Linux:文本三剑客之awk
- 一、awk编辑器
- 1.1 awk概述
- 1.2 awk工作原理
- 1.3 awk与sed的区别
- 二、awk的应用
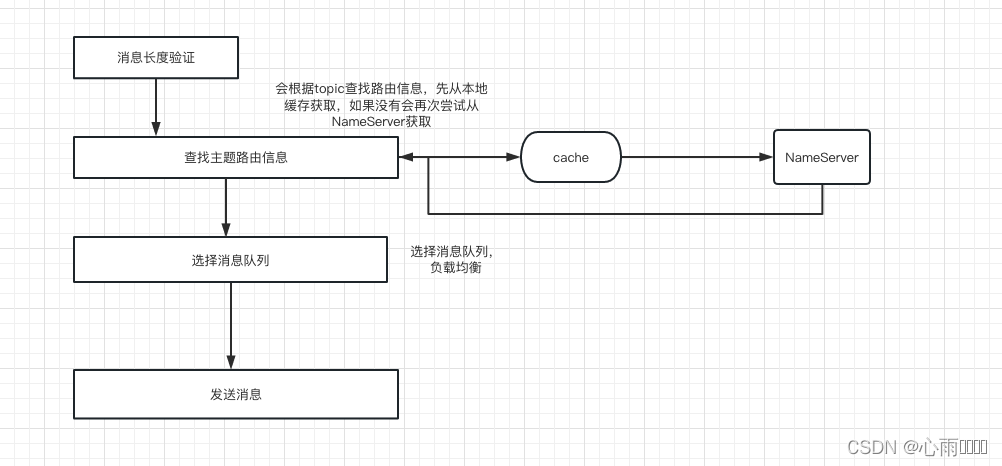
- 2.1 命令格式
- 2.2 awk常见的内建变量(可直接用)
- 三、awk使用
- 3.1 按行输出文本
- 3.2 按字段输出文本
- 3.3 通过管道、双引号调用 Shell 命令
一、awk编辑器
1.1 awk概述
- awk:是一种处理文本文件的语言,是一个强大的文本分析工具。
1.2 awk工作原理
- awk:逐行读取文本,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
1.3 awk与sed的区别
- 1、sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理。
- 2、awk信息的读入也是逐行读取的,执行结果可以通过print的功能将字段数据打印显示
- 3、在使用awk命令的过程中,可以使用逻辑操作符“&&”表示“与”、“||”表示“或”,“!”表示“非”
- 4、awk还可以进行简单的数学运算,如"+、、-、*、/、%、^"分别表示加、减、乘、除、取余和乘方
二、awk的应用
2.1 命令格式
awk 选项 ‘模式或条件 {操作}’ 文件1 文件2...
awk -f 脚本文件 文件1 文件2...
2.2 awk常见的内建变量(可直接用)
| 常见内建变量 | 说明 |
|---|---|
FS | 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同 |
NF | 当前处理的行的字段个数,$NF代表当前所在行的最后一个字段 |
NR | 当前处理的行的行号(序数) |
$0 | 当前处理的行的整行内容 |
$n | 当前处理行的第n个字段(第n列) |
FILENAME | 被处理的文件名 |
RS | 行分隔符。awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’ |
三、awk使用
3.1 按行输出文本
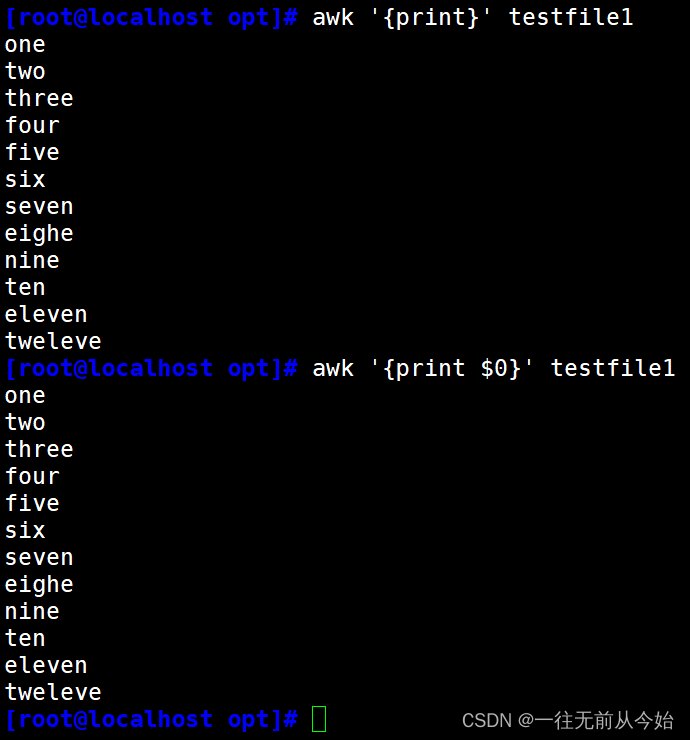
awk '{print}' testfile2 #输出所有内容
awk '{print $0}' testfile2 #输出所有内容
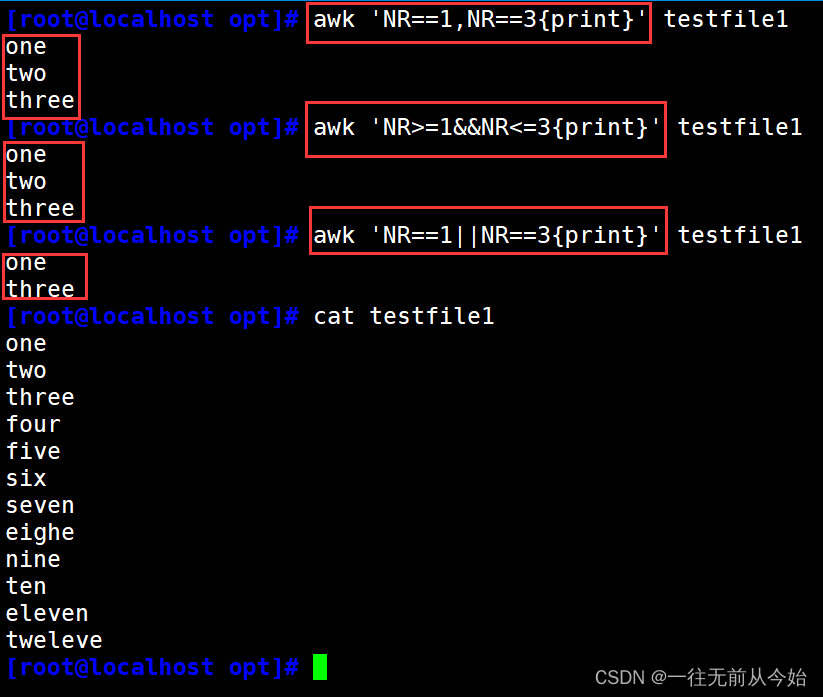
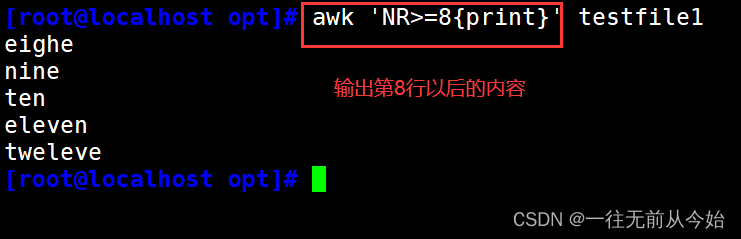
awk 'NR==1,NR==3{print}' testfile2 #输出第 1~3 行内容
awk '(NR>=1)&&(NR<=3){print}' testfile2 #输出第 1~3 行内容
awk 'NR==1||NR==3{print}' testfile2 #输出第1行、第3行内容
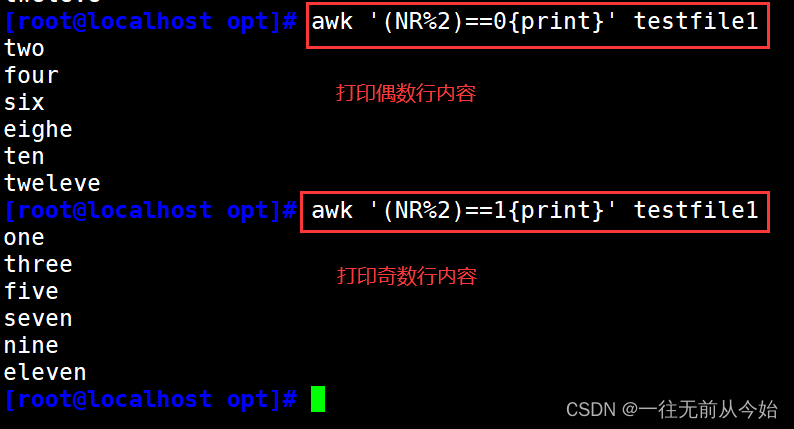
awk '(NR%2)==1{print}' testfile2 #输出所有奇数行的内容
awk '(NR%2)==0{print}' testfile2 #输出所有偶数行的内容
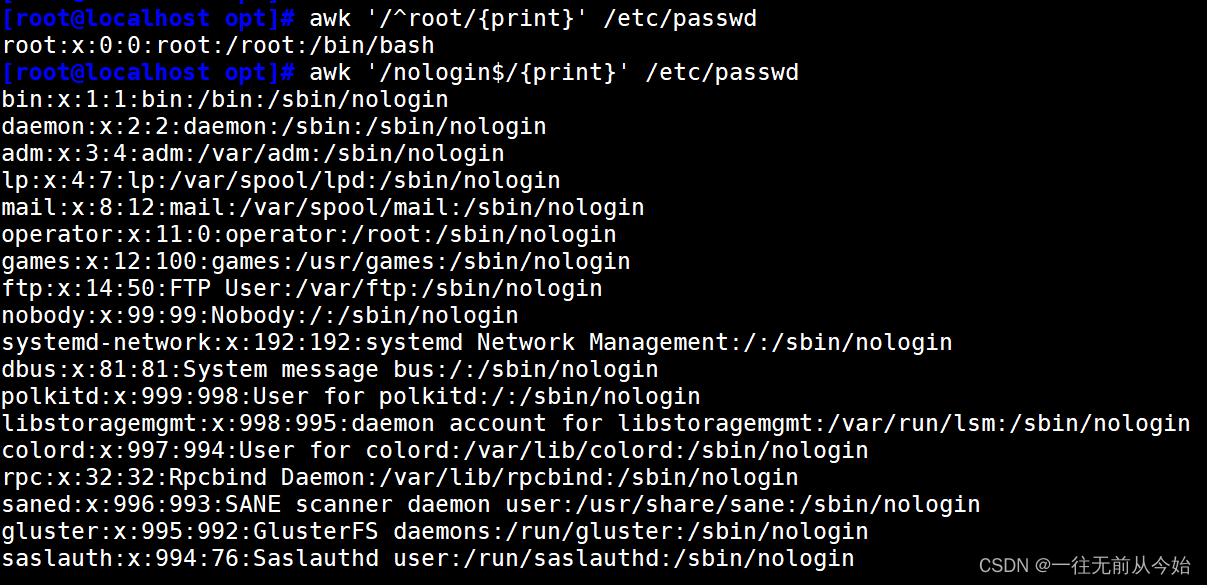
awk '/^root/{print}' /etc/passwd #输出以 root 开头的行
awk '/nologin$/{print}' /etc/passwd #输出以 nologin 结尾的行
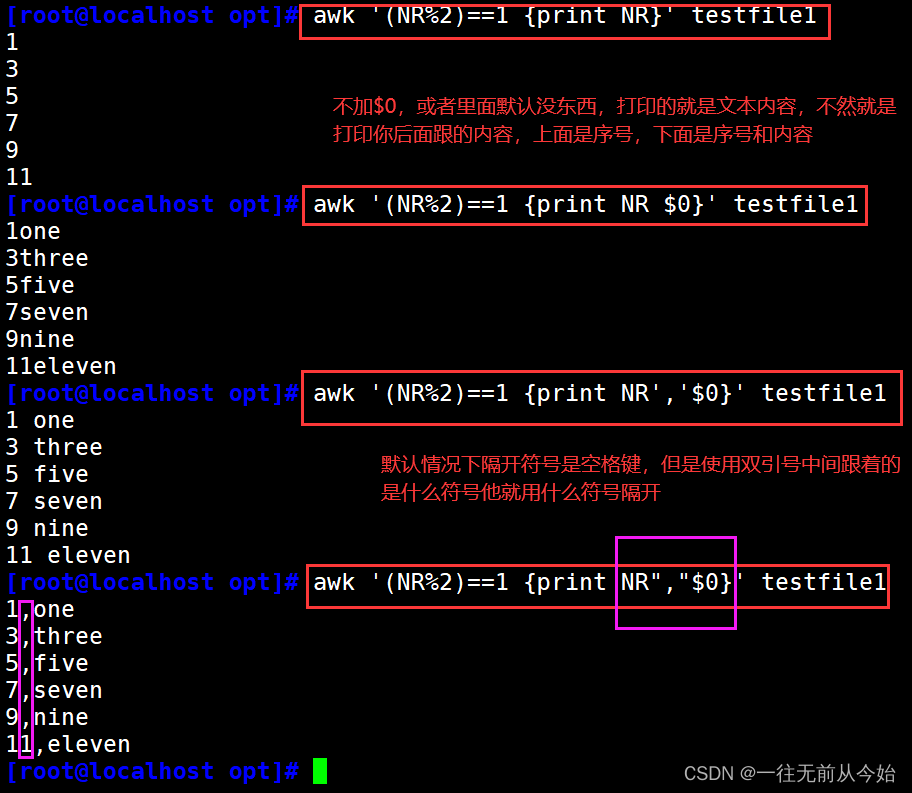
awk '(NR%2)==1 {print NR}' testfile1
awk '(NR%2)==1 {print NR $0}' testfile1
awk '(NR%2)==1 {print NR','$0}' testfile1
awk '(NR%2)==1 {print NR","$0}' testfile1 #只有用双引号才能指定间隔符号,否则默认使用空格符号,上面的单引号加不加没区别
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END {print x}' /etc/passwd #统计以/bin/bash 结尾的行数,等同于 grep -c "/bin/bash$" /etc/passwd
BEGIN模式表示:在处理指定的文本之前,需要先执行BEGIN模式中指定的动作;awk再处理指定的文本,之后再执行END模式中指定的动作,END{}语句块中,往往会放入打印结果等语句

3.2 按字段输出文本
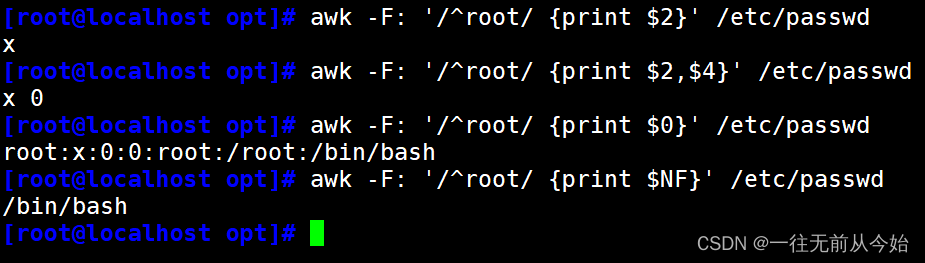
awk -F: '/^root/ {print $2}' /etc/passwd #输出root开头的第二个字段
awk -F: '/^root/ {print $2,$4}' /etc/passwd #输出root开头的第二、四字段
awk -F: '/^root/ {print $0}' /etc/passwd #输出root开头的行
awk -F: '/^root/ {print $NF}' /etc/passwd #输出root开头的最后一个字段
awk -F ":" '!($3<200){print}' /etc/passwd #输出第3个字段的值不小于200的行
awk 'BEGIN {FS=":"};{if($3>=1000){print}}' /etc/passwd #以冒号间隔,打印第三个字段的值大于等于1000的行
awk -F ":" '{max=($3>=$4)?$3:$4;{print max}}' /etc/passwd #($3>$4)?$3:$4;三元运算符,如果第3个字段的值大于等于第4个字段的值,则把第3个字段的值赋给max,否则第4个字段的值赋给max,然后打印出来
awk -F ":" '{print NR,$0}' /etc/passwd #输出每个行号,最后统计总行数
awk -F ":" '$7~"/bash"{print $1}' /etc/passwd #输出以冒号分隔且第7个字段中包含/bash的行的第1个字段
awk -F ":" '($1~"root")&&(NF==7){print $1,$2}' /etc/passwd #输出第1个字段中包含root且有7个字段的行的第1、2个字段
awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd #输出第7个字段既不为/bin/bash,也不为/sbin/nologin的所有行
3.3 通过管道、双引号调用 Shell 命令
echo $PATH | awk 'BEGIN{RS=":"};END{print NR}' #统计以冒号分隔的文本段落数,打印行号
awk -F: '/bash$/{print | "wc -l"}' /etc/passwd #调用 wc -l 命令统计使用 bash 的用户个数,等同于 grep -c "bash$" /etc/passwd
free -m | awk '/Mem:/ {print int($3/($3+$4)*100)"%"}' #查看当前内存使用百分比
top -b -n 1 | grep Cpu | awk -F ',' '{print $4}' | awk '{print $1}' #查看当前CPU空闲率,(-b -n 1 表示只需要1次的输出结果)
date -d "$(awk -F "." '{print $1}' /proc/uptime) second ago" +"%F %H:%M:%S" #显示上次系统重启时间,等同于uptime;second ago为显示多少秒前的时间,+"%F %H:%M:%S"等同于+"%Y-%m-%d %H:%M:%S"的时间格式。/proc/uptime 第一列输出的是:系统启动到现在的时间(以秒为单位);第二列输出的是:系统空闲的时间(以秒为单位)
date -d "$(date -d"1 month" +"%Y%m01") -3 day" +"%Y%m%d" #当月倒数第三天
date +"%Y%m01" #当月第一天
awk 'BEGIN {n=0 ; while ("w" | getline) n++ ; {print n-2}}' #调用w命令,并用来统计在线用户数
awk 'BEGIN {"hostname" | getline ; {print $0}}' #调用 hostname,并输出当前的主机名
seq 10 | awk '{getline; print $0}' #获取偶数行
seq 10 | awk '{print $0; getline}' #获取基数行

当getline左右无重定向符“<”或“|”时,awk首先读取到了第一行,就是1,然后getline,就到了1下面的第二行,就是2,因为getline之后,awk会改变对应的NF,NR,FNR和$0等内部变量,所以此时的$0的值就不再是1,而是2了,然后将它打印出来。 当getline左右有重定向符“<”或“|”时,getline则作用于定向输入文件,由于该文件是刚打开,并没有被awk读入一行,只是getline读入,那么getline返回的是该文件的第一行,而不是隔行。 FNR:awk当前读取的记录数,其变量值小于等于NR(比如当读取第二个文件时,FNR是从0开始重新计数,而NR不会)。 NR==FNR:用于在读取两个或两个以上的文件时,判断是不是在读取第一个文件
awk -F: '$1 ~ /root/ && $NF ~ /\/bin\/bash/ {print}' /etc/passwd #输出/etc/passwd/文件中首字段包含 root 且最后一个字段包含/bin/bash/的行,取反则在“~”加上“!”