【论文阅读】CatSQL: Towards Real World Natural Language to SQL Applications
文章目录
- 【论文阅读】CatSQL: Towards Real World Natural Language to SQL Applications
- 1. 来源
- 2. 介绍
- 3. 方法介绍
- 3.1 CatSQL模板
- 3.2 CatSQL 查询生成
- 3.2.1 GraPPa嵌入网络
- 3.2.2 使用CAT解码器网络生成查询体
- 3.2.3 字面处理(Literal handling)
- 3.2.4 嵌套的查询和查询连接
- 3.2.5 From 子句
- 3.3 语义校正
- 3.3.1 token 级别的违反
- 3.3.2 FROM 子句修订
- 3.3.3 连接路径修订
- 4. 实验
- 4.1 基准数据集
- 4.2 评价指标
- 4.3 基线方法
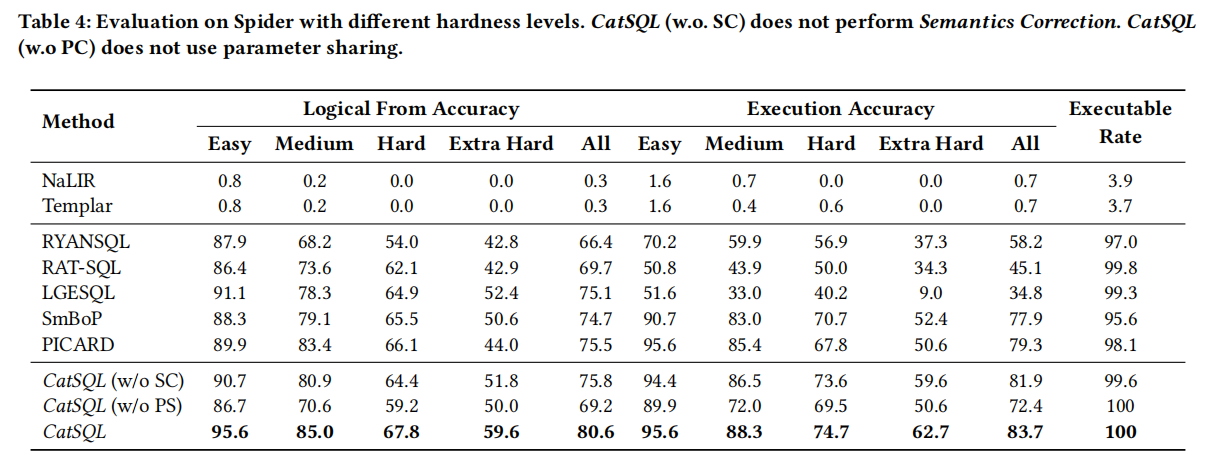
- 4.4 实验结果
- 5.总结
1. 来源

-
VLDB 2023
-
https://www.vldb.org/pvldb/vol16/p1534-fu.pdf
-
https://github.com/asfuhan/CatSQL.git
2. 介绍
SQL(NL2SQL)技术为访问数据库提供了一个方便的接口,特别是为非专家用户,进行各种数据分析。现有的方法通常采用基于规则或基于深度学习的解决方案。
- 前者很难在不同的领域中进行推广。
- 虽然后者可以很好地进行概括,但它通常会导致具有语法或语义错误的查询,因此甚至可能是不可执行。
在这项工作中,作者弥合了两者之间的差距,并设计了一个新的框架,以显著提高准确性和运行时。特别地,作者开发了一个新的CatSQL草图,它构建了一个具有最初作为占位符的插槽的模板,并与深度学习模型紧密集成,以基于数据库模式的有意义的内容填充这些插槽。与广泛使用的基于序列到序列的方法相比,作者的基于草图的方法不需要生成在模板中作为样板的关键字,并且可以实现更好的准确性和运行速度更快。
- 与现有的基于草图的方法相比,作者提出的CatSQL草图更通用和灵活,可以利用某些插槽上已经填充的值来推导出其余的值,以提高性能。
- 此外,作者还提出了语义校正技术,这是第一个在基于深度学习的NL2SQL解决方案中利用数据库领域知识的技术。语义校正是一种后处理程序,它通过应用规则来识别和纠正语义错误来检查最初生成的SQL查询。该技术显著提高了NL2SQL的精度。
- 该工作对单域和跨域基准测试进行了广泛的评估,并证明了方法在准确性和吞吐量方面都显著优于之前的方法。特别是,在最先进的NL2SQL基准测试Spider上,CatSQL原型在精度上比之前的最佳解决方案高出4分,同时仍然实现了高达63倍的吞吐量。
3. 方法介绍


在本节中,我们将介绍列操作模板方法来解决NL2SQL问题。该方法是一种基于模板的深度学习方法。也就是说,使用深度神经网络填充模板中的空槽,形成最终的SQL查询。
- 与现有的基于序列到序列的方法相比,基于模板的方法不需要浪费资源来生成关键字,如SELECT / FROM / WHERE;
因此,这种方法可以专注于生成基本信息以形成SQL查询。然而现有的基于模板的方法也存在两个问题。
- 首先,它们训练不同的模型来生成不同的子句。因此,每个模型只使用数据的一个子集。例如,SELECT 子句的模型不利用 WHERE 子句的任何数据。现有的工作表明,对于序列到序列模型,共享模型参数来生成不同的子句可以提高性能。
- 为此,作者开发了一个特殊的模板,称为列动作模板SQL或CatSQL,为多个子句训练一个模型,以实现基于模板的方法的参数共享的想法。
- 第二,现有的作品依赖于纯深度神经网络生成查询,从而忽略语义约束,这样大多数连接条件应该有一个PK-FK(主键-外键)关系。
- 作者的CatSQL方法为此,开发了一种新的语义校正技术来处理这些语义约束。语义校正技术修复了CatSQL SQL生成过程中的简单语义错误,并对生成的查询进行后处理,以修复考虑到数据库模式的更复杂的语义错误。
在下面,我们将首先介绍我们的CatSQL模板,然后描述我们的神经网络模型来填充模板中的每个插槽。最后,我们将解释我们的语义校正技术。
3.1 CatSQL模板

在表1 中定义了CatSQL模板。列操作模板(或CATs)的核心定义如下:

我们可以看到,CAT是一个通用模板,它适合于SQL查询的多个原因,包括:: (1) SELECT; (2) WHERE; (3)
GROUP BY; (4) ORDER BY; 和 (5) HAVING。不同的子句只填充插槽的一个子集。例如,SELECT 填充(可选)AGG、DISTINCT, 和 column;ORDER BY 填充 column 和 [ASC|DESC]。
每个子句都是一个关键字,后面跟着一个cat序列。特别是,对于WHERE子句,连接关键字(即,AND和OR)被视为CAT的一部分。例如,下面的表达式:

由以下三种类别组成:

CatSQL模板的定义是为了促进参数共享的想法,而以前的基于模板的方法并没有采用它。特别是,由于这四个CAT子句中的每一个都可以看作是一个CAT的序列,所以我们可以为所有四个不同的子句只训练一个序列到序列模型。在运行时,一旦预测了CAT,我们就可以通过组装不同的CAT子句来构建最终的SQL查询。
- 我们将在下一节中解释我们的神经网络如何填充CatSQL草图。
3.2 CatSQL 查询生成
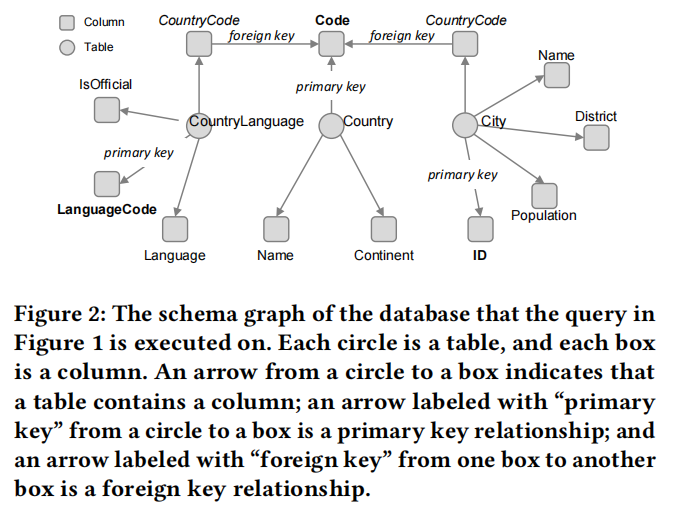
如上图 3 所示,CatSQL的整体架构由四个组件组成,即:(1) GraPPa嵌入网络、(2) CAT解码器网络、(3)连接网络和(4) FROM解码器网络。现在我们来解释这些组件。
3.2.1 GraPPa嵌入网络
- 参数共享思想的第一个实现是通过使用一个共同的嵌入网络。
为了达到这个目的,我们连接了自然语言问题、数据库模式和一些用于生成嵌套查询的附加信息。
- 问题是一对[CLS]令牌和[SEP]令牌之间的令牌序列。
- 数据库模式部分将每个表的名称及其列名一起编码为一个表模式序列,并将所有表的模式序列连接在一起,并由一个[SEP]标记分隔。
- 附加信息主要用于生成嵌套查询,因此我们稍后将保留它们。
我们在输入序列上运行一个名为 GraPPa 的嵌入网络来生成一个隐藏状态序列。GraPPa体系结构是一个24层的transformer 网络,预先训练了多个SQL解析任务。
- 所有其他组件共享相同的GraPPa编码网络,以利用参数共享的思想。
3.2.2 使用CAT解码器网络生成查询体
对于这五个CAT子句,我们可以将它们建模为一个有一些槽的CAT序列。因此,预测每个子句被表述为一个标准的CAT序列生成问题。特别地,从表1中可以看出,一个查询可以被视为 SELECT, FROM, WHERE, GROUP BY 和 ORDER BY子句的连接。
- 在该框架中,我们对FROM子句的处理不同,而每个其他的子句可以看作是一个cat序列。作者将这四个子句通过一个特殊的 [SEP] 标记连接在一起,因此我们可以将生成这四个子句的问题看作标准序列到序列生成问题,上面描述的输入序列,输出是 CATs 和 [SEP] 标记序列。
- 为此,从GATPPa编码网络生成的嵌入序列中,CAT解码器网络使用另一个四层变压器网络生成CAT隐藏状态的输出序列。它们中的每一个都对应着一个CAT。根据生成的CAT和[SEP]序列,我们可以将每个CAT分成不同的子句。
- 每个CAT最多有7个插槽,因此我们使用7个不同的分类器来生成一个CAT的不同批次。不同的子句可以填充不同的插槽。例如,对于SELECT子句,我们只填充AGG、不同的和列槽,并忽略其他四个分类器的输出,以确保生成的SQL查询是有效的。
- 对于7个槽中的5个,如AGG, DISTINCT, OP, AND/OR 连接 和 ASC/DESC 描述符,我们使用具有softmax激活的前馈层作为分类器。如果一个槽是可选的,我们可以填充一个特殊的[空]标记,以表示该槽被省略。
- 列插槽使用指针网络填充。也就是说,对于每个CAT,
- 我们首先得到由CAT解码器网络计算出的隐藏状态向量。同时,我们收集了所有的列,并为每个列名计算一个嵌入向量。
- 然后对于每一列,我们计算分数作为CAT隐藏状态向量和列的嵌入向量的内积。
- 然后,对于每个列名,我们计算一个分数作为CAT隐藏状态向量和列嵌入的内积。选择得分最高的列名来填充列插槽。
在讨论值槽处理方法之前,我们想提一下,不同的子句可能有不同的无效槽。例如,当我们填写SELECT子句时,我们不需要填写诸如OP和值等插槽。在这种情况下,网络仍然为这些插槽生成值,但在形成最终查询时将屏蔽它们。我们有一个特殊的例行程序来处理。我们现在将在下面描述我们的方法
3.2.3 字面处理(Literal handling)
- 值槽可以有三种不同的形式:(1)一个字面符;(2)一对字面文字;(3)嵌套的_term_token。
当填充这个插槽时,模型将首先运行一个分类器来确定它选择的三种场景中的哪一种。当需要一个文字时,将使用一个特殊的文字处理例程。
-
大多数现有的文字填充工作都试图直接在自然语言问题中找到一个标记,并将其复制到文字位置。但是,这种方法存在这样的问题,即当最终用户无法访问确切的数据记录时,问题中使用的单词可能与数据库中的值不匹配。
-
作者的方法将检查数据库值,以提高准确性。对于每个要生成的文字槽,网络为这个槽生成一个嵌入向量作为文字嵌入。我们也得到了在同一CAT中的列。然后,我们从这一列中检索所有不同的值,并计算每个值的嵌入。我们计算文字嵌入与每个值嵌入向量之间的余弦相似度得分,并选取得分最大的值。如果这个分数超过了手动指定的阈值,那么我们直接复制这个值;否则,我们将采用传统的方法在自然语言问题中复制最匹配这个文字嵌入的标记。
- 作者观察到,这种方法显著地提高了执行精度。
-
注意,每个列中所有不同值集及其嵌入是离线计算的,并定期更新模型更新。因此,在线服务模块只需要扫描这组值嵌入。与整个神经网络的计算相比,这需要的时间要短得多。
3.2.4 嵌套的查询和查询连接
现在将解释如何扩展嵌套的 term_token,以及连接网络如何处理连接查询。
扩展嵌套的 term_token。当生成一个嵌套的 term_token 时,生成器应该将其扩展为一个嵌套的子查询。该方法与顶级过程非常相似,但作者提供了额外的信息作为GraPPa网络的输入。
- 一个简单的想法是使用整个顶级查询(或嵌套查询中的内部块的外部块)来形成一个序列作为附加信息。但是,这种方法使得额外的输入太长,因此需要大量的计算资源,这限制了在现实场景中的应用程序。
- 作者提出了一种有效的记录外部块信息的方法。特别是,当扩展一个嵌套的_term_token时,我们收集外部查询中出现的所有列名,并将它们连接到一个由 [SEP] 标记分隔的序列中,以形成附加信息。
处理连接关键字,如INTERSECT, UNION, EXCEPT, 和 LIMIT,类似于扩展嵌套的 term_token。一旦生成了原子查询,我们运行一个连接网络(图3中的第3部分)来预测这四个关键字是否存在一个关键字。该模型由一个前馈层、一个注意池化层和另一个前馈层组成。
- 如果存在限制,则一个单独的文字处理模型将为此限制子句生成文字。当三个连接关键字中的任何一个存在时,例如,相交,我们将关键字的右侧部分视为嵌套查询,而左侧部分视为它的输出查询。
- 在此过程中,我们将正确部分的生成委托给上面解释的嵌套查询生成例程。
3.2.5 From 子句
- FROM子句的处理方式不同于其他CAT子句。它需要生成两部分:(1)要出现在查询中的表,以及(2)连接条件。
FROM 解码器网络专注于生成FROM子句中的表。特别地,我们将FROM子句中的表视为一个表的序列,因此生成该子句是一个标准的序列生成问题。
- From 解码器网络采用了一个标准的四层 transformer 架构来生成一系列的表嵌入。从每个嵌入中,我们将首先运行一个标准的两类分类器来分类它是表还是嵌套的 term_token。
- 如果是后者,我们将使用上面描述的嵌套查询扩展技术来处理它。
- 如果嵌入是一个表,我们使用一个指针网络从数据库中的所有表中选择一个表。这与在CAT解码器网络中用于生成列插槽的方法非常相似。唯一的区别是,这里的网络选择了一个表,而不是一列。
这里的连接条件生成算法不使用任何学习算法,但在生成的FROM子句生成的表上运行最小生成树算法。
- 一旦我们生成了一组 𝑘 个表的序列,即𝑡1,𝑡2,…,𝑡𝑘,我们就生成连接条件来连接它们。
- 为此,我们构建了一个带有 𝑘 个节点的图,以便每个表 𝑡𝑖 对应于图中的一个节点 𝑛𝑖 。
- 对于两个表 𝑡𝑖 和 𝑡𝑗,如果在 𝑡𝑖 和 𝑡𝑗 之间有一个PK-FK关系,则在 𝑛𝑖 和 𝑛𝑗 之间建立一条边,标记权重为
|𝑖−𝑗|,表示FROM子句中两个表之间的距离。 - 另外,如果 𝑡𝑖 和 𝑡𝑗 是同一个表,我们将构建一条边,将 𝑛𝑖 和 𝑛𝑗 连接到权重 |𝑖−𝑗|。
- 在这张图中,每条边都表示一个 PK-FK 连接条件或一个自连接条件。
在这个图上,我们运行一个最小生成树算法来得到一组具有最小总权值的 𝑘−1 边。如果图没有连通,那么我们得到每个连通子图的一个最小生成树。最小生成树上的所有边都将在生成的查询中转换为连接条件。
- 一些现有的方法在生成表序列时也采用了类似的方法,但在生成连接条件的方式上有所不同。对于每个生成的表𝑡𝑖,现有的模型试图找到 𝑡𝑖−1 和 𝑡𝑖 之间的PK-FK关系,并将其作为连接条件。当此例程失败时,它不会为 𝑡𝑖 生成连接条件。
- 请注意,由于两个表 𝑡𝑖 和 𝑡𝑗 之间的权重是|𝑖−𝑗|,如果 𝑡𝑖 与 𝑡𝑖−1 有PK-FK关系,那么它将更愿意选择这种关系(它的最小权重为1)。
- 因此,当现有的方法生成正确的 FROM 子句时,我们的算法的行为是相同的。同时,当这种关系不存在时,我们的方法可以更好地推广。在此情况下,我们需要寻求进一步的PK-FK关系或自连接关系来形成连接条件。
一旦预测了FROM子句,就会通过组装所有不同的CAT子句和FROM子句来构造一个原子SQL查询。如果查询中出现嵌套的 term_token,则迭代调用模型,直到展开所有嵌套标记,并且没有预测新的嵌套标记。
3.3 语义校正
本节将介绍语义校正技术,它通过利用数据库领域知识显著提高了准确性。虽然深度学习模型在理解问题的意图方面是有效的,但有时生成的SQL查询也表达了相同的意图,但考虑到数据库模式,它在语义上是无效的。
将这些语义约束合并到基于神经网络的SQL生成过程中是一项挑战。原因是:
- 神经网络方法通常是一种连续优化方法,但语义约束大多是需要满足的离散规则。
作者提出的语义校正技术是作为一种基于规则的方法来后处理生成的查询,并尽最大努力尝试修复明显的语义错误。我们将语义修正规则分为三类:(1) token 级别的违反、(2) FROM子句修订、和 (3) 连接路径修订。
3.3.1 token 级别的违反
这种类型的语义错误是最容易修复的。让我们来看看下面的例子:

由于列 petType 采用的是分类值,因此计算此列的平均值没有意义。在这种情况下,我们认为CAT中对应于AVG(petType)的AGG槽不能取AVG的值。因此,token 级别的违反规则将在解码过程中以输出概率 0 掩盖这样一个无效值。
- 这种类型的冲突很容易处理,因为它只需要检查部分生成的查询的一小部分,而不需要对整个查询的深入理解。
3.3.2 FROM 子句修订
- 这种类型的冲突是,查询体使用了一些没有出现在FROM子句中的表中的列。
在这种情况下,我们更倾向于考虑WHERE 子句更可信,因为它捕获了更多的自然语言问题的语义。因此,我们将把缺失的表添加到FROM子句的末尾。此外,我们还将为新添加的表生成连接条件。我们可以使用相同的最小生成树技术来生成这些连接条件。
3.3.3 连接路径修订
在许多涉及嵌套查询的情况下,连接路径很容易出错。让我们查看以下SQL查询:

在本例中,国家表中的列 name 与在嵌套查询中生成的 国家语言表 中的 isofficial 列没有FK关系。在这种情况下,我们将尝试重建一个正确的连接路径。
- 特别地,当一个查询涉及到 c1 op (SELECT c2 FROM t2 ) 时 ,我们要求c1和c2有一个 PK-FK 关系。
- 当这个要求没有得到满足时,我们会尝试用最小的修改来重写它。
- 特别地,在这种情况下,我们假设(1) outter查询中的c1是正确的;并且(2) 嵌套查询中的列 c2 和 t2 都是正确的。
- 基于这两个假设,我们需要从模式图中重建一个连接 c1 到 t2 的连接路径,该模式图与构造 from 子句的连接条件类似。
在此过程中,上面的例子将被重写为以下内容:

4. 实验
4.1 基准数据集
其中,
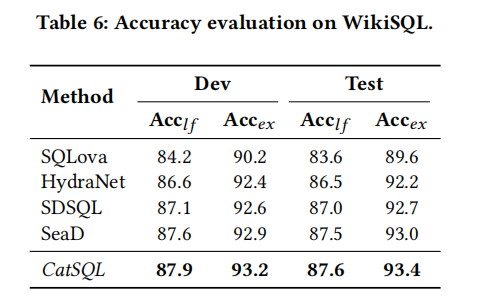
- WikiSQL的缺点是它的查询只使用selecet和位置,而提供了FROM子句,不涉及其他复杂操作符。
- Spider被认为是目前最困难的NL2SQL数据集。Spider支持更丰富的SQL语法,它根据数据集的硬度级别将其分为四类:
- Easy。单表查询;
- 中。使用 GROUP BY, ORDER BY and HAVING;
- 困难的。在多个表上使用 JOIN 并设置操作;
- 非常困难的。嵌套查询。
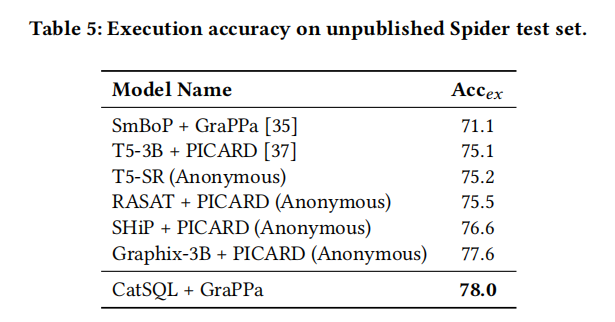
- WikiSQL和Spider都将数据分割为训练/开发/测试。采用train对模型进行训练;采用dev评价模型在训练过程中的性能,避免过拟合;训练后进行评价。Spider有一个不公开的单独的保留测试数据集。
- 为了避免歧义,在这项工作中,所有报告的结果都只在公开可用的数据集上进行评估。
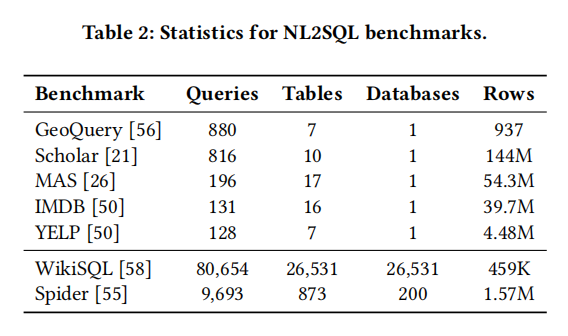
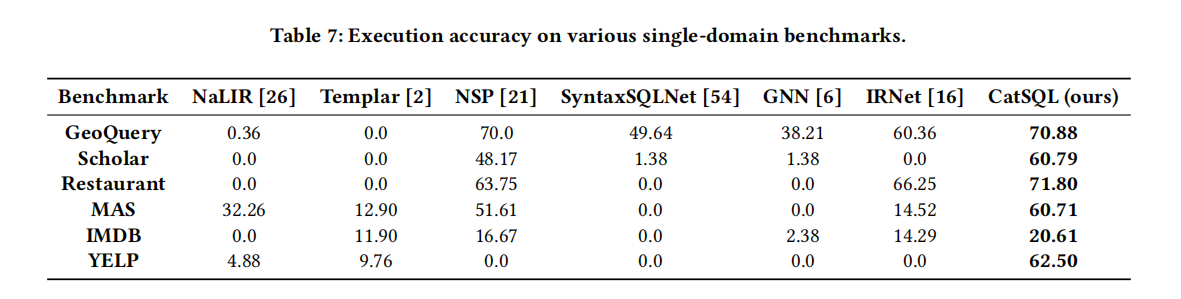
- 此外,还使用了几个经典的单域NL2SQL基准测试,包括 GeoQuery [21, 32, 56, 57], Scholar [21], MAS
[26], IMDB [50], and YELP [50],从而对我们的CatSQL方法和现有的NL2SQL系统进行了公平的比较。这些统计数据列于表2之中。
4.2 评价指标
为了评估方法的准确性,主要关注所谓的执行准确性(即Accex)指标。对于每个测试用例,我们将运行不同的系
统来获得生成SQL,并对基础数据库执行SQL查询,并将结果与黄金标准进行比较。
NL2SQL社区还使用了另一个称为逻辑形式准确性的指标(即Acclf)。当生成的SQL查询与黄金标准完全匹配时,这个指标会认为它是正确的。在Spider中,由于SQL文字可能不会出现在自然语言问题中,在其Acclf计算中,它不要求文字相同;因此,在计算Spider上的Acclf时,如果所有其他关键字和列完全匹配金标准,但文字可能是错误的,则生成的SQL查询被认为是正确的。显然,这个指标不像执行精度实用,因为(1)一个实用的NL2SQL应用程序要求生成的文字是正确的;(2)语法不同但语义等价的SQL查询应该被认为是正确的,因为它不会改变执行结果。对于Spider和WikiSQL基准测试,我们还提供了逻辑形式的精度结果作为NLP文献的参考。
此外,我们还报告了一个被称为可执行率的新指标。此度量报告底层数据库引擎可以成功执行的生成SQL查询的部分。为了评估速度,我们将使用相同的硬件设置来评估不同的方法,并报告每秒生成的查询数量。
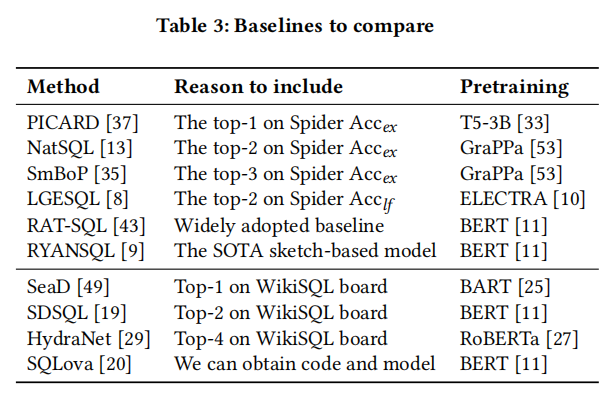
4.3 基线方法
4.4 实验结果
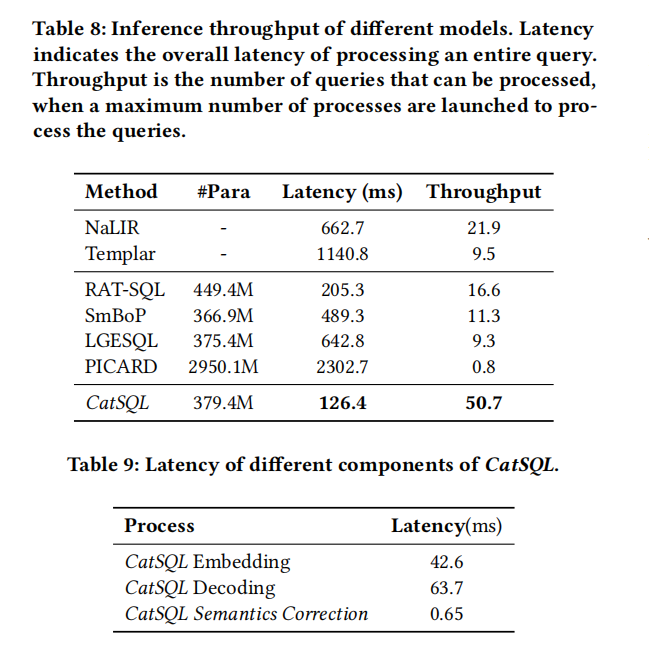
5.总结
在本文中,作者考虑了NL2SQL问题,并将现有的基于规则的解决方案和基于深度学习的解决方案结合起来,以在准确性和吞吐量方面实现显著的改进。
- 首先,作者设计了CatSQL,一个基于草图的NL2SQL解决方案,它被设计为快速和准确。
- 其次,开发了语义校正技术,这是第一个利用数据库领域知识来提高基于深度学习的NL2SQL算法的性能的工作。
- 实验结果表明,方法在广泛的基准中显著优于以前的方法。特别是,在最先进的跨域NL2SQL基准测试Spider上,我们的方法可以在执行精度上比以前的最先进的解决方案提高4分,同时实现高达63×更大的吞吐量。