文章目录
- 前言
- 一、 准备工作
- 二、resultMap处理字段和属性的映射关系
- 三、多对一映射
- 0、级联方式处理映射关系
- 1、使用association处理映射关系
- 2、分步查询解决多对一关系
- (1) 查询员工信息
- (2) 根据员工所对应的部门id查询部门信息
- 延迟加载
- 三、一对多的关系处理
- 0、使用collection来维系一对多的关系
- 1、分步查询
- (1)查询部门信息
- (2)根据部门id查询部门中的所有员工
- (3)测试类
前言
在开发中,我们不是总是对单表进行操作的场景。按照数据库表的设计原则,要符合一定的范式,那么就需要对某一种场景的表进行拆分。
在业务上,可能是属于同一个业务。但是,在数据库中表的存储这块,可能就会涉及到表的拆分。
这里设计到表的创建直接创建两张表:
一、 准备工作
- 对于如何搭建
MyBatis的测试环境,在博文从0到1搭建MyBatis实例思路剖析中有详细的介绍,这里就不一一的进行展开。 - 在
MySQL数据库中创建两张表作为本次测试所需要的环境基础。
在第一步的基础上,我们导入两张表。一张是t_dept,另一张是t_emp表
t_dept表
DROP TABLE IF EXISTS `t_dept`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `t_dept` (
`did` int NOT NULL,
`dept_name` varchar(45) DEFAULT NULL,
PRIMARY KEY (`did`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `t_dept`
--
LOCK TABLES `t_dept` WRITE;
/*!40000 ALTER TABLE `t_dept` DISABLE KEYS */;
INSERT INTO `t_dept` VALUES (1,'开发组'),(2,'ai组'),(3,'运维组');
/*!40000 ALTER TABLE `t_dept` ENABLE KEYS */;
UNLOCK TABLES;
t_emp表:
DROP TABLE IF EXISTS `t_emp`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `t_emp` (
`eid` int NOT NULL,
`emo_name` varchar(45) DEFAULT NULL,
`age` int DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`email` varchar(45) DEFAULT NULL,
`did` int DEFAULT NULL,
PRIMARY KEY (`eid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `t_emp`
--
LOCK TABLES `t_emp` WRITE;
/*!40000 ALTER TABLE `t_emp` DISABLE KEYS */;
INSERT INTO `t_emp` VALUES (1,'lucy',23,'0','lucy@gmail.com',1),(2,'jack',24,'1','jack@gmail.com',1),(3,'smith',22,'1','smith@openai.com',2),(4,'zhangsan',46,'1','zhangsan@openai.com',2),(5,'limu',47,'1','limu@amazon.com',3),(6,'fong',23,'1','fong@amazon.com',3);
/*!40000 ALTER TABLE `t_emp` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
先大致看一下数据库中的数据:

- 建立mapper、pojo、映射文件
整体的项目结构是:

mapper接口:
public interface DeptMapper {
}
public interface EmpMapper {
}
pojo:
// dept
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Dept{
private Integer did;
private String deptName;
}
// emp
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Emp {
private Integer eid;
private String empName;
private Integer age;
private String sex;
private String email;
}
这里我直接使用
lombok来动态的生成getter和setter方法
使用方法是直接在pom.xml文件中导入依赖
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.26</version>
</dependency>
xxxMapper.xml
<!--DeptMapper.xml-->
<mapper namespace="com.fckey.mybatis.mapper.DeptMapper">
</mapper>
<!--EmpMapper.xml-->
<mapper namespace="com.fckey.mybatis.mapper.EmpMapper">
</mapper>
二、resultMap处理字段和属性的映射关系
若字段名和实体类中的属性名不一致,但是字段名和属性名通过驼峰规则可以可以进行转变的。或者是不能进行转变的。都有对应的处理方法。
下面这种就是符合驼峰规则的:

对于可以通过驼峰规则进行映射的,有一种特有的解决映射问题的方法,可以直接在mybatis-config.xml全局配置文件中配置mapUnderscoreToCamelCase支持这种关系的映射
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
还有更加通用的方法解决映射问题:
- 给所有查出的字段起一个别名
<!-- List<Emp> getAll();-->
<select id="getAll" resultType="emp">
select eid, emp_name empName, age, sex, email from t_emp
</select>
- 自定义
resultmap来定义映射规则
在resultMap中,一一对应地设置属性名->字段名,再在select标签中添加resultMap="对应resultMap的id"
<!--
resultMap设置自定义映射关系
id 唯一标识
type 映射的实体类型
子标签:id 设置主键的映射关系, result设置其他的映射关系
property 设置映射关系中的属性名,必须是type属性所设置的实体类类型的属性名
column 设置映射关系中的字段名,必须是sql语句查询出来的字段名
如果使用resultMap,就所有属性都需要设置
-->
<resultMap id="empResultMap" type="Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
</resultMap>
<select id="getAll" resultMap="empResultMap">
select * from t_emp
</select>
三、多对一映射
如:查询员工信息以及员工所对应的部门信息
对于在Java实体类层面中维护多对多,一对多的这种映射关系。 需要在“一”的pojo中加入List<多>属性,在“多”的pojo中加入“一”
也就是说,在Dept类中,要加入private List<Emp> emps;在Emp类中,要加入private Dept dept;。

下面我们来看看在mybatis中解决多对一映射关系是如何进行处理,以及处理方法有哪几种 ?
对于多对一关系中,对于SQL的查询,是固定的多表连接查询。这无论是对于哪个需要手写sql的orm框架,这步是少不了的。
select * from t_emp left join t_dept
on t_emp.eid = t_dept.did WHERE t_emp.eid = #{eid}
关键是,特定的orm框架如何处理映射关系,下面介绍MyBatis几种常见的处理映射的方法。
对于上文中,已经写了如果是字段有不一致的情况,可以使用resultmap的方式来解决。
0、级联方式处理映射关系
EmpMapper.xml中:
<!-- 多对一映射关系,方式一:级联属性赋值-->
<resultMap id="getEmpAndDeptResultMapOne" type="Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
<result property="dept.did" column="did"></result>
<result property="dept.deptName" column="dept_name"></result>
</resultMap>
<!-- Emp getEmpAndDept(@Param("eid") Integer eid);-->
<select id="getEmpAndDept" resultMap="getEmpAndDeptResultMapOne">
select * from t_emp left join t_dept
on t_emp.eid = t_dept.did WHERE t_emp.eid = #{eid}
</select>
notice:
IDEA可能会爆红,但是没有关系。

EmpMapper类中
public interface EmpMapper {
/**
* 查询员工及其所对应的部门信息
*/
Emp getEmpAndDept(@Param("eid") Integer eid);
}
测试类中
/**
* 处理多对一的映射关系
* a> 级联属性赋值
* b> association
* c> 分步查询
*/
@Test
public void testGetEmpAndDept(){
SqlSession sqlSession = SqlSessionUtils.getSqlSession();
EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);
Emp empAndDept = mapper.getEmpAndDept(1);
System.out.println(empAndDept);
}

最后,确实把dept给查出了。
1、使用association处理映射关系
这种处理映射关系的改变就是把需要处理多对一关系的单独使用association标签来定义了。
EmpMapper.xml
<resultMap id="empDeptMap" type="Emp">
<id column="eid" property="eid"></id>
<result column="ename" property="ename"></result>
<result column="age" property="age"></result>
<result column="sex" property="sex"></result>
<association property="dept" javaType="Dept">
<id column="did" property="did"></id>
<result column="dname" property="dname"></result>
</association>
</resultMap>
<!--Emp getEmpAndDeptByEid(@Param("eid") int eid);-->
<select id="getEmpAndDeptByEid" resultMap="empDeptMap">
select emp.*,dept.* from t_emp emp left join t_dept dept on emp.did =
dept.did where emp.eid = #{eid}
</select>
结果依然和上面一样。
一般我们使用association来进行多对一的关系映射,这种比较形象。
2、分步查询解决多对一关系
对于上述的过程中,我们写的sql都是多表联查的SQL,给数据库发送的是一条查询请求。那我们能不能发送两条,然后将结果拼接?
(1) 查询员工信息
EmpMapper类中
public interface EmpMapper {
/**
* 通过分步查询查询员工信息 * @param eid
* @return
*/
Emp getEmpByStep(@Param("eid") int eid);
}
EmpMapper.xml:
<!-- getEmpAndDeptByStepTwo是这条sql语句的全类名-->
<resultMap id="getEmpAndDeptByStepResultMap" type="Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
<!--
select: 设置分步查询的sql的唯一标识(namespace.SQLId或mapper接口的全类名.方法名)
column:分步查询的条件
fetchType: 当开启了全局的延迟记载后,可通过此属性手动控制延迟加载的效果
fetchType:"lazy/eager" lazy表示延迟加载,eager表示立即加载
-->
<association property="dept"
select="com.fckey.mybatis.mapper.DeptMapper.getEmpAndDeptByStepTwo"
column="did"
fetchType="lazy">
</association>
</resultMap>
<select id="getEmpByStep" resultMap="getEmpAndDeptByStepResultMap">
select * from t_emp where eid = #{eid}
</select>
(2) 根据员工所对应的部门id查询部门信息
DeptMapper接口:
public interface DeptMapper {
/**
* 分步查询的第二步:根据员工所对应的did查询部门信息
*/
Dept getEmpDeptByStep(@Param("did") int did);
}
DeptMapper.xml:
<!-- Dept getEmpAndDeptByStepTwo(Integer did);-->
<!-- 分步查询可以实现懒加载-->
<select id="getEmpAndDeptByStepTwo" resultType="Dept">
select * from t_dept where did = #{did}
</select>
直接来进行测试一下,发现
@Test
public void testGetEmpByStep() throws IOException {
SqlSession sqlSession = getSqlSession();
EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);
Emp empByStep = mapper.getEmpByStep(1);
System.out.println(empByStep);
}

延迟加载
我们知道,对于分步查询,要是每次都发送两条查询语句可能就会造成时间上的损耗,但是,分步查询不是没有优点。
分步查询的优点:可以实现延迟加载,但是必须在核心配置文件中设置全局配置信息。
第一种可以实现粗力度的设置方式,在全局配置文件mybatis-config.xml中:
lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载aggressiveLazyLoading:当开启时,任何方法的调用都会加载该对象的所有属性。 否则,每个 属性会按需加载

此时就可以实现按需加载,获取的数据是什么,就只会执行相应的sql。此时可通过association和collection中的fetchType属性设置当前的分步查询是否使用延迟加载,fetchType=“lazy(延迟加 载)|eager(立即加载)”.
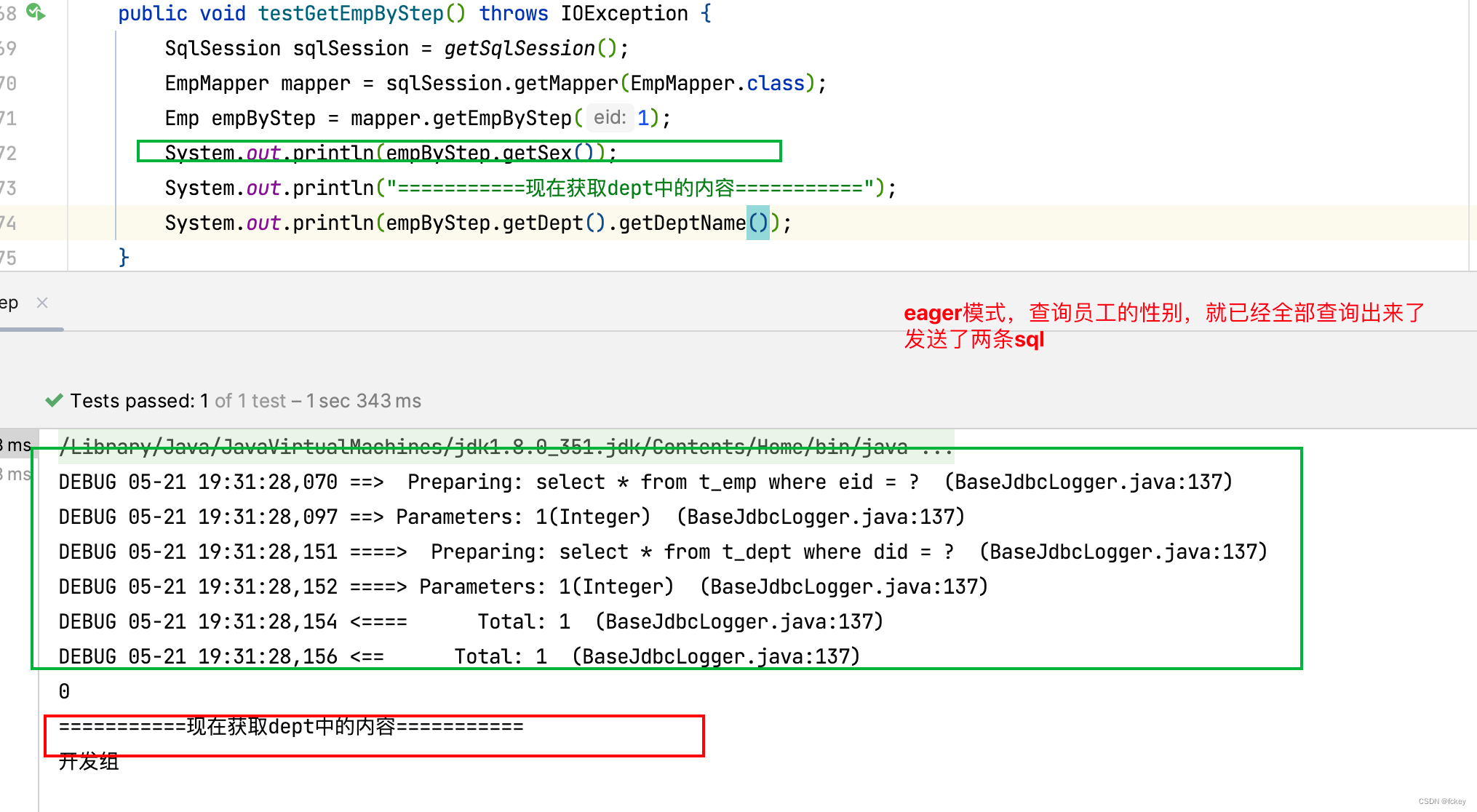
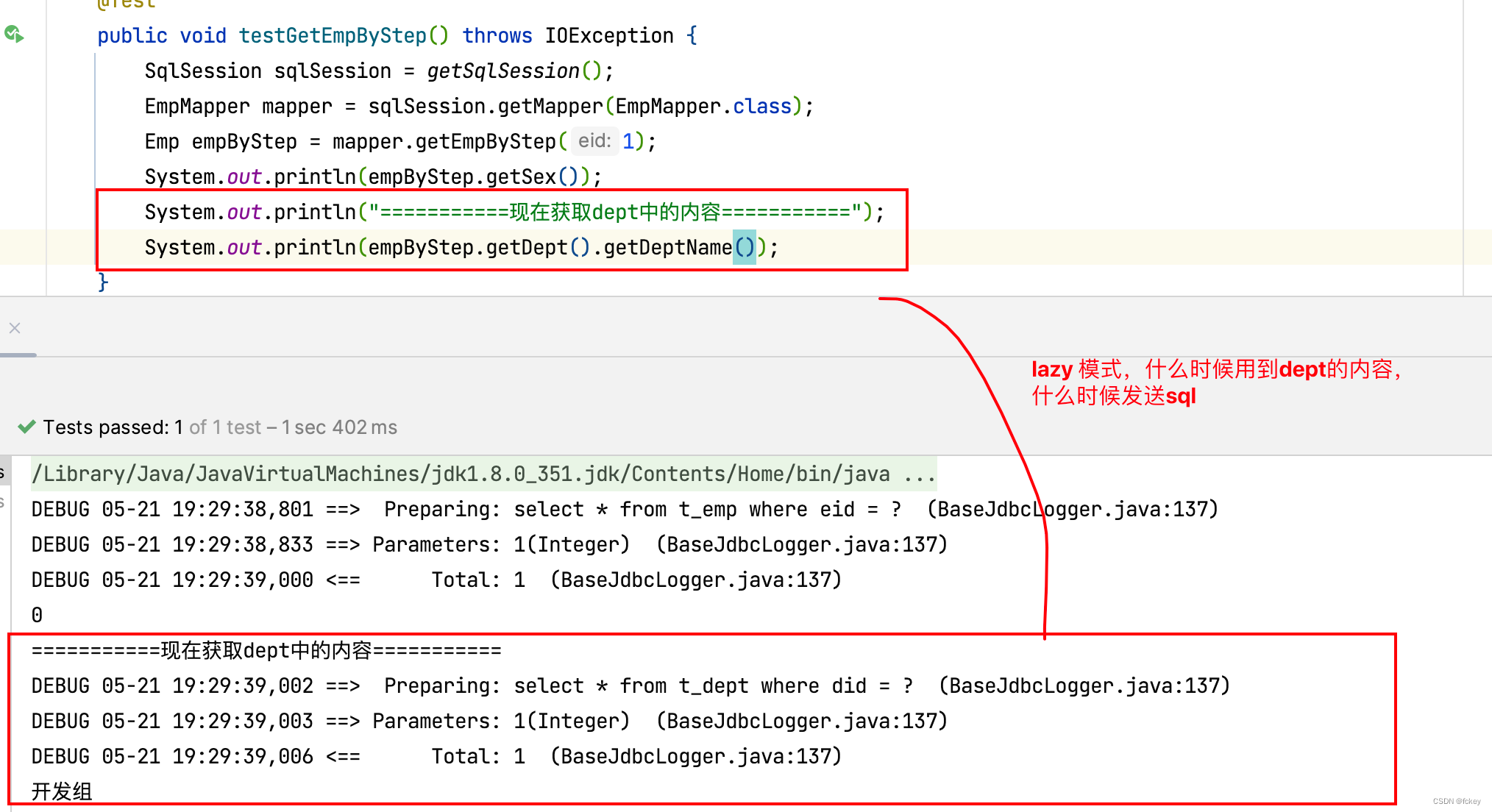
假设,我现在设计一个场景,查询的就是一个员工的性别,这个没有涉及到对部门的查询。如果部门一起查出来了,说明是立即加载。反之,则是延迟加载。
延迟加载打开:

立即加载打开:

通过fetchType参数,可以手动控制延迟加载或立即加载,否则根据全局配置的属性决定是延迟加载还是立即加载。
三、一对多的关系处理
需求:根据部门id查找部门以及部门中的员工信息
需要查询一对多、多对一的关系,需要在“一”的pojo中加入List<多>属性,在“多”的pojo中加入“一”。
也就是说,在Dept类中,要加入private List<Emp> emps;;在Emp类中,要加入private Dept dept;。然后给他们各自添加get、set方法,重写构造器和toString()
0、使用collection来维系一对多的关系
DeptMapper接口:
public interface DeptMapper {
/*
获取部门中所有的员工信息
*/
Dept getDeptAndEmp(@Param("did") Integer did);
}
DeptMapper.xml
<resultMap id="deptAndEmpResultMap" type="Dept">
<id property="did" column="did"></id>
<result property="deptName" column="dept_name"></result>
<!--
collection:处理一对多的映射关系
ofType:表示该属性对应的集合中存储数据的类型
-->
<collection property="emps" ofType="Emp">
<id property="eid" column="eid"></id>
<result property="empName" column="emp_name"></result>
<result property="age" column="age"></result>
<result property="sex" column="sex"></result>
<result property="email" column="email"></result>
</collection>
</resultMap>
<!-- Dept getDeptAndEmp(@Param("did") Integer did);-->
<select id="getDeptAndEmp" resultMap="deptAndEmpResultMap">
select * from t_dept left join t_emp on t_dept.did = t_emp.did where t_dept.did = #{did}
</select>
测试类来进行测试;
@Test
public void testGetDeptAndEmp() throws IOException {
SqlSession sqlSession = getSqlSession();
DeptMapper mapper = sqlSession.getMapper(DeptMapper.class);
Dept dept = mapper.getDeptAndEmp(1);
System.out.println(dept.getDeptName());
dept.getEmps().forEach(System.out::println);
}
最后结果得出;

1、分步查询
在处理一对多的关系中,也有分布查询,在分步查询中也有延迟加载和立即加载两种。
(1)查询部门信息
DeptMapper接口
public interface DeptMapper {
/**
* 分步查询 查询部门及其所有的员工信息
* 第一步 查询部门信息
*/
Dept getDeptAndEmoByStepOne(@Param("did") Integer did);
}
DeptMapper.xml
<!-- 分步查询-->
<resultMap id="deptAndEmoByStepOneMap" type="Dept">
<id property="did" column="did"></id>
<result property="deptName" column="dept_name"></result>
<collection property="emps"
select="com.fckey.mybatis.mapper.EmpMapper.getDeptAndEmpByStepTwo"
column="did"
fetchType="lazy"
>
</collection>
</resultMap>
<!-- Dept getDeptAndEmoByStepOne(@Param("did") Integer did);-->
<select id="getDeptAndEmoByStepOne" resultMap="deptAndEmoByStepOneMap">
select * from t_dept where did = #{did}
</select>
(2)根据部门id查询部门中的所有员工
EmpMapper
public interface EmpMapper {
/**
* 分步查询 查询部门及其所有的员工信息
* 第一步 查询部门信息
* 第二步 根据查询员工信息
*/
List<Emp> getDeptAndEmpByStepTwo(@Param("did") Integer did);
}
EmpMapper.xml
<!-- 分步查询-->
<!-- List<Emp> getDeptAndEmpByStepTwo(@Param("did") Integer did);-->
<select id="getDeptAndEmpByStepTwo" resultType="Emp">
select * from t_emp where did = #{did}
</select>
(3)测试类
@Test
public void testGetDeptAndEmp() throws IOException {
SqlSession sqlSession = getSqlSession();
DeptMapper mapper = sqlSession.getMapper(DeptMapper.class);
Dept dept = mapper.getDeptAndEmp(1);
System.out.println(dept.getDeptName());
System.out.println("====================");
dept.getEmps().forEach(System.out::println);
}
然后,设置的是延迟加载的模式,运行结果如下所示

然后,有人问,有一对多,多对一,那多对多的关系呢?对于多对多的关系需要抽离出第三张表,本质上还是一对多,多对一的变体。