介绍
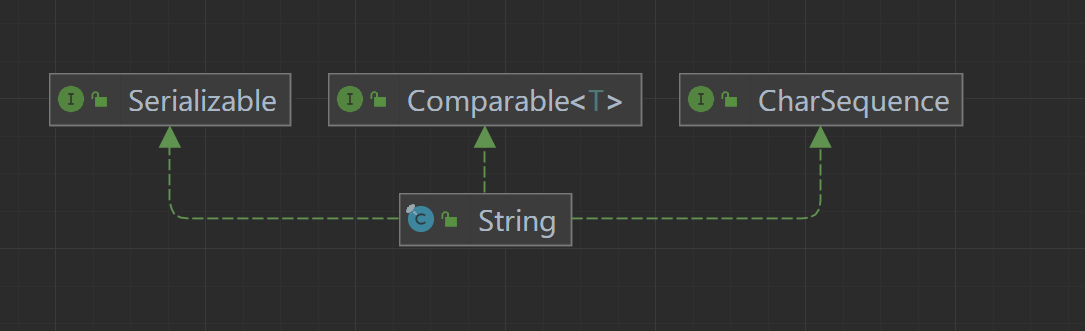
1)String 是一个 final 类,即不能被继承的类 。
2)String类实现了 java.io.Serializable 接口,可以实现序列化。
3)String类实现了 Comparable< String>,可以用于比较大小(按顺序比较单个字符的ASCII码) 。
4)String 类实现了 CharSequence 接口,表示是一个有序字符的序列,因为 String 的本质是一个 char 类型数组。
5)private final char value[] 这是 String 字符串的本质,是一个字符集合,存储String对象的字符内容,而且是 final 的,是不可变的。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence
常量&变量
/** The value is used for character storage. */
//用不可变的 char 数组用来存放字符串
private final char value[];
/** Cache the hash code for the string */
//缓存 String 的 hash 值
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
//序列化版本号
private static final long serialVersionUID = -6849794470754667710L;
注:版本变化
在jdk8中
用char 数组来存放字符串
private final char value[];
在jdk9及以后版本中
用byte 数组来存放字符串
private final byte[] value;
构造方法
/**
* Initializes a newly created {@code String} object so that it represents
* an empty character sequence. Note that use of this constructor is
* unnecessary since Strings are immutable.
* 初始化 String 对象,将 "" 空字符串的 value 赋值给实例对象的 value,也是空字符,
* 因为字符串是不可变的,所以不必要使用这个方法
*/
public String() {
this.value = "".value;
}
/**
* Initializes a newly created {@code String} object so that it represents
* the same sequence of characters as the argument; in other words, the
* newly created string is a copy of the argument string. Unless an
* explicit copy of {@code original} is needed, use of this constructor is
* unnecessary since Strings are immutable.
*
* @param original
* A {@code String}
* 将形参的value和hash赋值给实例对象作为初始化
* 相当于深拷贝了一个形参String对象
*/
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
/**
* Allocates a new {@code String} so that it represents the sequence of
* characters currently contained in the character array argument. The
* contents of the character array are copied; subsequent modification of
* the character array does not affect the newly created string.
*
* @param value
* The initial value of the string
* 将数组值拷贝赋给不可变字符数组
* 这里为什么不直接赋值呢: 因为参数 char value[] 是可变的,
* 如果直接赋值,当参数数组发生变化时,就会影响到新生成的 String 对象,这就破坏的 String 的“不可变性”。
*/
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
/**
* Allocates a new {@code String} that contains characters from a subarray
* of the character array argument. The {@code offset} argument is the
* index of the first character of the subarray and the {@code count}
* argument specifies the length of the subarray. The contents of the
* subarray are copied; subsequent modification of the character array does
* not affect the newly created string.
*
* @param value
* Array that is the source of characters
*
* @param offset
* The initial offset
*
* @param count
* The length
*
* @throws IndexOutOfBoundsException
* If the {@code offset} and {@code count} arguments index
* characters outside the bounds of the {@code value} array
* 在char数组的基础上,从offset位置开始计数count个,构成一个新的String的字符串
*/
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= value.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
/**
* Allocates a new {@code String} that contains characters from a subarray
* of the <a href="Character.html#unicode">Unicode code point</a> array
* argument. The {@code offset} argument is the index of the first code
* point of the subarray and the {@code count} argument specifies the
* length of the subarray. The contents of the subarray are converted to
* {@code char}s; subsequent modification of the {@code int} array does not
* affect the newly created string.
*
* @param codePoints
* Array that is the source of Unicode code points
*
* @param offset
* The initial offset
*
* @param count
* The length
*
* @throws IllegalArgumentException
* If any invalid Unicode code point is found in {@code
* codePoints}
*
* @throws IndexOutOfBoundsException
* If the {@code offset} and {@code count} arguments index
* characters outside the bounds of the {@code codePoints} array
*
* @since 1.5
* int 数组的元素则是字符对应的 ASCII 整数值。
*/
public String(int[] codePoints, int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count <= 0) {
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
if (offset <= codePoints.length) {
this.value = "".value;
return;
}
}
// Note: offset or count might be near -1>>>1.
if (offset > codePoints.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
final int end = offset + count;
// Pass 1: Compute precise size of char[]
int n = count;
for (int i = offset; i < end; i++) {
int c = codePoints[i];
if (Character.isBmpCodePoint(c))
continue;
else if (Character.isValidCodePoint(c))
n++;
else throw new IllegalArgumentException(Integer.toString(c));
}
// Pass 2: Allocate and fill in char[]
final char[] v = new char[n];
for (int i = offset, j = 0; i < end; i++, j++) {
int c = codePoints[i];
if (Character.isBmpCodePoint(c))
v[j] = (char)c;
else
Character.toSurrogates(c, v, j++);
}
this.value = v;
}
/**
* Allocates a new {@code String} constructed from a subarray of an array
* of 8-bit integer values.
*
* <p> The {@code offset} argument is the index of the first byte of the
* subarray, and the {@code count} argument specifies the length of the
* subarray.
*
* <p> Each {@code byte} in the subarray is converted to a {@code char} as
* specified in the method above.
*
* @deprecated This method does not properly convert bytes into characters.
* As of JDK 1.1, the preferred way to do this is via the
* {@code String} constructors that take a {@link
* java.nio.charset.Charset}, charset name, or that use the platform's
* default charset.
*
* @param ascii
* The bytes to be converted to characters
*
* @param hibyte
* The top 8 bits of each 16-bit Unicode code unit
*
* @param offset
* The initial offset
* @param count
* The length
*
* @throws IndexOutOfBoundsException
* If the {@code offset} or {@code count} argument is invalid
*
* @see #String(byte[], int)
* @see #String(byte[], int, int, java.lang.String)
* @see #String(byte[], int, int, java.nio.charset.Charset)
* @see #String(byte[], int, int)
* @see #String(byte[], java.lang.String)
* @see #String(byte[], java.nio.charset.Charset)
* @see #String(byte[])
*/
@Deprecated
public String(byte ascii[], int hibyte, int offset, int count) {
checkBounds(ascii, offset, count);
char value[] = new char[count];
if (hibyte == 0) {
for (int i = count; i-- > 0;) {
value[i] = (char)(ascii[i + offset] & 0xff);
}
} else {
hibyte <<= 8;
for (int i = count; i-- > 0;) {
value[i] = (char)(hibyte | (ascii[i + offset] & 0xff));
}
}
this.value = value;
}
/**
* Allocates a new {@code String} containing characters constructed from
* an array of 8-bit integer values. Each character <i>c</i>in the
* resulting string is constructed from the corresponding component
* <i>b</i> in the byte array such that:
*
* <blockquote><pre>
* <b><i>c</i></b> == (char)(((hibyte & 0xff) << 8)
* | (<b><i>b</i></b> & 0xff))
* </pre></blockquote>
*
* @deprecated This method does not properly convert bytes into
* characters. As of JDK 1.1, the preferred way to do this is via the
* {@code String} constructors that take a {@link
* java.nio.charset.Charset}, charset name, or that use the platform's
* default charset.
*
* @param ascii
* The bytes to be converted to characters
*
* @param hibyte
* The top 8 bits of each 16-bit Unicode code unit
*
* @see #String(byte[], int, int, java.lang.String)
* @see #String(byte[], int, int, java.nio.charset.Charset)
* @see #String(byte[], int, int)
* @see #String(byte[], java.lang.String)
* @see #String(byte[], java.nio.charset.Charset)
* @see #String(byte[])
*/
@Deprecated
public String(byte ascii[], int hibyte) {
this(ascii, hibyte, 0, ascii.length);
}
/* Common private utility method used to bounds check the byte array
* and requested offset & length values used by the String(byte[],..)
* constructors.
*/
private static void checkBounds(byte[] bytes, int offset, int length) {
if (length < 0)
throw new StringIndexOutOfBoundsException(length);
if (offset < 0)
throw new StringIndexOutOfBoundsException(offset);
if (offset > bytes.length - length)
throw new StringIndexOutOfBoundsException(offset + length);
}
/**
* Constructs a new {@code String} by decoding the specified subarray of
* bytes using the specified charset. The length of the new {@code String}
* is a function of the charset, and hence may not be equal to the length
* of the subarray.
*
* <p> The behavior of this constructor when the given bytes are not valid
* in the given charset is unspecified. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param bytes
* The bytes to be decoded into characters
*
* @param offset
* The index of the first byte to decode
*
* @param length
* The number of bytes to decode
* @param charsetName
* The name of a supported {@linkplain java.nio.charset.Charset
* charset}
*
* @throws UnsupportedEncodingException
* If the named charset is not supported
*
* @throws IndexOutOfBoundsException
* If the {@code offset} and {@code length} arguments index
* characters outside the bounds of the {@code bytes} array
*
* @since JDK1.1
* 从bytes数组中的offset位置开始,将长度为length的字节,以charsetName格式编码,拷贝到value
*/
public String(byte bytes[], int offset, int length, String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null)
throw new NullPointerException("charsetName");
//判断byte数组是否越界
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charsetName, bytes, offset, length);
}
/**
* Constructs a new {@code String} by decoding the specified subarray of
* bytes using the specified {@linkplain java.nio.charset.Charset charset}.
* The length of the new {@code String} is a function of the charset, and
* hence may not be equal to the length of the subarray.
*
* <p> This method always replaces malformed-input and unmappable-character
* sequences with this charset's default replacement string. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param bytes
* The bytes to be decoded into characters
*
* @param offset
* The index of the first byte to decode
*
* @param length
* The number of bytes to decode
*
* @param charset
* The {@linkplain java.nio.charset.Charset charset} to be used to
* decode the {@code bytes}
*
* @throws IndexOutOfBoundsException
* If the {@code offset} and {@code length} arguments index
* characters outside the bounds of the {@code bytes} array
*
* @since 1.6
*/
public String(byte bytes[], int offset, int length, Charset charset) {
if (charset == null)
throw new NullPointerException("charset");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charset, bytes, offset, length);
}
/**
* Constructs a new {@code String} by decoding the specified array of bytes
* using the specified {@linkplain java.nio.charset.Charset charset}. The
* length of the new {@code String} is a function of the charset, and hence
* may not be equal to the length of the byte array.
*
* <p> The behavior of this constructor when the given bytes are not valid
* in the given charset is unspecified. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param bytes
* The bytes to be decoded into characters
*
* @param charsetName
* The name of a supported {@linkplain java.nio.charset.Charset
* charset}
*
* @throws UnsupportedEncodingException
* If the named charset is not supported
*
* @since JDK1.1
*/
public String(byte bytes[], String charsetName)
throws UnsupportedEncodingException {
this(bytes, 0, bytes.length, charsetName);
}
/**
* Constructs a new {@code String} by decoding the specified array of
* bytes using the specified {@linkplain java.nio.charset.Charset charset}.
* The length of the new {@code String} is a function of the charset, and
* hence may not be equal to the length of the byte array.
*
* <p> This method always replaces malformed-input and unmappable-character
* sequences with this charset's default replacement string. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param bytes
* The bytes to be decoded into characters
*
* @param charset
* The {@linkplain java.nio.charset.Charset charset} to be used to
* decode the {@code bytes}
*
* @since 1.6
*/
public String(byte bytes[], Charset charset) {
this(bytes, 0, bytes.length, charset);
}
/**
* Constructs a new {@code String} by decoding the specified subarray of
* bytes using the platform's default charset. The length of the new
* {@code String} is a function of the charset, and hence may not be equal
* to the length of the subarray.
*
* <p> The behavior of this constructor when the given bytes are not valid
* in the default charset is unspecified. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param bytes
* The bytes to be decoded into characters
*
* @param offset
* The index of the first byte to decode
*
* @param length
* The number of bytes to decode
*
* @throws IndexOutOfBoundsException
* If the {@code offset} and the {@code length} arguments index
* characters outside the bounds of the {@code bytes} array
*
* @since JDK1.1
*/
public String(byte bytes[], int offset, int length) {
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(bytes, offset, length);
}
/**
* Constructs a new {@code String} by decoding the specified array of bytes
* using the platform's default charset. The length of the new {@code
* String} is a function of the charset, and hence may not be equal to the
* length of the byte array.
*
* <p> The behavior of this constructor when the given bytes are not valid
* in the default charset is unspecified. The {@link
* java.nio.charset.CharsetDecoder} class should be used when more control
* over the decoding process is required.
*
* @param bytes
* The bytes to be decoded into characters
*
* @since JDK1.1
*/
public String(byte bytes[]) {
this(bytes, 0, bytes.length);
}
/**
* Allocates a new string that contains the sequence of characters
* currently contained in the string buffer argument. The contents of the
* string buffer are copied; subsequent modification of the string buffer
* does not affect the newly created string.
*
* @param buffer
* A {@code StringBuffer}
* 以 StringBuffer 为构造参数是线程安全的;
*/
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}
/**
* Allocates a new string that contains the sequence of characters
* currently contained in the string builder argument. The contents of the
* string builder are copied; subsequent modification of the string builder
* does not affect the newly created string.
*
* <p> This constructor is provided to ease migration to {@code
* StringBuilder}. Obtaining a string from a string builder via the {@code
* toString} method is likely to run faster and is generally preferred.
*
* @param builder
* A {@code StringBuilder}
*
* @since 1.5
*
* 使用 StringBuilder 为参数构造,不是线程安全的。
*/
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
/*
* Package private constructor which shares value array for speed.
* this constructor is always expected to be called with share==true.
* a separate constructor is needed because we already have a public
* String(char[]) constructor that makes a copy of the given char[].
*/
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
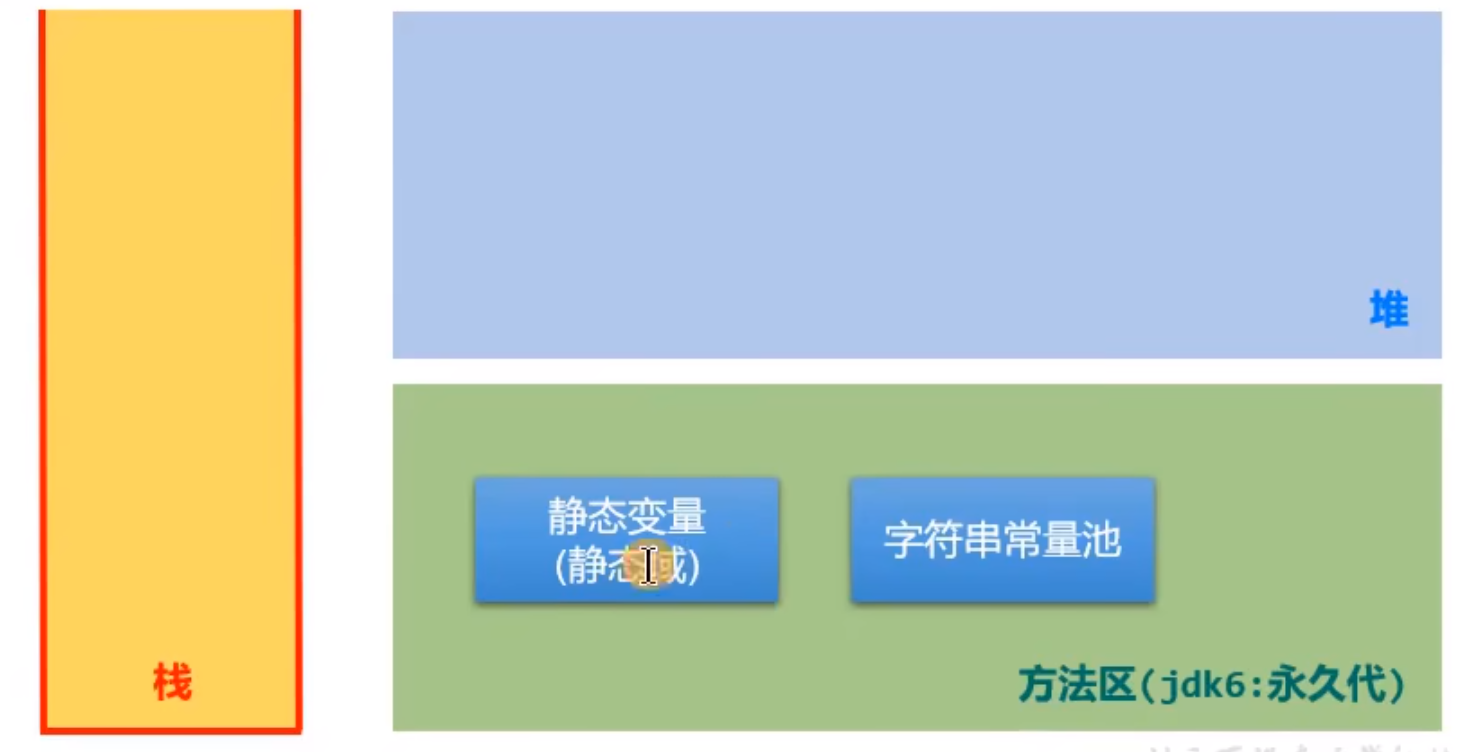
内存结构
字符串常量的存储位置
1.字符串常量都存储在字符串常量池(StringTable)中
2.字符串常量池不允许存放两个相同的字符串常量。
3.字符串常量池,在不同的jdk版本中,存放位置不同。
3.1 jdk7之前:字符串常量池存放在方法区
3.2 jdk7及之后:字符串常量池存放在堆空间。


常用方法
length
/**
* Returns the length of this string.
* The length is equal to the number of <a href="Character.html#unicode">Unicode
* code units</a> in the string.
*
* @return the length of the sequence of characters represented by this
* object.
* 返回value数组的长度
*/
public int length() {
return value.length;
}
isEmpty
/**
* Returns {@code true} if, and only if, {@link #length()} is {@code 0}.
*
* @return {@code true} if {@link #length()} is {@code 0}, otherwise
* {@code false}
*
* @since 1.6
* value数组的长度是否为0
*/
public boolean isEmpty() {
return value.length == 0;
}
charAt
/**
* Returns the {@code char} value at the
* specified index. An index ranges from {@code 0} to
* {@code length() - 1}. The first {@code char} value of the sequence
* is at index {@code 0}, the next at index {@code 1},
* and so on, as for array indexing.
*
* <p>If the {@code char} value specified by the index is a
* <a href="Character.html#unicode">surrogate</a>, the surrogate
* value is returned.
*
* @param index the index of the {@code char} value.
* @return the {@code char} value at the specified index of this string.
* The first {@code char} value is at index {@code 0}.
* @exception IndexOutOfBoundsException if the {@code index}
* argument is negative or not less than the length of this
* string.
* 获取下标为index的value数组字符
*/
public char charAt(int index) {
//校验索引越界
if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
equals
/**
* Compares this string to the specified object. The result is {@code
* true} if and only if the argument is not {@code null} and is a {@code
* String} object that represents the same sequence of characters as this
* object.
*
* @param anObject
* The object to compare this {@code String} against
*
* @return {@code true} if the given object represents a {@code String}
* equivalent to this string, {@code false} otherwise
*
* @see #compareTo(String)
* @see #equalsIgnoreCase(String)
* String的equals方法,重写了Object的equals方法(区分大小写)
* 比较的是两个字符串的值是否相等
*/
public boolean equals(Object anObject) {
//比较两个对象内存地址是否相同
if (this == anObject) {
return true;
}
//String类型
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
//两个字符串长度相同
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
//比较每个相同索引下字符是否相等
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
equalsIgnoreCase
/**
* Compares this {@code String} to another {@code String}, ignoring case
* considerations. Two strings are considered equal ignoring case if they
* are of the same length and corresponding characters in the two strings
* are equal ignoring case.
*
* <p> Two characters {@code c1} and {@code c2} are considered the same
* ignoring case if at least one of the following is true:
* <ul>
* <li> The two characters are the same (as compared by the
* {@code ==} operator)
* <li> Applying the method {@link
* java.lang.Character#toUpperCase(char)} to each character
* produces the same result
* <li> Applying the method {@link
* java.lang.Character#toLowerCase(char)} to each character
* produces the same result
* </ul>
*
* @param anotherString
* The {@code String} to compare this {@code String} against
*
* @return {@code true} if the argument is not {@code null} and it
* represents an equivalent {@code String} ignoring case; {@code
* false} otherwise
*
* @see #equals(Object)
* 比较两个字符串的值是否相等 不区分大小写
*/
public boolean equalsIgnoreCase(String anotherString) {
//先判断两个对象内存地址是否相同
return (this == anotherString) ? true
: (anotherString != null)
//字符长度相同
&& (anotherString.value.length == value.length)
//忽略大小写 判断两个字符串内容是否相同
&& regionMatches(true, 0, anotherString, 0, value.length);
}
compareTo
/**
* Compares two strings lexicographically.
* The comparison is based on the Unicode value of each character in
* the strings. The character sequence represented by this
* {@code String} object is compared lexicographically to the
* character sequence represented by the argument string. The result is
* a negative integer if this {@code String} object
* lexicographically precedes the argument string. The result is a
* positive integer if this {@code String} object lexicographically
* follows the argument string. The result is zero if the strings
* are equal; {@code compareTo} returns {@code 0} exactly when
* the {@link #equals(Object)} method would return {@code true}.
* <p>
* This is the definition of lexicographic ordering. If two strings are
* different, then either they have different characters at some index
* that is a valid index for both strings, or their lengths are different,
* or both. If they have different characters at one or more index
* positions, let <i>k</i> be the smallest such index; then the string
* whose character at position <i>k</i> has the smaller value, as
* determined by using the < operator, lexicographically precedes the
* other string. In this case, {@code compareTo} returns the
* difference of the two character values at position {@code k} in
* the two string -- that is, the value:
* <blockquote><pre>
* this.charAt(k)-anotherString.charAt(k)
* </pre></blockquote>
* If there is no index position at which they differ, then the shorter
* string lexicographically precedes the longer string. In this case,
* {@code compareTo} returns the difference of the lengths of the
* strings -- that is, the value:
* <blockquote><pre>
* this.length()-anotherString.length()
* </pre></blockquote>
*
* @param anotherString the {@code String} to be compared.
* @return the value {@code 0} if the argument string is equal to
* this string; a value less than {@code 0} if this string
* is lexicographically less than the string argument; and a
* value greater than {@code 0} if this string is
* lexicographically greater than the string argument.
* 这是一个比较字符串中字符大小的函数,因为String实现了Comparable<String>接口,所以重写了compareTo方法
* 实现了Comparable接口的类的对象的列表或数组可以通过Collections.sort或Arrays.sort进行自动排序。
*/
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
// 取两个字符串长度的最小值lim
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
// 从 value 的第一个字符开始到最小长度lim处为止,如果字符不相等,返回自身(对象不相等处字符-被比较对象不相等字符)
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
// 如果前面都相等,则返回(自身长度-被比较对象长度)
return len1 - len2;
}
startsWith
/**
* Tests if the substring of this string beginning at the
* specified index starts with the specified prefix.
*
* @param prefix the prefix.
* @param toffset where to begin looking in this string.
* @return {@code true} if the character sequence represented by the
* argument is a prefix of the substring of this object starting
* at index {@code toffset}; {@code false} otherwise.
* The result is {@code false} if {@code toffset} is
* negative or greater than the length of this
* {@code String} object; otherwise the result is the same
* as the result of the expression
* <pre>
* this.substring(toffset).startsWith(prefix)
* </pre>
* 当前对象[toffset,toffset + prefix.value.lenght]区间的字符串片段等于prefix
* 也可以说当前对象的toffset位置开始是否以prefix作为前缀
*/
public boolean startsWith(String prefix, int toffset) {
char ta[] = value;
//获得需要判断的起始位置,偏移量
int to = toffset;
char pa[] = prefix.value;
int po = 0;
int pc = prefix.value.length;
// Note: toffset might be near -1>>>1.
// 如果起始地址小于0或者(起始地址+所比较对象长度)大于自身对象长度,返回假
if ((toffset < 0) || (toffset > value.length - pc)) {
return false;
}
//从所比较对象的末尾开始比较:循环pc次,既prefix的长度
while (--pc >= 0) {
//每次比较当前对象的字符串的字符是否跟prefix一样
if (ta[to++] != pa[po++]) {
//一样则pc--,to++,po++,有一个不同则返回false
return false;
}
}
return true;
}
/**
* Tests if this string starts with the specified prefix.
*
* @param prefix the prefix.
* @return {@code true} if the character sequence represented by the
* argument is a prefix of the character sequence represented by
* this string; {@code false} otherwise.
* Note also that {@code true} will be returned if the
* argument is an empty string or is equal to this
* {@code String} object as determined by the
* {@link #equals(Object)} method.
* @since 1. 0
* 判断当前对象[0, prefix.value.lenght]区间的字符串片段等于prefix。
*/
public boolean startsWith(String prefix) {
return startsWith(prefix, 0);
}
endsWith
/**
* Tests if this string ends with the specified suffix.
*
* @param suffix the suffix.
* @return {@code true} if the character sequence represented by the
* argument is a suffix of the character sequence represented by
* this object; {@code false} otherwise. Note that the
* result will be {@code true} if the argument is the
* empty string or is equal to this {@code String} object
* as determined by the {@link #equals(Object)} method.
* 判断当前字符串对象是否以字符串prefix结尾
*/
public boolean endsWith(String suffix) {
return startsWith(suffix, value.length - suffix.value.length);
}
contains
/**
* Returns true if and only if this string contains the specified
* sequence of char values.
*
* @param s the sequence to search for
* @return true if this string contains {@code s}, false otherwise
* @since 1.5
* 是否含有CharSequence这个子类元素,通常用于StrngBuffer,StringBuilder
*/
public boolean contains(CharSequence s) {
return indexOf(s.toString()) > -1;
}
hashCode
/**
* Returns a hash code for this string. The hash code for a
* {@code String} object is computed as
* <blockquote><pre>
* s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
* </pre></blockquote>
* using {@code int} arithmetic, where {@code s[i]} is the
* <i>i</i>th character of the string, {@code n} is the length of
* the string, and {@code ^} indicates exponentiation.
* (The hash value of the empty string is zero.)
*
* @return a hash code value for this object.
* String类重写了Object类的hashCode方法。
* 哈希表来实现的数据结构来使用,比如String对象要放入HashMap中。
*/
public int hashCode() {
//hash是成员变量,所以默认为0
int h = hash;
//如果hash为0,且字符串对象长度大于0,不为""
if (h == 0 && value.length > 0) {
//获取当前对象的value
char val[] = value;
// 通过算法s[0]31^(n-1) + s[1]31^(n-2) + ... + s[n-1]计算hash值
for (int i = 0; i < value.length; i++) {
//每次都是31 * 每次循环获得的h +第i个字符的ASSIC码
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
indexOf
/**
* Returns the index within this string of the first occurrence of
* the specified character. If a character with value
* {@code ch} occurs in the character sequence represented by
* this {@code String} object, then the index (in Unicode
* code units) of the first such occurrence is returned. For
* values of {@code ch} in the range from 0 to 0xFFFF
* (inclusive), this is the smallest value <i>k</i> such that:
* <blockquote><pre>
* this.charAt(<i>k</i>) == ch
* </pre></blockquote>
* is true. For other values of {@code ch}, it is the
* smallest value <i>k</i> such that:
* <blockquote><pre>
* this.codePointAt(<i>k</i>) == ch
* </pre></blockquote>
* is true. In either case, if no such character occurs in this
* string, then {@code -1} is returned.
*
* @param ch a character (Unicode code point).
* @return the index of the first occurrence of the character in the
* character sequence represented by this object, or
* {@code -1} if the character does not occur.
*/
public int indexOf(int ch) {
//从第一个字符开始搜索
return indexOf(ch, 0);
}
/**
* Returns the index within this string of the first occurrence of the
* specified character, starting the search at the specified index.
* <p>
* If a character with value {@code ch} occurs in the
* character sequence represented by this {@code String}
* object at an index no smaller than {@code fromIndex}, then
* the index of the first such occurrence is returned. For values
* of {@code ch} in the range from 0 to 0xFFFF (inclusive),
* this is the smallest value <i>k</i> such that:
* <blockquote><pre>
* (this.charAt(<i>k</i>) == ch) {@code &&} (<i>k</i> >= fromIndex)
* </pre></blockquote>
* is true. For other values of {@code ch}, it is the
* smallest value <i>k</i> such that:
* <blockquote><pre>
* (this.codePointAt(<i>k</i>) == ch) {@code &&} (<i>k</i> >= fromIndex)
* </pre></blockquote>
* is true. In either case, if no such character occurs in this
* string at or after position {@code fromIndex}, then
* {@code -1} is returned.
*
* <p>
* There is no restriction on the value of {@code fromIndex}. If it
* is negative, it has the same effect as if it were zero: this entire
* string may be searched. If it is greater than the length of this
* string, it has the same effect as if it were equal to the length of
* this string: {@code -1} is returned.
*
* <p>All indices are specified in {@code char} values
* (Unicode code units).
*
* @param ch a character (Unicode code point).
* @param fromIndex the index to start the search from.
* @return the index of the first occurrence of the character in the
* character sequence represented by this object that is greater
* than or equal to {@code fromIndex}, or {@code -1}
* if the character does not occur.
* index方法就是返回ch字符第一次在字符串中出现的位置
* 即从fromIndex位置开始查找,从头向尾遍历,ch整数对应的字符在字符串中第一次出现的位置
* -1代表字符串没有这个字符,整数代表字符第一次出现在字符串的位置
*/
public int indexOf(int ch, int fromIndex) {
final int max = value.length;
if (fromIndex < 0) {
fromIndex = 0;
} else if (fromIndex >= max) {
// Note: fromIndex might be near -1>>>1.
return -1;
}
//一个char占用两个字节,如果ch小于2的16次方(65536),绝大多数字符都在此范围内
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value;
//从 fromIndex位置起遍历value数组
for (int i = fromIndex; i < max; i++) {
if (value[i] == ch) {
//存在相等的字符,返回第一次出现该字符的索引位置,并终止循环
return i;
}
}
return -1;
} else {
return indexOfSupplementary(ch, fromIndex);
}
}
/**
* Returns the index within this string of the first occurrence of the
* specified substring.
*
* <p>The returned index is the smallest value <i>k</i> for which:
* <blockquote><pre>
* this.startsWith(str, <i>k</i>)
* </pre></blockquote>
* If no such value of <i>k</i> exists, then {@code -1} is returned.
*
* @param str the substring to search for.
* @return the index of the first occurrence of the specified substring,
* or {@code -1} if there is no such occurrence.
* 返回第一次出现的字符串的位置
*/
public int indexOf(String str) {
return indexOf(str, 0);
}
/**
* Returns the index within this string of the first occurrence of the
* specified substring, starting at the specified index.
*
* <p>The returned index is the smallest value <i>k</i> for which:
* <blockquote><pre>
* <i>k</i> >= fromIndex {@code &&} this.startsWith(str, <i>k</i>)
* </pre></blockquote>
* If no such value of <i>k</i> exists, then {@code -1} is returned.
*
* @param str the substring to search for.
* @param fromIndex the index from which to start the search.
* @return the index of the first occurrence of the specified substring,
* starting at the specified index,
* or {@code -1} if there is no such occurrence.
* 从fromIndex开始遍历,返回第一次出现str字符串的位置
*/
public int indexOf(String str, int fromIndex) {
return indexOf(value, 0, value.length,
str.value, 0, str.value.length, fromIndex);
}
/**
* Code shared by String and AbstractStringBuilder to do searches. The
* source is the character array being searched, and the target
* is the string being searched for.
*
* @param source the characters being searched.
* @param sourceOffset offset of the source string.
* @param sourceCount count of the source string.
* @param target the characters being searched for.
* @param fromIndex the index to begin searching from.
* 这是一个不对外公开的静态函数
*/
static int indexOf(char[] source, int sourceOffset, int sourceCount,
String target, int fromIndex) {
return indexOf(source, sourceOffset, sourceCount,
target.value, 0, target.value.length,
fromIndex);
}
/**
* Code shared by String and StringBuffer to do searches. The
* source is the character array being searched, and the target
* is the string being searched for.
*
* @param source the characters being searched.
* @param sourceOffset offset of the source string.
* @param sourceCount count of the source string.
* @param target the characters being searched for.
* @param targetOffset offset of the target string.
* @param targetCount count of the target string.
* @param fromIndex the index to begin searching from.
*/
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
if (fromIndex < 0) {
fromIndex = 0;
}
if (targetCount == 0) {
return fromIndex;
}
char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount);
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}
substring
/**
* Returns a string that is a substring of this string. The
* substring begins with the character at the specified index and
* extends to the end of this string. <p>
* Examples:
* <blockquote><pre>
* "unhappy".substring(2) returns "happy"
* "Harbison".substring(3) returns "bison"
* "emptiness".substring(9) returns "" (an empty string)
* </pre></blockquote>
*
* @param beginIndex the beginning index, inclusive.
* @return the specified substring.
* @exception IndexOutOfBoundsException if
* {@code beginIndex} is negative or larger than the
* length of this {@code String} object.
* 截取当前字符串对象的片段,组成一个新的字符串对象
*/
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
//利用构造函数生成新的String对象
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
/**
* Returns a string that is a substring of this string. The
* substring begins at the specified {@code beginIndex} and
* extends to the character at index {@code endIndex - 1}.
* Thus the length of the substring is {@code endIndex-beginIndex}.
* <p>
* Examples:
* <blockquote><pre>
* "hamburger".substring(4, 8) returns "urge"
* "smiles".substring(1, 5) returns "mile"
* </pre></blockquote>
*
* @param beginIndex the beginning index, inclusive.
* @param endIndex the ending index, exclusive.
* @return the specified substring.
* @exception IndexOutOfBoundsException if the
* {@code beginIndex} is negative, or
* {@code endIndex} is larger than the length of
* this {@code String} object, or
* {@code beginIndex} is larger than
* {@code endIndex}.
* 截取一个区间范围
* [beginIndex,endIndex),不包括endIndex
*/
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}
concat
/**
* Concatenates the specified string to the end of this string.
* <p>
* If the length of the argument string is {@code 0}, then this
* {@code String} object is returned. Otherwise, a
* {@code String} object is returned that represents a character
* sequence that is the concatenation of the character sequence
* represented by this {@code String} object and the character
* sequence represented by the argument string.<p>
* Examples:
* <blockquote><pre>
* "cares".concat("s") returns "caress"
* "to".concat("get").concat("her") returns "together"
* </pre></blockquote>
*
* @param str the {@code String} that is concatenated to the end
* of this {@code String}.
* @return a string that represents the concatenation of this object's
* characters followed by the string argument's characters.
* String的拼接函数
*/
public String concat(String str) {
if (str.isEmpty()) {
return this;
}
//获得当前String对象的长度
int len = value.length;
int otherLen = str.length();
//将数组扩容,将value数组拷贝到buf数组中,长度为len + str.lenght
char buf[] = Arrays.copyOf(value, len + otherLen);
//然后将str字符串从buf字符数组的len位置开始覆盖,得到一个完整的buf字符数组
str.getChars(buf, len);
//生成新的Strintg对象
return new String(buf, true);
}
join
/**
* Returns a new String composed of copies of the
* {@code CharSequence elements} joined together with a copy of
* the specified {@code delimiter}.
*
* <blockquote>For example,
* <pre>{@code
* String message = String.join("-", "Java", "is", "cool");
* // message returned is: "Java-is-cool"
* }</pre></blockquote>
*
* Note that if an element is null, then {@code "null"} is added.
*
* @param delimiter the delimiter that separates each element
* @param elements the elements to join together.
*
* @return a new {@code String} that is composed of the {@code elements}
* separated by the {@code delimiter}
*
* @throws NullPointerException If {@code delimiter} or {@code elements}
* is {@code null}
*
* @see java.util.StringJoiner
* @since 1.8
* 拼接CharSequence,包含String、StringBuilder、StringBuffer
*/
public static String join(CharSequence delimiter, CharSequence... elements) {
Objects.requireNonNull(delimiter);
Objects.requireNonNull(elements);
// Number of elements not likely worth Arrays.stream overhead.
StringJoiner joiner = new StringJoiner(delimiter);
for (CharSequence cs: elements) {
joiner.add(cs);
}
return joiner.toString();
}
/**
* Returns a new {@code String} composed of copies of the
* {@code CharSequence elements} joined together with a copy of the
* specified {@code delimiter}.
*
* <blockquote>For example,
* <pre>{@code
* List<String> strings = new LinkedList<>();
* strings.add("Java");strings.add("is");
* strings.add("cool");
* String message = String.join(" ", strings);
* //message returned is: "Java is cool"
*
* Set<String> strings = new LinkedHashSet<>();
* strings.add("Java"); strings.add("is");
* strings.add("very"); strings.add("cool");
* String message = String.join("-", strings);
* //message returned is: "Java-is-very-cool"
* }</pre></blockquote>
*
* Note that if an individual element is {@code null}, then {@code "null"} is added.
*
* @param delimiter a sequence of characters that is used to separate each
* of the {@code elements} in the resulting {@code String}
* @param elements an {@code Iterable} that will have its {@code elements}
* joined together.
*
* @return a new {@code String} that is composed from the {@code elements}
* argument
*
* @throws NullPointerException If {@code delimiter} or {@code elements}
* is {@code null}
*
* @see #join(CharSequence,CharSequence...)
* @see java.util.StringJoiner
* @since 1.8
*/
public static String join(CharSequence delimiter,
Iterable<? extends CharSequence> elements) {
Objects.requireNonNull(delimiter);
Objects.requireNonNull(elements);
StringJoiner joiner = new StringJoiner(delimiter);
for (CharSequence cs: elements) {
joiner.add(cs);
}
return joiner.toString();
}
replace
/**
* Returns a string resulting from replacing all occurrences of
* {@code oldChar} in this string with {@code newChar}.
* <p>
* If the character {@code oldChar} does not occur in the
* character sequence represented by this {@code String} object,
* then a reference to this {@code String} object is returned.
* Otherwise, a {@code String} object is returned that
* represents a character sequence identical to the character sequence
* represented by this {@code String} object, except that every
* occurrence of {@code oldChar} is replaced by an occurrence
* of {@code newChar}.
* <p>
* Examples:
* <blockquote><pre>
* "mesquite in your cellar".replace('e', 'o')
* returns "mosquito in your collar"
* "the war of baronets".replace('r', 'y')
* returns "the way of bayonets"
* "sparring with a purple porpoise".replace('p', 't')
* returns "starring with a turtle tortoise"
* "JonL".replace('q', 'x') returns "JonL" (no change)
* </pre></blockquote>
*
* @param oldChar the old character.
* @param newChar the new character.
* @return a string derived from this string by replacing every
* occurrence of {@code oldChar} with {@code newChar}.
* 替换,将字符串中的oldChar字符全部替换成newChar
*/
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
//循环len次
while (++i < len) {
//找到第一个旧字符,打断循环
if (val[i] == oldChar) {
break;
}
}
//如果第一个旧字符的位置小于len
if (i < len) {
//new一个字符数组,len个长度
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
//把旧字符的前面的字符都复制到新字符数组上
buf[j] = val[j];
}
//从i位置开始遍历
while (i < len) {
char c = val[i];
//发现旧字符就替换,不相关的则直接复制
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
//通过新字符数组buf重构一个新String对象
return new String(buf, true);
}
}
return this;
}
/**
* Replaces each substring of this string that matches the given <a
* href="../util/regex/Pattern.html#sum">regular expression</a> with the
* given replacement.
*
* <p> An invocation of this method of the form
* <i>str</i>{@code .replaceAll(}<i>regex</i>{@code ,} <i>repl</i>{@code )}
* yields exactly the same result as the expression
*
* <blockquote>
* <code>
* {@link java.util.regex.Pattern}.{@link
* java.util.regex.Pattern#compile compile}(<i>regex</i>).{@link
* java.util.regex.Pattern#matcher(java.lang.CharSequence) matcher}(<i>str</i>).{@link
* java.util.regex.Matcher#replaceAll replaceAll}(<i>repl</i>)
* </code>
* </blockquote>
*
*<p>
* Note that backslashes ({@code \}) and dollar signs ({@code $}) in the
* replacement string may cause the results to be different than if it were
* being treated as a literal replacement string; see
* {@link java.util.regex.Matcher#replaceAll Matcher.replaceAll}.
* Use {@link java.util.regex.Matcher#quoteReplacement} to suppress the special
* meaning of these characters, if desired.
*
* @param regex
* the regular expression to which this string is to be matched
* @param replacement
* the string to be substituted for each match
*
* @return The resulting {@code String}
*
* @throws PatternSyntaxException
* if the regular expression's syntax is invalid
*
* @see java.util.regex.Pattern
*
* @since 1.4
* @spec JSR-51
* 当不是正规表达式时,与replace效果一样,都是全体换。如果字符串的正则表达式,则规矩表达式全体替换
*/
public String replaceAll(String regex, String replacement) {
return Pattern.compile(regex).matcher(this).replaceAll(replacement);
}
split
/**
* Splits this string around matches of the given
* <a href="../util/regex/Pattern.html#sum">regular expression</a>.
*
* <p> The array returned by this method contains each substring of this
* string that is terminated by another substring that matches the given
* expression or is terminated by the end of the string. The substrings in
* the array are in the order in which they occur in this string. If the
* expression does not match any part of the input then the resulting array
* has just one element, namely this string.
*
* <p> When there is a positive-width match at the beginning of this
* string then an empty leading substring is included at the beginning
* of the resulting array. A zero-width match at the beginning however
* never produces such empty leading substring.
*
* <p> The {@code limit} parameter controls the number of times the
* pattern is applied and therefore affects the length of the resulting
* array. If the limit <i>n</i> is greater than zero then the pattern
* will be applied at most <i>n</i> - 1 times, the array's
* length will be no greater than <i>n</i>, and the array's last entry
* will contain all input beyond the last matched delimiter. If <i>n</i>
* is non-positive then the pattern will be applied as many times as
* possible and the array can have any length. If <i>n</i> is zero then
* the pattern will be applied as many times as possible, the array can
* have any length, and trailing empty strings will be discarded.
*
* <p> The string {@code "boo:and:foo"}, for example, yields the
* following results with these parameters:
*
* <blockquote><table cellpadding=1 cellspacing=0 summary="Split example showing regex, limit, and result">
* <tr>
* <th>Regex</th>
* <th>Limit</th>
* <th>Result</th>
* </tr>
* <tr><td align=center>:</td>
* <td align=center>2</td>
* <td>{@code { "boo", "and:foo" }}</td></tr>
* <tr><td align=center>:</td>
* <td align=center>5</td>
* <td>{@code { "boo", "and", "foo" }}</td></tr>
* <tr><td align=center>:</td>
* <td align=center>-2</td>
* <td>{@code { "boo", "and", "foo" }}</td></tr>
* <tr><td align=center>o</td>
* <td align=center>5</td>
* <td>{@code { "b", "", ":and:f", "", "" }}</td></tr>
* <tr><td align=center>o</td>
* <td align=center>-2</td>
* <td>{@code { "b", "", ":and:f", "", "" }}</td></tr>
* <tr><td align=center>o</td>
* <td align=center>0</td>
* <td>{@code { "b", "", ":and:f" }}</td></tr>
* </table></blockquote>
*
* <p> An invocation of this method of the form
* <i>str.</i>{@code split(}<i>regex</i>{@code ,} <i>n</i>{@code )}
* yields the same result as the expression
*
* <blockquote>
* <code>
* {@link java.util.regex.Pattern}.{@link
* java.util.regex.Pattern#compile compile}(<i>regex</i>).{@link
* java.util.regex.Pattern#split(java.lang.CharSequence,int) split}(<i>str</i>, <i>n</i>)
* </code>
* </blockquote>
*
*
* @param regex
* the delimiting regular expression
*
* @param limit
* the result threshold, as described above
*
* @return the array of strings computed by splitting this string
* around matches of the given regular expression
*
* @throws PatternSyntaxException
* if the regular expression's syntax is invalid
*
* @see java.util.regex.Pattern
*
* @since 1.4
* @spec JSR-51
* 根据切割符号切割字符串
*/
public String[] split(String regex, int limit) {
/* fastpath if the regex is a
(1)one-char String and this character is not one of the
RegEx's meta characters ".$|()[{^?*+\\", or
(2)two-char String and the first char is the backslash and
the second is not the ascii digit or ascii letter.
*/
/* 1、单个字符,且不是".$|()[{^?*+\\"其中一个
* 2、两个字符,第一个是"\",第二个大小写字母或者数字
*/
char ch = 0;
if (((regex.value.length == 1 &&
".$|()[{^?*+\\".indexOf(ch = regex.charAt(0)) == -1) ||
(regex.length() == 2 &&
regex.charAt(0) == '\\' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 &&
((ch-'A')|('Z'-ch)) < 0)) &&
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE))
{
int off = 0;
int next = 0;
//大于0,limited==true,反之limited==false
boolean limited = limit > 0;
ArrayList<String> list = new ArrayList<>();
while ((next = indexOf(ch, off)) != -1) {
//当参数limit<=0 或者 集合list的长度小于 limit-1
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));
off = next + 1;
} else { // last one
//assert (list.size() == limit - 1);
//判断最后一个list.size() == limit - 1
list.add(substring(off, value.length));
off = value.length;
break;
}
}
// If no match was found, return this
//如果没有一个能匹配的,返回一个新的字符串,内容和原来的一样
if (off == 0)
return new String[]{this};
// Add remaining segment
// 当 limit<=0 时,limited==false,或者集合的长度 小于 limit是,截取添加剩下的字符串
if (!limited || list.size() < limit)
list.add(substring(off, value.length));
// Construct result
// 当 limit == 0 时,如果末尾添加的元素为空(长度为0),则集合长度不断减1,直到末尾不为空
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).isEmpty()) {
resultSize--;
}
}
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result);
}
return Pattern.compile(regex).split(this, limit);
}
/**
* Splits this string around matches of the given <a
* href="../util/regex/Pattern.html#sum">regular expression</a>.
*
* <p> This method works as if by invoking the two-argument {@link
* #split(String, int) split} method with the given expression and a limit
* argument of zero. Trailing empty strings are therefore not included in
* the resulting array.
*
* <p> The string {@code "boo:and:foo"}, for example, yields the following
* results with these expressions:
*
* <blockquote><table cellpadding=1 cellspacing=0 summary="Split examples showing regex and result">
* <tr>
* <th>Regex</th>
* <th>Result</th>
* </tr>
* <tr><td align=center>:</td>
* <td>{@code { "boo", "and", "foo" }}</td></tr>
* <tr><td align=center>o</td>
* <td>{@code { "b", "", ":and:f" }}</td></tr>
* </table></blockquote>
*
*
* @param regex
* the delimiting regular expression
*
* @return the array of strings computed by splitting this string
* around matches of the given regular expression
*
* @throws PatternSyntaxException
* if the regular expression's syntax is invalid
*
* @see java.util.regex.Pattern
*
* @since 1.4
* @spec JSR-51
*/
public String[] split(String regex) {
return split(regex, 0);
}
toLowerCase
/**
* Converts all of the characters in this {@code String} to lower
* case using the rules of the given {@code Locale}. Case mapping is based
* on the Unicode Standard version specified by the {@link java.lang.Character Character}
* class. Since case mappings are not always 1:1 char mappings, the resulting
* {@code String} may be a different length than the original {@code String}.
* <p>
* Examples of lowercase mappings are in the following table:
* <table border="1" summary="Lowercase mapping examples showing language code of locale, upper case, lower case, and description">
* <tr>
* <th>Language Code of Locale</th>
* <th>Upper Case</th>
* <th>Lower Case</th>
* <th>Description</th>
* </tr>
* <tr>
* <td>tr (Turkish)</td>
* <td>\u0130</td>
* <td>\u0069</td>
* <td>capital letter I with dot above -> small letter i</td>
* </tr>
* <tr>
* <td>tr (Turkish)</td>
* <td>\u0049</td>
* <td>\u0131</td>
* <td>capital letter I -> small letter dotless i </td>
* </tr>
* <tr>
* <td>(all)</td>
* <td>French Fries</td>
* <td>french fries</td>
* <td>lowercased all chars in String</td>
* </tr>
* <tr>
* <td>(all)</td>
* <td><img src="doc-files/capiota.gif" alt="capiota"><img src="doc-files/capchi.gif" alt="capchi">
* <img src="doc-files/captheta.gif" alt="captheta"><img src="doc-files/capupsil.gif" alt="capupsil">
* <img src="doc-files/capsigma.gif" alt="capsigma"></td>
* <td><img src="doc-files/iota.gif" alt="iota"><img src="doc-files/chi.gif" alt="chi">
* <img src="doc-files/theta.gif" alt="theta"><img src="doc-files/upsilon.gif" alt="upsilon">
* <img src="doc-files/sigma1.gif" alt="sigma"></td>
* <td>lowercased all chars in String</td>
* </tr>
* </table>
*
* @param locale use the case transformation rules for this locale
* @return the {@code String}, converted to lowercase.
* @see java.lang.String#toLowerCase()
* @see java.lang.String#toUpperCase()
* @see java.lang.String#toUpperCase(Locale)
* @since 1.1
* 将大写字符转换为小写
*/
public String toLowerCase(Locale locale) {
if (locale == null) {
throw new NullPointerException();
}
int firstUpper;
final int len = value.length;
/* Now check if there are any characters that need to be changed. */
scan: {
for (firstUpper = 0 ; firstUpper < len; ) {
char c = value[firstUpper];
//判断字符是否大写
if ((c >= Character.MIN_HIGH_SURROGATE)
&& (c <= Character.MAX_HIGH_SURROGATE)) {
int supplChar = codePointAt(firstUpper);
if (supplChar != Character.toLowerCase(supplChar)) {
break scan;
}
firstUpper += Character.charCount(supplChar);
} else {
if (c != Character.toLowerCase(c)) {
break scan;
}
firstUpper++;
}
}
return this;
}
char[] result = new char[len];
int resultOffset = 0; /* result may grow, so i+resultOffset
* is the write location in result */
/* Just copy the first few lowerCase characters. */
System.arraycopy(value, 0, result, 0, firstUpper);
String lang = locale.getLanguage();
boolean localeDependent =
(lang == "tr" || lang == "az" || lang == "lt");
char[] lowerCharArray;
int lowerChar;
int srcChar;
int srcCount;
for (int i = firstUpper; i < len; i += srcCount) {
srcChar = (int)value[i];
if ((char)srcChar >= Character.MIN_HIGH_SURROGATE
&& (char)srcChar <= Character.MAX_HIGH_SURROGATE) {
srcChar = codePointAt(i);
srcCount = Character.charCount(srcChar);
} else {
srcCount = 1;
}
if (localeDependent ||
srcChar == '\u03A3' || // GREEK CAPITAL LETTER SIGMA
srcChar == '\u0130') { // LATIN CAPITAL LETTER I WITH DOT ABOVE
lowerChar = ConditionalSpecialCasing.toLowerCaseEx(this, i, locale);
} else {
lowerChar = Character.toLowerCase(srcChar);
}
if ((lowerChar == Character.ERROR)
|| (lowerChar >= Character.MIN_SUPPLEMENTARY_CODE_POINT)) {
if (lowerChar == Character.ERROR) {
lowerCharArray =
ConditionalSpecialCasing.toLowerCaseCharArray(this, i, locale);
} else if (srcCount == 2) {
resultOffset += Character.toChars(lowerChar, result, i + resultOffset) - srcCount;
continue;
} else {
lowerCharArray = Character.toChars(lowerChar);
}
/* Grow result if needed */
int mapLen = lowerCharArray.length;
if (mapLen > srcCount) {
char[] result2 = new char[result.length + mapLen - srcCount];
System.arraycopy(result, 0, result2, 0, i + resultOffset);
result = result2;
}
for (int x = 0; x < mapLen; ++x) {
result[i + resultOffset + x] = lowerCharArray[x];
}
resultOffset += (mapLen - srcCount);
} else {
result[i + resultOffset] = (char)lowerChar;
}
}
return new String(result, 0, len + resultOffset);
}
trim
/**
* Returns a string whose value is this string, with any leading and trailing
* whitespace removed.
* <p>
* If this {@code String} object represents an empty character
* sequence, or the first and last characters of character sequence
* represented by this {@code String} object both have codes
* greater than {@code '\u005Cu0020'} (the space character), then a
* reference to this {@code String} object is returned.
* <p>
* Otherwise, if there is no character with a code greater than
* {@code '\u005Cu0020'} in the string, then a
* {@code String} object representing an empty string is
* returned.
* <p>
* Otherwise, let <i>k</i> be the index of the first character in the
* string whose code is greater than {@code '\u005Cu0020'}, and let
* <i>m</i> be the index of the last character in the string whose code
* is greater than {@code '\u005Cu0020'}. A {@code String}
* object is returned, representing the substring of this string that
* begins with the character at index <i>k</i> and ends with the
* character at index <i>m</i>-that is, the result of
* {@code this.substring(k, m + 1)}.
* <p>
* This method may be used to trim whitespace (as defined above) from
* the beginning and end of a string.
*
* @return A string whose value is this string, with any leading and trailing white
* space removed, or this string if it has no leading or
* trailing white space.
* 去除字符串首尾部分的空值,如,' ' or " ",非""
* 原理是通过substring去实现的,首尾各一个指针
* 头指针发现空值就++,尾指针发现空值就--
*/
public String trim() {
//代表尾指针,实际是尾指针+1的大小
int len = value.length;
//代表头指针
int st = 0;
char[] val = value; /* avoid getfield opcode */
// 找到字符串前段没有空格的位置:st<len,且字符的整数值小于32则代表有空值,st++
while ((st < len) && (val[st] <= ' ')) {
st++;
}
// 找到字符串末尾没有空格的位置:len - 1才是真正的尾指针,如果尾部元素的整数值<=32,则代表有空值,len--
while ((st < len) && (val[len - 1] <= ' ')) {
len--;
}
// 如果前后都没有出现空格,返回字符串本身:截取st到len的字符串(不包括len位置)
return ((st > 0) || (len < value.length)) ? substring(st, len) : this;
}
toString、toCharArray、valueOf
/**
* This object (which is already a string!) is itself returned.
*
* @return the string itself.
* 返回自己
*/
public String toString() {
return this;
}
/**
* Converts this string to a new character array.
*
* @return a newly allocated character array whose length is the length
* of this string and whose contents are initialized to contain
* the character sequence represented by this string.
* 返回value数组的拷贝
*/
public char[] toCharArray() {
// Cannot use Arrays.copyOf because of class initialization order issues
char result[] = new char[value.length];
System.arraycopy(value, 0, result, 0, value.length);
return result;
}
/**
* Returns the string representation of the {@code Object} argument.
*
* @param obj an {@code Object}.
* @return if the argument is {@code null}, then a string equal to
* {@code "null"}; otherwise, the value of
* {@code obj.toString()} is returned.
* @see java.lang.Object#toString()
* 将Object转换为字符串
*/
public static String valueOf(Object obj) {
return (obj == null) ? "null" : obj.toString();
}
format
/**
* Returns a formatted string using the specified format string and
* arguments.
*
* <p> The locale always used is the one returned by {@link
* java.util.Locale#getDefault() Locale.getDefault()}.
*
* @param format
* A <a href="../util/Formatter.html#syntax">format string</a>
*
* @param args
* Arguments referenced by the format specifiers in the format
* string. If there are more arguments than format specifiers, the
* extra arguments are ignored. The number of arguments is
* variable and may be zero. The maximum number of arguments is
* limited by the maximum dimension of a Java array as defined by
* <cite>The Java™ Virtual Machine Specification</cite>.
* The behaviour on a
* {@code null} argument depends on the <a
* href="../util/Formatter.html#syntax">conversion</a>.
*
* @throws java.util.IllegalFormatException
* If a format string contains an illegal syntax, a format
* specifier that is incompatible with the given arguments,
* insufficient arguments given the format string, or other
* illegal conditions. For specification of all possible
* formatting errors, see the <a
* href="../util/Formatter.html#detail">Details</a> section of the
* formatter class specification.
*
* @return A formatted string
*
* @see java.util.Formatter
* @since 1.5
* 使用本地语言环境,制定字符串格式和参数生成格式化的新字符串。
*/
public static String format(String format, Object... args) {
return new Formatter().format(format, args).toString();
}
/**
* Returns a formatted string using the specified locale, format string,
* and arguments.
*
* @param l
* The {@linkplain java.util.Locale locale} to apply during
* formatting. If {@code l} is {@code null} then no localization
* is applied.
*
* @param format
* A <a href="../util/Formatter.html#syntax">format string</a>
*
* @param args
* Arguments referenced by the format specifiers in the format
* string. If there are more arguments than format specifiers, the
* extra arguments are ignored. The number of arguments is
* variable and may be zero. The maximum number of arguments is
* limited by the maximum dimension of a Java array as defined by
* <cite>The Java™ Virtual Machine Specification</cite>.
* The behaviour on a
* {@code null} argument depends on the
* <a href="../util/Formatter.html#syntax">conversion</a>.
*
* @throws java.util.IllegalFormatException
* If a format string contains an illegal syntax, a format
* specifier that is incompatible with the given arguments,
* insufficient arguments given the format string, or other
* illegal conditions. For specification of all possible
* formatting errors, see the <a
* href="../util/Formatter.html#detail">Details</a> section of the
* formatter class specification
*
* @return A formatted string
*
* @see java.util.Formatter
* @since 1.5
* 使用指定的语言环境,制定字符串格式和参数生成格式化的字符串。
*/
public static String format(Locale l, String format, Object... args) {
return new Formatter(l).format(format, args).toString();
}
intern
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
* 本地方法。
* 在1.7以及以后,字符串常量池放到了堆中,同时永久代换成了元空间。
* 因为字符串常量池和对象都是在堆上的,所以常量池中保存的可能是对象也可能是堆上已经存在的对象的引用。
* 当调用str.intern()方法的时候,如果常量池中已经存在,则返回常量池中的对象;
* 如果常量池不存在,则将此String对象添加到字符串常量池中,并返回此对象的引用。
*/
public native String intern();
思考
String str = “abc” 和 String str1 = new String(“abc”)有什么区别
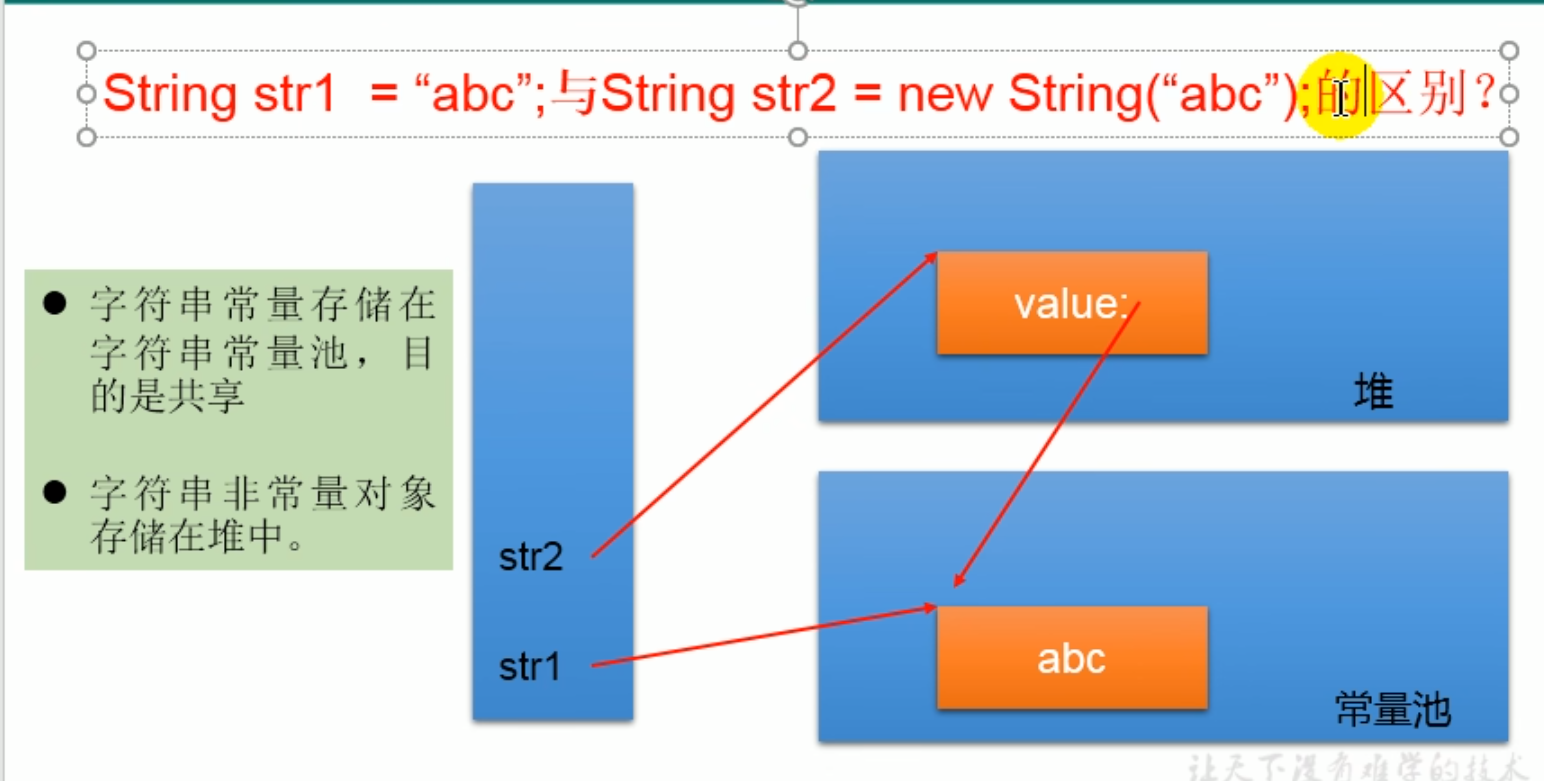
String str1 = “abc”; //在方法区字符串常量池中创建了一个abc字符串,并把地址赋值给s,产生了一个对象
String str2 = new String(“abc”);// 创建2个对象 new一个字符串对象在堆内存中,并在常量池中创建abc(字符串在常量池中,没有则创建,有则不创建)
字符串的拼接

注:字符串拼接有变量参与, 不会再常量池中,在堆空间中,相当于new String
String使用equals和==比较的区别

github:String源码
如文章有问题请留言,谢谢~