目录
宏定义
数值宏常量
字符串宏常量
用定义充当注释符号宏
用 define 宏定义表达式
宏定义中的空格
宏定义
数值宏常量
在C语言中,宏定义可以用于定义数值宏常量。数值宏常量是一个值,在宏定义中用一个常量名称来表示,该值在后续的代码中可以被多次引用。
数值宏常量主要有以下几个特点:
1. 可以是整数或小数:可以定义整数或小数的数值宏常量,例如:#define PI 3.14。
2. 没有类型:宏定义中的数值宏常量没有类型,因此可以在代码中使用时自动转化为相应的类型。
3. 通常使用大写字母:为了方便识别,通常将数值宏常量的名称使用大写字母来表示,例如:#define MAX_NUM 100。
为何这些字面值建议定义成宏?
数值宏常量的主要优点是能够提高代码的可读性和可维护性。通过将数值宏定义为常量名称,可以避免在后续代码中多次出现相同的数值常量,减少冗余代码,从而使代码更加简洁和易于理解。此外,如果需要更改常量的值,只需要修改宏定义即可,这样可以更加方便和快捷地修改代码。
字符串宏常量
在C语言中,宏定义还可以用于定义字符串宏常量。字符串宏常量是一个字符串,在宏定义中用一个常量名称来表示,该字符串在后续的代码中可以被多次引用。
字符串宏常量主要有以下几个特点:
1. 必须使用双引号:在宏定义中,字符串宏常量必须使用双引号将字符串括起来。
2. 可以包含转义字符:字符串宏常量可以包含转义字符,例如:#define PATH "D:\\胡巴"。
3. 没有类型:宏定义中的字符串宏常量没有类型,因此可以在代码中使用时自动转化为相应的类型。
4. 通常使用大写字母:为了方便识别,通常将字符串宏常量的名称使用大写字母来表示,例如:#define PATH "D:\\胡巴"。
#include<stdio.h>
/*第一个宏,字符串没有带双引号,直接报错*/
#define PATH D:\胡巴
int main()
{
printf("%s\n", PATH);
return 0;
}
#include<stdio.h>
/*第二个宏,字符串带上双引用,有告警,能够编译通过。
不过windows中路径分割符需要\\,输出乱码,改过之后,正常*/
//#define PATH "D:\胡巴" --- 输出-> D:喊?
#define PATH "D:\\胡巴" // 正常
int main()
{
printf("%s\n", PATH);
return 0;
}
#include<stdio.h>
/*第三个宏,不带双引号,进行\续行 直接报错*/
//第三个\是续行符的意思
#define PATH D:\\\
胡巴
int main()
{
printf("%s\n", PATH);
return 0;
}
#include<stdio.h>
/*第四个宏,带双引号,进行\续行 正常输出*/
#define PATH "D:\\\
胡巴"
int main()
{
printf("%s\n", PATH);
return 0;
}结论:宏定义代表字符串的时候,一定要带上双引号,可以用\续行符进行续行。
用定义充当注释符号宏
程序翻译是什么?
C语言程序翻译指的是将C语言编写的源代码(即人类可读的代码)转化为计算机可执行的代码。这个过程叫做编译(Compilation)。
为什么要进行程序翻译?
C语言需要进行程序翻译,是因为计算机只能理解由二进制代码(机器码)组成的指令,而人类编写的C语言程序是文本形式的,计算机不能直接运行。
程序翻译的步骤
1. 预处理(Preprocessing):预处理器(Preprocessor)根据程序中包含的预编译指令,如#include等,将源代码中的宏定义、注释、条件编译等转换为实际的C代码。预处理的输出结果通常是一个扩展名为.i的文件。
2. 编译(Compilation):编译器(Compiler)将扩展名为.i的预处理后的文件编译成汇编语言(Assembly Language)代码,这个汇编代码是计算机可以理解的中间语言。编译的输出结果通常是一个扩展名为.s的汇编语言代码文件。
3. 汇编(Assembly):汇编器(Assembler)将扩展名为.s的汇编语言代码文件转换成计算机可执行的机器码(Machine Code)。汇编的输出结果通常是一个扩展名为.o的目标文件。
4. 链接(Linking):链接器(Linker)将程序中使用到的各个目标文件和库文件(Library)链接成一个完整的可执行文件(Executable File)。器链接的输出结果通常是扩展名为.exe的可执行文件。
最终得到的可执行文件就是计算机可以直接运行的程序。

库文件(Library)的介绍
C语言中的库是一些预编译好的代码文件,可以包含很多常用的函数和变量。它们可以被其他程序或应用程序调用,以便在程序中使用它们的功能而不必重新编写代码。这有效地简化了代码编写过程并提高了程序员的工作效率。
在C语言中,库一般被分为两种类型:静态库和动态库。
静态库是一组已经编译好的目标文件的集合,可以直接链接至程序中。这意味着,在程序运行时,静态库的所有函数和代码都会被打包成一个单独的可执行文件。静态库的优点是调用速度快,运行效率高,并且程序独立性也很高。缺点是占用磁盘空间比较大,而且多个程序使用同一个库会导致程序冗余。
动态库是一种在程序运行时才会被链接的代码文件。通常以.dll或.so文件的形式存在。程序在运行时,只会在需要使用某个函数时才会去链接相关动态库。这样可以有效减小程序的体积,并且多个程序共用同一个库不会导致程序体积冗余。但是,动态库调用速度相对静态库较慢,且程序执行过程中可能存在动态链接错误等风险。
C语言的库通常可以分为以下几类:
1. 标准库:也称为C标准库,在编译C程序时默认会链接这个库,包括stdio.h、stdlib.h、string.h、math.h等等。
2. 第三方库:由独立的开发者或团队编写的库,在程序编辑过程中需要手动链接,例如Boost库。
3. 自定义库:由程序员自己编写的库文件,可以在程序中重复使用,提高代码的可重用性和可维护性。自定义库可以是静态库或动态库。
4. 操作系统库:涵盖了与操作系统通信相关的函数和变量。例如,Windows操作系统提供了Windows API库,Linux操作系统则提供了Glibc库。
总之,使用C语言的库可以大大简化代码编写过程,提高程序员的工作效率,同时也可以提高程序的可重用性和可维护性。
为什么计算机在编译的过程中,需要将高级语言转为汇编语言再转为二进制代码,为什么不能直接将高级语言转为二级制代码,省略去中间的转化汇编代码的过程呢?
高级语言是人类可读写的,可以方便地表达复杂的算法和逻辑,但是计算机无法直接理解高级语言,需要将其转换为计算机可以执行的二进制代码。在将高级语言转换为二进制代码的过程中,计算机会经过编译器的多个阶段,其中包括语法分析、语义分析、代码优化等步骤,这些步骤都需要将高级语言转换为汇编语言再转换为二进制代码。
之所以不能直接将高级语言转换为二进制代码,是因为高级语言和计算机的指令集是不同的,要将高级语言转换为计算机指令需要经过复杂的转换,其中涉及到很多细节问题。而汇编语言作为一种比较接近底层的语言,可以更容易地和计算机指令对应起来,因此在编译的过程中使用汇编语言作为中间语言可以大大简化编译器的实现难度和编译速度。
预处理过程中是先处理注释还是先处理宏替换呢?
#include <stdio.h>
//当前,我们用BSC充当C++风格的注释
#define BSC //
int main()
{
BSC printf("hello world\n");
return 0;
}倘若,先执行宏替换,那么先得到的代码应该是:
int main()
{
//将BSC替换成为‘//’
// printf("hello world\n");
return 0;
}
//再执行去注释,那么代码最终的样子,应该是
int main()
{
return 0; //printf被注释掉
}
//并且,最终运行的时候,应该没有输出但是当我们查看输出结果时,发现结果并非如此。
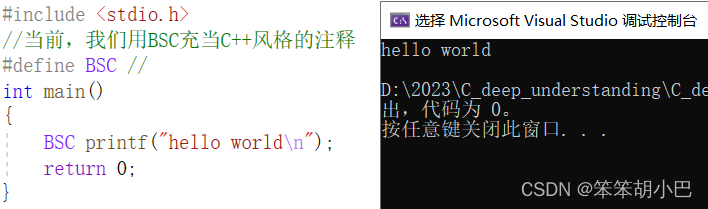
程序输出结果了,和我们预期的并不一样 ,所以程序实际上,是先执行去注释,再进行宏替换。
//先去掉宏后面的//,因为是注释
#define BSC // //最终宏变成了#define BSC 空
int main()
{
BSC printf("hello world\n");
//因为BSC是空,所以在进行替换之后,就是printf("hello world\n");
return 0;
}
结论:预处理期间:先执行去注释,在进行宏替换。
#include <stdio.h>
#define BSC //
#define BMC /*
#define EMC */
int main()
{
BSC printf("hello today\n");
BMC printf("hello tomorrow\n"); EMC
return 0;
}那我们的上面的程序的输出语句有没有被注释,按照上面的结论,并没有。

用 define 宏定义表达式
#include <stdio.h>
#define SUM(x) (x)+(x) //定义宏求两个数的和
int main()
{
printf("%d\n", SUM(10));
printf("SUM(20)\n");
return 0;
}
第七行 printf("%d\n", SUM(10)); 是一个printf函数,用于将SUM(10)的值打印到控制台上。在程序中,SUM(10)的值为(10)+(10) = 20,因此该语句会输出数字20。
第八行 printf("SUM(20)\n"); 是另一个printf函数,用于将字符串SUM(20)打印到控制台上。在程序中,该语句并不会调用SUM宏,因此输出的是一个字符串而不是数字。
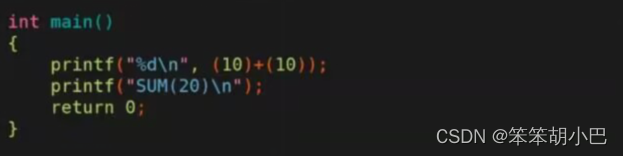
从上面的预编译结果看,我们发现只有第个输出的代码进行替换了。说明宏不是无脑文本替换的。
#include <stdio.h>
//该宏最大的特征是,替换的不是单个变量/符号/表达式,而是多行代码
#define INIT_VALUE(a,b)\ //对变量a、b进制初始化
a = 0;\
b = 0;
int main()
{
int flag = 0;
scanf("%d", &flag);
int a = 100;
int b = 200;
printf("before: %d, %d\n", a, b);
if (flag)
INIT_VALUE(a, b);
else //error C2181: 没有匹配 if 的非法 else
printf("error!\n");
printf("after: %d, %d\n", a, b);
return 0;
}为什么报错了呢?从下面的预编译结果看我们就清楚原因了。
int main()
{
int flag = 0;
scanf("%d", &flag);
int a = 100;
int b = 200;
printf("before: %d, %d\n", a, b);
if (flag)
a = 0; b = 0;; //if倘若没有带{},那么if后面只能跟一条语句
else //else匹配if时,直接报错了
printf("error!\n");
printf("after: %d, %d\n", a, b);
return 0;
}怎么修正呢?
//方案一 - 给if语句后的语句加上花括号
#include <stdio.h>
#define INIT_VALUE(a,b)\
a = 0;\
b = 0;
int main()
{
int flag = 0;
scanf("%d", &flag);
int a = 100;
int b = 200;
printf("before: %d, %d\n", a, b);
if (flag) { //直接带上花括号就好了
INIT_VALUE(a, b);
}
else {
printf("error!\n");
}
printf("after: %d, %d\n", a, b);
return 0;
}//失败方案二 - 在宏这里直接加上花括号
#include <stdio.h>
#define INIT_VALUE(a,b) {a = 0; b = 0;} //在宏这里直接加上花括号,这样行不行呢?
int main()
{
int flag = 0;
scanf("%d", &flag);
int a = 100;
int b = 200;
printf("before: %d, %d\n", a, b);
if (flag)
INIT_VALUE(a, b);
//这里会被宏替换为{a = 0; b = 0;}; - 后面多了一个分号;
else
printf("error!\n");
printf("after: %d, %d\n", a, b);
return 0;
}//方案二 - 使用do-while-zero结构
#include <stdio.h>
#define INIT_VALUE(a,b)\
do{\
a = 0;\
b = 0;\
}while(0)
//使用do-while-zero结构
int main()
{
int flag = 0;
scanf("%d", &flag);
int a = 100;
int b = 200;
printf("before: %d, %d\n", a, b);
if (flag) {
INIT_VALUE(a, b);
//这里会被宏替换为 do{a = 0; b = 0;}while(0); --- ;正好匹配do-while语句
}
else {
printf("error!\n");
}
printf("after: %d, %d\n", a, b);
return 0;
}宏定义中的空格
#include <stdio.h>
//#define INC (a) ((a)++) //error
#define INC(a) ((a)++) //定义不能带空格
int main()
{
int i = 0;
INC (i); //使用可以带空格,但是不推荐
printf("%d\n", i);
return 0;
}#undef
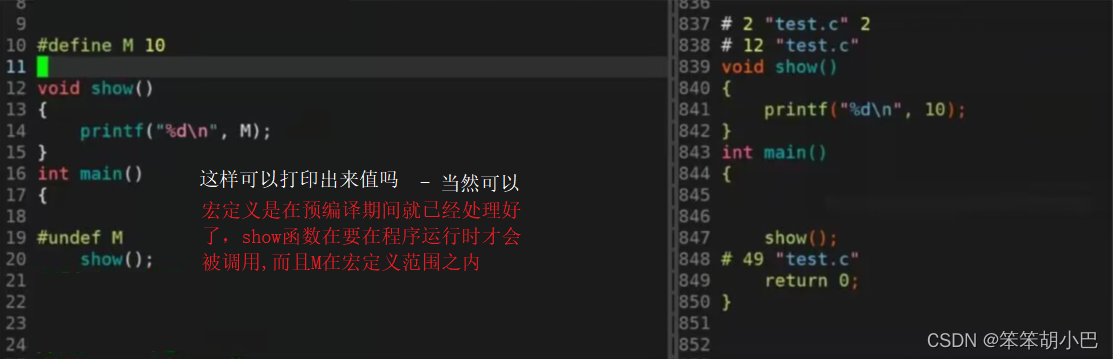
1. 宏只能在main上面定义吗?
不是的。宏定义可以出现在任何位置,包括main函数之后。宏可以在当前源文件内的任何位置使用,也可以在包含该宏定义的头文件所在的其他源文件中使用。为了方便复用和避免冲突,建议将宏的定义放在头文件中。如果没有多文件,建议放在main上面定义。
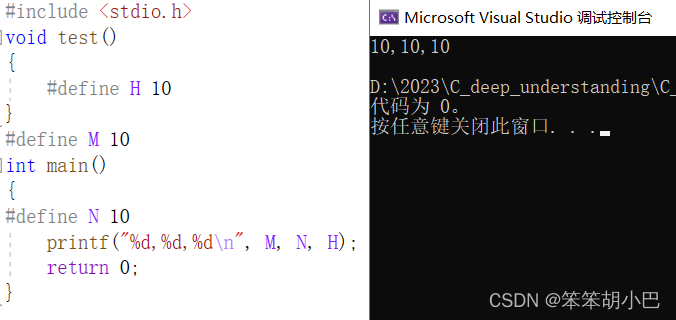
2. 在一个源文件内,宏的有效范围是什么?
在一个源文件中定义的宏的有效范围是从定义宏的位置开始,到文件结束或者该宏被#undef指令取消定义之前。在这个范围内,宏可以在源文件中的任何函数或语句中使用。同时,头文件中定义的宏可以在包含该头文件的任何源文件中使用,但是需要通过#include指令将头文件包含进来。宏的作用域仅限于定义宏的源文件或者包含该宏定义的头文件内部,在其他源文件中无法直接使用宏。因此,为了避免宏命名的冲突,建议在头文件中使用条件编译来防止多次包含同一个头文件和重复定义同一个宏。
#include <stdio.h>
#define M 10
int main()
{
printf("%d, %d\n", M, N);//error:未定义的标识符"N"
#define N 100
printf("%d, %d\n", M, N);
return 0;
}结论:宏的有效范围,是从定义处往下有效,之前无效
在C语言中,#undef是一个预处理指令,用于取消一个之前定义的宏的定义,即将该宏从预处理符号表中删除。语法格式为:
```
#undef macro
```其中,macro是要取消定义的宏的名称。
通过#undef指令可以在预处理阶段取消一个之前定义的宏的定义。取消定义后,宏就不能再被使用,并且如果在源文件中使用该宏,会被当做普通的符号处理。如果想要重新定义该宏,需要重新使用#define指令来定义。
取消宏的定义可以用于避免宏定义的名字冲突,或者在某些情况下需要动态修改宏定义的情况下使用。但是,在实际编程中一定要谨慎使用#undef指令,因为这会导致代码的可读性和可维护性降低。
//undef本质作用
#include <stdio.h>
#define M 10
int main()
{
#define N 100
printf("%d, %d\n", M, N);
#undef M //取消M
#undef N //取消N
//从该位置开始,M,N,不在被识别
printf("%d, %d\n", M, N);
//error:未定义的标识符"M"、"N"
return 0;
}结论:undef是取消宏的意思,可以用来限定宏的有效范围。
小练习一下
#include <stdio.h>
int main()
{
#define X 3
#define Y X*2
#undef X
#define X 2
int z = Y;
printf("%d\n", z);
return 0;
}我们来看一下预编译的结果

首先,在第一行代码中,使用`#define X 3` 定义了X为常量3。
接着,在第二行代码中,使用`#define Y X*2` 定义了Y为X的两倍。此时,由于X被定义为常量3,因此Y的值为6。
然后,在第三行代码中,使用`#undef X` 取消了X的定义。这意味着在之后的代码中,X将不再表示常量3。
在第四行代码中,使用`#define X 2` 重新定义X为常量2。这样,之后如果使用X时,它将被替换为常量2。
接下来,在第五行代码中,使用`int z = Y` 将Y的值赋给整型变量z。但是,由于在宏定义中使用了X,而此时X已被重新定义为2,因此编译器会将宏定义`Y X*2` 中的X替换为2,也就是将Y的值替换为4。
最终,在第六行代码中,使用`printf("%d\n", z);` 将变量z的值输出到控制台。由于z的值为4,因此输出结果为4。
总体来说,这段代码的作用是测试宏定义中使用常量的替换规则,以及取消和重新定义宏定义的方法。
再来看这个代码