14.1 深度学习基础
14.1.1 深度学习的基本思想
- 特征工程:尽可能选择和构建出好的特征,使得机器学习算法能够达到最佳性能。是机器学习的上限,而算法就是逼近这个上限
- 传统的机器学习特证工程
- 依靠人工方式提取和设计特征
- 需要大量的专业知识和经验
- 特征设计和具体任务密切相关
- 特征的计算、调整和测试需要大量的时间
- 隐含层的作业就是提取特征层,因此隐含层也被叫做特征层
- 深度神经网络:有多层隐含层的神经网络。
- 使用神经网络,特征工程就没那么重要了,只需要对原始数据做一些必要的预处理之后,把他们直接喂入神经网络之中,通过训练,自动的调整权值,使得预测的结果符合预计的要求,这种方式称为端到端学习:自动的从数据中学习特征。
- 随着层数的增加,表达出的特征越来越抽象,能力也越好,有多个隐含层的深度神经网络就是深度学习(Deep Learning)
- 自动的从数据中学习到与任务相关的特征
- 提取出的特征缺乏可解释性
- 数据驱动:当某个任务的数据量大到一定程度,及其就可能在该任务上超过人类
14.1.2 深度学习三要素
- 深度学习三要素:数据、算法和计算机
14.1.2.1 数据
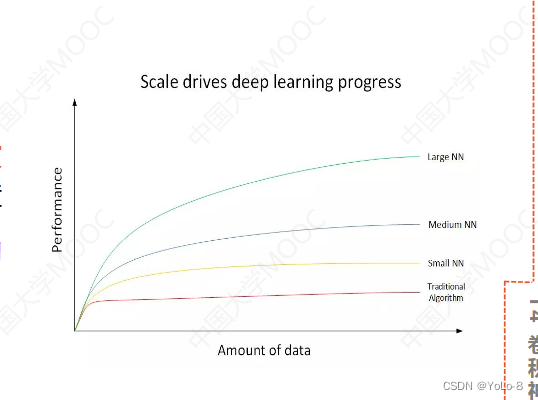
- 数据量大,神经网络随着网络的规模递增
- 数据量越大,深度学习的优势越明显
- 大规模深层神经网络需要算法创新和改进,使深度学习的性能和速度得到保障
- 训练大规模深层神经网络,需要强大的计算资源
14.2 图像识别与深度学习
- 图像识别:利用计算机对图像进行处理和分析,使机器能理解图像中的内容
- 图像识别的核心问题就是图像特征的提取
- 颜色特征
- 颜色直方图:描述了颜色色彩在整幅图中所占的比例,并没有描述每种颜色所处的空间位置,因此颜色特征需要和其他特征配合使用
- 形状特征:可以提取出景物的轮廓或者形状轮廓
- 纹理特征:描述了图像或者图像区域的景物的表面性质
- 语义鸿沟(Semantic Gap):图像的底层视觉特性和高层语义概念之间的鸿沟
- 还有会出现不相似的视觉特性,相同的语义概念
- 深度学习:采用端到端的学习方法
14.3 图像卷积
14.3 图像卷积运算
- 下面看图像的卷积运算是如何实现的
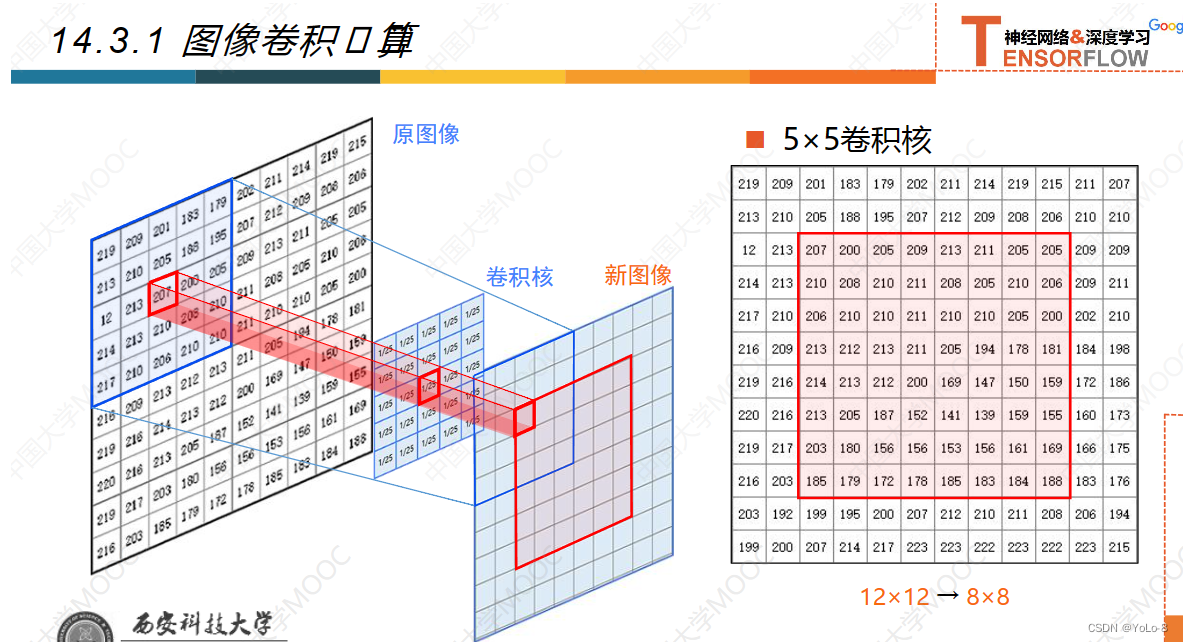
- 我们知道数字图像在计算机中保存为一个矩阵,矩阵中每个元素的值就是图像中对应像素点的灰度值,对数字图像做卷积运算,就是对图像中每个像素点用它周围像素点的灰度值加权求和去调整这个点的灰度值;
- 首先需要定义一个卷积核/卷积模板,是一个NN的矩阵,卷积核的尺寸决定了卷积卷积运算的范围,他应该是一个奇数,这样才有一个中心点,卷积核中的数字就是这个点和周围点的权值,一般采用比较小的卷积
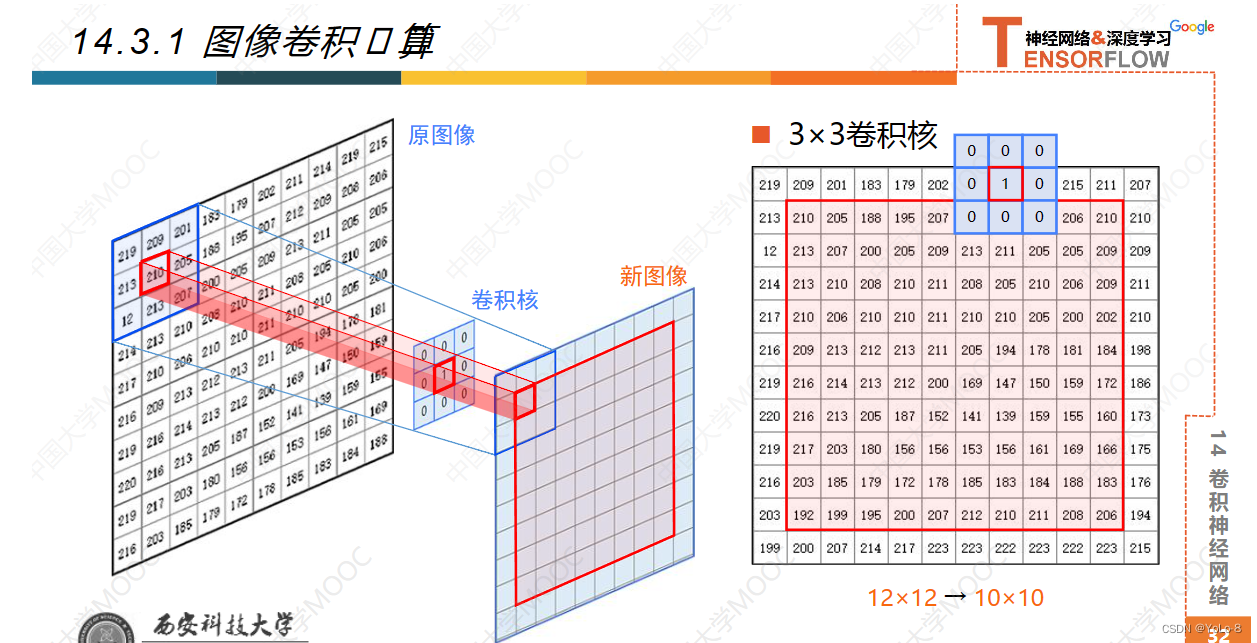
核,如55、77请添加图片描述
每次滑动,卷积之后得到的矩阵,会小一圈
55的卷积核就会小两圈
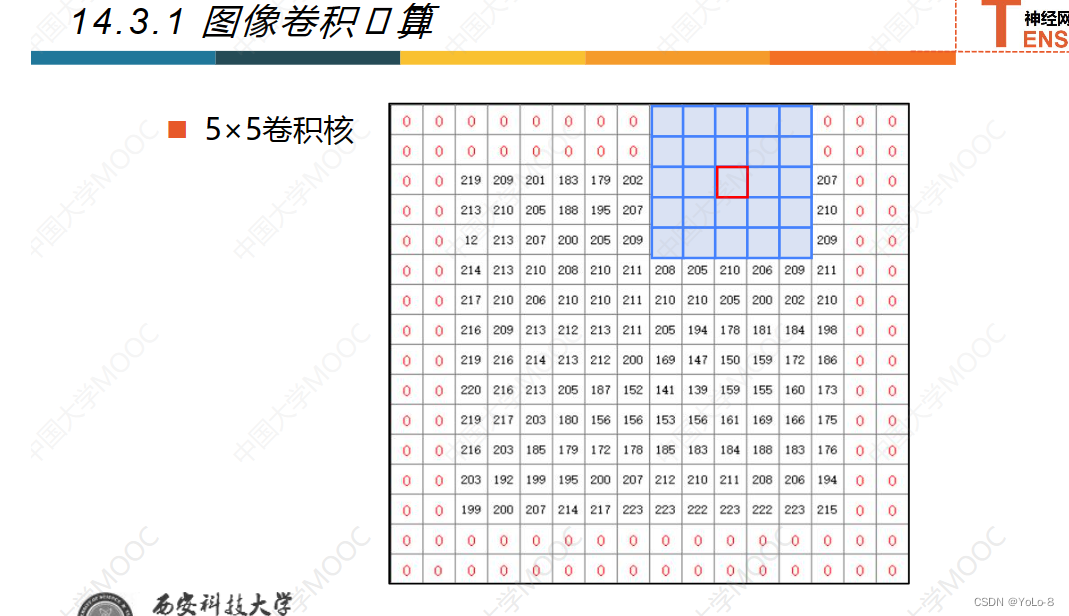
如果不想卷积之后的变小,那就可以自己先填充
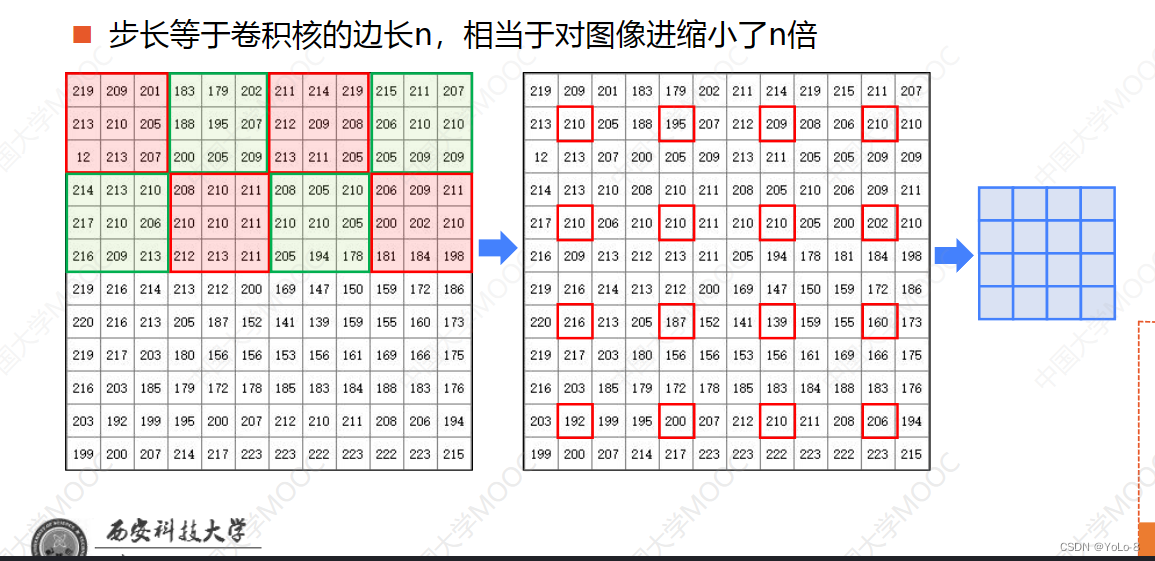
- 步长(stride):卷积核一次移动的像素数
- 步长等于卷积核的边长n,相当于对图像进行缩小了n倍
14.3.2 图像卷积在机器学习中的应用
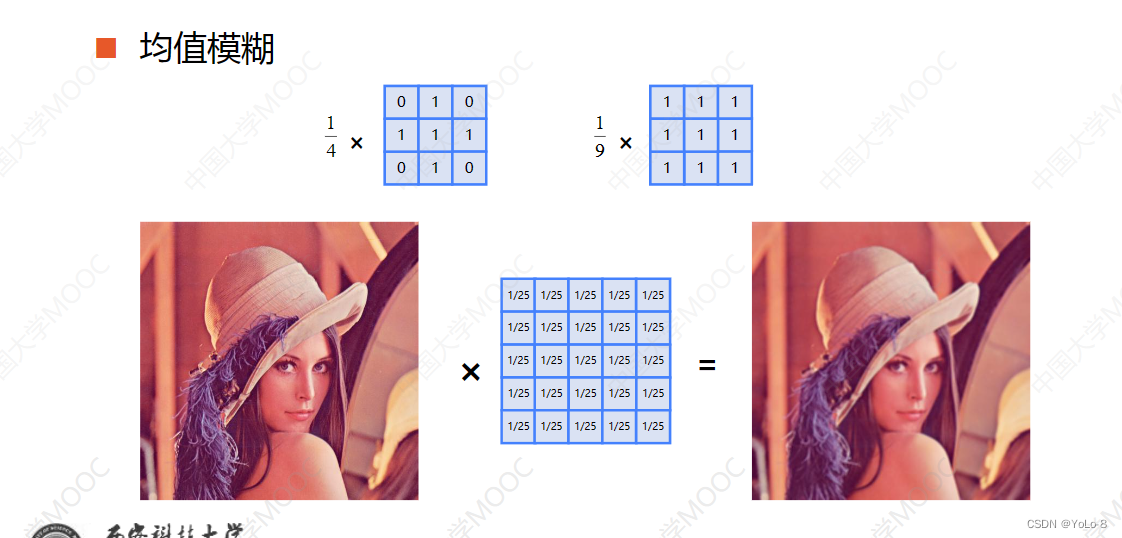
- 均值模糊

- 高斯模糊:根据高斯分布的取值来确定权值
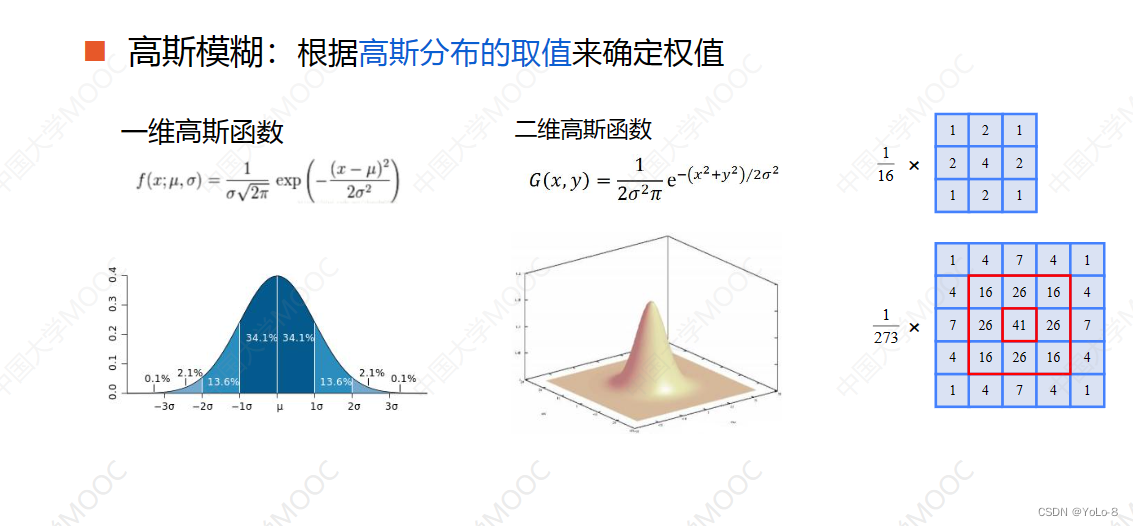

可以看到高斯模糊在平滑物体表面的同时,能够更好的保持物体的表面和轮廓
- 边缘检测:计算当前点和周围点的颜色值或灰度值的差别
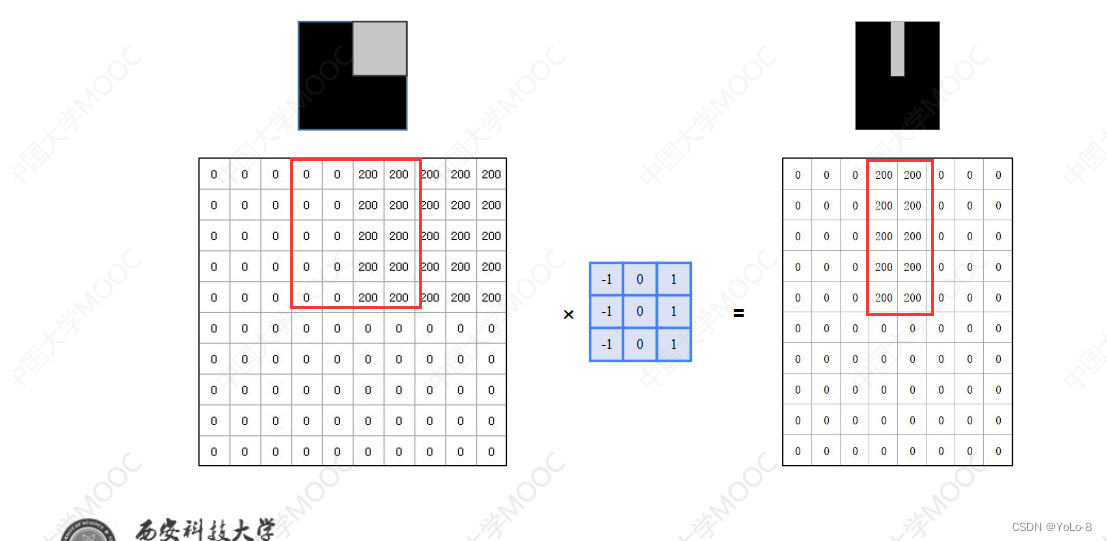
能够检测出竖直的边缘
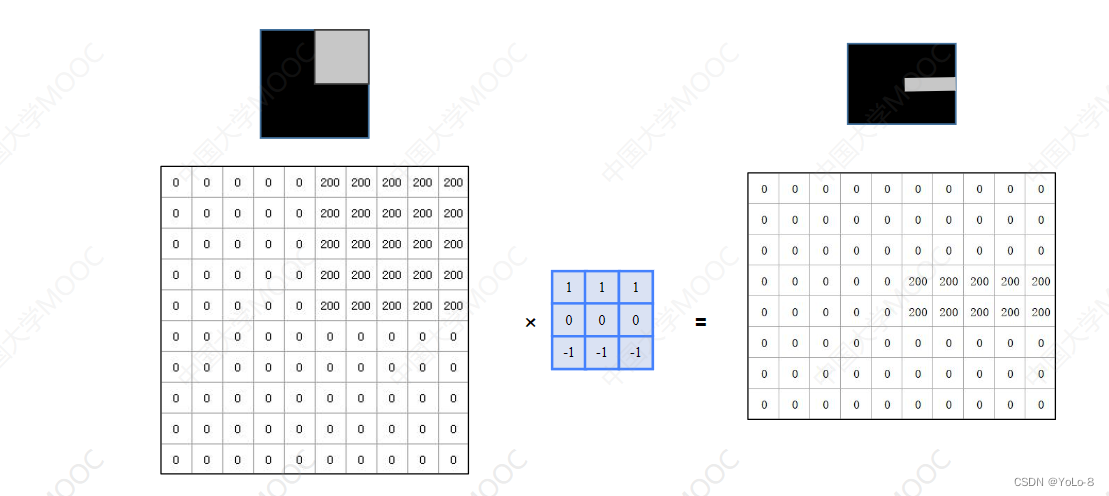
能偶检测出水平的边缘,两者结合
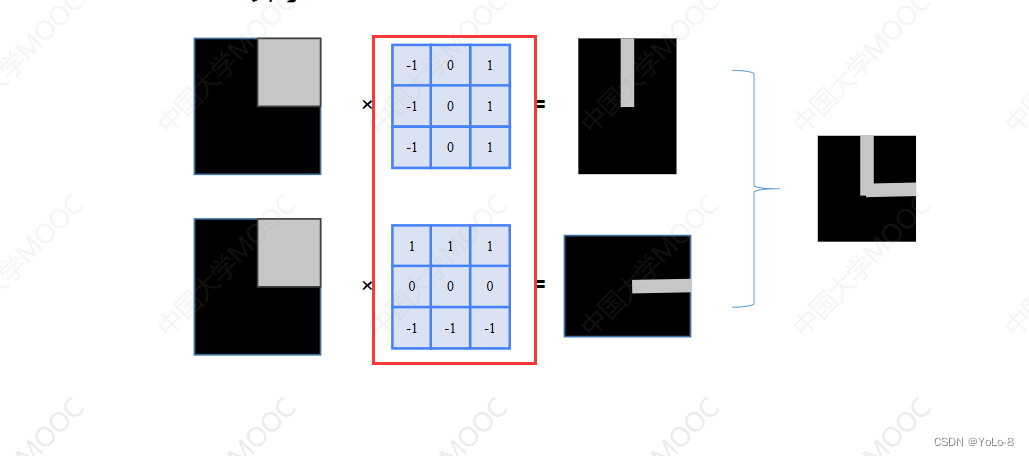
能偶检测出45°角的边缘

在prewitt算子的基础上,增加了权重的概念,认为上下左右直线方向的距离大于斜线方向的距离,因此他们的权重更大
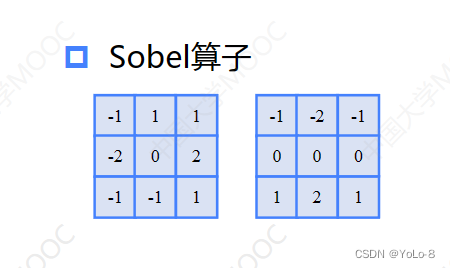
它通过对邻域中心像素的四方向或者八方向求梯度,再将梯度相加起来,判断中心像素灰度与邻域内其他灰度像素的关系

他将高斯和Laplcian算子相结合,综合考虑了对噪声的抑制和边缘检测,它的抗干扰能力强,边界定位精度高,边缘连续性好,而且能够有效提取对比度弱的边界,在图像处理领域中,得到了广泛的应用
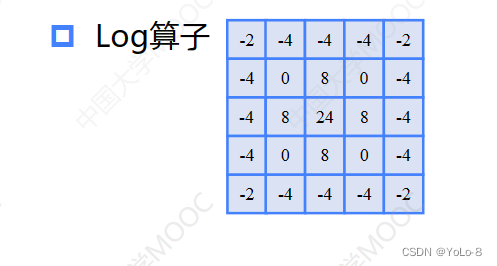
- 图像的卷积运算可以看作是提取图像特征的方式,使用不同的卷积核,可以抽取不同的图像特征
14.4 卷积神经网络
14.4.1 卷积神经网络的基本思想
- 全连接神经网络
- 隐含层可以自动学习数据中的特征
- 每一个节点都和它前面一层中的所有节点相连,能够最大程度保留输入数据中所有信息,不会漏掉原始数据中每个维度所贡献的信息
- 参数量非常大,网络收敛速度慢
- 动物视觉系统
- 视觉皮层的神经元是局部接受信息的
- 感受野(receptive field):一个神经元所接受并相应的刺激区域
-
权值共享
-
卷积神经网络(Convolutional Neural Networks,CNN)
- 使用不同的卷积核
- 每个卷积核可以得到一个特征
- 多个卷积核可以得到多个特征
- 卷积网络采用局部连接和权值共享的机制,使得网络的结构更接近于实际的生物神经网络,降低了网络的复杂性,模型参数的数量远小于全连接神经网络,而且由于同一层中的神经元权值相同,网络可以并行学习。
- 卷积核的权值是从数据中学习得到的
- 每个卷积网络的权值是根据任务目标自动学习出来的,这样更加灵活和智能,更好的处理语音和视频
14.4.2 卷积神经网络的结构
- 卷积神经网络是一种多层的前馈型神经网络,从结构上,它可以分为分为特征提取阶段和分类识别阶段
- 特征提取阶段通常由多个特征曾堆叠而成,每个特征层由卷积层和池化层组成;处在网络前端的特征层用来捕捉图像局部细节信息,后面的特征层捕捉图像中更加抽象的信息;
- 分类识别阶段通常是一个简单的分类器,例如全连接网络或者支持向量机,他接受最后一个特征层的输出完成分类和识别
- 特征提取阶段
- 卷积层(convolution):特征提取层,使用卷积和提取图像中的特征,这里的卷积运算是有偏置项的;一个卷积核在整张图像中提取到的特征构成特征图(feature map)
- 每个卷积层中包含多个卷积核
- 在卷积核之后会定一个激活函数(relu)

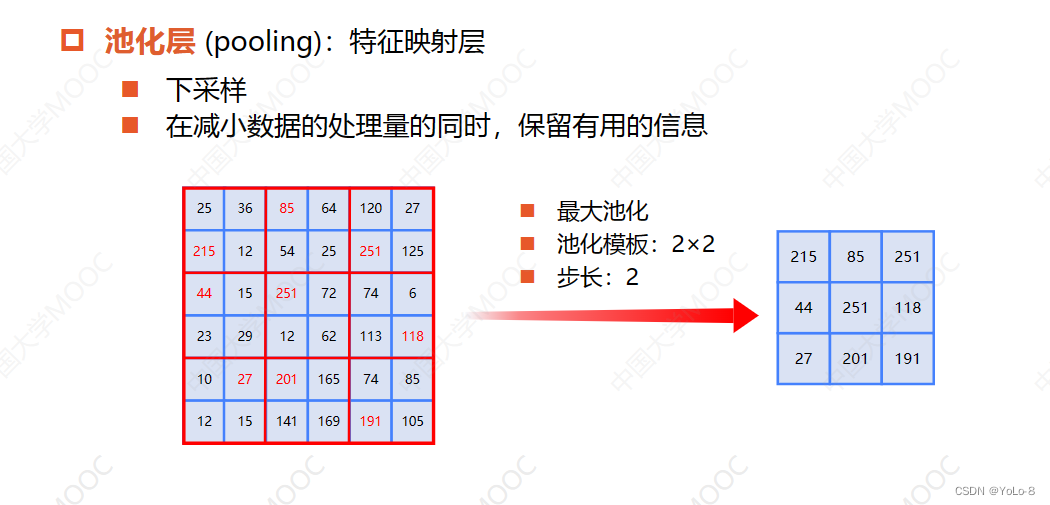
1.池化层(pooling):特征映射层;池化是一种下采样运算;在减少数据运算量的同时,保留有用的信息
2如下一个尺寸为66的图片,对他进行最大池化,池化模板的尺寸为22,步长为2,就是把它按照2*2的小区域进行分块,把每个块合并成一个像素,去每个块中的最大值,作为合并后的像素值
3可以得到图像的
4最大池化就是在缩小图像的同时,对每个图像最亮的像素采样,可以得到图像的主要轮廓,因此池化又进行了一次网络提取
5进一步抽象信息
6提高了泛化性,防止过拟合

- 在网络前端的卷积层中,每个神经元只连接输入图像中很小的一个范围,感受野比较小,能够捕获图像中局部细节的信息;而经过多层卷积层和池化层的堆叠后,后面的卷积层中,神经元的感受野逐层加大,可以捕获图像中更高层,更抽象的信息,从而得到图像在各个不同尺度上的抽象表示。
- 除了最大池化,还有其他的池化方法

- 重叠采样的池化(Overlapping):池化步长小于n,每个块之间有相互重叠的部分
- 池化层在卷积神经网络中并不是一个必须的,在目前一些新的卷积网络中,就没有池化层的出现
- 卷积神经网络是一种监督学习的神经网络,训练过程与传统的人工神经网络相似;首先,从训练集中取出样本,输入网络;经过逐级变化,传输到输出层,计算输出层与样本标签之间的差值,反向传播误差,采用梯度下降法更新权值,最小化损失,反复迭代,在网络收敛,并达到预期的精度时,结束训练,保存网络参数,以后就可以直接使用这个训练好的网络进行数据分类
14.5 实例:卷积神经网络实现手写数字识别
# 1 导入库
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
import numpy as np
import matplotlib.pyplot as plt
# 在使用GPU版本的Tensorflow训练模型时,有时候会遇到显存分配的错误
# InternalError: Bias GEMM launch failed
# 这是在调用GPU运行程序时,GPU的显存空间不足引起的,为了避免这个错误,可以对GPU的使用模式进行设置
gpus = tf.config.experimental.list_physical_devices('GPU')# 这是列出当前系统中的所有GPU,放在列表gpus中
# 使用第一块gpu,所以是gpus[0],把它设置为memory_growth模式,允许内存增长也就是说在程序运行过程中,根据需要为TensoFlow进程分配显存
# 如果系统中有多个GPU,可以使用循环语句把它们都设置成为true模式
tf.config.experimental.set_memory_growth(gpus[0], True)
# 2 加载数据
mnist = tf.keras.datasets.mnist
(train_x,train_y),(test_x,test_y) = mnist.load_data()
# (60000,28,28),(60000,),(10000,28,28),(10000,)
# numpy.ndarray,numpy.ndarray,numpy.ndarray,numpy.ndarray
# 3 数据预处理,这里也可以省去,在之后为进行维度变换
# X_train = train_x.reshape((60000,28*28)) # (60000,784)
# X_test = test_x.reshape((10000,28*28)) # (10000,784)
# 对属性进行归一化,使它的取值在0~1之间,同时转换为tensorflow张量,类型为tf.float32
X_train = train_x.reshape(60000,28,28,1) # (60000,28,28,1)
X_test = test_x.reshape(10000,28,28,1) # (10000,28,28,1)
#X_train = tf.expend_dims(train_x,3)
#X_test = tf.expend_dims(test_x,3)
X_train,X_test = tf.cast(X_train/255.0,tf.float32),tf.cast(X_test/255.0,tf.float32)
y_train,y_test = tf.cast(train_y,tf.int32),tf.cast(test_y,tf.int32)
# 4 建立模型
model = tf.keras.Sequential([
# unit1
tf.keras.layers.Conv2D(16,kernel_size = (3,3),padding="same",activation=tf.nn.relu,input_shape=(28,28,1)),
tf.keras.layers.MaxPool2D(pool_size=(2,2)),
# unit2
tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding="same",activation=tf.nn.relu),
tf.keras.layers.MaxPool2D(pool_size=(2,2)),
# unit3
tf.keras.layers.Flatten(),
# unit4
tf.keras.layers.Dense(128,activation="relu"),
tf.keras.layers.Dense(10,activation="softmax")
])
# 5 配置训练方法
model.compile(optimizer='adam',
loss = 'sparse_categorical_crossentropy',
metrics = ['sparse_categorical_accuracy'])
# 6 训练模型
model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
# 7 评估模型
model.evaluate(X_test,y_test,verbose=2)
# 8 使用模型
np.argmax(model.predict([[X_test[0]]]))# 两层中括号
# 随机抽取4个样本
for i in range(4):
num = np.random.randint(1,10000)
plt.subplot(1,4,i+1)
plt.axis("off")
plt.imshow(test_x[num],cmap='gray')
y_pred = np.argmax(model.predict([[X_test[num]]]))
plt.title("y="+str(test_y[num])+"\ny_pred"+str(y_pred))
plt.show()
输出结果为:
Train on 48000 samples, validate on 12000 samples
Epoch 1/5
2021-12-20 14:04:34.470826: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cublas64_100.dll
2021-12-20 14:04:34.721941: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudnn64_7.dll
2021-12-20 14:04:35.626785: W tensorflow/stream_executor/cuda/redzone_allocator.cc:312] Internal: Invoking ptxas not supported on Windows
Relying on driver to perform ptx compilation. This message will be only logged once.
48000/48000 [==============================] - 5s 95us/sample - loss: 0.2031 - sparse_categorical_accuracy: 0.9398 - val_loss: 0.0721 - val_sparse_categorical_accuracy: 0.9783
Epoch 2/5
48000/48000 [==============================] - 3s 54us/sample - loss: 0.0616 - sparse_categorical_accuracy: 0.9808 - val_loss: 0.0687 - val_sparse_categorical_accuracy: 0.9797
Epoch 3/5
48000/48000 [==============================] - 3s 54us/sample - loss: 0.0437 - sparse_categorical_accuracy: 0.9868 - val_loss: 0.0480 - val_sparse_categorical_accuracy: 0.9850
Epoch 4/5
48000/48000 [==============================] - 3s 54us/sample - loss: 0.0329 - sparse_categorical_accuracy: 0.9900 - val_loss: 0.0423 - val_sparse_categorical_accuracy: 0.9872
Epoch 5/5
48000/48000 [==============================] - 3s 53us/sample - loss: 0.0248 - sparse_categorical_accuracy: 0.9925 - val_loss: 0.0386 - val_sparse_categorical_accuracy: 0.9892
10000/1 - 1s - loss: 0.0167 - sparse_categorical_accuracy: 0.9886

【参考文献】: 神经网络与深度学习——TensorFlow实践