发到POD中的端口。
当你不想通过service与特定实例对话时(由于调试或其他原因),Kubernetes允许配置端口转发到实例。这是通过kubectl port-forward命令完成的。以下命令会将计算机的本地端口8888转发到kubiamanual pod的端口8080:
$ kubectl port-forward kubia-manual 8888:8080
Forwarding from 127.0.0.1:8888 -> 8080
在另一个终端中进行测试:
$ curl localhost:8888
You've hit kubia-manual
图3.5展示了当你发送请求时会发生的过程的过于简化的视图。实际上,在kubectl进程和Pod之间还有几个额外的组件,但它们目前不是相关的。

3.3 Organizing pods with labels
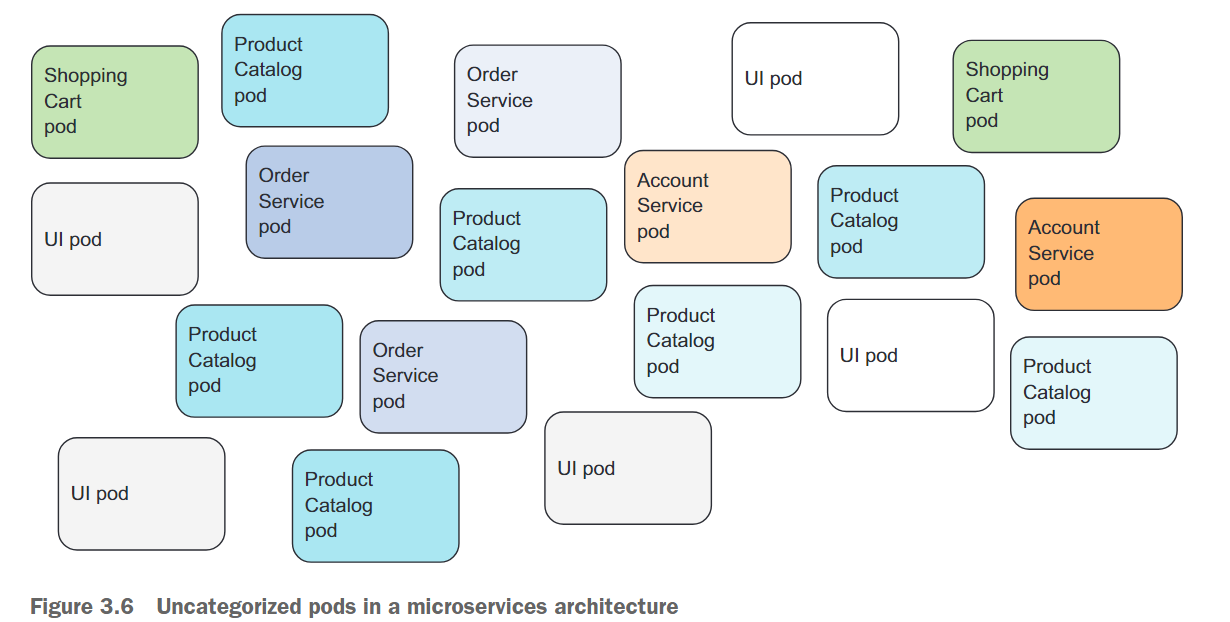
此时,你的集群中有两个正在运行的Pod。在部署实际应用程序时,大多数用户最终将运行更多的Pod。随着Pod数量的增加,将它们分类到子集中的需求变得越来越明显。 例如,对于微服务架构,部署的微服务数量很容易超过20个或更多。这些组件可能会被复制(部署多个相同组件的副本)并且多个版本或发布(稳定版、beta版、金丝雀版等)将同时运行。这可能会导致系统中有数百个Pod。如果没有组织它们的机制,就会十分混乱,如图3.6所示。
组织Pod和所有其他Kubernetes对象则是通过标签(labels)完成的
3.3.1 Introducing labels
标签是 Kubernetes 的一个简单而强大的功能,可以用于组织 Pods 和其他所有 Kubernetes 资源。标签是任意的键值对,附加到资源上,并在使用标签选择器过滤资源时起作用。一个资源可以拥有多个标签,只要这些标签的键在该资源中是唯一的即可。一般在创建资源时会附加标签,但稍后也可以添加其他标签或修改现有标签的值,而不必重新创建资源。
让我们回到图3.6中的微服务示例。通过为这些Pod添加标签,可以获得一个更加良好组织的系统。每个Pod都有两个标签:
app,指定Pod属于哪个应用程序、组件或微服务;rel,显示在该Pod中运行的应用程序的是稳定版、beta版还是金丝雀版。
金丝雀版本是指在部署应用程序的新版本时,将其放置在稳定版本旁边,只让一小部分用户尝试新版本以观察其表现,然后再将其推给所有用户。这可避免将错误的版本推给太多用户。
通过添加这两个标签,基本上已经将Pod组织成两个维度(按应用程序横向组织,按Release纵向组织),如图3.7所示。

3.3.2 Specifying labels when creating a pod
创建一个名为kubia-manual-with-labels.yaml的新文件,其中包含以下内容。
apiVersion: v1 # k8s API版本
kind: Pod
metadata:
name: kubia-manual-v2 #Pod的名称
labels: # 添加两个label
create_method: manual
env: prod
spec:
containers:
- image: yijunquan/kubia # 镜像名称
name: kubia
ports:
- containerPort: 8080 # 容器监听的端口
protocol: TCP
应用这个YAML文件
$ kubectl create -f kubia-manual-with-labels.yaml
pod/kubia-manual-v2 created
查看已有Pod的labels:
$ kubectl get po --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kubia-manual 1/1 Running 0 33m <none>
kubia-manual-v2 1/1 Running 0 108s create_method=manual,env=prod
如果只对某些标签感兴趣,则可以使用-L指定它们,并在各自的列中显示每个标签,而不是列出所有标签:
$ kubectl get po -L creation_method,env
NAME READY STATUS RESTARTS AGE CREATION_METHOD ENV
kubia-manual 1/1 Running 0 35m
kubia-manual-v2 1/1 Running 0 3m17s manual prod
3.3.3 Modifying labels of existing pods
可以在现有Pod上添加和修改标签。因为kubia-manupod也是手动创建的,所以让我们为它添加create_method=manual标签:
$ kubectl label pod kubia-manual creation_method=manual
pod/kubia-manual labeled
让我们在kubia-manual-v2 pod上将env=prod标签更改为env=DEBUG,以查看如何更改现有标签。
$ kubectl label pod kubia-manual-v2 env=debug --overwrite
pod/kubia-manual-v2 labeled
查看更改后的Pod
$ kubectl get pod -L creation_method,env
NAME READY STATUS RESTARTS AGE CREATION_METHOD ENV
kubia-manual 1/1 Running 0 50m manual
kubia-manual-v2 1/1 Running 0 18m manual debug
3.4 Listing subsets of pods through label selectors
标签和标签选择器是相辅相成的。通过标签选择器,可以选择带有特定标签的一组Pod,并对这些Pod执行操作。标签选择器是一种筛选资源的规则,根据带有特定值的标签是否包含在其中来进行筛选。
标签选择器可以根据以下方式筛选资源:
- 包含(或不包含)某个特定键的标签
- 包含某个带有特定键和值的标签
- 包含某个特定键的标签,但其值不等于指定的值。
3.4.1 Listing pods using a label selector
使用标签选择器列出手动创建的Pod:
$ kubectl get pod -l creation_method=manual
NAME READY STATUS RESTARTS AGE
kubia-manual 1/1 Running 0 12h
kubia-manual-v2 1/1 Running 0 11h
列出包含env标签的所有Pod,无论其值是什么:
$ kubectl get pod -l env
NAME READY STATUS RESTARTS AGE
kubia-manual-v2 1/1 Running 0 11h
列出不含env标签的Pod:
$ kubectl get pod -l '!env'
NAME READY STATUS RESTARTS AGE
kubia-manual 1/1 Running 0 12h
同样可以使用如下标签选择器来选择Pod:
creation_method!=manual选择creation_method标签的值不为manual的Pod。env in (prod,devel)选择env标签的值为prod或者devel的Pod。env notin (prod,devel)选择env标签的值不为prod或者devel的Pod。
回到面向微服务的体系结构示例中的Pod,可以使用app=PC标签选择器(如下图所示)选择属于product catalog微服务的所有Pod
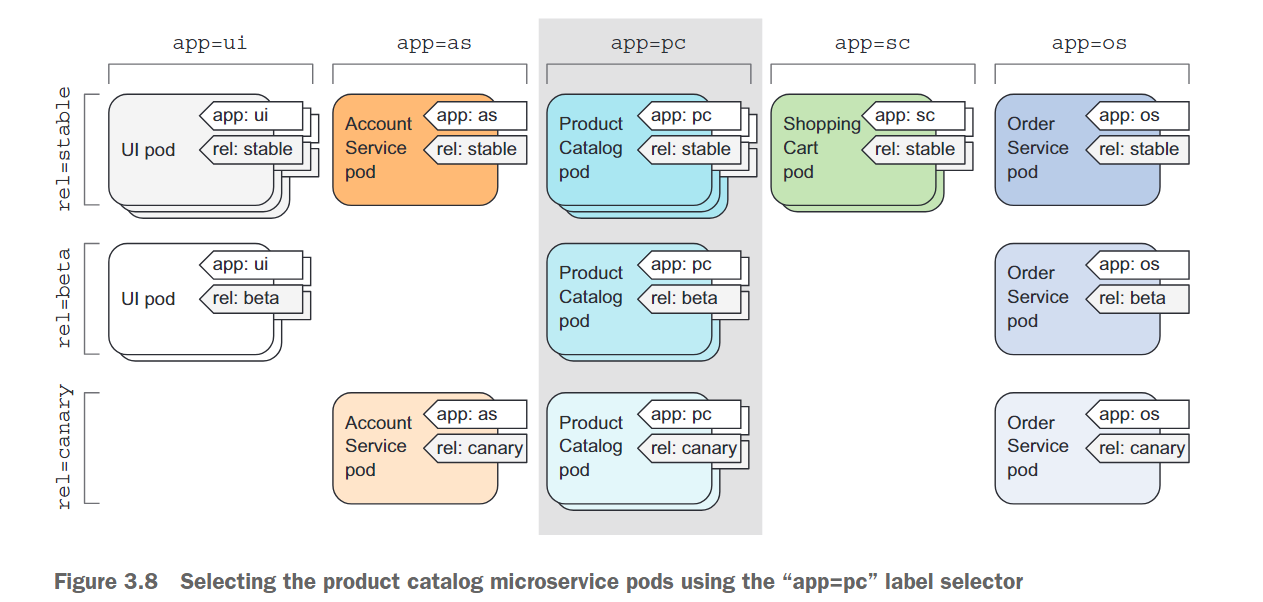
3.4.2 Using multiple conditions in a label selector
选择器可以包括多个逗号分隔的条件,所有条件需要匹配才能符合选择器。举个例子,如果只想选择运行product catalog微服务beta版本的pod,可以使用如下选择器:app=pc,rel=beta(参见图3.9)。标签选择器不仅可以用于列出pod,还可以用于针对所有pod的一个子集执行操作。
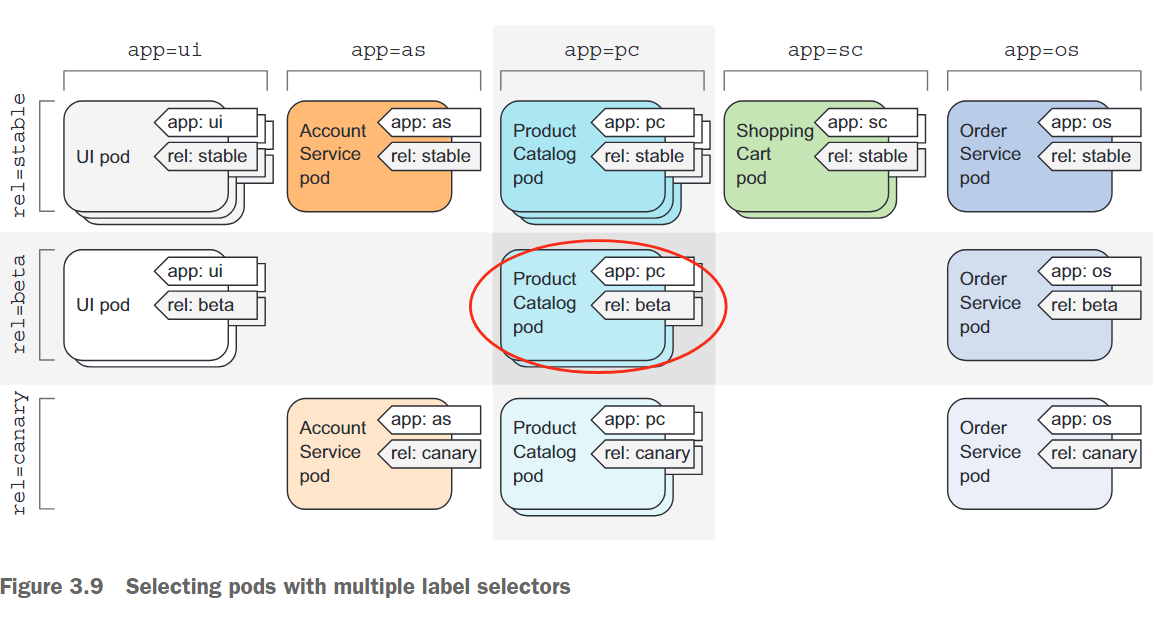
3.5 Using labels and selectors to constrain pod scheduling
在Kubernetes集群中,Pod通常是随机调度到任意节点上的,而不需要精确地指定某个节点。但在某些情况下,需要让Pod调度到满足特定要求的节点,例如节点硬件配置不同或需要GPU加速。此时,使用节点标签和标签选择器,描述节点需求,然后让Kubernetes选择与这些要求匹配的节点,这样就可以参与Pod调度的决策。需要注意的是,Kubernetes的核心思想是将基础设施与应用程序隔离,不要让应用程序与特定的节点耦合。
3.5.1 Using labels for categorizing worker nodes
假设集群中的一个节点包含一个旨在用于通用GPU计算的GPU。你希望将标签添加到显示此功能的节点。向其中一个节点添加标签gpu=true(从kubectl get nodes返回的列表中选择一个):
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
yjq-k8s1 Ready control-plane,master 9d v1.21.3
yjq-k8s2 Ready worker 9d v1.21.3
yjq-k8s3 Ready worker 9d v1.21.3
yjq-k8s4 Ready worker 9d v1.21.3
$ kubectl label node yjq-k8s2 gpu=true
node/yjq-k8s2 labeled
$ kubectl get node -l gpu=true
NAME STATUS ROLES AGE VERSION
yjq-k8s2 Ready worker 9d v1.21.3
$ kubectl get nodes -L gpu
NAME STATUS ROLES AGE VERSION GPU
yjq-k8s1 Ready control-plane,master 9d v1.21.3
yjq-k8s2 Ready worker 9d v1.21.3 true
yjq-k8s3 Ready worker 9d v1.21.3
yjq-k8s4 Ready worker 9d v1.21.3
3.5.2 Scheduling pods to specific nodes
如果需要在部署Pod时要求调度器只选择那些提供GPU的节点,需要在部署该Pod的YAML文件中添加一个节点选择器。下面提供了一个示例文件kubia-gpu.yaml,包含了节点选择器的配置。用户只需要运行kubectl create -f kubia-gpu.yaml命令即可依照该YAML文件创建Pod。
apiVersion: v1 # k8s API版本
kind: Pod
metadata:
name: kubia-gpu #Pod的名称
spec:
nodeSelector:
gpu: "true"
containers:
- image: yijunquan/kubia # 镜像名称
name: kubia
ports:
- containerPort: 8080 # 容器监听的端口
protocol: TCP
3.6 Annotating pods
Kubernetes中除了标签以外还有一种键值对存储方式——注释(annotation)。注释和标签类似,但是注释不用于识别和分组对象,而是主要供工具使用。注释可以包含更大的信息块,可以用来为Kubernetes的新功能引入相关的API变化。注释常用于为每个Pod或其他API对象添加描述,在集群中使用者可以快速获取每个对象的信息。例如,通过在注释中指定对象的创建人,可以使协作更加容易。
向现有对象添加注释的最简单方法是通过kubectl Annotate命令:
$ kubectl annotate pod kubia-manual mycompany.com/someannotation="foo bar"
pod/kubia-manual annotated
添加了带有值foo bar的注释myCompany.com/ome注解。对注释键使用这种格式是一个好主意,以防止键冲突。当不同的工具或库向对象添加批注时,如果它们不像在这里所做的那样使用唯一前缀,可能会意外地覆盖彼此的批注。可以使用kubectl describe查看添加的批注:
$ kubectl describe pod kubia-manual | grep "Annotations"
Annotations: mycompany.com/someannotation: foo bar
3.7 Using namespaces to group resources
Kubernetes namespace为对象名称提供了一个作用域。你可以将所有资源拆分到多个namespace中,而不是将所有资源放在一个namespace中,这还允许你多次使用相同的资源名称(跨不同的namespace)。
Kubernetes中的namespace与Linux中的各种namespace具有不同的含义和作用。
在Linux中,namespace是一种机制,用于隔离系统中不同进程的资源,例如文件系统、网络、进程ID等。这样可以使不同进程相互隔离,并且不会相互干扰。例如,Docker使用Linux的命名空间来隔离容器的运行环境。
而在Kubernetes中,namespace是用于将同一集群中的不同资源(例如Pod、Service、Deployment等)划分为不同的虚拟集合。每个资源都属于特定的namespace,不同的namespace之间相互隔离,这样可以将不同应用程序或不同团队的资源隔离开来,在同一集群中进行管理和调度,从而避免冲突和混乱。
3.7.1 Understanding the need for namespaces
使用多个命名空间允许你将具有众多组件的复杂系统分割成更小、不同的组。它们还可用于在多租户环境中分离资源,将资源分割成生产、开发和测试环境,或以任何其他你可能需要的方式。资源名称只需要在命名空间内是唯一的。两个不同的命名空间可以包含相同名称的资源。但是,虽然大多数资源是有命名空间的,但有几种资源不是。其中之一是Node资源,它是全局的,不绑定到单个命名空间。
3.7.2 Discovering other namespaces and their pods
之前都是在默认命名空间中部署Pod,让我们看看集群中有哪些namespace:
$ kubectl get ns
NAME STATUS AGE
default Active 9d
experiment Active 9d
istio-system Active 9d
k8s-in-action Active 42h
kube-flannel Active 9d
kube-node-lease Active 9d
kube-public Active 9d
kube-system Active 9d
kubernetes-dashboard Active 9d
monitoring Active 9d
可以通过加上-n来查看指定namespace中的Pod:
$ kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
chaosblade-operator-64c9587579-9cj96 1/1 Running 0 13h
chaosblade-tool-488rv 1/1 Running 1 9d
chaosblade-tool-bbzw7 1/1 Running 0 9d
chaosblade-tool-rdwx9 1/1 Running 3 9d
chaosblade-tool-wchxf 1/1 Running 4 9d
coredns-59d64cd4d4-264v5 1/1 Running 0 7d17h
coredns-59d64cd4d4-q4p2m 1/1 Running 0 7d17h
coredns-59d64cd4d4-qszcl 1/1 Running 0 13h
etcd-yjq-k8s1 1/1 Running 1 9d
kube-apiserver-yjq-k8s1 1/1 Running 1 9d
kube-controller-manager-yjq-k8s1 1/1 Running 2 9d
kube-proxy-2lnh2 1/1 Running 1 9d
kube-proxy-422l7 1/1 Running 4 9d
kube-proxy-8mw2q 1/1 Running 5 9d
kube-proxy-vqx6j 1/1 Running 1 9d
kube-scheduler-yjq-k8s1 1/1 Running 1 9d
除了隔离资源之外,命名空间还用于仅允许特定用户访问特定资源,甚至用于限制单个用户可用的计算资源量。
3.7.3 Creating a namespace
可以使用YAML文件来创建namespace:

$ kubectl create -f custom-namespace.yaml
namespace "custom-namespace" created
也可以使用kubectl create命令来创建namespace:
$ kubectl create namespace custom-namespace
namespace "custom-namespace" created
namespace中不允许包含"."
3.7.4 Managing objects in other namespaces
可以将Pod分配到指定的命名空间:
$ kubectl create -f kubia-manual.yaml -n custom-namespace
pod/kubia-manual created
现在有两个同名的Pod(kubia-manual)。一个在默认namespace中,另一个在custom-namespace中。
如果不指定名称空间,kubectl将在当前kubectl上下文中配置的默认namespace中执行操作。可以通过kubectl配置命令更改当前上下文的namespace和当前上下文本身。
要快速切换到不同的namespaces,可以设置以下别名:alias kcd='kubectl config set-context $(kubectl config currentcontext) --namespace ',然后就可以使用kcd some-namespace更改当前上下文的namespace。
3.7.5 Understanding the isolation provided by namespaces
虽然命名空间允许将对象隔离成不同的组,从而使你只能操作属于指定命名空间的对象,但它们并不提供任何运行对象的隔离。
3.8 Stopping and removing pods
3.8.1 Deleting a pod by name
可以直接通过名称删除default命名空间中的Pod:
$ kubectl delete pod kubia-gpu
pod "kubia-gpu" deleted
通过删除Pod,你会指示Kubernetes终止该Pod中的所有容器。Kubernetes向进程发送SIGTERM信号,并等待一定数量的秒数(默认为30秒),以使其正常关闭。如果它没有及时关闭,则通过SIGKILL杀死该进程。为确保你的进程始终正常关闭,它们需要正确处理SIGTERM信号。
你也可以通过指定多个以空格分隔的名称删除多个Pod(例如,
kubectl delete po pod1 pod2)。
3.8.2 Deleting pods using label selectors
也可以使用标签选择器来删除Pod:
$ kubectl delete pod -l creation_method=manual
pod "kubia-manual" deleted
pod "kubia-manual-v2" deleted
3.8.3 Deleting pods by deleting the whole namespace
也可以通过删除整个namespace来删除命名空间中的Pod:
$ kubectl delete ns custom-namespace
namespace "custom-namespace" deleted
3.8.4 Deleting all pods in a namespace, while keeping the namespace
可以通过如下命令删除namespace中的所有Pod,同时保留namespace:
$ kubectl delete po --all
也可以删除所有资源:
$ kubectl delete all --all