pandas
- pandas 的核心是:‘Series’、‘DataFrame’、'Index’三个类型
1. 创建DataFrame对象
1.1 通过二维数组创建
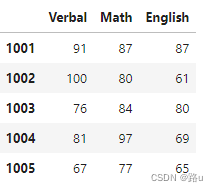
scores = np.random.randint(60,101,(5,3))
scores
'''
array([[ 91, 87, 87],
[100, 80, 61],
[ 76, 84, 80],
[ 81, 97, 69],
[ 67, 77, 65]])
'''
df1=pd.DataFrame(data=scores,
columns=['Verbal','Math','English'],
index=np.arange(1001,1006))
df1
1.2 字典提供数据创建
my_dict = {
'Verbal': [91,93,89,75,60],
'Math': [77,80,85,79,74],
'Rnglish': [88,78,91,67,86]
}
my_dict
'''
{'Verbal': [91, 93, 89, 75, 60],
'Math': [77, 80, 85, 79, 74],
'Rnglish': [88, 78, 91, 67, 86]}
'''
# 方法2:通过字典提供数据创建DataFrame对象
df2 = pd.DataFrame(data=my_dict, index=np.arange(1001,1006))
1.3 通过csv文件创建
df3 = pd.read_csv(
'E:/文档/excel/2018年北京积分落户数据.csv',
index_col='id', # 指定索引列
encoding='utf-8',
sep=',', # 字段分隔符,默认值为','
# header=0 # 指定表头在第几行(从0开始)
# quoterchar='`', # 去掉包裹字符串的符号(默认英文上引号)
# usecols=['id','name','score'], # 读取指定行
# nrows=20, # 限制读取行数
# skiprows=np.arange(1,21), # 跳过行号
# 数据过大时可用:
# iterator=True, # 启用迭代器模式
# chunksize=1000 # 每次加载的数据体量
)
df3
1.4 通过Excel创建
df5 = pd.read_excel(
'E:/文档/excel/2020年销售数据 (2).xlsx',
sheet_name='data', # 指定工作表名字
header=1, # 指定表头
)
df5
1.5 从关系型数据库二维表加载
# 方法1
import pymysql
conn = pymysql.connect(host='***', port=3306,
user='***', password='***',
database='***',charset='utf8mb4'
)
conn
%pip install -U pymysql "sqlalchemy<2.0"
# 方法2
from sqlalchemy import create_engine
# URL - 统一资源定位符
# 协议+自协议://用户名:口令@域名或IP地址:端口/路径/资源名称
engine = create_engine('mysql+pymysql://用户名:密码@域名或IP地址:3306/库名')
engine
df7 = pd.read_sql_query('select * from tb_dept', engine, index_col='dno')
df9 = pd.read_sql_table('tb_dept', engine, index_col='eno')
df8 = pd.read_sql('select * from tb_emp',conn, index_col='eno')
df8 = pd.read_sql_query('select * from tb_dept natural join tb_emp', engine, index_col='dno')
df10 = pd.read_sql('tb_emp2',engine,index_col='eno')
2.索引
2.1 行索引:index
# 行索引
df1.index # Index([1001, 1002, 1003, 1004, 1005], dtype='int32')
# 行索引的值
df1.index.values # array([1001, 1002, 1003, 1004, 1005])
df1.index.tolist() # [1001, 1002, 1003, 1004, 1005]
2.2 列索引:columns
# 列索引
df1.columns
# Index(['Verbal', 'Math', 'English'], dtype='object')
# 列索引的值
df1.columns.values # array(['Verbal', 'Math', 'English'], dtype=object)
df1.values
'''
array([[ 91, 87, 87],
[100, 80, 61],
[ 76, 84, 80],
[ 81, 97, 69],
[ 67, 77, 65]])
'''
2.3 取列
df1.Math
'''
1001 87
1002 80
1003 84
1004 97
1005 77
Name: Math, dtype: int32
'''
type(df1.Math) # pandas.core.series.Series
2.4 取行
df1.loc[1003]
'''
Verbal 76
Math 84
English 80
Name: 1003, dtype: int32
'''
2.4 获取单元格
# (1)先行后列
df1.loc[1003]['English'] # 80
# (2)先列后行
df1['English'][1003]
#(3)at
df1.at[1003,'English']
2.5 修改单元格
df1.at[1003,'English']=88
2.6 添加行/列
# 添加行
df1.loc[1006] = [77,88,78]
df1
# 添加列
df1['评级'] = ['A','B','C','D','A','B']
df1
df1.insert(1, 'married', True)
df1
2.6 取前/后几行
df1.head()
df1.tail()
2.7 取消索引
df10.reset_index(inplace=True)
2.8 重设索引
df10.set_index('eno',inplace=True)
3.数据重塑
merge、concat
# 连接两表
# 有相同列名时
pd.merge(df7,df8,on='dno',how='left')
rename
# 修改列名
df8.rename(columns={'dno':'depyno'},inplace=True)
# 列名不相同时连接两个表
pd.merge(df7,df8,left_on='dno',right_on='depyno',how='inner')
# 数据拼接(通常用于数据结构相同的DataFrame对象)
df11 = pd.concat((df8,df10))
删除行、列
# 删除行/列
df11.drop(columns=['mgr','comm'],index=[9700])
4. 数据清洗
4.1 空值处理
1)判断空值
# 判断空值,显示的是TRUE和FALSE
df11.isna()
df11.isnull()
2)替换
# 将comm字段的空值填为0
df11.comm.fillna(0,inplace=True)
# 替换操作
df11.comm.replace(0,np.nan,inplace=True)
# 将空值替换成它的上/下一个值
# 上一个:ffill 下一个:bfill
df11.comm.fillna(method='ffill')
3) 删除
# 根据布尔索引删除补贴为空值的员工
df11.drop(index=df11[df11.comm.isna()].index,inplace=True)
# 删除有空值的列
df11.dropna(axis=1)
4)判断非空值
# 判断非空值
df5.notna()
df5.notnull()
# 获取job字段中非空值内容
df5[df5.job.isna()].index
# 通过布尔索引获取job字段为空的员工索引,然后删除这个员工
df5.drop(index=df5[df5.job.isna()].index, inplace=True)
# 删除有空值的行
df5.dropna()
# 删除有空值的列
df5.dropna(axis=1)
4.2 重复值
1)判断重复值
# 判断重复
df5.duplicated(['ename', 'job'])
2)删除重复数据
# 删除重复数据
# keep - 'first' / 'last' / False
df5.drop_duplicates(['ename', 'job'], keep='last', inplace=True)
df5.comm.duplicated()
3)统计重复值
# 统计有多少个不重复数据
df5.comm.nunique()
# 统计每个元素重复的次数(按次数从高到低排列)
df5.comm.value_counts()
# 获取独一无二的元素构成的数组
df5.comm.unique()
4.4 异常值
temp = np.random.randint(1, 100, 100)
temp = np.append(temp, [180, 200, 250, -50, -100, -160])
plt.boxplot(temp, showmeans=True, sym='x')
plt.show()
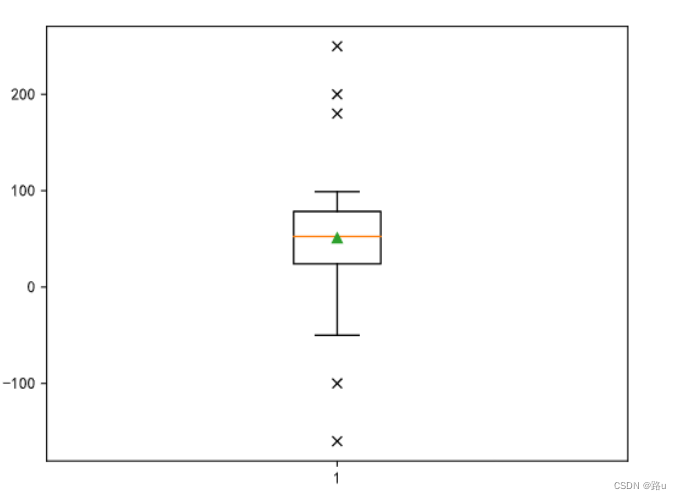
1)数值判定法
# 请设计一个函数,给入一个数组或数据系列,找出离群点返回
# 要求:用数值判定法对离群点进行甄别
def detect_outliers_by_iqr(data, whis=1.5):
"""甄别离群点(数值判定法)"""
q3, q1 = np.quantile(data, [0.75, 0.25])
iqr = q3 - q1
return data[(data < q1 - whis * iqr) | (data > q3 + whis * iqr)]
detect_outliers_by_iqr(temp)
detect_outliers_by_iqr(temp, whis=3)
2)Z-score:|𝑧|>3
𝑧=(𝑥𝑖-𝜇)/𝜎
def detect_outliers_by_zscore(data):
"""甄别离群点(zscore判定法)"""
mu, sigma = np.mean(data), np.std(data)
z = (data - mu) / sigma
return data[np.abs(z) > 3]
detect_outliers_by_zscore(temp)
4.5 预处理
# 案例:
jobs_df = pd.read_csv('../res/jobs.csv', index_col='id')
jobs_df.info()
# 删除uri、city字段(删除不需要字段)
jobs_df.drop(columns=['uri', 'city'], inplace=True)
jobs_df.tail(5)
# 从salary字段抽取出薪资的下限和上限并处理成平均值
salary = jobs_df.salary.str.upper().str.extract(r'(\d+)-(\d+)').astype('i8').mean(axis=1)
jobs_df = jobs_df.assign(salary=salary)
jobs_df['salary'] = salary
# 将地址site字段拆分为三个列
jobs_df[['city', 'district', 'stree']] = jobs_df.site.str.split(expand=True)
jobs_df.drop(columns=['site'], inplace=True)
jobs_df
# edu字段的高中和中专替换为学历不限
jobs_df.edu.unique()
jobs_df.edu.replace('高中|中专', '学历不限', regex=True, inplace=True)
# 通过job_name字段匹配关键词筛选数据
jobs_df['job_name'] = jobs_df.job_name.str.lower()
jobs_df = jobs_df[jobs_df.job_name.str.contains('python|数据分析', regex=True)]
# 重置索引并将清洗后的数据写入CSV文件
jobs_df.reset_index(drop=True, inplace=True)
jobs_df.index.name = 'id'
jobs_df.to_csv('res/cleaned_jobs.csv')