vue - 大文件分片上传之simple-uploader.js的使用
- 分片上传的思路
- 前端文件切片常见的写法
- 后端常见的写法
关于大文件上传
关于单个文件上传:其实就是
前端中的文件通过http传到后端,后端再写入服务器的过程
那单个大文件分片上传:其实就是前端把大文件分成了好几块,后端再多次写入服务器的过程
关于秒传与断点续传
秒传:其实就是
服务器中存在这个文件了,再次传的时候就不重新上传了,前端直接显示上传成功
断点续传:其实就是文件传了一部分,剩下的还没传。这个时候根据上传的偏移量offset,把剩下的上传到服务器
前提知识
1. 前端使用spark-md5.js对文件进行加密
import SparkMD5 from 'spark-md5'
const spark = new SparkMD5.ArrayBuffer()
//获取文件二进制数据
var fileReader = new FileReader()
fileReader.readAsArrayBuffer(file) //file就是获取到的文件
//异步执行函数,fileReader.readAsArrayBuffer的回调函数
fileReader.onload = function (e) {
spark.append(e.target.result)
const md5 = spark.end()
console.log(md5)
//打印结果这个文件会有一串唯一编码类似下面
//4b4a94c7ff8953d7103515e91d432b0a
}
2. simple-uploader.js的使用
// options常见配置
options: {
// 上传地址,若测试和真正上传接口不是同个路径,可以用函数模式。
// 如果是同一个路径,一个get请求,一个post请求
target: "/fileStorage/upload",
// 是否开启服务器分片校验。默认为 true
testChunks: true,
// 真正上传的时候使用的 HTTP 方法,默认 POST
uploadMethod: "post",
// 分片大小
chunkSize: CHUNK_SIZE,
// 并发上传数,默认为 3
simultaneousUploads: 3,
/**
* 检测校验是md5加密以后的事情,整个上传过程,只会执行一次。
* 执行一次以后,看是上传完成,还是需要继续上传
*
* 发起测试校验以后,所有分片都会进入这个回调
*
* 判断分片是否上传,秒传和断点续传基于此方法
* 如果后端返回的是true,代表秒传
* 如果后端返回[1,2,3,4,5,6,7,8,9]等(分片信息),代表可以继续上传
*
*
* 我个人理解的停止上传与继续上传就是断点上传
*
*
* 我个人理解这个方法是这样的:分块以后知道有几块了,再跟数据库做比对,知道是上传完成了,还是需要继续上传
* api接口只走一次检验方法,那如果是上传完成了直接ok,如果是需要继续上传,那就接着上传,组件再暴露出pause和resume方法,用于停止和继续上传。(api得到数据库数据以后,每块走这个方法,进行对比。)
*/
checkChunkUploadedByResponse: (chunk, message) => {
console.log("message,第一次test以后,返回来的数据", chunk.offset)
// message是后台返回
let messageObj = JSON.parse(message);
let dataObj = messageObj.data;
if (dataObj.uploaded !== null) {
return dataObj.uploaded;
}
// 判断文件或分片是否已上传,已上传返回 true
// 这里的 uploadedChunks 是后台返回
return (dataObj.uploadedChunks || []).indexOf(chunk.offset + 1) >= 0;
},
parseTimeRemaining: function (timeRemaining, parsedTimeRemaining) {
//格式化时间
return parsedTimeRemaining
.replace(/\syears?/, "年")
.replace(/\days?/, "天")
.replace(/\shours?/, "小时")
.replace(/\sminutes?/, "分钟")
.replace(/\sseconds?/, "秒");
},
// 处理所有请求的参数
// processParams:(params,file,chunk) => {
// // 这里需要根据后端的要求,处理一些请求参数
// // params.xxx = chunk.xxx // 比如一些需要在上传时,带上测试校验返回的一些信息字段
// // return params;
// }
},
// 常用的回调函数
<uploader
ref="uploader"
:options="options"
:autoStart="false"
:file-status-text="fileStatusText"
@file-added="onFileAdded"
@file-success="onFileSuccess"
@file-error="onFileError"
@file-progress="onFileProgress"
class="uploader-example"
>
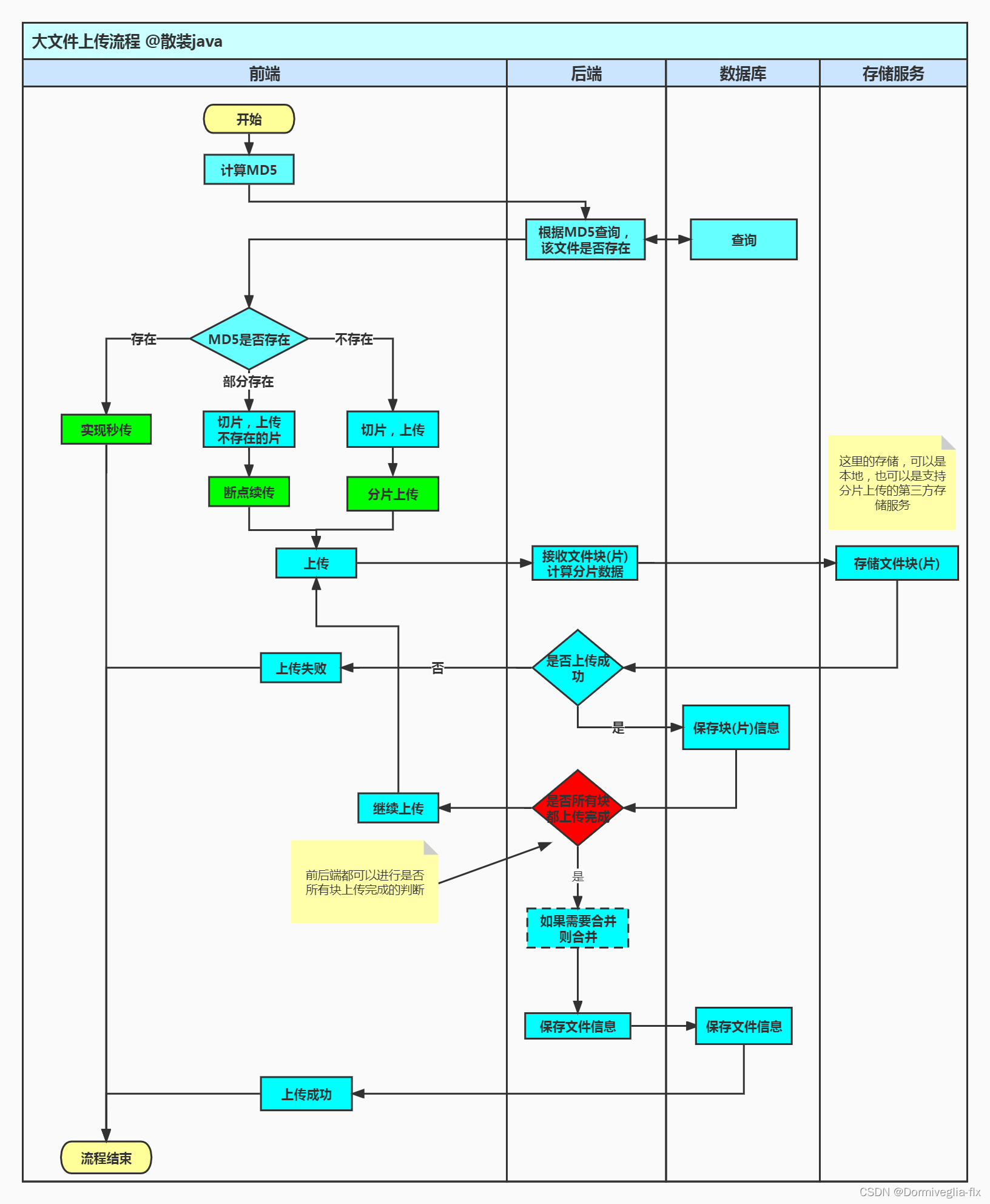
分片上传的思路
- 先对文件进行
md5加密。使用md5加密的优点是:可以对文件进行唯一标识。在后端根据md5判断文件是否存在。 - 向后台发送
第一次请求接口,且只发送一次,用于检测,接口里的数据就是我们已经上传过的文件块。用于检测是否需要秒传或者继续上传 - 当文件存在的话,就不用重新再上传。(
秒传) - 当文件不存在的话,且对大文件进行
分片。比如一个100M的文件,我们一个分片是5M的话,那么这个文件可以分20次上传。(checkChunkUploadedByResponse方法里面判断) - 当文件不存在的话,且已经上传了一部分的。接着上传(
checkChunkUploadedByResponse方法里面判断) - 向后台
发送第二次请求接口,这时的请求才是正儿八经的上传请求。此时,请求可以停止和继续发。
前端文件切片常见的写法
// 文件切片需要是的参数:
1. var fileSize = file.size; // 文件大小
2. var CHUNK_SIZE = 2 * 1024 * 1024; // 切片的大小
3. var chunks = Math.ceil(fileSize / chunkSize); // 获取切片的个数
4. var currentChunk = 0; // 当前分片下标
// 加载下一个分片的start与end
const start = currentChunk * CHUNK_SIZE;
const end = start + CHUNK_SIZE >= file.size ? file.size : start + CHUNK_SIZE;
// md5 加密
getFileMD5(file, callback) {
// 使用SparkMD5,对文件进行加密
let spark = new SparkMD5.ArrayBuffer();
let fileReader = new FileReader();
//获取文件分片对象(注意它的兼容性,在不同浏览器的写法不同)
let blobSlice =
File.prototype.slice ||
File.prototype.mozSlice ||
File.prototype.webkitSlice;
// 当前分片下标
let currentChunk = 0;
// 分片总数(向下取整)
let chunks = Math.ceil(file.size / CHUNK_SIZE);
// 暂停上传
file.pause();
// 第一次加载分片的方法
loadNext();
// fileReader.readAsArrayBuffer,读完后的回调函数
fileReader.onload = function (e) {
// console.log("currentChunk :>> ", currentChunk);
spark.append(e.target.result);
if (currentChunk < chunks) {
currentChunk++;
loadNext();
} else {
// 该文件的md5值
let md5 = spark.end();
// 回调传值md5
callback(md5);
}
};
fileReader.onerror = function () {
this.$message.error("文件读取错误");
file.cancel();
};
// 加载下一个分片
function loadNext() {
const start = currentChunk * CHUNK_SIZE;
const end =
start + CHUNK_SIZE >= file.size ? file.size : start + CHUNK_SIZE;
// 文件分片操作,读取下一分片(fileReader.readAsArrayBuffer操作会触发onload事件)
fileReader.readAsArrayBuffer(blobSlice.call(file.file, start, end));
}
},
// @file-added="onFileAdded" 回调函数
onFileAdded(file, event) {
console.log("onFileAdded方法执行了__flx",event)
/*
* 第一步,判断文件类型是否允许上传
* */
// todo 判断文件类型是否允许上传
/*
* 第二步:计算文件 MD5,并恢复上传
* */
this.getFileMD5(file, (md5) => {
console.log('MD5回调函数')
if (md5 !== "") {
// 修改文件唯一标识
file.uniqueIdentifier = md5;
// 请求后台判断是否上传
// 恢复上传
file.resume();
}
});
},
后端常见的写法

// 校验接口的业务逻辑
// 一共两张表,一张是每块的记录表(chunck),一张是上传完成的记录表(file)
// chunck表中的操作
// 1. 根据 identifier 查找数据是否存在
// 2. 如果查询的List的length是 0 说明文件不存在,则直接返回没有上传
// 3. 如果不是0,则拿到第一个数据,查看文件是否分片
// 4. 如果没有分片,那么直接返回已经上传成功,否则返回分片数据。
// 分片上传的逻辑
// 1. 每次上传完成以后,都把数据存到chunck表中
// 2. 当所有都上传完以后,存到文件表file中