· CSDN的uu们,大家好。这里是C++入门的第四讲。
· 座右铭:前路坎坷,披荆斩棘,扶摇直上。
· 博客主页: @姬如祎
· 收录专栏:C++专题

目录
1. 知识引入
2. 函数重载的知识点
2. 为什么C语言不支持函数重载而C++支持呢?
2.1 前置知识
2.2 原因详解
1. 知识引入
在书写排序排序算法时,我们经常会用到 Swap(int* a, int* b) 函数,可是在实际的运用中,我们不可能只会遇到交换整型数据的情况。当我们需要交换其它类型的数据时,用C语言来实现就比较麻烦了,你必须写很多个函数名不同的函数,来区别不同数据类型之间两个数的交换。
void SwapInt(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void SwapDouble(double* a, double* b)
{
double tmp = *a;
*a = *b;
*b = tmp;
}这样是不是十分的麻烦,于是C++引入了一个新的语法:函数重载:
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
于是,实现相同的功能C++的代码就可以这么写:
void Swap(int* a, int* b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
void Swap(double* a, double* b)
{
double tmp = *a;
*a = *b;
*b = tmp;
}这样写的好处是显而易见的:我们交换数据只需要记忆Swap这一个函数就可以了。而不需要像C语言那样对于不同的数据类型记忆不同的函数。
2. 函数重载的知识点
再来看看函数重载的概念:
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
下面我们枚举一些能够发生函数重载的例子:
#include<iostream>
using namespace std;
// 1、参数类型不同
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
// 2、参数个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
// 3、参数类型顺序不同
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}
int main()
{
Add(10, 20);
Add(10.1, 20.2);
f();
f(10);
f(10, 'a');
f('a', 10);
return 0;
}注意第三点一定是参数类型的顺序不同,千万别想成形参不同哈。
这里就会有一个问题了,为什么函数的返回值不能构成函数重载呢?
看下面的一段代码:f() 这两个函数仅有返回值不同,在main函数调用 f() 时, 请问,我们应该调用哪一个函数呢?显然这是不正确的代码!
int f()
{
cout << "int f()" << endl;
return 1;
}
double f()
{
cout << "double f()" << endl;
return 1.1;
}
int main()
{
f();
return 0;
}我们结合一下上一讲的缺省参数。像这样的代码是会报调用不明确的错误的。

以上就是函数重载的全部知识点。
2. 为什么C语言不支持函数重载而C++支持呢?
2.1 前置知识
在搞清楚这个问题之前,我们还需要再回忆C / C++ 的编译环境。编译环境可以分为编译,链接两个阶段。编译又可以细分为:预编译(预处理),编译,汇编三个阶段。
预编译(预处理):这个阶段的任务包括了头文件的展开,注释的删除,条件编译,宏的替换等等,源文件经过预处理会生成一个以.i为后缀的文件。但是在VS这个集成开发环境是无法使整个编译过程停到这一步的,我们需要在Linux环境下才能观察到。
输入命令:
gcc -E add.c -o add.i
就能看到源文件经过预编译(预处理)之后的文件了。
编译:这个阶段的任务就是对生成的. i文件进行语法分析,词法分析,符号汇总等,最终形成汇编代码。这里的符号汇总会将那些可能跨文件使用的符号进行汇总,包括全局变量,函数名等等。完成编译阶段会生成一个以.s的后缀的文件。
可以在Linux环境中输入命令查看:
gcc -S add.i
汇编:将汇编代码转化成机器指令(二进制指令),形成符号表,符号表中包含了符号的名称,符号的地址等。假设一个源文件中只有函数的定义,那么符号表中的该符号对应的地址就是一个无效的地址。经过汇编阶段会生成一个后缀名为. o的文件。在Linux环境下,. o文件,以及最终生成的可执行文件都是Elf格式的文件。
可以输入命令查看符号表:
readelf -s add.o
这里的.o文件你可以类比VS中的目标文件.obj。
链接:这个阶段的任务是合并段表,符号表的合并与重定位。因为我们写的源文件在编译阶段都是分开编译的,他们联系起来就是在链接阶段。例如:当函数的声明与定义是分文件编写的时候,如果只有函数的声明,却没有函数的定义,就会报链接错误:
LNK:link的缩写表明是链接时出现的错误。


2.2 原因详解
本质的原因就是在与C语言与C++的函数名修饰规则不同,即是添加到符号表里面的函数的符号不同。怎么查看符号表里面的函数符号嘞,可以通过看汇编代码查看,也可以通过直接看符号表查看。这里我们就演示第一种。
我们先来看C语言的函数名修饰规则:
#include<stdio.h>
int Add(int x, int y)
{
return x + y;
}
int main()
{
int ret = Add(2, 3);
return 0;
}将上面的代码通过gcc编译器编译,得到生成的可执行文件:testc,然后输入命令查看汇编代码:
# 编译,指定可执行文件为:testc
gcc test.c -o testc
# 查看汇编代码
objdump -S testc然后找到Add函数,就可以看到C语言的函数经过函数名修饰规则之后的符号!
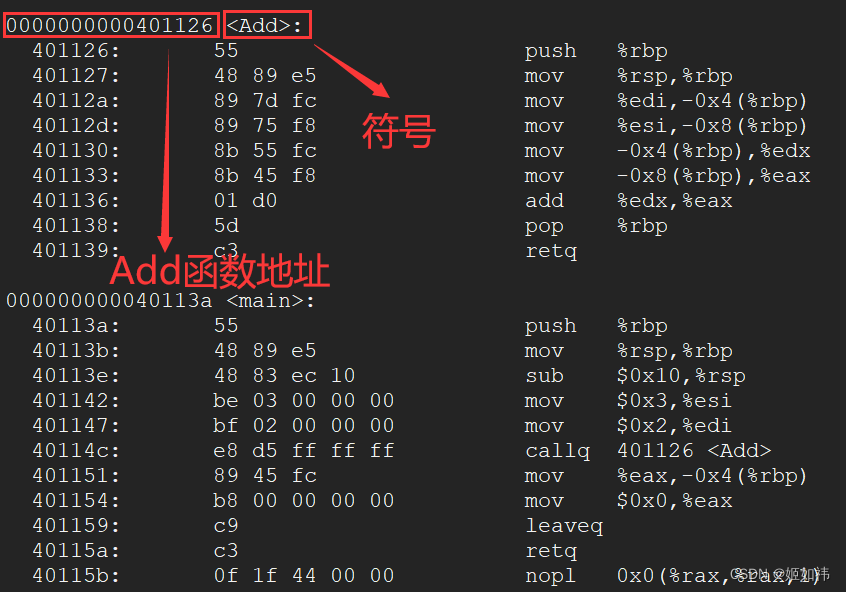
我们可以看到C语言用的函数的符号就是函数名。当我们定义两个同样名字的函数,在编译的过程中编译器尝试为函数生成二进制代码时,编译器无法确定使用哪个函数的定义,从而导致编译出错。
我们再来看g++编译器下的C++的函数名修饰规则:
#include<iostream>
using namespace std;
int Add(int x, int y)
{
return x + y;
}
double Add(double x, double y)
{
return x + y;
}
int main()
{
int ret = Add(2, 3);
int ans = Add(2.2, 3.3);
return 0;
}
将上面的代码通过g++编译器编译,得到生成的可执行文件:testcpp,然后输入命令查看汇编代码:
# 编译,指定可执行文件为:testcpp
g++ test.c -o testcpp
# 查看汇编代码
objdump -S testcpp然后找到两个不同的Add函数,就可以看到C++的函数经过g++编译器函数名修饰规则之后的符号!
 g++的函数修饰后变成【_Z+函数长度+函数名+类型首字母】。如上图第一个函数,_Z:固定的格式,3:Add函数的函数名长度是3,i:Add函数的第一个参数为int,缩写为i,i:Add函数的第二个参数还是int,同样缩写为i。
g++的函数修饰后变成【_Z+函数长度+函数名+类型首字母】。如上图第一个函数,_Z:固定的格式,3:Add函数的函数名长度是3,i:Add函数的第一个参数为int,缩写为i,i:Add函数的第二个参数还是int,同样缩写为i。

我们可以看到VS编译器的函数名修饰规则要复杂得多。
在编译时,因为函数的符号并不相同,编译器就会生成不同的二进制代码。在函数调用的地方,也会根据传入参数的不同调用不同的函数。
这便是C++能够函数重载C语言不行的原因。
这里有人可能会问,我们将函数的返回值添加到函数名修饰规则是不是通过函数的返回值也能实现函数重载了呢?
显然是不行的,假设我们有两个仅返回值不同的函数,在函数调用的地方,编译器无法确定是调用的是哪一个函数,会出现调用歧义。