本文主要介绍TextCNN文本分类,主要从TextCNN的原理的Pytorch实现来逐步讲解。主要思想来自论文《Convolutional Neural Networks for Sentence Classification(EMNLP2014)
论文连接:[1408.5882] Convolutional Neural Networks for Sentence Classification (arxiv.org)
目录
一、CNN原理
1.1 卷积计算过程
1.2 激励层与池化层
二、TextCNN文本分类Pytorch实现
2.1 导入包
2.2 参数设置
2.3 数据预处理
2.4 模型构建
2.5 模型训练
2.6 模型测试
一、CNN原理
卷积神经网络各个层级结构,如下图:
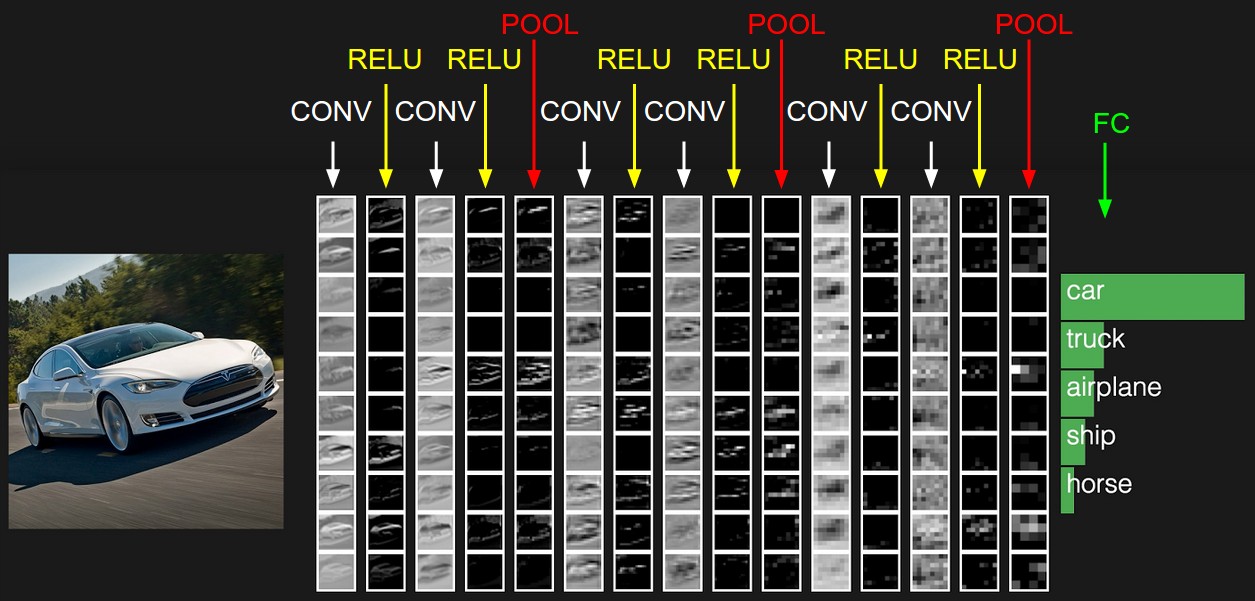
上图中 CNN 要做的事情是:给定一张图片,是车是马还是飞机未知,现在需要模型判断这张图片里具体是一个什么东西
最左边是
- 数据输入层,对数据做一些处理,比如去均值(把输入数据各个维度都中心化为 0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA / 白化等等。CNN 只对训练集做 “去均值” 这一步
中间是
- CONV:卷积层 (Convolutional Layer),线性乘积求和
- RELU:激励层,ReLU 是激活函数的一种
- POOL:池化层 (Pooling Layer),简言之,即取区域平均值或最大(最小)值
最右边是
- FC:全连接层 (Fully-Connected Layer)
1.1 卷积计算过程
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器 filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源
举个具体的例子。比如下图中,图中左边部分是原始输入数据,图中中间部分是滤波器 filter,图中右边是输出的新的二维数据,右上角是具体的计算过程

在下图对应的计算过程中,左边是图像输入,中间部分就是滤波器 filter(带着一组固定权重的神经元),不同的滤波器 filter 会得到不同的输出数据,比如颜色深浅、轮廓等。如果想提取图像的不同特征,则可以用不同的滤波器
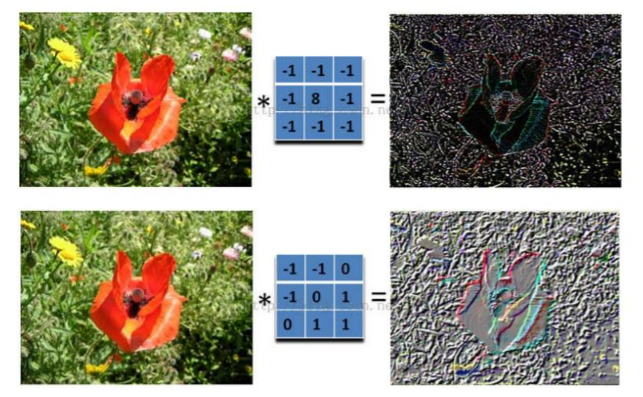
在 CNN 中,滤波器 filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。这个过程中,有这么几个参数:
- 深度 depth:即神经元个数,决定输出的 depth 厚度。同时代表滤波器个数
- 步长 stride:决定滑动多少步可以到边缘
- 填充值 zero-padding:在外围边缘补充若干圈 0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除

卷积动图
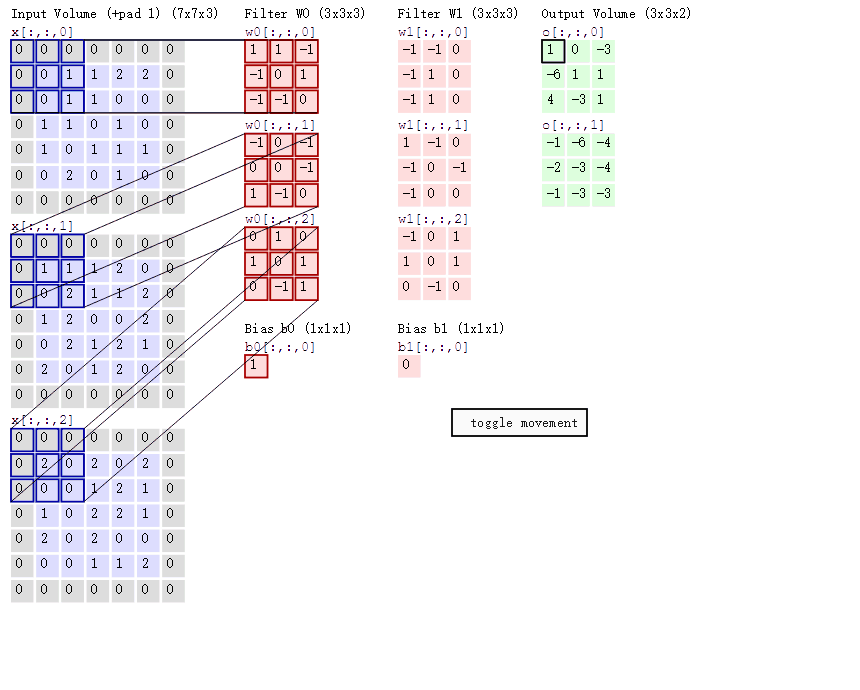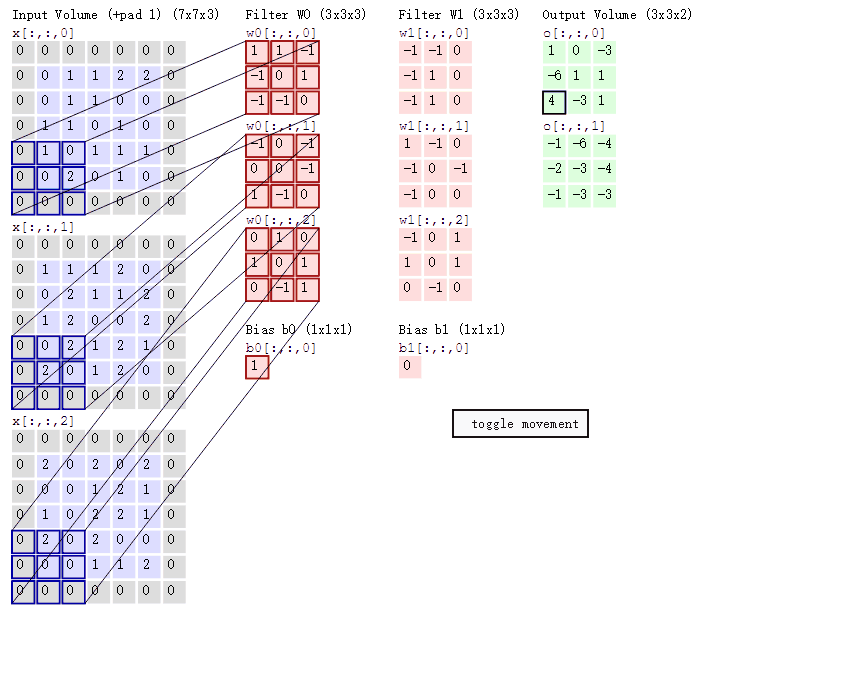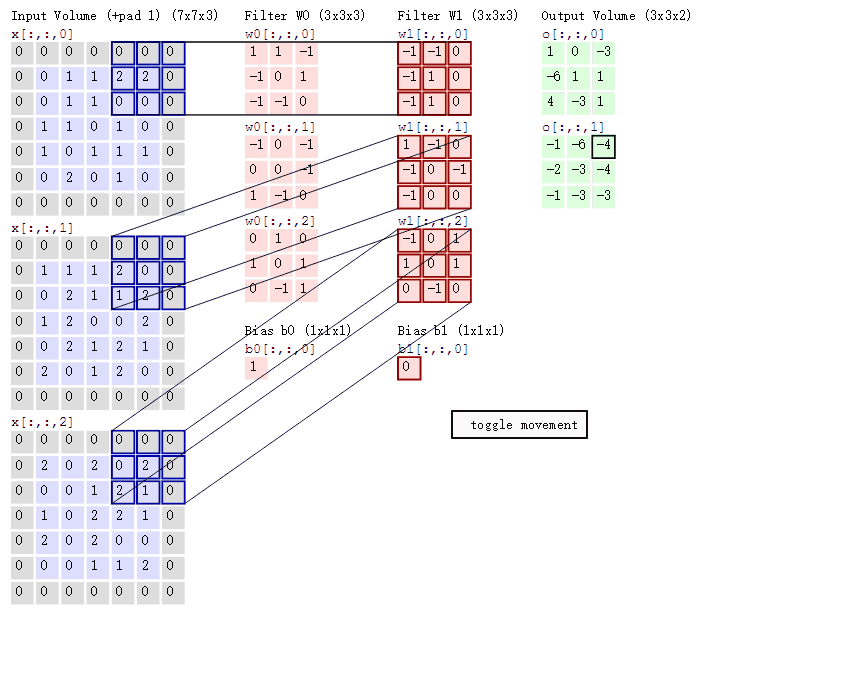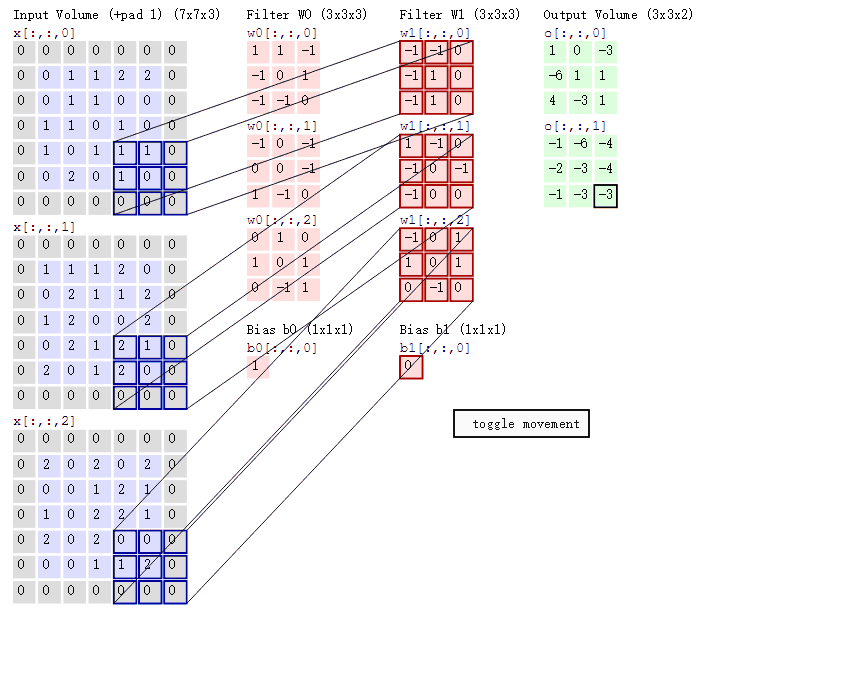
从图中可以看到:
- 有两个神经元,即两个滤波器,depth=2
- 数据窗口每次移动 2 个步长,取 3*3 的局部数据,即 stride=2
- zero-padding=1
然后分别以两个滤波器 filter 为轴滑动数组进行卷积计算,得到两组不同的结果
- 左边是输入(7*7*3 中,7*7 代表图像的长宽,3 代表 RGB 三个颜色通道)
- 中间部分是两个不同的滤波器 Filter w0、Filter w1
- 最右边则是两个不同的输出
随着左边数据窗口的平移滑动,滤波器 Filter w0 / Filter w1 对不同的局部数据进行卷积计算
值得一提的是:左边数据在变化,每次滤波器都是针对某一局部的数据窗口进行卷积,这就是所谓的 CNN 中的局部感知机制。打个比方,滤波器就像一双眼睛,人类视角有限,一眼望去,只能看到这世界的局部。如果一眼就看到全世界,你会累死,而且一下子接受全世界所有信息,你大脑接收不过来
与此同时,数据窗口滑动,导致输入在变化,但中间滤波器 Filter w0 的权重(即每个神经元连接数据窗口的权重)是固定不变的,这个权重不变即所谓的 CNN 中的参数(权重)共享机制
最后提一点,从图上我们可以看到,每个 filter 下面都有一个 bias,因此要在原来的内积计算结束后,再加上这个 bias,得到最终的对应位置值
最后再给一个经过卷积后的图像长宽计算公式

1.2 激励层与池化层
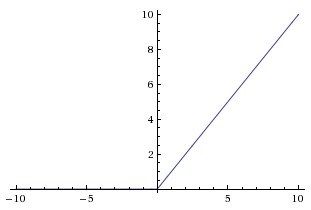
激励层
现在绝大部分神经网络采用的激励函数都是 Relu,它的优点是收敛快,求梯度简单,其图形表示如下
池化层(Pooling Layer)
池化,简言之,就是取某个区域的平均值或最大(最小)值,如下图所示
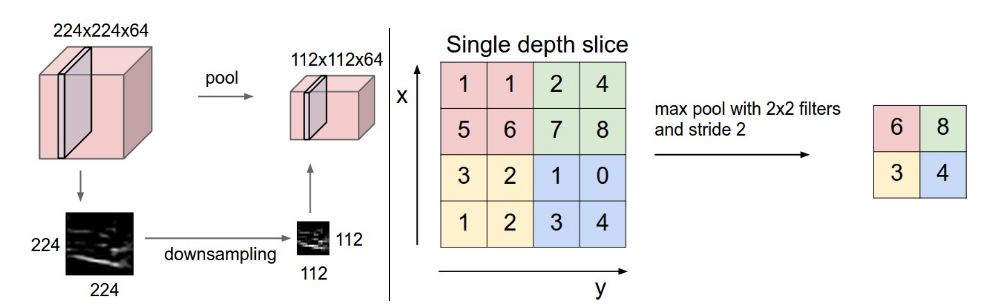
上图所展示的是取区域最大值,即左上角 2x2 的矩阵中 6 最大,右上角 2x2 的矩阵中 8 最大,左下角 2x2 的矩阵中 3 最大,右下角 2x2 的矩阵中 4 最大,所以得到上图右边部分的结果:6 8 3 4
二、TextCNN文本分类Pytorch实现
2.1 导入包
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
dtype = torch.FloatTensor
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')2.2 参数设置
#(senquence_length = 3)
sentences = ["i love you", "he loves me", "she likes baseball", "i hate you", "sorry for that", "this is awful"]
labels = [1,1,1,0,0,0]
#TextCNN Parameter
embedding_size = 2
sequence_length = len(sentences[0]) # every sentences contains sequence_length(=3) words
num_classes = len(set(labels)) # num_class = 2
batch_size = 3
word_list = " ".join(sentences).split() # ['i', 'love', 'you', 'he', 'loves', 'me', 'she', 'likes', 'baseball', 'i', 'hate', 'you', 'sorry', 'for', 'that', 'this', 'is', 'awful']
word2idx = {w: i for i ,w in enumerate(vocab)} # {'that': 0, 'loves': 1, 'likes': 2, 'for': 3, 'love': 4, 'sorry': 5, 'she': 6, 'you': 7, 'is': 8, 'me': 9, 'baseball': 10, 'hate': 11, 'he': 12, 'i': 13, 'awful': 14, 'this': 15}
vocab = list(set(word_list)) # ['that', 'loves', 'likes', 'for', 'love', 'sorry', 'she', 'you', 'is', 'me', 'baseball', 'hate', 'he', 'i', 'awful', 'this']
vocab_size = len(vocab)2.3 数据预处理
def make_data(sentences, labels):
inputs = []
# 把每个句子中的单词替换为id [[13, 4, 7], [12, 1, 9], [6, 2, 10], [13, 11, 7], [5, 3, 0], [15, 8, 14]]
for sen in sentences:
inputs.append([word2idx[n] for n in sen.split()])
targets = []
for out in labels:
targets.append(out)
return inputs, targets
# input_batch=[[13, 4, 7], [12, 1, 9], [6, 2, 10], [13, 11, 7], [5, 3, 0], [15, 8, 14]],target_batch=[1, 1, 1, 0, 0, 0]
input_batch, target_batch = make_data(sentences,labels)
"""input_batch=tensor([[13, 4, 7],
[12, 1, 9],
[ 6, 2, 10],
[13, 11, 7],
[ 5, 3, 0],
[15, 8, 14]]),target_batch=tensor([1, 1, 1, 0, 0, 0])"""
input_batch, target_batch = torch.LongTensor(input_batch), torch.LongTensor(target_batch)
dataset = Data.TensorDataset(input_batch, target_batch)
loader = Data.DataLoader(dataset, batch_size, True)2.4 模型构建
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN, self).__init__()
self.W = nn.Embedding(vocab_size, embedding_size)
output_channel = 3
self.conv = nn.Sequential(
# conv : [input_channel(=1), out_channel,(filer_height,filter_width),stride=1]
nn.Conv2d(1, output_channel, (2, embedding_size)),
nn.ReLU(),
# pool : ((filter_height, filter_width))
nn.MaxPool2d((2,1)),
)
# fc
self.fc = nn.Linear(output_channel, num_classes)
def forward(self, X):
"""
X: [batch_size, sequence_length]
"""
batch_size = X.shape[0]
embedding_X = self.W(X) # [batch_size, sequence_length, embedding_size]
embedding_X = embedding_X.unsqueeze(1) # add channel(=1) [batch, channel(=1),squence_length,embedding_size]
conved = self.conv(embedding_X) # [batch_size, output_channel*1*1]
flatten = conved.view(batch_size, -1) # 数据变成batch_size行
output = self.fc(flatten)
return output
下面详细介绍一下数据在网络中流动的过程中维度的变化。输入数据是个矩阵,矩阵维度为 [batch_size, seqence_length],输入矩阵的数字代表的是某个词在整个词库中的索引(下标)
首先通过 Embedding 层,也就是查表,将每个索引转为一个向量,比方说 12 可能会变成 [0.3,0.6,0.12,...],因此整个数据无形中就增加了一个维度,变成了 [batch_size, sequence_length, embedding_size]
之后使用 unsqueeze(1) 函数使数据增加一个维度,变成 [batch_size, 1, sequence_length, embedding_size]。现在的数据才能做卷积,因为在传统 CNN 中,输入数据就应该是 [batch_size, in_channel, height, width] 这种维度

[batch_size, 1, 3, 2] 的输入数据通过 nn.Conv2d(1, 3, (2, 2)) 的卷积之后,得到的就是 [batch_size, 3, 2, 1] 的数据,由于经过 ReLU 激活函数是不改变维度的,所以就没画出来。最后经过一个 nn.MaxPool2d((2, 1)) 池化,得到的数据维度就是 [batch_size, 3, 1, 1]

2.5 模型训练
model = TextCNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr = 1e-3)
#Training
for epoch in range(5000):
for batch_x, batch_y in loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d'%(epoch + 1),'loss = ','{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()打印结果
Epoch: 1000 loss = 0.004997 Epoch: 1000 loss = 0.003771 Epoch: 2000 loss = 0.000500 Epoch: 2000 loss = 0.000527 Epoch: 3000 loss = 0.000079 Epoch: 3000 loss = 0.000158 Epoch: 4000 loss = 0.000048 Epoch: 4000 loss = 0.000019 Epoch: 5000 loss = 0.000010 Epoch: 5000 loss = 0.000010
2.6 模型测试
# Test
test_text = 'i hate me'
tests = [[word2idx[n] for n in test_text.split()]]
test_batch = torch.LongTensor(tests).to(device)
# Predict
model = model.eval()
predict = model(test_batch).data.max(1, keepdim=True)[1]
if predict[0][0] == 0:
print(test_text,"is Bad Mean...")
else:
print(test_text,"is Good Mean!!")打印结果
i hate me is Bad Mean...
预测成功!
参考
1. CS231n笔记:通俗理解CNN - mathor (wmathor.com)
2. TextCNN的PyTorch实现 - mathor (wmathor.com)


![[BJDCTF2020]Easy MD51](https://img-blog.csdnimg.cn/img_convert/57829304e2c0456a965417ab09d32338.png)