数据湖漫游指南
文件大小和文件数
文件格式
分区方案
使用查询加速
我如何管理对我的数据的访问?
我选择什么数据格式?
如何管理我的数据湖成本?
如何监控我的数据湖?
ADLS Gen2 何时是您数据湖的正确选择?
设计数据湖的关键考虑因素
术语
组织和管理数据湖中的数据
我想要集中式还是联合式数据湖实施?
如何组织我的数据?
优化数据湖以获得更好的规模和性能
推荐阅读
问题、意见或反馈?
Azure Data Lake Storage Gen2 (ADLS Gen2) 是用于大数据分析的高度可扩展且经济高效的数据湖解决方案。随着我们继续与客户合作,利用 ADLS Gen2 从他们的数据中发掘关键洞察,我们已经确定了一些关键模式和注意事项,可帮助他们在大规模大数据平台架构中有效利用 ADLS Gen2。
本文档记录了我们在与客户合作的基础上学到的这些注意事项和最佳实践。就本文档而言,我们将重点介绍我们的大型企业客户在 Azure 上大量使用的现代数据仓库模式,包括我们的解决方案,例如 Azure Synapse Analytics。
我们将改进此文档以在未来的迭代中包含更多分析模式。
重要提示:请将此文档的内容视为指导和最佳实践,以帮助您做出架构和实施决策。这不是官方的 HOW-TO 文档。
ADLS Gen2 何时是您数据湖的正确选择?#
企业数据湖旨在成为大数据平台中使用的非结构化、半结构化和结构化数据的中央存储库。企业数据湖的目标是消除数据孤岛(数据只能由组织的一部分访问)并促进单一存储层,以适应组织的各种数据需求有关选择正确的更多信息存储解决方案,请访问在 Azure 中选择大数据存储技术一文。
出现的一个常见问题是何时使用数据仓库与数据湖。我们敦促您将数据湖和数据仓库视为互补的解决方案,它们可以协同工作,帮助您从数据中获得关键见解。数据湖是存储来自各种来源的所有类型数据的存储库。自然形式的数据存储为原始数据,并在此原始数据上应用模式和转换,以根据业务试图回答的关键问题获得有价值的业务洞察力。数据仓库是高度结构化的模式化数据的存储,这些数据通常被组织和处理以获得非常具体的见解。例如。零售客户可以将过去 5 年的销售数据存储在数据湖中,此外,他们可以处理来自社交媒体的数据,从零售分析解决方案中提取消费和情报的新趋势,并利用所有这些作为输入一起生成一个数据集,可用于预测明年的销售目标。然后,他们可以将高度结构化的数据存储在数据仓库中,BI 分析师可以在其中构建目标销售预测。此外,他们可以使用数据湖中相同的销售数据和社交媒体趋势来构建智能机器学习模型,以在其网站上进行个性化推荐。
ADLS Gen2 是适用于大数据分析工作负载的企业级超大规模数据存储库。ADLS Gen2 通过分层命名空间提供更快的性能和 Hadoop 兼容访问,通过细粒度访问控制和本机 AAD 集成降低成本和安全性。这适合作为专注于大数据分析场景的企业数据湖的选择——使用转换从非结构化数据中提取高价值的结构化数据、使用机器学习的高级分析或实时数据摄取和分析以获得快速洞察力。值得注意的是,我们已经看到客户对超大规模的定义有不同的定义——这取决于存储的数据、交易数量和交易吞吐量。当我们说超大规模时,我们通常指的是数 PB 的数据和数百 Gbps 的吞吐量——这种分析所涉及的挑战与吞吐量中的数百 GB 数据和几 Gbps 的事务非常不同。
设计数据湖的关键考虑因素#
当您在 ADLS Gen2 上构建企业数据湖时,了解您对关键用例的需求很重要,包括
我在数据湖中存储了什么?
我在数据湖中存储了多少数据?
您在数据的哪一部分上运行分析工作负载?
谁需要访问我的数据湖的哪些部分?
我将在我的数据湖上运行哪些各种分析工作负载?
分析工作负载有哪些不同的事务模式?
我的工作预算是多少?
对于我们一直从客户那里听到的一些关键设计/架构问题,我们希望将本文档的其余部分固定在以下结构中。
有优缺点的可用选项
选择适合您的选项时要考虑的因素
适用时推荐的模式
您想要避免的反模式
为了最好地利用本文档,请确定您的关键场景和要求,并根据您的要求权衡我们的选项以决定您的方法。如果您无法选择完全适合您的场景的选项,我们建议您使用一些选项进行概念验证 (PoC),让数据指导您的决策。
术语#
在我们讨论构建数据湖的最佳实践之前,熟悉我们将在使用 ADLS Gen2 构建数据湖的上下文中使用的各种术语非常重要。本文档假设您在 Azure 中有一个帐户。
资源:可通过 Azure 获得的可管理项目。虚拟机、存储帐户、VNET 是资源的示例。
订阅:Azure 订阅是一个逻辑实体,用于分离 Azure 资源的管理和财务(计费)逻辑。订阅与 Azure 资源的限制和配额相关联,您可以在此处阅读有关它们的信息。
资源组:用于容纳 Azure 解决方案所需资源的逻辑容器可以作为一个组一起管理。您可以在此处阅读有关资源组的更多信息。
存储帐户:包含所有 Azure 存储数据对象的 Azure 资源:blob、文件、队列、表和磁盘。您可以在此处阅读有关存储帐户的更多信息。就本文档而言,我们将重点介绍 ADLS Gen2 存储帐户——它本质上是一个启用了分层命名空间的 Azure Blob 存储帐户,您可以在此处相关信息。
容器(也称为非 HNS 启用帐户的容器):一个容器组织一组对象(或文件)。一个存储帐户对容器的数量没有限制,容器可以存储无限数量的文件夹和文件。有些属性可以应用于容器级别,例如 RBAC 和 SAS 键。
文件夹/目录:文件夹(也称为目录)组织一组对象(其他文件夹或文件)。一个文件夹下可以创建多少个文件夹或文件没有限制。文件夹还具有与之关联的访问控制列表 (ACL),有两种类型的 ACL 与文件夹关联——访问 ACL 和默认 ACL,您可以在此处阅读有关它们的更多信息。
对象/文件:文件是保存可以读/写的数据的实体。一个文件有一个与之关联的访问控制列表。文件只有访问 ACL,没有默认 ACL。
组织和管理数据湖中的数据#
随着我们的企业客户制定他们的数据湖战略,ADLS Gen2 的关键价值主张之一是作为其所有分析场景的单一数据存储。请记住,这个单一数据存储是一个逻辑实体,根据设计考虑,它可以表现为单个 ADLS Gen2 帐户或多个帐户。一些客户拥有分析管道组件的端到端所有权,而其他客户则拥有一个中央团队/组织来管理数据湖的基础架构、运营和治理,同时为多个客户提供服务——无论是他们企业中的其他组织还是外部的其他客户到他们的企业。
在本节中,我们针对客户在设计企业数据湖时听到的一系列常见问题提出了我们的想法和建议。作为说明,我们将以大型零售客户 Contoso.com 为例,构建他们的数据湖策略以帮助处理各种预测分析场景。
我想要集中式还是联合式数据湖实施?#
作为企业数据湖,您有两种可用的选择——要么将所有数据管理集中在一个组织内以满足您的分析需求,要么拥有一个联合模型,您的客户管理他们自己的数据湖,而集中式数据团队提供指导并管理数据湖的几个关键方面,例如安全性和数据治理。重要的是要记住,集中式和联合数据湖策略都可以使用一个存储帐户或多个存储帐户来实施。
客户问我们的一个常见问题是,他们是否可以在单个存储帐户中构建数据湖,或者他们是否需要多个存储帐户。虽然从技术上讲,单个 ADLS Gen2 可以解决您的业务需求,但客户选择多个存储帐户的原因有多种,包括但不限于本节其余部分中的以下场景。
关键考虑#
在决定要创建的存储帐户数时,以下注意事项有助于决定要预配的存储帐户数。
单个存储帐户使您能够管理一组控制平面管理操作,例如存储帐户中所有数据的 RBAC、防火墙设置、数据生命周期管理策略,同时允许您使用容器、文件和存储帐户上的文件夹。如果您想优化以简化管理,特别是如果您采用集中式数据湖策略,这将是一个值得考虑的好模型。
多个存储帐户使您能够在不同帐户之间隔离数据,以便可以对它们应用不同的管理策略或单独管理它们的计费/成本逻辑。如果您正在考虑采用联合数据湖策略,每个组织或业务部门都有自己的一组可管理性要求,那么此模型可能最适合您。
让我们将这些方面放在一些场景的上下文中。
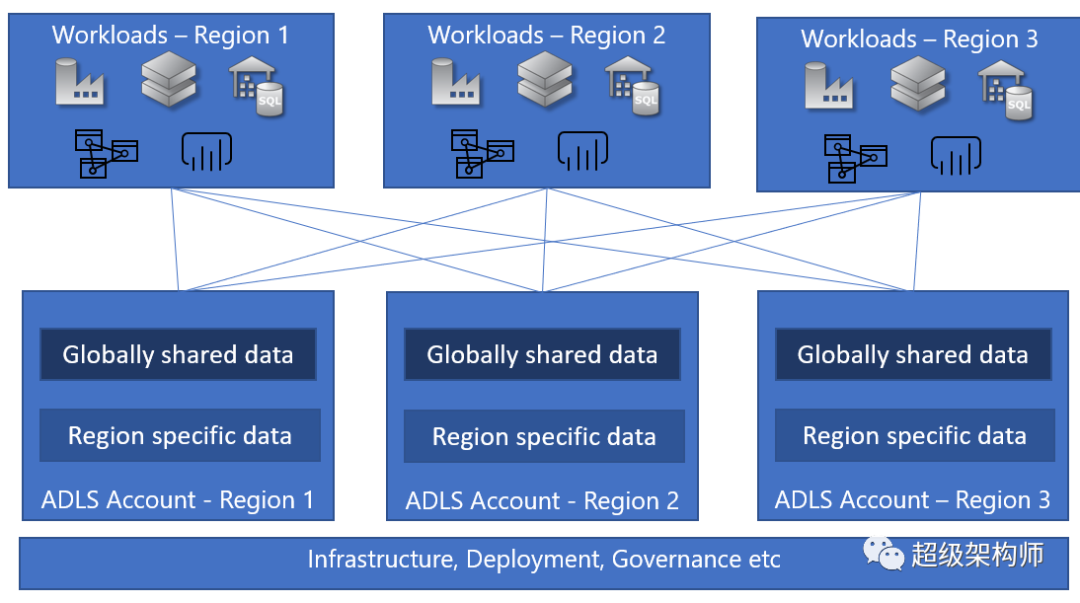
覆盖全球的企业数据湖#
在全球市场和/或地理分布的组织的推动下,有些情况下,企业的分析场景将多个地理区域考虑在内。数据本身可以分为两大类。
可以在所有地区全球共享的数据——例如Contoso 正在尝试规划下一个财政年度的销售目标,并希望从各个地区获取销售数据。
需要隔离到一个区域的数据——例如Contoso 希望根据买家的个人资料和购买模式提供个性化的买家体验。鉴于这是客户数据,需要满足主权要求,因此数据不能离开该区域。
在这种情况下,客户将提供特定于区域的存储帐户来存储特定区域的数据并允许与其他区域共享特定数据。这里仍然有一个集中的逻辑数据湖,其中包含一组由多个存储帐户组成的中央基础设施管理、数据治理和其他操作。
客户或数据特定隔离#
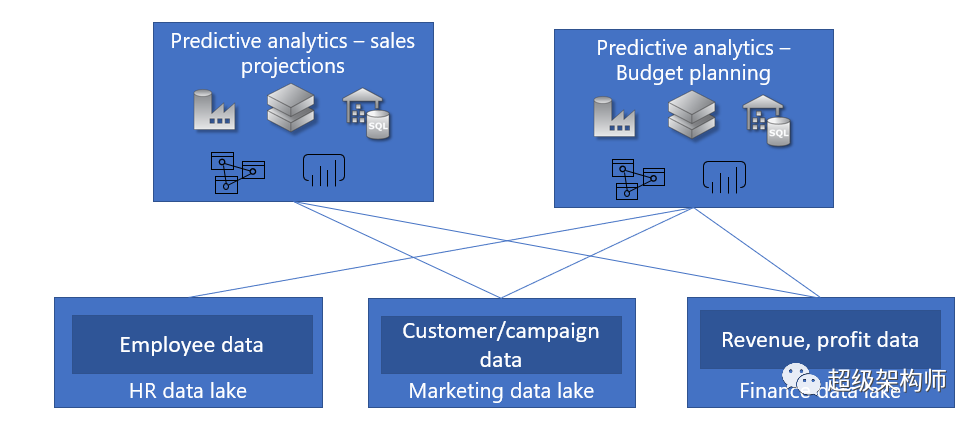
存在企业数据湖服务于多个客户(内部/外部)场景的场景,这些场景可能会受到不同的要求——不同的查询模式和不同的访问要求。让我们以我们的 Contoso.com 为例,他们有分析方案来管理公司运营。在这种情况下,他们拥有各种数据源——员工数据、客户/活动数据和财务数据,这些数据受不同治理和访问规则的约束,也可能由公司内的不同组织管理。在这种情况下,他们可以选择为各种数据源创建不同的数据湖。
在另一种情况下,作为为多个客户提供服务的多租户分析平台的企业最终可能会为不同订阅中的客户提供单独的数据湖,以帮助确保客户数据及其相关的分析工作负载与其他客户隔离,以帮助管理他们的成本和计费模式。
建议#
为您的开发和生产环境创建不同的存储帐户(最好在不同的订阅中)。除了确保需要不同 SLA 的开发和生产环境之间有足够的隔离之外,这还有助于您有效地跟踪和优化管理和计费策略。
确定数据的不同逻辑集,并考虑以统一或隔离的方式管理它们的需求——这将有助于确定您的帐户边界。
从一个存储帐户开始您的设计方法,并考虑为什么需要多个存储帐户(隔离、基于区域的要求等)而不是相反的原因。
其他资源(例如 VM 核心、ADF 实例)也有订阅限制和配额——在设计数据湖时要考虑这些因素。
反模式#
谨防多重数据湖管理#
当您决定 ADLS Gen2 存储帐户的数量时,请确保针对您的消费模式进行优化。如果您不需要隔离并且您没有充分利用您的存储帐户的功能,您将承担管理多个帐户的开销,而没有有意义的投资回报。
来回复制数据#
当您拥有多个数据湖时,您需要谨慎对待的一件事是您是否以及如何跨多个帐户复制数据。这会产生一个管理问题,即真相的来源是什么以及它需要有多新鲜,并且还会消耗涉及来回复制数据的事务。如果您有一个合法的方案来复制您的数据,我们的路线图中有一些功能可以使此工作流程更容易。
可扩展性注释#
我们的客户问的一个常见问题是,单个存储帐户是否可以无限地继续扩展以满足他们的数据、事务和吞吐量需求。我们在 ADLS Gen2 中的目标是满足客户所需的极限。当您遇到需要真正存储大量数据(数 PB)并需要帐户支持真正大的事务和吞吐量模式(数万 TPS 和数百 Gbps 吞吐量)的场景时,我们确实要求),通常通过 Databricks 或 HDInsight 进行分析处理需要 1000 个计算能力核心,请联系我们的产品组,以便我们可以计划适当地支持您的要求。
如何组织我的数据?#
ADLS Gen2 帐户中的数据组织可以在容器、文件夹和文件的层次结构中按顺序完成,如我们上面所见。当我们与客户合作制定他们的数据湖策略时,一个非常常见的讨论点是他们如何最好地组织他们的数据。有多种方法可以在数据湖中组织数据,本节记录了许多构建数据平台的客户采用的通用方法。
该组织跟踪数据的生命周期,因为它通过源系统一直流向最终消费者——BI 分析师或数据科学家。例如,让我们跟随销售数据通过 Contoso.com 的数据分析平台的旅程。
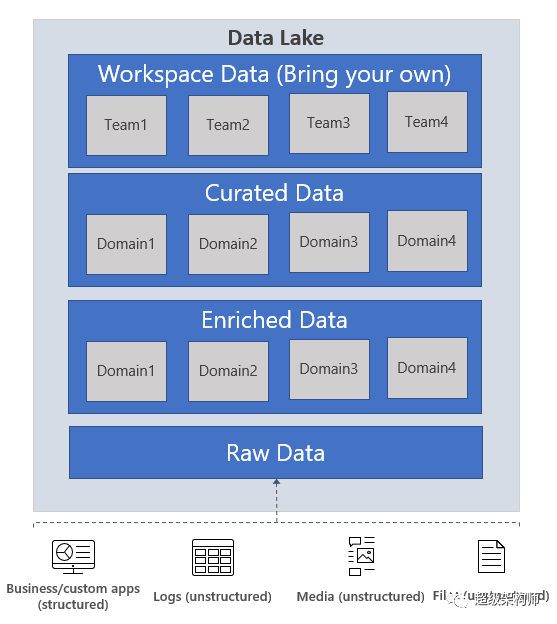
例如,将原始数据视为自然状态下有水的湖泊/池塘,数据按原样摄取和存储,未经转换,丰富的数据是水库中的水,经过清洗并以可预测的状态存储(以我们的数据为例),策划的数据就像准备消费的瓶装水。工作区数据就像一个实验室,科学家可以在其中携带自己的数据进行测试。值得注意的是,虽然所有这些数据层都存在于单个逻辑数据湖中,但它们可能分布在不同的物理存储帐户中。在这些情况下,拥有 Metastore 有助于发现。
原始数据:这是来自源系统的数据。此数据按原样存储在数据湖中,并由分析引擎(例如 Spark)使用以执行清理和充实操作以生成精选数据。原始区域中的数据有时也存储为聚合数据集,例如在流场景的情况下,数据通过消息总线(如事件中心)摄取,然后通过实时处理引擎(如 Azure Stream 分析或 Spark Streaming)聚合,然后存储在数据湖中。根据您的业务需求,您可以选择保持数据原样(例如来自服务器的日志消息)或聚合它(例如实时流数据)。这一层数据由中央数据工程团队高度控制,很少被其他消费者访问。根据您企业的保留策略,此数据要么在保留策略要求的期限内按原样存储,要么在您认为数据不再使用时将其删除。例如。这将是从在其本地系统中运行的 Contoso 的销售管理工具中提取的原始销售数据。
丰富的数据:这一层数据是原始数据(按原样或聚合)具有定义模式的版本,并且数据经过清理、丰富(与其他来源),可供分析引擎使用以提取高价值数据。数据工程师生成这些数据集,并继续从这些数据集中提取高价值/精选数据。例如。这将是丰富的销售数据 - 确保销售数据被模式化,丰富了其他产品或库存信息,并为 Contoso 内部的不同业务部门分成多个数据集。
精选数据:这一层数据包含提供给数据消费者(BI 分析师和数据科学家)的高价值信息。该数据具有结构,可以按原样(例如数据科学笔记本)或通过数据仓库提供给消费者。该层中的数据资产通常受到高度管理和良好记录。例如。业务部门的高质量销售数据(即与其他需求预测信号(如社交媒体趋势模式)相关的丰富数据区域中的数据),用于预测分析以确定下一财政年度的销售预测。
工作区数据:除了数据工程团队从源头摄取的数据之外,数据的消费者还可以选择带来其他可能有价值的数据集。在这种情况下,数据平台可以为这些消费者分配工作空间,以便他们可以使用精选数据以及他们带来的其他数据集来生成有价值的见解。例如。数据科学团队正在尝试确定新地区的产品放置策略,他们可以带来其他数据集,例如客户人口统计数据和该地区其他类似产品的使用数据,并使用高价值的销售洞察数据来分析产品市场契合度和发行策略。
存档数据:这是您组织的数据“保险库” - 存储的数据主要符合保留策略,并且具有非常严格的用途,例如支持审计。您可以使用 ADLS Gen2 中的 Cool 和 Archive 层来存储此数据。您可以阅读有关我们的数据生命周期管理政策的更多信息,以确定适合您的计划。
关键考虑#
在决定数据结构时,请考虑数据本身的语义以及访问数据的消费者,以确定适合您的数据组织策略。
建议#
为不同的数据区域创建不同的文件夹或容器(更多关于文件夹与容器之间的注意事项) - 原始数据集、丰富数据集、策划数据集和工作区数据集。
在一个区域内,选择根据逻辑分隔在文件夹中组织数据,例如日期时间或业务单位或两者兼而有之。您可以在我们的最佳实践文档中找到有关目录布局的更多示例和场景。
在设计文件夹结构时考虑分析使用模式。例如。如果您有一个 Spark 作业读取过去 3 个月内来自特定地区的产品的所有销售数据,那么理想的文件夹结构是 /enriched/product/region/timestamp。
在决定文件夹结构时,请考虑您希望遵循的访问控制模型。
下表提供了一个框架,供您考虑数据的不同区域以及具有常见模式的区域的相关管理。
| 考虑 | 原始数据 | 丰富的数据 | 策划的数据 | 工作空间数据 |
|---|---|---|---|---|
| 消费者 | 数据工程团队 | 数据工程团队,由数据科学家/BI分析师提供临时访问模式 | 数据工程师、BI分析师、数据科学家 | 数据科学家/BI分析师 |
| 访问控制 | 数据工程团队已锁定访问权限 | 完全控制数据工程团队,并对BI分析师/数据科学家具有读取权限 | 完全控制数据工程团队,对BI分析师/数据科学家具有读写权限 | 完全控制数据工程师、数据科学家/BI 分析师 |
| 数据生命周期管理 | 一旦生成了丰富的数据,就可以将其移动到较冷的存储层以管理成本。 | 较旧的数据可以移动到较冷的层。 | 较旧的数据可以移动到较冷的层。 | 虽然最终消费者可以控制这个工作区,但要确保有清理不必要数据的流程和策略——例如,使用基于策略的 DLM,数据可以很容易地建立起来。 |
| 文件夹结构和层次结构 | 文件夹结构以反映摄入模式。 | 文件夹结构反映组织,例如业务部门。 | 文件夹结构反映组织,例如业务部门。 | 文件夹结构反映了工作区所使用的团队。 |
| 实例 | /raw/sensordata /raw/lobappdata /raw/userclickdata | /enriched/sales /enriched/ manufacturing | /curated/sales /curated/ manufacturing | /workspace/salesBI /workspace/ manufacturin datascience |
我们的客户询问何时使用容器以及何时使用文件夹来组织数据的另一个常见问题。虽然在更高级别,它们都用于数据的逻辑组织,但它们有一些关键区别。
| 考虑 | 容器 | 文件夹 |
|---|---|---|
| 等级 | 容器可以包含文件夹或文件。 | 文件夹可以包含其他文件夹或文件。 |
| 使用AAD的访问控制 | 在容器级别,可以使用RBAC设置粗粒度的访问控制。这些RBAC适用于容器内的所有数据。 | 在文件夹级别,可以使用ACL设置细粒度的访问控制。ACL仅适用于该文件夹(除非使用默认ACL,在这种情况下,在该文件夹下创建新文件/文件夹时会对其进行快照)。 |
| 非AAD访问控制 | 在容器级别,可以启用匿名访问(通过共享密钥)或设置特定于容器的SAS密钥。 | 文件夹不支持非AAD访问控制。 |
反模式#
不相关数据无限增长#
虽然 ADLS Gen2 存储不是很昂贵,并且允许您在存储帐户中存储大量数据,但即使您不需要整个数据语料库,生命周期管理策略的缺失也可能最终导致存储中数据的增长非常快为您的方案。我们看到这种数据增长的两种常见模式是:-
使用较新版本的数据刷新数据——客户通常会保留一些较旧版本的数据以供分析,当同一数据有一段时间刷新时,例如当上个月的客户参与数据在 30 天的滚动窗口中每天刷新时,您每天都会获得 30 天的参与数据,如果您没有适当的清理流程,您的数据可能会呈指数级增长。
工作区数据积累——在工作区数据区,您的数据平台的客户,即 BI 分析师或数据科学家可以带来他们自己的数据集 通常,我们已经看到,当未使用的数据是留在存储空间周围。
我如何管理对我的数据的访问?#
ADLS Gen2 支持结合 RBAC 和 ACL 来管理数据访问的访问控制模型。您可以在此处找到有关访问控制的更多信息。除了使用 RBAC 和 ACL 使用 AAD 身份管理访问之外,ADLS Gen2 还支持使用 SAS 令牌和共享密钥来管理对 Gen2 帐户中数据的访问。
我们从客户那里听到的一个常见问题是何时使用 RBAC 以及何时使用 ACL 来管理对数据的访问。RBAC 允许您将角色分配给安全主体(AAD 中的用户、组、服务主体或托管标识),并且这些角色与容器中数据的权限集相关联。RBAC 可以帮助管理与控制平面操作(例如添加其他用户和分配角色、管理加密设置、防火墙规则等)或数据平面操作(例如创建容器、读写数据等)相关的角色。有关 RBAC 的更多信息,您可以阅读这篇文章。
RBAC 本质上仅限于顶级资源——ADLS Gen2 中的存储帐户或容器。您还可以在资源组或订阅级别跨资源应用 RBAC。ACL 允许您将安全主体的一组特定权限管理到更窄的范围 - ADLS Gen2 中的文件或目录。有 2 种类型的 ACL——访问 ADL 控制对文件或目录的访问,默认 ACL 是为与目录关联的目录设置的 ACL 模板,这些 ACL 的快照由在下创建的任何子项继承那个目录。
关键考虑#
下表提供了如何使用 ACL 和 RBAC 来管理 ADLS Gen2 帐户中数据权限的快速概览——在较高级别,使用 RBAC 来管理粗粒度权限(适用于存储帐户或容器)并使用用于管理细粒度权限的 ACL(适用于文件和目录)。
| Consideration | RBACs | ACLs |
|---|---|---|
| Scope | Storage accounts, containers. Cross resource RBACs at subscription or resource group level. | Files, directories |
| Limits | 2000 RBACs in a subscription | 32 ACLs (effectively 28 ACLs) per file, 32 ACLs (effectively 28 ACLs) per folder, default and access ACLs each |
| Supported levels of permission | Built-in RBACs or custom RBACs | ACL permissions |
在容器级别使用 RBAC 作为数据访问控制的唯一机制时,请注意 2000 的限制,尤其是在您可能拥有大量容器的情况下。您可以在门户的任何访问控制 (IAM) 刀片中查看每个订阅的角色分配数量。
建议#
为对象(通常是我们在客户那里看到的目录中的目录)创建所需权限级别的安全组,并将它们添加到 ACL。对于要提供权限的特定安全主体,请将它们添加到安全组,而不是为它们创建特定的 ACL。遵循这种做法将帮助您最大限度地减少管理新身份访问的过程——如果您想将新身份递归添加到容器中的每个文件和文件夹,这将需要很长时间。让我们举一个例子,您的数据湖中有一个目录 /logs,其中包含来自服务器的日志数据。您可以通过 ADF 将数据摄取到此文件夹中,还可以让服务工程团队的特定用户上传日志并管理其他用户到此文件夹。此外,您还有各种 Databricks 集群分析日志。您将创建 /logs 目录并创建两个具有以下权限的 AAD 组 LogsWriter 和 LogsReader。
LogsWriter 添加到具有 rwx 权限的 /logs 文件夹的 ACL。
LogsReader 添加到具有 r-x 权限的 /logs 文件夹的 ACL。
ADF 的 SPN/MSI 以及用户和服务工程团队可以添加到 LogsWriter 组。
Databricks 的 SPN/MSI 将添加到 LogsReader 组。
我选择什么数据格式?#
数据可能以多种格式到达您的数据湖帐户——人类可读的格式,如 JSON、CSV 或 XML 文件,压缩的二进制格式,如 .tar.gz 和各种大小——巨大的文件(几 TB),如从本地系统导出 SQL 表或从 IoT 解决方案导出大量小文件(几 KB),例如实时事件。虽然 ADLS Gen2 支持在不施加任何限制的情况下存储所有类型的数据,但最好考虑数据格式以最大限度地提高处理管道的效率并优化成本——您可以通过选择正确的格式和正确的文件大小来实现这两个目标。Hadoop 有一组它支持的文件格式,用于优化存储和处理结构化数据。让我们看看一些常见的文件格式——Avro、Parquet 和 ORC。所有这些都是机器可读的二进制文件格式,提供压缩来管理文件大小,并且本质上是自描述的,文件中嵌入了模式。格式之间的区别在于数据的存储方式——Avro 以基于行的格式存储数据,而 Parquet 和 ORC 格式以列格式存储数据。
关键考虑#
Avro 文件格式适用于 I/O 模式更重的写入或查询模式倾向于完整检索多行记录。例如。Avro 格式受到消息总线的青睐,例如 Event Hub 或 Kafka 连续写入多个事件/消息。
当 I/O 模式读取量更大和/或查询模式专注于记录中的列的子集时,Parquet 和 ORC 文件格式受到青睐——其中可以优化读取事务以检索特定列而不是读取整个记录。
如何管理我的数据湖成本?#
ADLS Gen2 为您的分析场景提供数据湖存储,目标是降低您的总拥有成本。可以在此处找到 ADLS Gen2 的定价。由于我们的企业客户满足多个组织的需求,包括中央数据湖上的分析用例,他们的数据和交易往往会急剧增加。由于很少或没有集中控制,相关成本也会增加。本部分提供了可用于管理和优化数据湖成本的关键注意事项。
关键考虑#
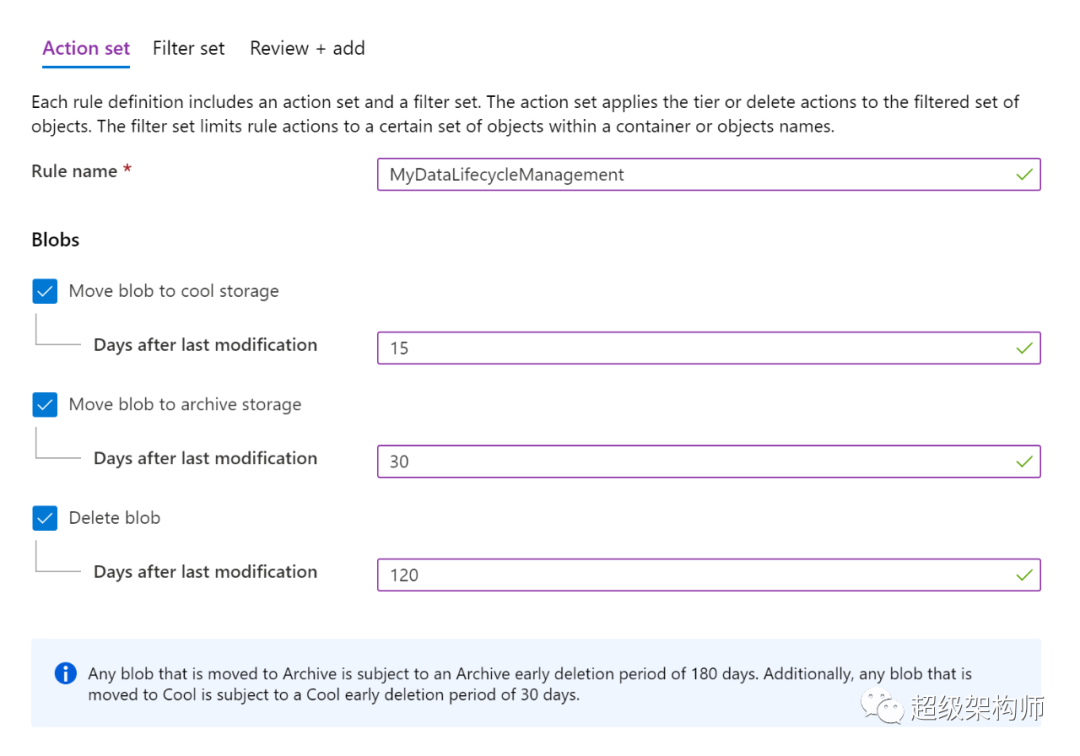
ADLS Gen2 提供策略管理,您可以使用它来利用存储在您的 Gen2 帐户中的数据的生命周期。您可以在此处阅读有关这些政策的更多信息。例如。如果您的组织有保留数据 5 年的保留策略要求,您可以设置策略以在数据 5 年未修改时自动删除数据。如果您的分析方案主要对上个月摄取的数据进行操作,您可以将早于该月的数据移动到较低的层(冷层或存档层),这些层的数据存储成本较低。请注意,较低层的静态数据价格较低,但交易策略较高,因此如果您希望频繁处理数据,请不要将数据移动到较低层。
确保您为您的帐户选择了正确的复制选项,您可以阅读数据冗余文章以了解有关您的选项的更多信息。例如。虽然 GRS 账户确保您的数据跨多个区域复制,但它的成本也高于 LRS 账户(数据在同一数据中心复制)。当您拥有生产环境时,GRS 等复制选项对于通过高可用性和灾难恢复确保业务连续性非常有价值。但是,LRS 帐户可能足以满足您的开发环境。
正如您从 ADLS Gen2 的定价页面中看到的,您的读写交易按 4 MB 的增量计费。例如。如果您执行 10,000 次读取操作,并且每次读取的文件大小为 16 MB,则您需要为 40,000 次交易付费。当您在事务中读取几 KB 的数据时,您仍需为 4 MB 的事务付费。优化单个事务中的更多数据,即优化事务中的更高吞吐量不仅可以节省成本,还可以极大地提高您的性能。
如何监控我的数据湖?#
了解您的数据湖的使用方式及其执行方式是操作您的服务并确保它可供使用其中包含的数据的任何工作负载使用的关键组成部分。这包括:
能够根据频繁操作来审计您的数据湖
了解关键性能指标,例如高延迟的操作
了解常见错误、导致错误的操作以及导致服务端节流的操作
关键考虑#
数据湖的所有遥测数据均可通过 Azure Monitor 中的 Azure 存储日志获得。Azure Monitor 中的 Azure 存储日志是 Azure 存储的一项新预览功能,它允许您的存储帐户与 Log Analytics、事件中心以及使用标准诊断设置将日志存档到另一个存储帐户之间的直接集成。可以在 Azure 存储监视数据参考中找到指标和资源日志的完整列表及其关联架构的参考。
在考虑访问方式时,选择将 Azure 存储日志中的日志存储在何处变得很重要:
如果要近乎实时地访问日志并能够将日志中的事件与来自 Azure Monitor 的其他指标相关联,则可以将日志存储在 Log Analytics 工作区中。这允许您使用 KQL 和作者查询来查询您的日志,这些查询枚举您工作区中的 StorageBlobLogs 表。
如果要存储日志以用于近实时查询和长期保留,可以配置诊断设置以将日志发送到 Log Analytics 工作区和存储帐户。
如果您想通过另一个查询引擎(例如 Splunk)访问您的日志,您可以配置您的诊断设置以将日志发送到事件中心并将日志从事件中心摄取到您选择的目的地。
可以通过 Azure 门户、PowerShell、Azure CLI 和 Azure 资源管理器模板启用 Azure Monitor 中的 Azure 存储日志。对于大规模部署,可以使用 Azure Policy 并完全支持修复任务。有关更多详细信息,请参阅:
Azure/社区政策
ciphertxt/AzureStoragePolicy
Azure Monitor 中 Azure 存储日志的常见 KQL 查询
以下查询可用于深入了解数据湖的性能和健康状况:
Frequent operations
StorageBlobLogs | where TimeGenerated > ago(3d) | summarize count() by OperationName | sort by count_ desc | render piechart
High latency operations
StorageBlobLogs | where TimeGenerated > ago(3d) | top 10 by DurationMs desc | project TimeGenerated, OperationName, DurationMs, ServerLatencyMs, ClientLatencyMs = DurationMs - ServerLatencyMsOperations causing the most errors
StorageBlobLogs | where TimeGenerated > ago(3d) and StatusText !contains "Success" | summarize count() by OperationName | top 10 by count_ desc
Azure Monitor 中 Azure 存储日志的所有内置查询的列表可在 GitHub 上的 Azure Montior 社区的 Azure 服务/存储帐户/查询文件夹中找到。
优化您的数据湖以获得更好的规模和性能#
正在建设中,寻求贡献
在本节中,我们将讨论如何优化数据湖存储以提高分析管道中的性能。在本节中,我们将重点介绍帮助您优化存储事务的基本原则。为确保我们拥有正确的上下文,没有优化数据湖的灵丹妙药或 12 步流程,因为很多考虑因素取决于您尝试解决的特定用途和业务问题。但是,当我们谈论优化数据湖以提高性能、可扩展性甚至成本时,归结为两个关键因素:-
优化高吞吐量 - 目标是每个事务至少获得几 MB(越高越好)。
优化数据访问模式——减少不必要的文件扫描,只读取您需要读取的数据。
作为优化的先决条件,了解有关事务配置文件和数据组织的更多信息非常重要。鉴于分析场景的不同性质,优化取决于您的分析管道、存储 I/O 模式和您操作的数据集,特别是数据湖的以下方面。
请注意,我们讨论的场景主要侧重于优化 ADLS Gen2 性能。除了存储性能考虑之外,分析管道的整体性能还会有特定于分析引擎的考虑,我们与 Azure 上的分析产品(如 Azure Synapse Analytics、HDInsight 和 Azure Databricks)的合作关系确保我们专注于打造整体体验更好的。同时,虽然我们以特定引擎为例,但请注意,这些示例主要讨论存储性能。
文件大小和文件数量#
分析引擎(您的摄取或数据处理管道)会为其读取的每个文件(与列出、检查访问和其他元数据操作相关)产生开销,而过多的小文件会对您的整体工作的性能产生负面影响。此外,当您的文件太小(在 KB 范围内)时,您通过 I/O 操作实现的吞吐量也很低,需要更多的 I/O 来获取您想要的数据。通常,最佳做法是将数据组织成更大的文件(目标至少为 100 MB 或更多)以获得更好的性能。
在很多情况下,如果您的原始数据(来自各种来源)本身并不大,您可以使用以下选项来确保您的分析引擎所操作的数据集仍然使用大文件进行优化。
在您的分析管道中添加数据处理层,以将多个小文件中的数据合并为一个大文件。您还可以利用这个机会以读取优化的格式(例如 Parquet)存储数据,以便进行下游处理。
在处理实时数据的情况下,您可以将实时流引擎(例如 Azure Stream Analytics 或 Spark Streaming)与消息代理(例如事件中心或 Apache Kafka)结合使用,以将您的数据存储为更大的文件。
文件格式#
正如我们已经讨论过的,优化您的存储 I/O 模式可以在很大程度上使您的分析管道的整体性能受益。值得一提的是,选择正确的文件格式不仅可以提供更好的性能,还可以降低数据存储成本。Parquet 是一种非常流行的数据格式,值得为您的大数据分析管道进行探索。
Apache Parquet 是一种开源文件格式,针对读取繁重的分析管道进行了优化。Parquet 的列式存储结构让您可以跳过不相关的数据,从而提高查询效率。这种跳过的能力还会导致只将您想要的数据从存储发送到分析引擎,从而降低成本并提高性能。此外,由于相似的数据类型(对于一列)存储在一起,与以文本文件格式存储相同数据相比,Parquet 有助于高效的数据压缩和编码方案,从而降低数据存储成本。
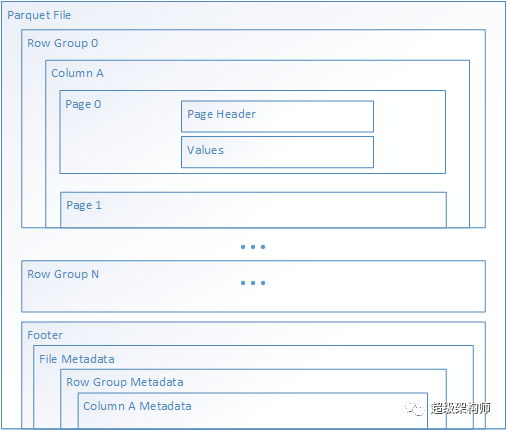
Azure Synapse Analytics、Azure Databricks 和 Azure 数据工厂等服务内置了本机功能,可以利用 Parquet 文件格式。
分区方案#
有效的数据分区方案可以提高分析管道的性能,还可以降低查询产生的总体事务成本。简单来说,分区是一种通过将具有相似属性的数据集分组到一个存储实体(例如文件夹)中来组织数据的方法。当您的数据处理管道查询具有相似属性的数据(例如过去 12 小时内的所有数据)时,分区方案(在这种情况下,由 datetime 完成)让您跳过不相关的数据,只寻找那些你要。
让我们以 Contoso 的 IoT 场景为例,其中数据从各种传感器实时摄取到数据湖中。现在,您有多种存储数据的选项,包括(但不限于)下面列出的选项:
Option 1 -
/<sensorid>/<datetime>/<temperature>, <sensorid>/<datetime>/<pressure>, <sensorid>/<datetime>/<humidity>Option 2 -
/<datetime>/<sensorid>/<temperature>, /<datetime>/<sensorid>/<pressure>, /datetime>/<sensorid>/<humidity>Option 3 -
<temperature>/<datetime>/<sensorid>, <pressure>/<datetime>/<sensorid>, <humidity>/<datetime>/<sensorid>
如果高优先级方案是根据传感器发送的值了解传感器的健康状况以确保传感器正常工作,那么您将每隔一小时左右运行一次分析管道,以对来自特定传感器的数据与来自其他传感器的数据进行三角测量以确保它们正常工作。在这种情况下,选项 2 将是组织数据的最佳方式。相反,如果您的高优先级方案是根据传感器数据了解该地区的天气模式以确保您需要采取哪些补救措施,您将定期运行分析管道,以根据该地区的传感器数据评估天气。在这种情况下,您可能希望通过传感器ID 上的日期和属性来优化组织。
Apache Spark 等开源计算框架为您可以在大数据应用程序中利用的分区方案提供本机支持。
使用查询加速 #
Azure Data Lake Storage 有一项名为 Query Acceleration 的功能,可在预览版中使用,旨在优化性能的同时降低成本。查询加速允许您通过指定更多谓词(认为这些谓词类似于您将在 SQL 查询的 WHERE 子句中提供的条件)和列投影(认为这些列作为您将在 SQL 查询的 SELECT 语句中指定的列)在非结构化数据上。

除了通过过滤查询使用的特定数据来提高性能外,查询加速还通过优化传输的数据来降低分析管道的整体成本,从而降低整体存储交易成本,并节省您的计算资源成本 否则,您本来可以阅读整个数据集并过滤所需的数据子集。
| 本文 :https://architect.pub/hitchhikers-guide-data-lake | ||
| 讨论:知识星球【首席架构师圈】或者加微信小号【ca_cto】或者加QQ群【792862318】 | ||
| 公众号 | 【jiagoushipro】 【超级架构师】 精彩图文详解架构方法论,架构实践,技术原理,技术趋势。 我们在等你,赶快扫描关注吧。 |  |
| 微信小号 | 【ca_cea】 50000人社区,讨论:企业架构,云计算,大数据,数据科学,物联网,人工智能,安全,全栈开发,DevOps,数字化. |
|
| QQ群 | 【285069459】深度交流企业架构,业务架构,应用架构,数据架构,技术架构,集成架构,安全架构。以及大数据,云计算,物联网,人工智能等各种新兴技术。 加QQ群,有珍贵的报告和干货资料分享。 |
|
| 视频号 | 【超级架构师】 1分钟快速了解架构相关的基本概念,模型,方法,经验。 每天1分钟,架构心中熟。 |
|
| 知识星球 | 【首席架构师圈】向大咖提问,近距离接触,或者获得私密资料分享。 |
|
| 喜马拉雅 | 【超级架构师】路上或者车上了解最新黑科技资讯,架构心得。 | 【智能时刻,架构君和你聊黑科技】 |
| 知识星球 | 认识更多朋友,职场和技术闲聊。 | 知识星球【职场和技术】 |
| 领英 | Harry | https://www.linkedin.com/in/architect-harry/ |
| 领英群组 | 领英架构群组 | https://www.linkedin.com/groups/14209750/ |
| 微博 | 【超级架构师】 | 智能时刻 |
| 哔哩哔哩 | 【超级架构师】 |
|
| 抖音 | 【cea_cio】超级架构师 |
|
| 快手 | 【cea_cio_cto】超级架构师 |
|
| 小红书 | 【cea_csa_cto】超级架构师 |
|
| 网站 | CIO(首席信息官) | https://cio.ceo |
| 网站 | CIO,CTO和CDO | https://cioctocdo.com |
| 网站 | 架构师实战分享 | https://architect.pub |
| 网站 | 程序员云开发分享 | https://pgmr.cloud |
| 网站 | 首席架构师社区 | https://jiagoushi.pro |
| 网站 | 应用开发和开发平台 | https://apaas.dev |
| 网站 | 开发信息网 | https://xinxi.dev |
| 网站 | 超级架构师 | https://jiagou.dev |
| 网站 | 企业技术培训 | https://peixun.dev |
| 网站 | 程序员宝典 | https://pgmr.pub |
| 网站 | 开发者闲谈 | https://blog.developer.chat |
| 网站 | CPO宝典 | https://cpo.work |
| 网站 | 首席安全官 | https://cso.pub |
| 网站 | CIO酷 | https://cio.cool |
| 网站 | CDO信息 | https://cdo.fyi |
| 网站 | CXO信息 | https://cxo.pub |








谢谢大家关注,转发,点赞和点在看。