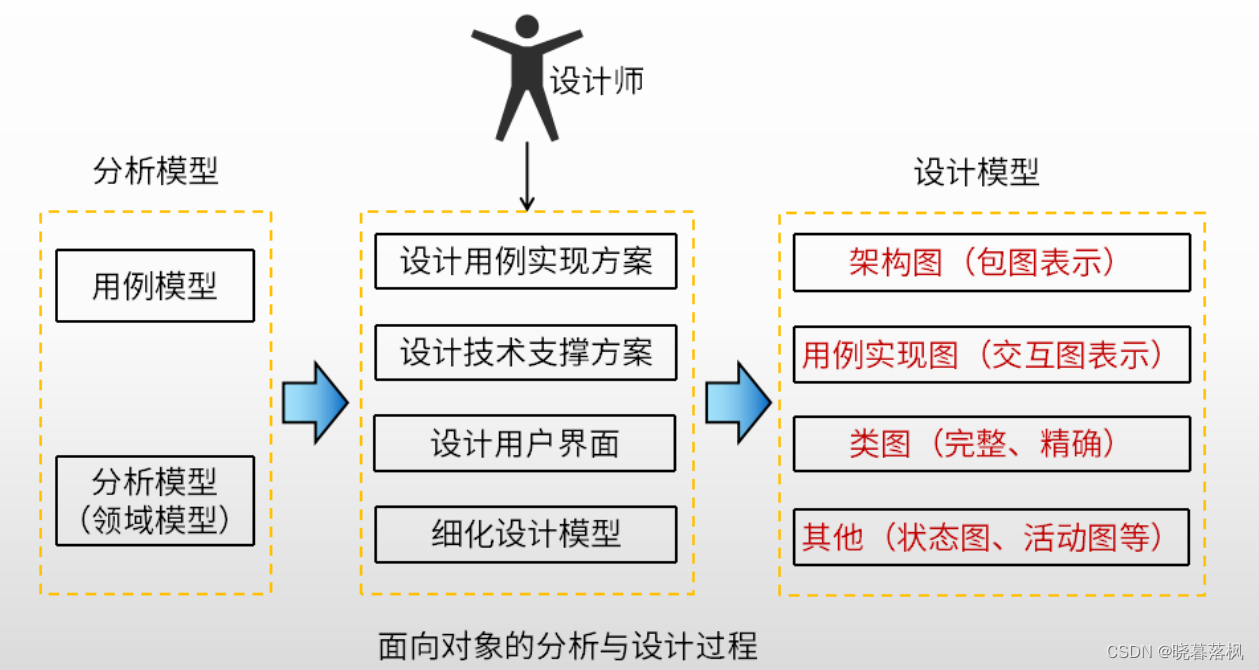
背景
有一批信号数据要送到网络里训练,训练之前为了统一量纲,首先根据方差和均值做了一次标准化,然后求了一次能量(20*log10(x)),也就是说送进网络里的其实是一个能量谱,但是训练过程中经常蹦出来一些莫名其妙的数值,理论上我的数据标准化以后都应该是在-10-10之间的,但有时候会蹦出几百甚至e+20次方的数据,导致网络学习非常坎坷,例如:
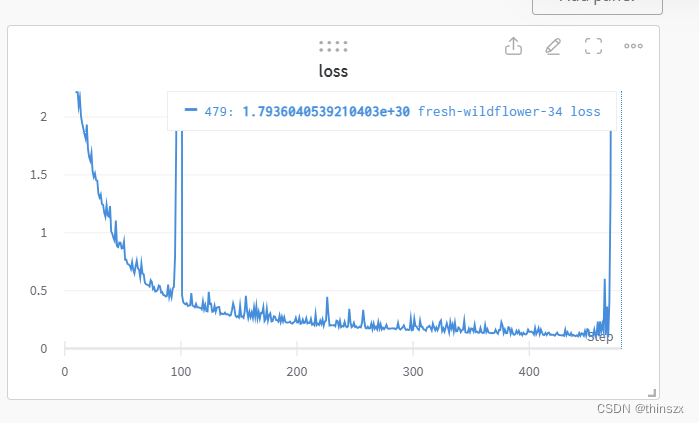
但是当我实际加载/记录数据的时候,发现这个问题非常的随机,有时候分明都是同一个数据,第一次加载正常,第二次加载就不正常了,就是很想问问dataloader,你有事吗?后来发现原来是自己的问题😅
问题出现的原因
我的数据处理流程(pytorch的__getitem()__大概是对元数据做了这么一些操作:
x = ...
x = np.abs(x)
x = np.mean(x, axis=-2)
x = np.squeeze(x)
x = np.log10(x, where=(x!=0)) # where 参数是为了防止对0进行log操作,但还是没跳过这里的大坑...
x = (x - mean_x) / var_x # 这个是之前遍历数据集算出来的定值,假设数据同分布,别管这个
上面说的大坑是啥呢…主要有两个:
- numpy的浮点数比较标准和!=之间的不同
- numpy.log结果的类型转换
学计算机的应该都知道,浮点数之间应该是不能直接进行比较的,但是写python时间太长了,已经被各种库惯坏了,居然把这个给忘了,直接用了x!=0 进行比较,好在python平时对浮点数支持比较好,没遇到过什么问题,但是这个地方因为要算log,和0非常接近的浮点数都会导致inf或是-inf,或是其他非常诡异的数字(和0挨得还不够近),我就是遇到了这个问题,直接采用!=超出了python本身的浮点数比较范围,因此这些很接近0的数字被送到了np.log10做运算
解决方法
1. 采用numpy提供的比较方式和log10提供的参数
numpy的log10其实有三个参数,一个是x,还有两个分别是out和where,懒得翻译了,直接看https://numpy.org/doc/stable/reference/generated/numpy.log10.html:
-
out ndarray, None, or tuple of ndarray and None, optional
A location into which the result is stored. If provided, it must have a shape that the inputs broadcast to. If not provided or None, a freshly-allocated array is returned. A tuple (possible only as a keyword argument) must have length equal to the number of outputs. -
where array_like, optional
This condition is broadcast over the input. At locations where the condition is True, the out array will be set to the ufunc result. Elsewhere, the out array will retain its original value. Note that if an uninitialized out array is created via the default out=None, locations within it where the condition is False will remain uninitialized.
这里只说了out参数会用来进行广播,但实际测试发现这个广播机制会导致运算错误…另外在where的部分最好使用numpy提供的isclose,虽然测试发现isclose不能完全规避问题,修改过后的代码应该长这样:
x = ...
x = np.abs(x)
x = np.mean(x, axis=-2)
x = np.squeeze(x)
x = np.log10(x, out=np.zeros_like(x), where=(np.isclose(x, 0.0)==False) ###############
x = (x - mean_x) / var_x
相关信息见https://stackoverflow.com/a/52209380
2. 不要每次都在原数据上做运算
其实这个问题产生的根本原因还是我把运算过程写在了pytorch的dataset加载过程中,每次__get_item()__ 做运算的时候会有许多不确定性,包括但不限于随机种子的设置,磁盘在运行什么,天气,湿度,电脑心情好不好,今天本人脸黑不黑etc. 也就导致了浮点数精度的随机变化,上面提到的方式可以非常大概率减小这种极小值做浮点数比较的不确定性,但是我感觉可能还是有那个亿万分之一的概率会碰上莫名其面的bug…因此如果送入网络的数据基本不怎么变的情况下,我建议还是在整个数据上做完各种log或比较等运算后,直接把结果保存下来,以后都用算好的结果…
credit
https://stackoverflow.com/a/52209380