🐱作者:一只大喵咪1201
🐱专栏:《C++学习》
🔥格言:你只管努力,剩下的交给时间!

lambda表达式 | 可变参数模板 | 包装器
- 🏀lambda表达式
- 🥎lambda表达式语法
- 🥎函数对象与lambda表达式
- 🏀可变参数模板
- 🥎展开参数包
- 🥎STL中emplace相关接口
- 🏀包装器
- 🥎function
- 🥎bind
- 🏀总结
🏀lambda表达式

用一个类来描述水果,包括水果的名字,价钱,水果的评分。

将该类实例化出来,进行排序,分别按照价格和评分升序排序。
- 使用sort()进行排序时,传入比较方法。

使用两个仿函数分别实现价格和评价升序排序的比较逻辑。

运行结果如上图所示,符合我们预期。
- 如果此时还想根据其他数据排序呢?比如名称,重量等等。
每多一种排序方式就需要写一个仿函数,而且该仿函数只有这里会使用一次,之后就不再使用了。
- 当排序方式多了以后,而且仿函数命名不是很规范,比如是Compare1,conpare2……
此时程序的可读性就会降低,需要反复确认当前使用的Comare是根据什么比较的,而且很冗余。
C++11中提供了lambda表达式。
见lambda表达式:
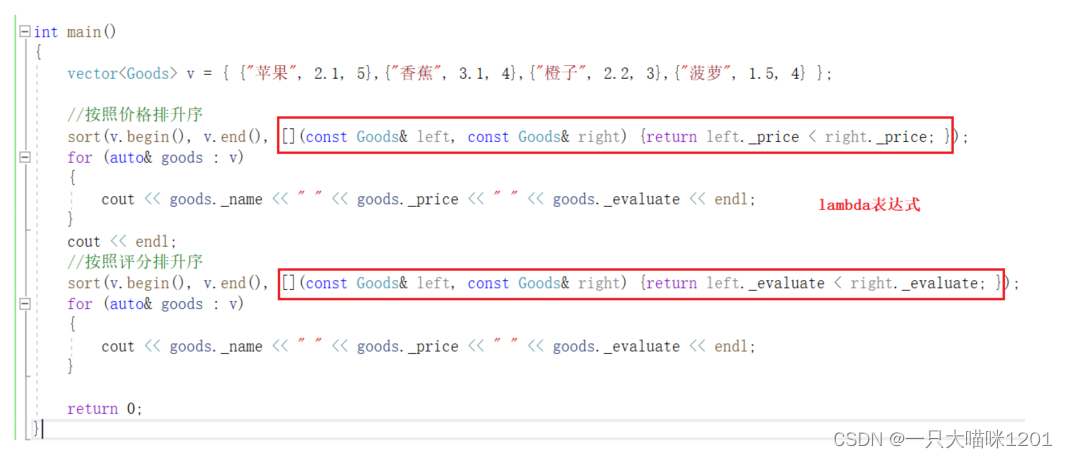
上图红色框中所示就是lambda表达式。
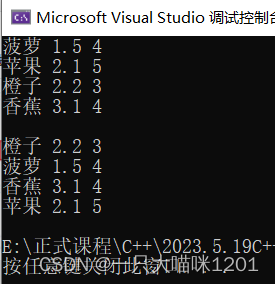
同样可以实现使用仿函数的比较结果。
- lambda表达式就像是是一个匿名仿函数对象,只在当前位置使用,使用完毕后销毁。
- 而且增加了代码的可读性,可以直接看到sort的比较逻辑。
🥎lambda表达式语法
lambda表达式书写格式:
[捕捉列表](参数列表)mutable->(返回值类型){函数体}
- [捕捉列表]
捕捉列表是编译器判断lambda表达式的依据,所以必须写[],[]内可以有参数,后面详细讲解。
- (参数列表)
参数列表和普通函数的参数列表一样,如果不需要参数传递,可以连同()一起省略。
- mutable
默认情况下,lambda表达式的形参都是const类型,形参不可以被修改,使用mutable可以取消形参的常量属性。使用mutable时,参数列表不可以省略(即使参数为空)。一般情况下mutable都是省略的。
- ->返回值类型
->和返回值类型是一体的,如->int表示lambda的返回值是int类型。一般情况下省略->返回值类型,因为编译器可以根据函数体中的return推导出返回值类型。为了提高程序的可读性可以写上。
- {函数体}
和普通函数一样,{}里的是lambda的具体实现逻辑。{函数体}里的内容可以写在一行:
{表达式1;表达式2;//.......}
也可以写成多行:
{
表达式1;
表达式2;
//.....
}
注意:
- 在lambda函数定义中,参数列表和返回值类型都是可选部分,可写可不写。
- 而捕捉列表和函数体必须写,但是内容可以为空。
lambda表达式的最简形式为:
[]{}
该lambda不能做任何事情。
捕获列表说明:
捕捉列表描述了上下文中那些数据可以被lambda使用,以及使用的方式传值还是传引用:
- [var]:表示值传递方式捕捉变量var。
- [=]:表示值传递方式捕获所有父作用域中的变量(包括this)。
- [&var]:表示引用传递捕捉变量var。
- [&]:表示引用传递捕捉所有父作用域中的变量(包括this)。
- [this]:表示值传递方式捕捉当前的this指针。
说明:
- 父作用域指包含lambda函数的语句块,而且只会捕捉lambda函数前面的父作用域中的变量。
- &var不能表示取地址,这里是捕捉,并不是传参,捕捉中就不存在取地址这一语法。
- 语法上捕捉列表可由多个捕捉项组成,并以逗号分割,比如:
- [=, &a, &b]:以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量
- [&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
- 捕捉列表不允许变量重复传递,否则就会导致编译错误,比如:
- [=, a]:=已经以值传递方式捕捉了所有变量,捕捉a重复就会报错。
- 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都 会导致编译报错。

将lambda表达式对象赋值给func1,这里暂时使用auto推演类型。
- 省略了参数列表和返回值类型,函数体中使用的是父域中的变量a和b。
- 调用lambda时不用传参。
可以看到,lambda执行的逻辑是a+b。

- 省略返回值类型,且函数体中没有返回值
- 函数体中使用的是父域中b的引用。
可以看到,变量b在lambda中被改变了。

- 完整的lambda表达式,省略了mutable。
- 传值捕捉父域中的所有值,其中变量b是传引用捕捉。
- 写明返回值类型是int。
可以看到,lambda表达式参数传10以后,函数体进行了运算。
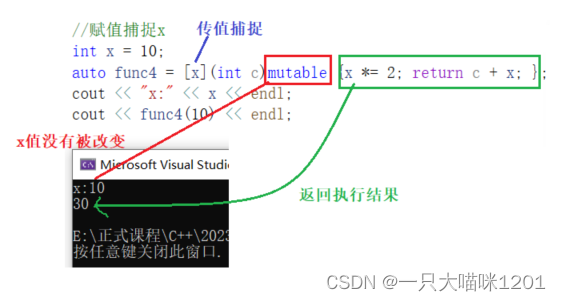
- 传值捕捉x,使用了mutable,否则在函数体中的捕捉到的x不能被改变。
- 父域中的x没有被改变,传值捕捉相当于是给形参传值,是一种拷贝,但是默认情况下拷贝的值是const类型,所以需要mutable来改变属性。
可以看到,最终返回的值是函数体中的运算结果。
从上面的例子中也可以看出,lambda表达式本质上可以理解为匿名函数对象,它是一个可调用对象。
🥎函数对象与lambda表达式
函数对象,又称为仿函数,即可以像函数一样使用的对象,就是在类中重载了operator()运算符的类对象。
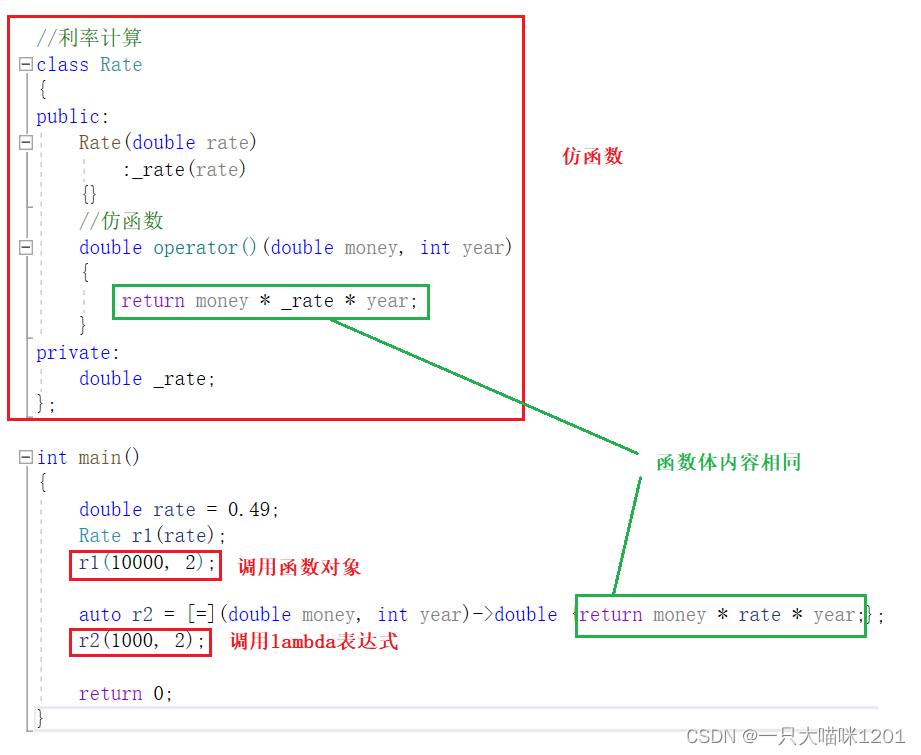
使用函数对象和lambda两种方式进行利率计算,执行的函数体内容相同。
- 从使用方式上来看,函数对象和lambda表达式完全一样,如上图中r1和r2所示。
- rate是函数对象的成员变量,通过构造函数初始化,lambda通过捕获列表来捕获该变量。
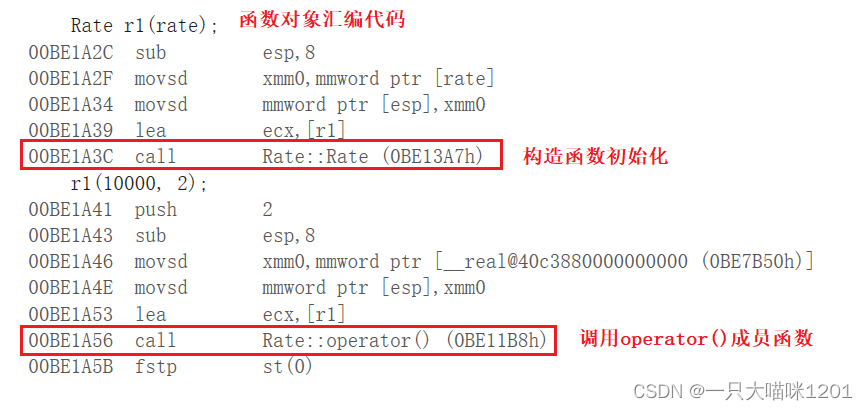
调试起来后,查看汇编代码,如上图所示是调用函数对象部分的汇编代码。
- 创建函数对象时,调用了Rate类域中的构造函数。
- 调用函数对象时,调用了Rate类域中的operator()成员函数。
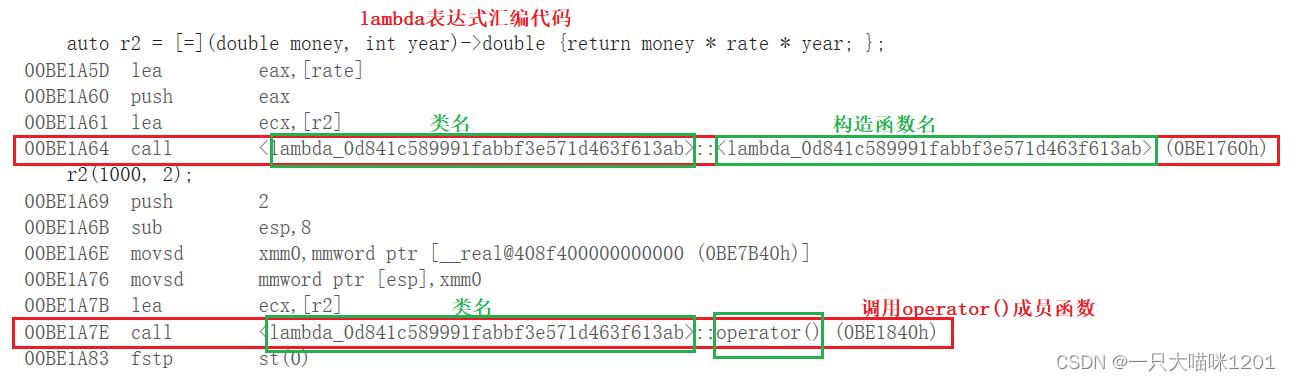
上图所示是lambda表达式部分的汇编代码。
- 创建lambda表达式时,也是调用了某个类中的构造函数。
该类不像函数对象那样明确,而是有很长一串,如上图所示的lambda_0d841c589991fabbf3e571d463f613ab。
- 调用lambda表达式时,调用的是该类中的operator()成员函数。
函数对象和lambda在汇编代码上是一样的,只是类不同而已。函数对象的类名是我们自己定义的。
- lambda的类名是编译器自己生成的。
编译器在遇到lambda表达式的时候,会执行一个算法,生成长串数字,而且几乎每次生成的数字都不同,也就意味着每次创建的类名都不同。
- lambda表达式的类型只有编译器自己知道,用户是无法知道的。
- 所以要通过auto来推演它的类型,才能接收这个匿名的函数对象。
lambda表达式和函数对象其实是一回事,只是lambda表达式的类是由编译器自动生成的。
此时大家应该就理解了为什么说lambda其实就是一个匿名的函数对象了吧。
注意:lambda表达式相互之间不可以赋值,因为编译器生成的类不一样,也就意味着不是一个类型。
🏀可变参数模板
template <class ...Args>
void ShowList(Args... args)
{
//.......
}
- Args:是一个模板参数包,在模板中必须以…Args表面它是一个模板参数包。
- args:是一个形参参数包,它的类型是Args…表面它是一个参数包。
- 参数包:可以包含0~N个类型的参数。
在使用可变参数模板的时候,可以传入任意个类型的数据,编译器会将所有类型打包。
可变参数模板的难点就是如果展开参数包,从而使用里面的每个模板参数。
🥎展开参数包
递归函数方式展开参数包:
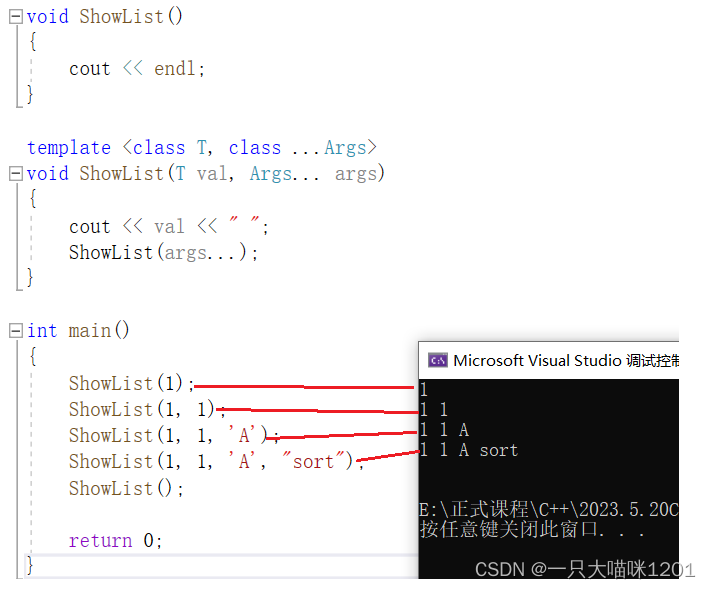
先直接看结果,调用同一个函数模板,传入不同个数的参数,函数模板都能将这些变化的参数打印出来。
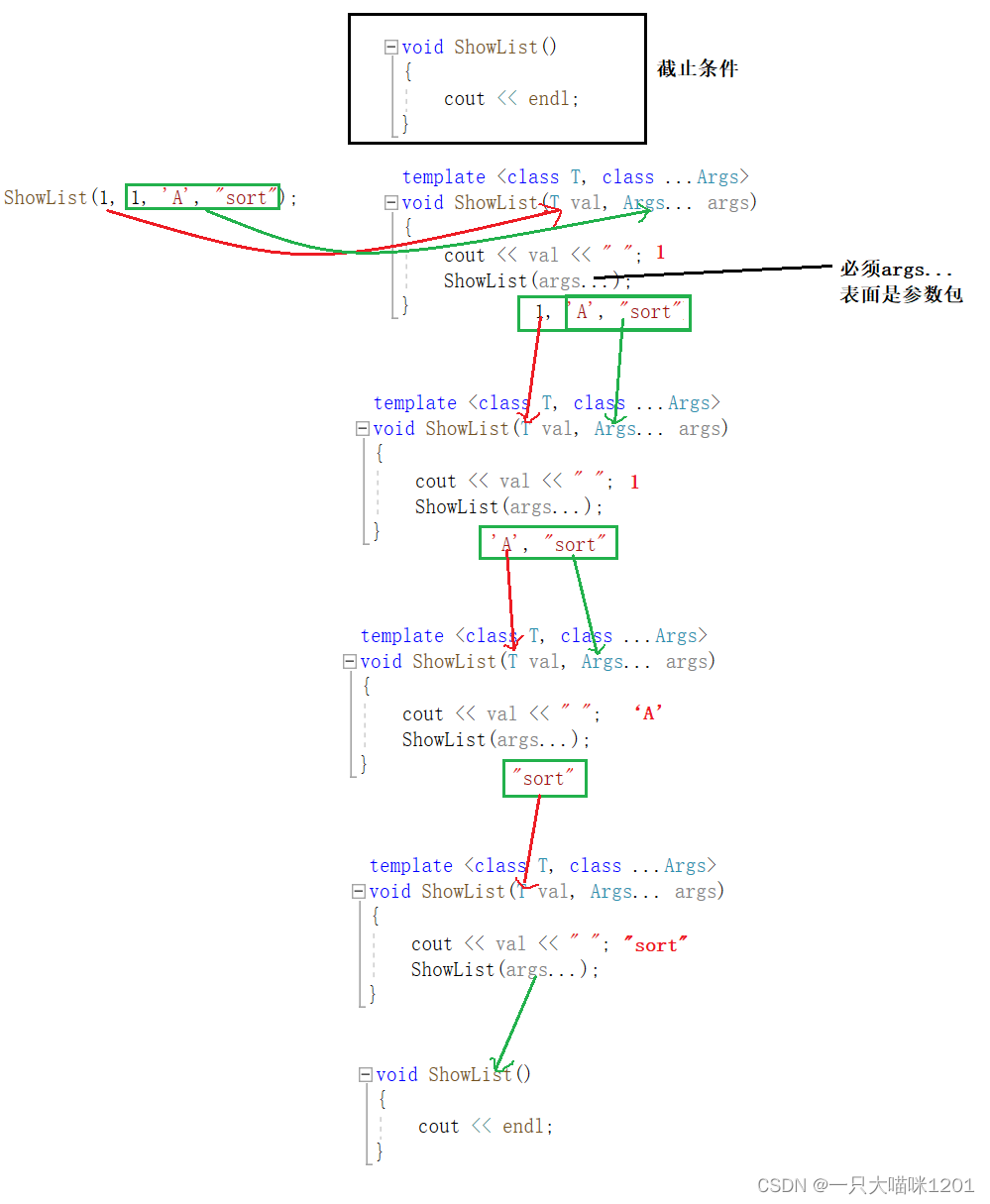
以调用ShowList(1, 1, ‘A’, “sort”);为例解释展开参数包的过程。
- 传递实参(1, 1, ‘A’, “sort”),ShowList接收参数。
- 1 → T val
- (1, ‘A’, “sort”) → Args… args
打印val值,剩下的参数以参数包的形式继续传给ShowList。
- 传递实参(1, ‘A’, “sort”),ShowList接收参数。
- 1 → T val
- (‘A’, “sort”) → Args… args
打印val值,剩下的参数继续以参数包的形式传给ShowList。
- 传递实参(‘A’, “sort”),ShowList接收参数。
- ‘A’ → T val
- (“sort”) → Args… args
打印val值,剩下的参数继续以参数包的形式传给ShowList。
- 传递实参(“sort”),ShowList接收参数。
- “sort” → T val
- 此时参数包中没有参数了,调用无形参的ShowList()。
打印val值,再调用不需要接收形参的ShowList(),打印换行,到此参数包的展开就完毕了。
这种方式很像递归,在函数模板中调用函数模板,通过模板参数中的第一个模板参数一个个从参数包中拿参数。不需要的形参的函数就相当于一个结束条件。
逗号表达式展开参数包:

先上代码,后面再解释为什么这样。
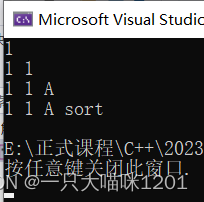
同样将参数包挨个展开了。
- 逗号表达式的结果是最右边的值。
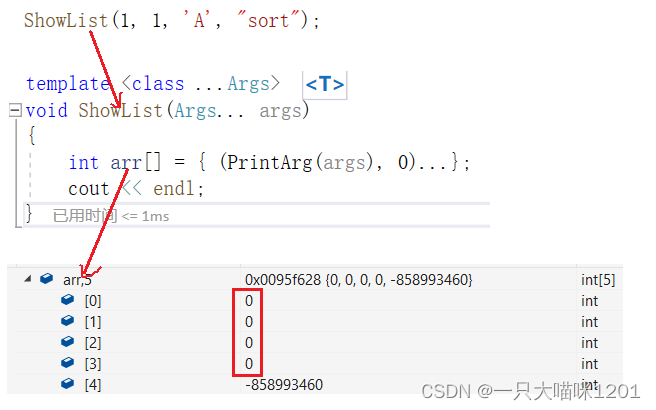
- 调用ShowList的时候,传入了四个参数。
- 将参数包放在数组中,并且调用打印函数PrintArg。
{(PrintArg(args), 0)...};
展开成为:
{(PrintArg(arg1), 0), (PrintArg(arg2), 0), (PrintArg(arg3), 0), (PrintArg(arg4), 0)};
由于使用的是逗号表达式,所以(PrintArg(arg1), 0)会先调用PrintArg(arg1),最终返回最右边的值,也就是0。
参数包中的每个参数都执行这样的逻辑,最终返回的都是0,而这由0组成的列表又初始化了数组arr。
所以我们可以在调试窗口中可以看到数组中的值是0。
在这里,数组的目的仅仅是为了在构造数组的过程中展开参数包,它起到一个辅助作用。
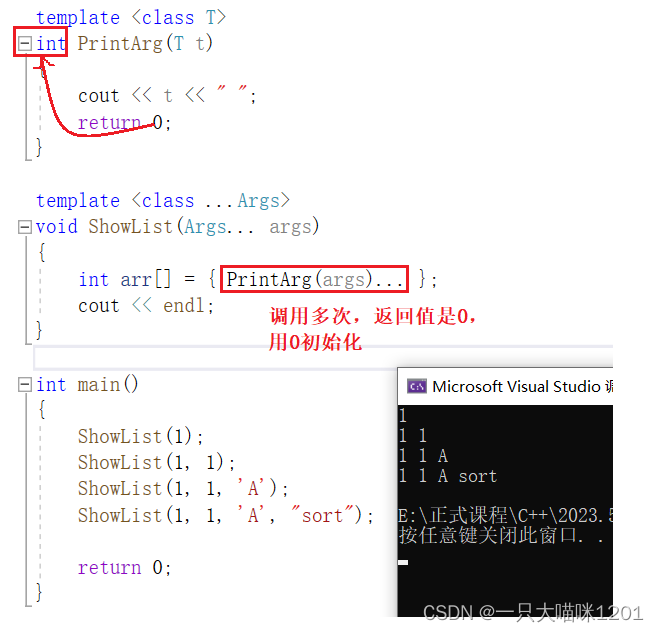
采用上图所示方式也可以展开参数包。
- 在ShowList中的数组中多次调用PrintArg函数,每次调用后返回值是0。
- 多个0形参的列表初始化数组。
这种方式中,看起来比逗号表达式好理解,数组同样仅起辅助作用。
🥎STL中emplace相关接口
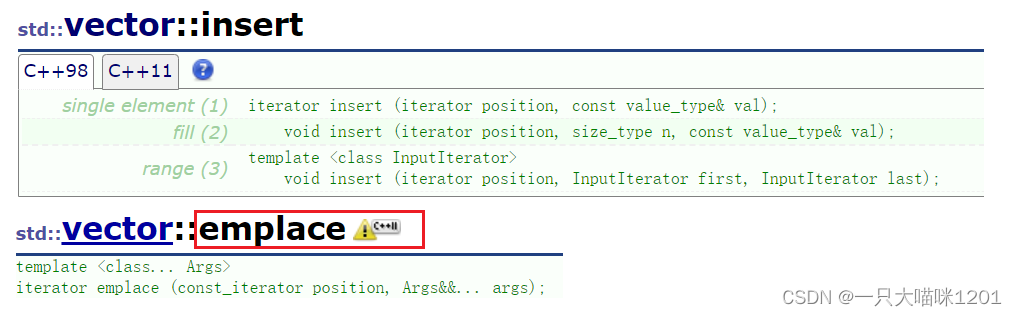
emplace的作用和insert类似。
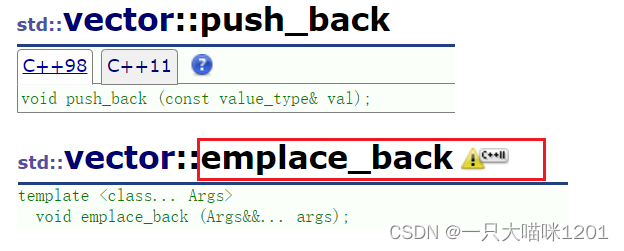
emplace_back的作用和push_back相似。
- C++11提供了emplace相关的系列接口,上图是以vector为例,其他STL容器也有emplace系列的相关接口。

emplace接口也是模板函数,它既是一个万能引用模板也是一个可变参数模板,可以称为万能引用可变参数模板。
- 无论插入的数据是左值还是右值,无论是多少个,都可插入。
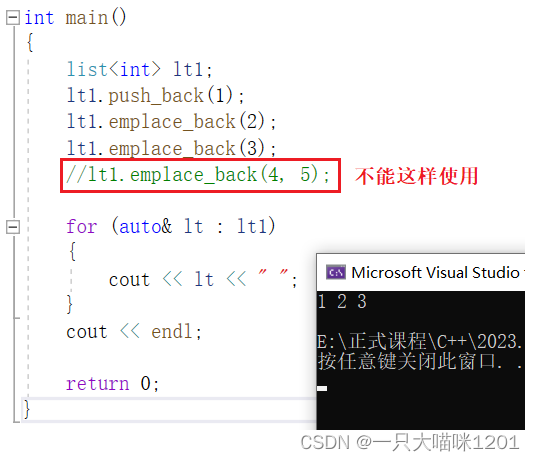
- 对于内置类型,push_back和emplace_back没有任何区别。
- 而且也不可以一次性插入多个内置类型的值。
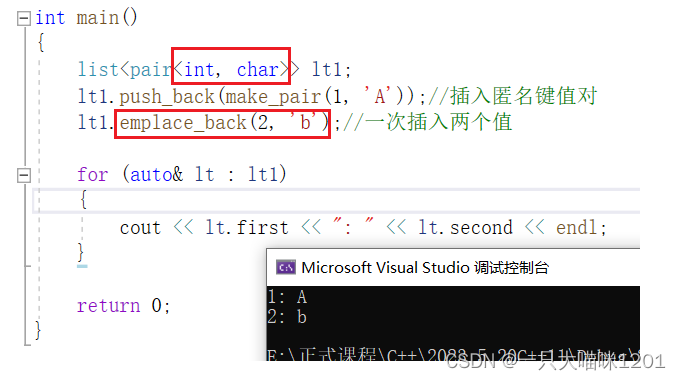
只有对容器实例化后,并且存放多个值时,才能使用empalce_back一次性插入。如上图所示。
emplace相关接口的优势:
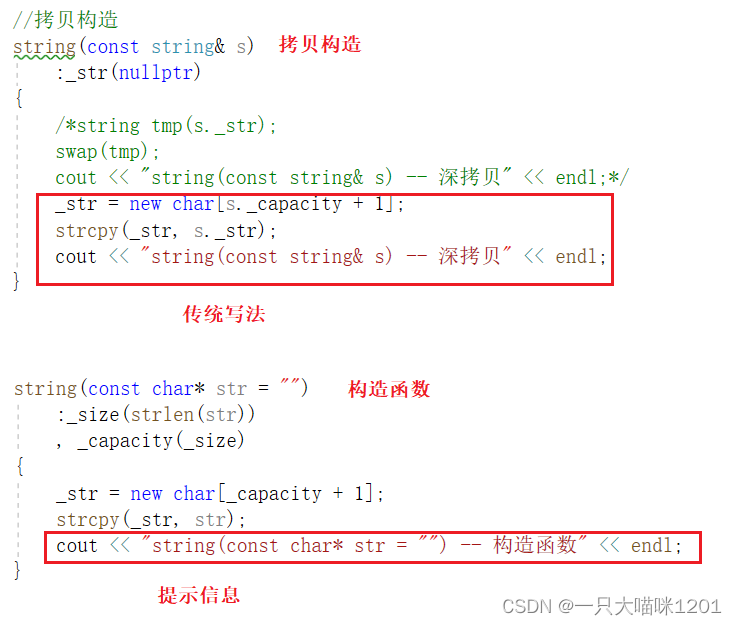
将上篇文章C++11——新特性 | 右值引用 | 完美转发中的string做改造。
- 拷贝构造改用传统写法,并且在用字符串的构造的构造函数中打印提示信息。
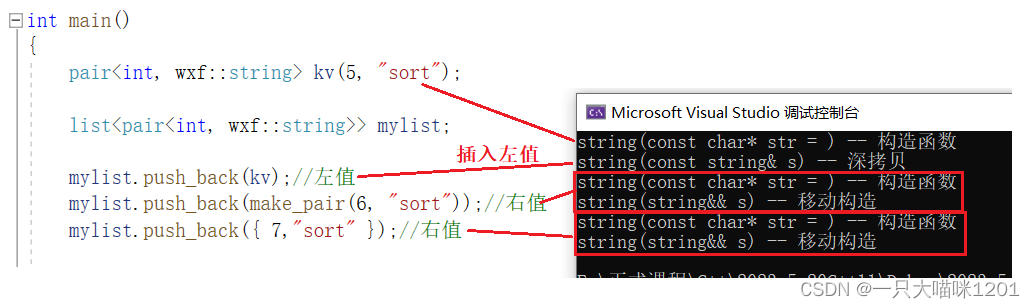
使用push_back插入不同类型的值。
- 插入左值:调用拷贝构造函数,发生了深拷贝。
- 插入右值(匿名键值对):调用构造函数和移动构造函数。
- 插入右值(匿名initializer_lis对象):调用构造函数和移动构造函数。
其中调用构造函数都是在初始化"sort"时候调用的。插入左值编译器不敢进行资源转移,所以在new一个新节点的时候进行深拷贝,而插入右值时在new新节点时直接进行了资源转移。
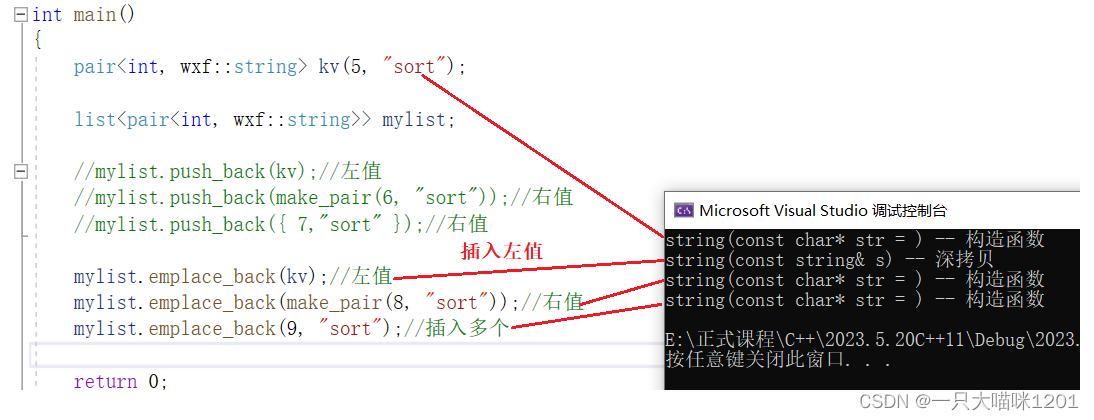
使用emplace_back插入不同类型的值。
- 插入左值:调用拷贝构造函数,发生了深拷贝。
- 插入右值(匿名键值对):仅调用构造函数,相比于push_back,少调用了移动构造函数。
- 插入多个值(可变参数):仅调用构造函数。
对比发现:
- 插入左值时,emplace_back和push_back没有区别。
因为左值无论是编译器还是emplace_back都是不敢进行优化的,只能老老实实进行深拷贝,以防影响到原本的左值。
- 插入右值(匿名键值对)时,emplace_back仅调用了构造函数。
在插入的过程中,匿名对象一直存在,没有被转移资源,知道链表在new一个新节点的时候,才用右值对象中的数据来初始化节点,其中string调用的是普通构造函数,是用右值中的字符串来初始化的。
- 插入多个值(可变参数)时,emplace_back仅调用了构造函数。
和插入右值一样,只有在new一个新节点的时候,多个插入的值才被用来初始化,所以也是只调用了普通构造函数。
- 只有在插入自定义类型的右值时,emplace_back的效率才比push_back高。
- emplace_back比push_back少调用了一个移动构造函数。
我们知道,移动构造是将右值的资源进行转移,也是非常高效的,代价非常小。
emplace系列接口在存在移动构造的情况下,并不能比push_back高效很多,但还是高一点的。

将string中的移动构造函数屏蔽后。
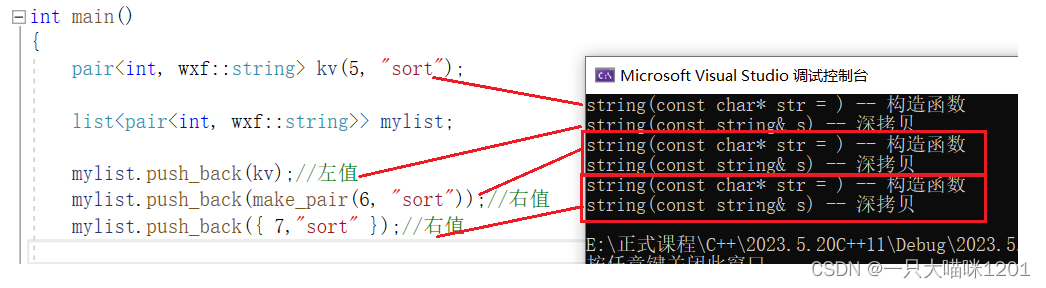
使用push_back插入左值和右值。
- 此时,无论是插入右值还是左值,调用的都是拷贝构造函数,进行了深拷贝。
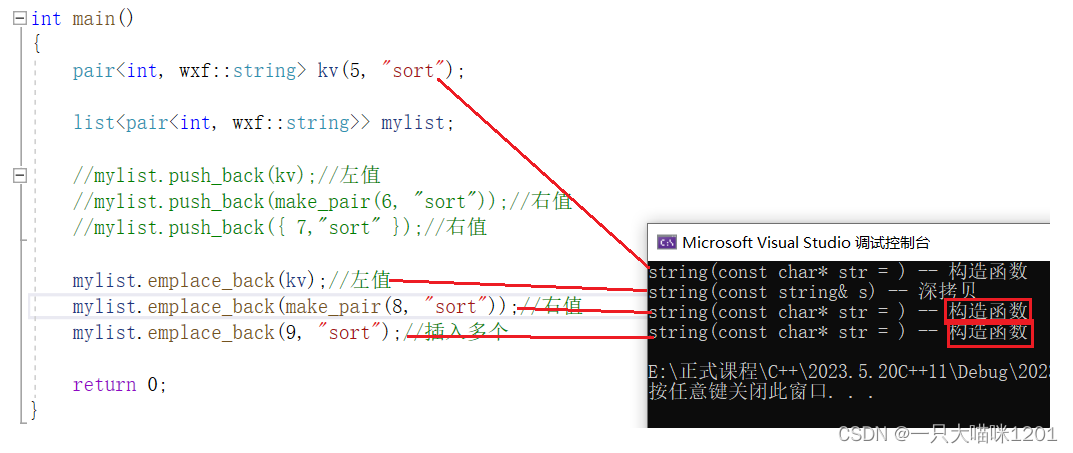
使用emplace_back插入左值和右值。
- 对于左值,仍然需要深拷贝。
- 对于右值,则仅调用了构造函数,不用进行拷贝构造而发生深拷贝。
emplace_back相比于push_back少调用了拷贝构造,没有进行深拷贝,大大提高了效率,降低了系统开销。
对于不存在移动构造的情况下,emplace相关接口比push_back高效很多。
🏀包装器
🥎function
- function包装器:也叫作适配器。
但是它和适配器又不一样,在模拟实现栈和队列的时候就是使用的适配器模式,适配器是在已有结构的基础上进行改造,如将正向迭代器改成反向迭代器。
而function包装器仅仅是进行包装,而不进行改造。它是一个类模板:
template <class Ret, class ...Args>
class function<Ret(Args...)>;
- 模板参数:Ret,表示返回值类型,…Args是参数包,表示可接收的形参。
- class function<Ret(Args…)>有点像模板特化的味道,Ret(Args…)其实就是函数去掉函数名,如int(char ch, int x)这样。
可以看出,function类包装的是有返回值和形参的可调用对象:
- 函数指针
- 仿函数对象
- lambda表达式
在使用function包装器的时候,必须包头文件:
#include <functional>
包装函数指针:
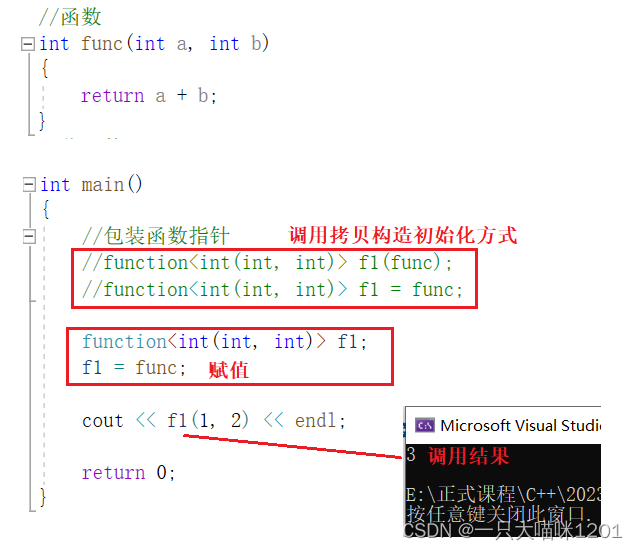
实现一个函数func,进行两个数相加,返回值是int类型,两个形参也是int类型。
- 在function实例化时使用<int(int, int)>,表示包装的可调用对象返回值和形参都是int类型。
- function实例化对象时,可以使用拷贝构造方式初始化。
- 也可以创建对象后再赋值。
包装过后,函数指针func就被包装成了f1,调用f1就可以执行函数func的逻辑,如上图结果所示。
包装仿函数对象:
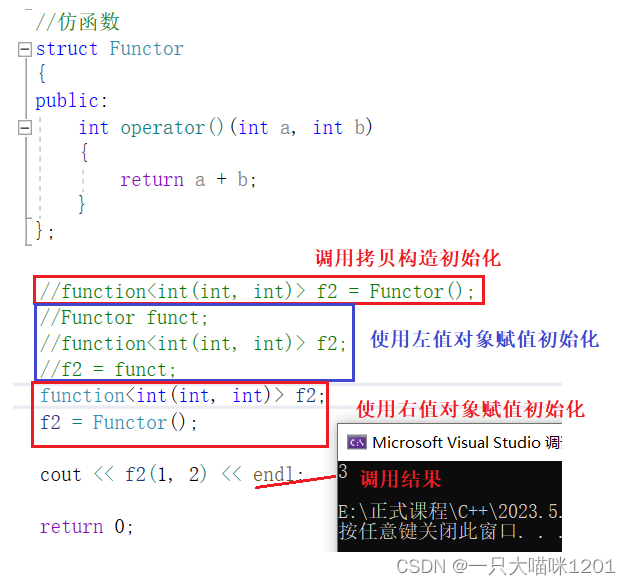
实现一个仿函数Functor,其中operator()的返回值是int,两个形参也是int。
- 包装仿函数对象时,可以使用仿函数对象的左值初始化也可以使用右值初始化。
- 和包装函数指针一样,可以使用调用拷贝构造的方式初始化,也可以使用赋值的方式初始化。
包装过后,仿函数对象就成了f2了,调用f2就可以执行仿函数对象的逻辑,如上图运行结果所示。

但是不能使用上图红色框中的方式来初始化function对象,即使是左值也不行。
- 根据这里的报错可以得出看到,编译器在这里将Functor识别成了一个指针,并不是仿函数对象。
本喵觉得这里是VS2019的编译器的BUG,按道理是可以的,有兴趣的小伙伴可以试试其他编译器。
包装lambda表达式:
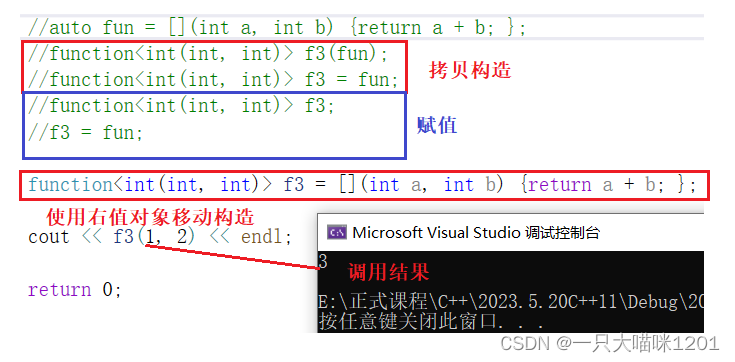
- 包装lambda表达式时,lambda可以是匿名对象,也可以是左值。
- 可以使用拷贝构造的方式初始化,也可以赋值。
包装过后,lambda表达式就成f3了,调用f3就可以执行仿函数对象的逻辑,如上图运行结果所示。
包装静态类成员函数:
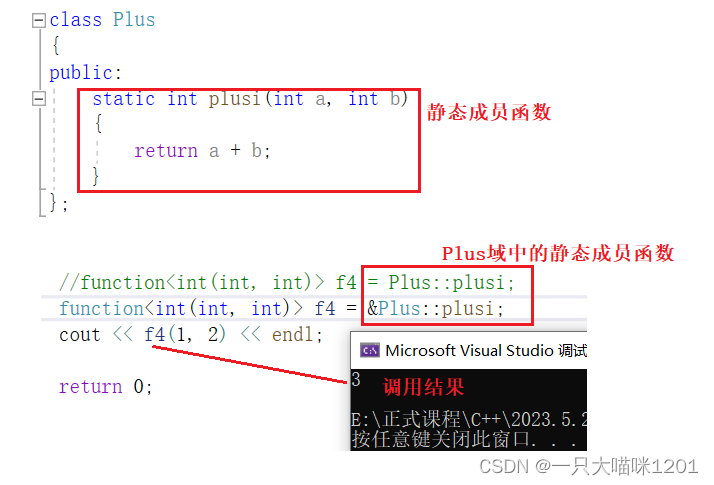
- 静态成员函数没有this指针,和普通函数的区别在于它处于某个类的类域中。
- 类名::静态成员函数名就是一个函数指针,所以可以之间包装。
- 对静态成员函数名的取地址符合可加可不加,建议加上。
对静态类成员函数包装后就成了f4了,调用f4执行的就是静态成员函数的逻辑,调用结果如上图所示。
包装类普通成员函数:
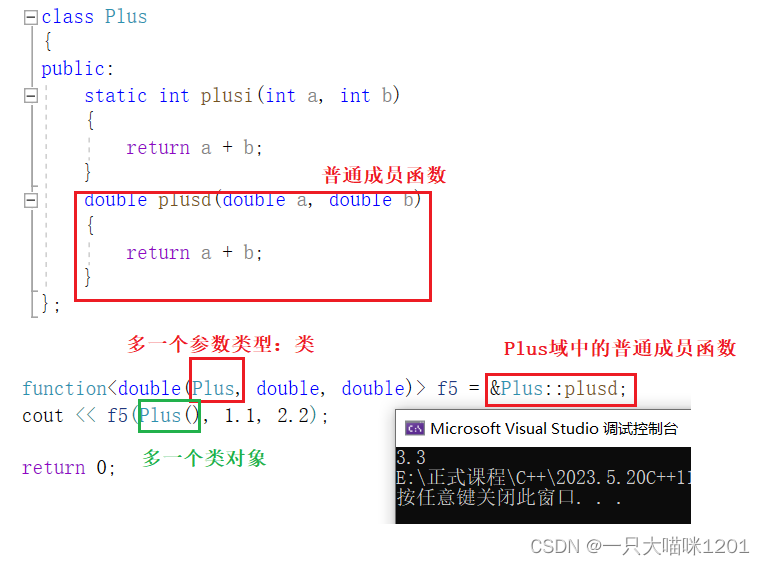
- 普通成员函数的调用是需要this指针的,而且this指针是不能显式传递的,只能由编译器来完成传递。
- &类::成函数名拿到了成员函数的函数指针,这里必须有取地址符号。
- 包装器实例化时,<double(Plus, double, double)>除了成员函数的两个形参类型外,还需要有当前类的类型。
- 在调用包装器时,除了传入的两个double类型的实参外,还要有当前类对象。
切记:实例化时需要的是当前类的类型,而不是当前类型的指针(this指针不会显式传递),调用包装器时,还需要传入当前类的对象。
对普通类成员函数包装后就成了f5了,调用f5执行的就是普通类成员函数的逻辑,如上图调用结果所示。
function作用之一:统一类型。
函数指针,仿函数对象,lambda表达式,静态类成员函数,普通类成员函数,这些可调用对象是完全不相同的类型,但是使用function包装器包装以后,就都变成了function<int(int, int)>类型了。

创建一个函数模板,在模板函数中创建一个静态变量,打印它的值和地址,并且每打印一次后对其进行加加。通过实例化后的可调用对象执行相应的逻辑。
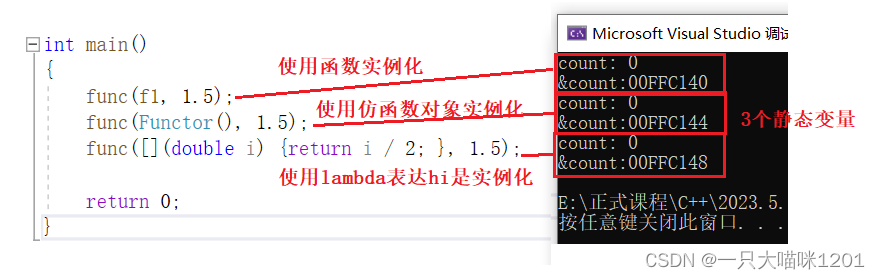
- 使用函数f1实例化函数模板,并且给定的实参是1.5。
- 使用仿函数对象实例化函数模板,给定的实参是1.5。
- 使用lambda表达式实例化函数模板,给定的实参是1.5。
当然还可以用静态成员函数以及非静态成员函数实例化函数模板,有兴趣的小伙伴自己尝试。
- 运行结果中有三个不同的静态变量(它们的地址不相同),而且值都是0。
- 说明实例化出了3个函数。
模板实例化后推演为具体类型的工作是由编译器完成的,这其实有很大的系统开销,只是我们没有感觉罢了。

使用包装器将上面用来实例化函数模板的三种可调用对象进行包装,此时就都变成了function<double(double)>类型了,只有一种类型。
再用这种function类型去实例化函数模板,编译器推演后只实例化出一个函数。
- 静态变量的地址都相同,说明它们是同一个静态变量。
- 静态变量从0变化到2,说明这个函数被调用了3次。
经过function的包装后,减少了实例化的系统开销。
function作用之二:减少因多次实例化导致的系统开销。
作用一和二的本质都是通过统一类型完成的,在需要将多种可调用对象统一类型的场景时,就使用function包装器。
🥎bind

- bind:也叫做绑定,是一个函数模板,它就像一个函数包装器(适配器),接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。
- 这是一个万能引用模板,除了可调用对象模板参数外,其他参数是可变参数,也就是一个参数包。
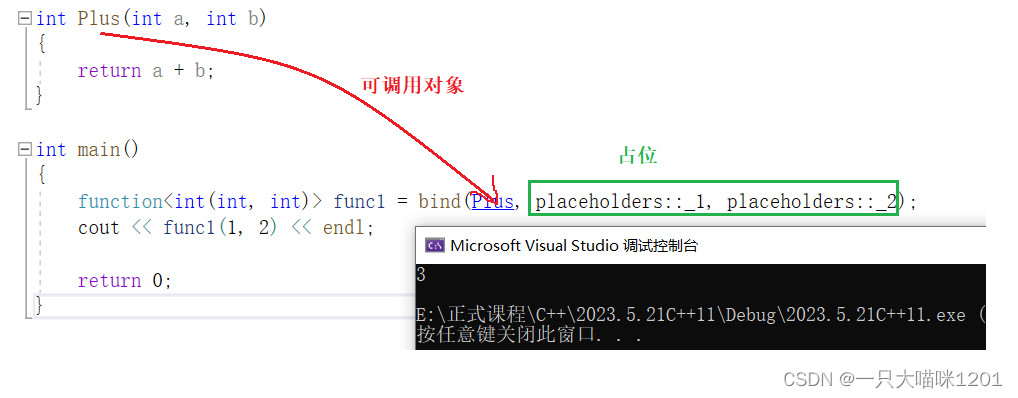
bind(可调用对象, 占位1, 占位2.....);

C++11提供了一个命名空间placeholders,该空间中的_1, _2, _3…表示占位符。
- bind可调用对象时,并没有传参数,但是要根据可调用对象的形参个数先占好位。
上面代码表示:绑定函数plus参数分别由调用func1的第一、二个参数指定。
- 可调用对象经过bind绑定以后,就称为绑定函数。
bind的作用主要有两个:调整可调用对象的参数顺序,绑定固定参数。
调整参数的顺序:

创建一个作减法的仿函数,将仿函数对象绑定后再使用function包装。
- func2和func3绑定的都是仿函数对象Sub()。
- func2绑定仿函数对象时,占位的顺序是placeholders::_1, placeholders::_2。
在调用func2(1, 2)的时候,1→placeholders::_1(形参int a),2→placeholders::_2(形参int b),所以执行a-b时就是1-2=-1。
- func3绑定仿函数对象时,占位的顺序是placeholders::_2, placeholders::_1。
在调用func3(1, 2)的时候,1→placeholders::_2(形参int b),2→placeholders::_1(形参int a),所以执行a-b时就是2-1=1。
根据这个道理,我们直接改变在使用sort()时的less仿函数比较方式。

只是在绑定仿函数对象时,调整了参数的顺序,就可以让less仿函数实现greater的功能。
绑定固定参数:
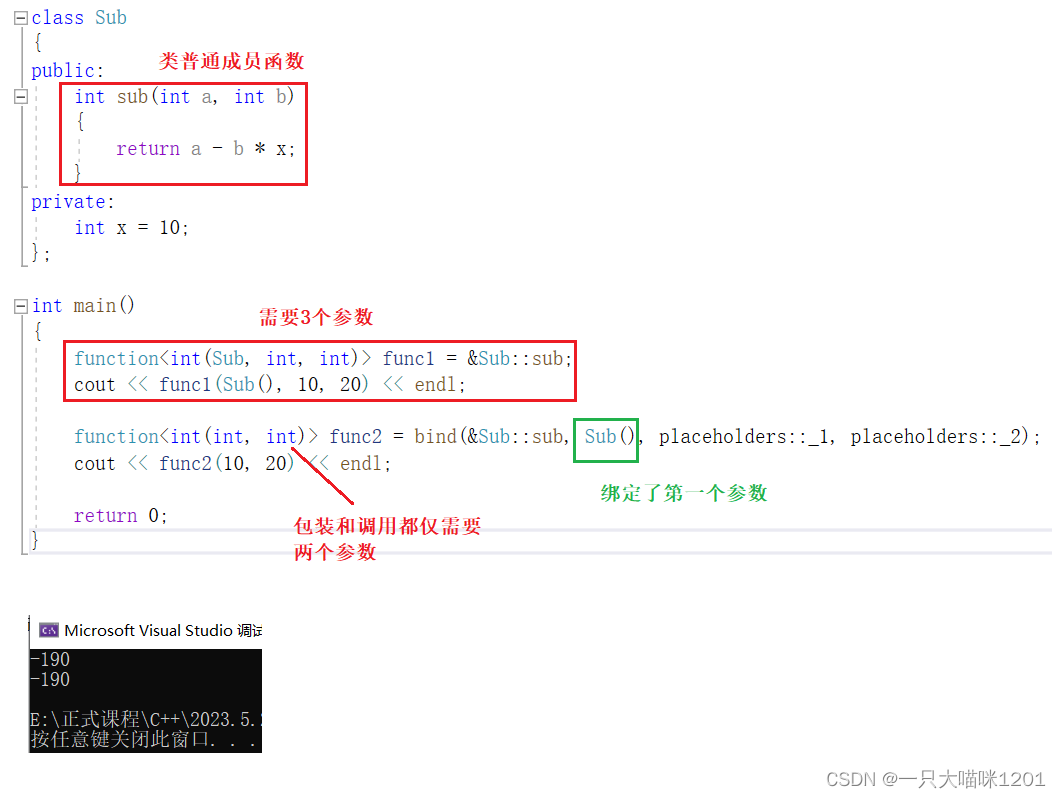
在使用function统一可调用对象类型的时候,那些可调用对象中,只有类的普通成员函数包装后的类型和其他不一样,因为在包装时候需要多一个当前类的类型,调用时还需多一个当前类的对象。
- 将类普通成员函数绑定时,将需要多的那个当前类对象的参数绑定。
如上图绿色框中所示,意味着将Sub()匿名对象绑定了,也就是编译器自动将这个参数在调用的时候传给类成员函数了。
我们在调用时只需要传递后两个参数即可。可以看到,两种方式的运行结果是一样的。
🏀总结
lambda表达式是一个经常使用的东西,使用起来也很方便,非常时候临时使用一下。至于可变参数模板,只需要了解有这个东西就可以,知道emplace相关接口是可变参数模板,一次可以传入多个参数,我们自己几乎不会写这样的模板。function的时候也非常普遍,尤其在网络部分,至于bind只需要了解即可。



![buu [AFCTF2018]MyOwnCBC 1](https://img-blog.csdnimg.cn/b53a15be88f14bb49e60ad3d0ec8fbc7.png)





![[CTF/网络安全] 攻防世界 xff_referer 解题详析](https://img-blog.csdnimg.cn/11f390c5dd2c45fda42155833b78bd99.png#pic_center)