文章目录
- swin Transformer
- 创新点:
- 网络架构:
- Patch Partition
- linear Embedding
- Swin Transformer
- Patch Merging
- 总结
swin Transformer
论文:https://arxiv.org/pdf/2103.14030.pdf
代码:https://github.com/microsoft/Swin-Transformer
本文参考:swin Transformer讲解视频
创新点:
- Swin Transformer使用了类似CNN中的层次化构建方法(Hierarchical feature maps),这样的方法有利于提取到多层次的特征,方便分割等下游任务。
- 划分了更小的patch,就必然会带来更大的计算量,所以Swin Transformer使用了Windows Multi-Head Self-Attention(W-MSA),在每个窗口进行注意力计算,这样做可以大大减少计算量。但是这样做在减少了计算量的同时也会隔绝不同窗口之间的信息传递,所以作者又提出了Shifted Windows Multi-Head Self-Attention(SW-MSA),使信息在相邻的窗口传递
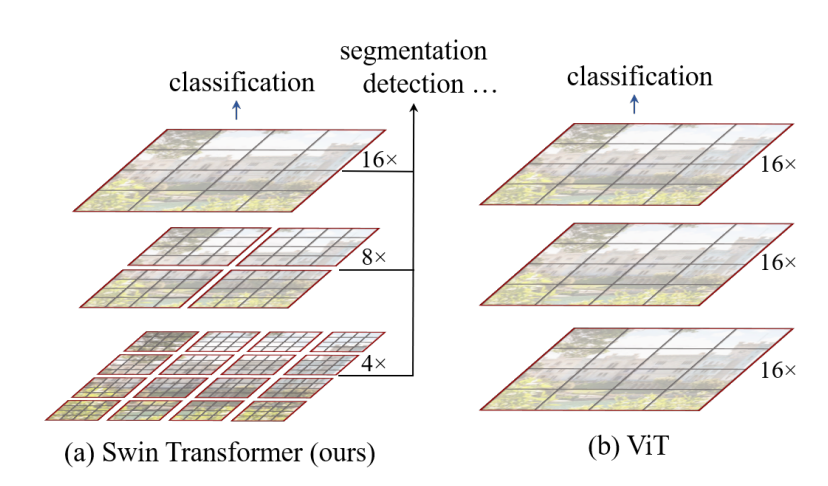
网络架构:
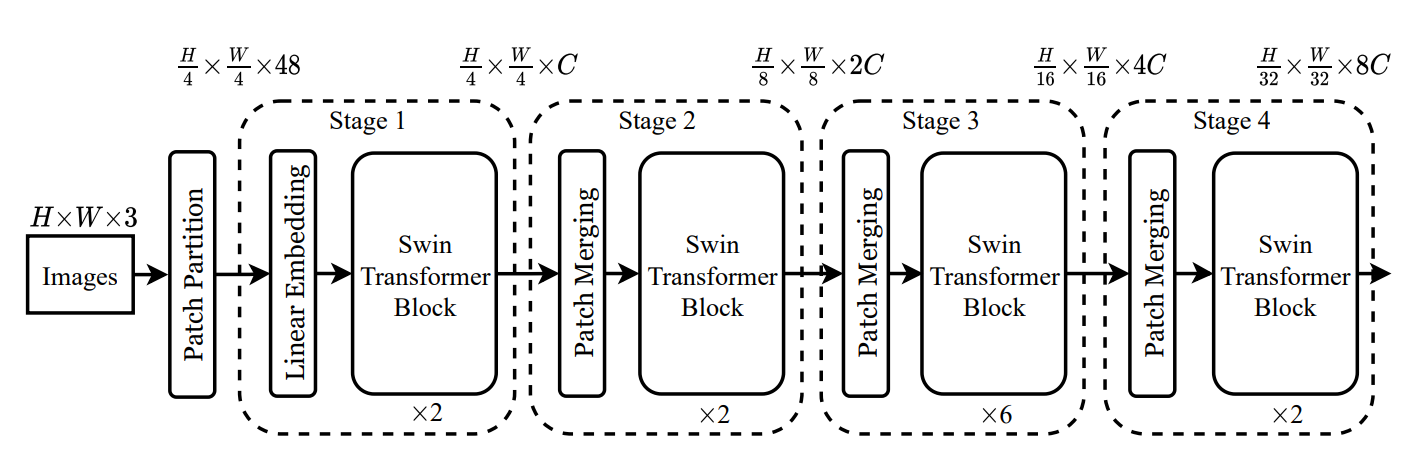
网络框架图如下:
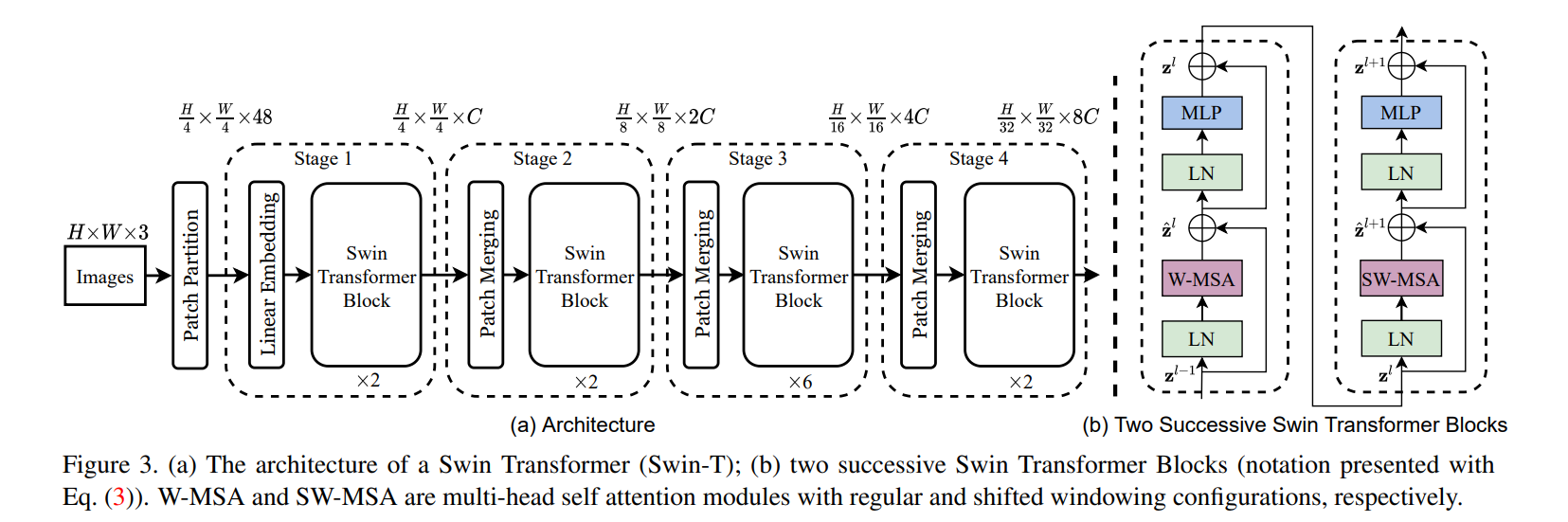
整个过程如下:
Patch Partition
假设我们输入图像为224x224x3,那么首先过一个Patch Partition
就是把图像划分为4x4的patch,每一个patch大小为4x4x3,将其拉直就是48大小,我们将其当作一个token
那么处理后大小就变成56x56x48
(56是224/4得到的,48是4x4x3)
代码的做法是使用卷积实现的)
linear Embedding
stage1部分,进来先是一个linear Embedding,线性映射
将56x56展平,得到3136x48的token,经过线性映射将其变为3136xC,(不同版本的C大小不同)
线性映射层的目的就是为了改变通道数,改变为Transformer可以接受的长度。还会过一个Layer_Norm。
(其实这个linear Embedding和上面的Patch Partition,在代码中是合在一起用一次卷积实现的,输入通道数=3,输出通道数=C,stride=4,卷积核大小=4,然后展平,得到3136xC的二维矩阵。这个就相当于ViT的PatchEmbed)
Swin Transformer
得到3136xC,显然不能输入道Transformer里面,这尺寸太长了。所以这里使用的是Windows Multi-head Self-Attention(W-MSA)
我们将原来的图片56x56xC划分为一个个没有重叠的小窗口,窗口大小是7x7,然后在每个小窗口里面做自注意力,这个计算量就大大降低了
56x56xC划分后就得到了8x8个窗口。这种方法与原来的方法复杂度对比:
具体可以去看视频讲解:https://www.bilibili.com/video/BV13L4y1475U/?vd_source=20756f1667908eb0bfec8057bec3fb85
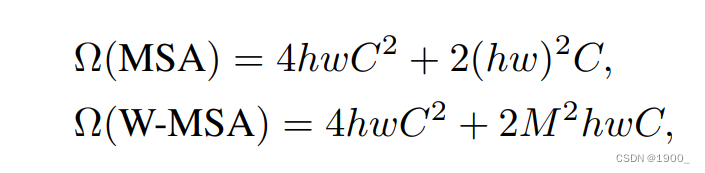
这么做有一个问题,每个窗口都独立的去做注意力,那么窗口与窗口之间就没有信息交换了,也无法达到全局建模了。
所以下面引入了移动窗口的概念:Shifted Windows Multi-Head Self-Attention(SW-MSA)
加入原来的窗口如图蓝色框所示,我们就往右下方移动一半,(原来4x4,下移2格,右移2格)
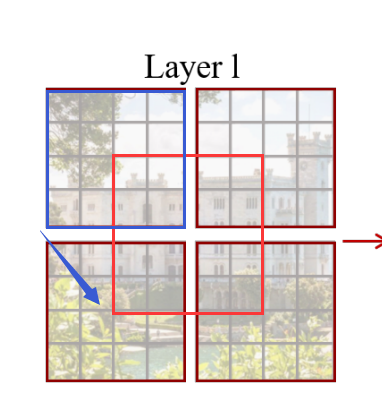
就得到了如下图所示的效果:
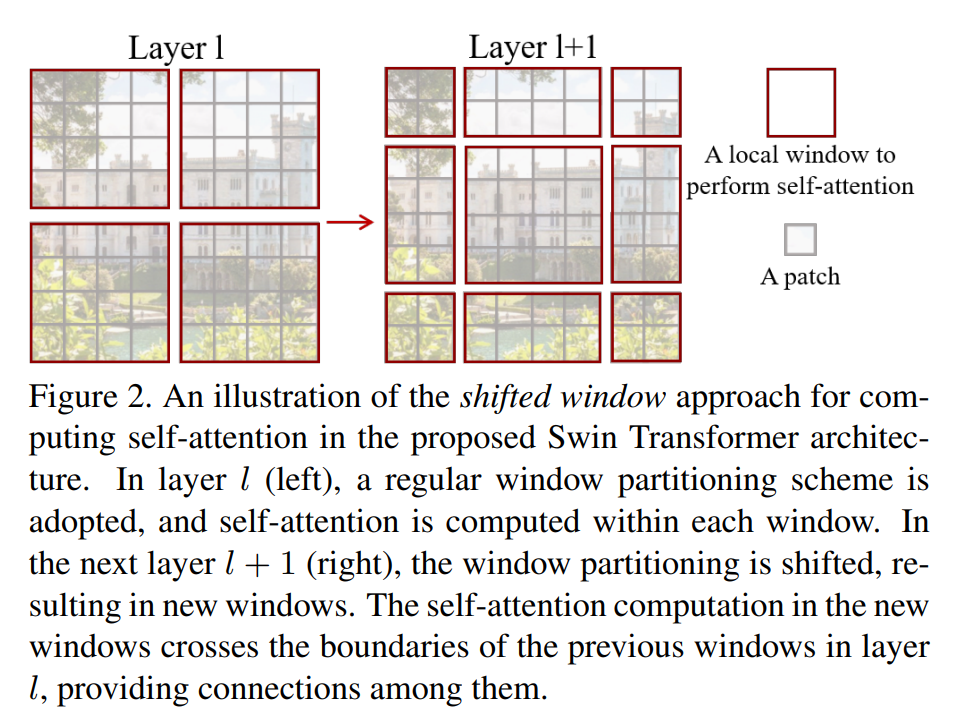
在右移后的窗口上再做一次多头注意力
每次都是两个连着:先在窗口上做一次MSA,再在移动后的窗口上做一次MSA。这样就实现了窗口间的通信。
所以可以看到每个stage里面的层数安排都是偶数,因为这两层是一起用的。
- 作者为了提高移动窗口多头自注意力的计算效率,还提出了一种掩码计算方式
- 本文采用相对位置编码而非绝对位置编码
掩码计算参看老师的视频讲解就行,讲的很清楚:
https://www.bilibili.com/video/BV13L4y1475U/?vd_source=20756f1667908eb0bfec8057bec3fb85
Patch Merging
经过stage1,输出和输出尺寸是一样的,输出还是3136xC
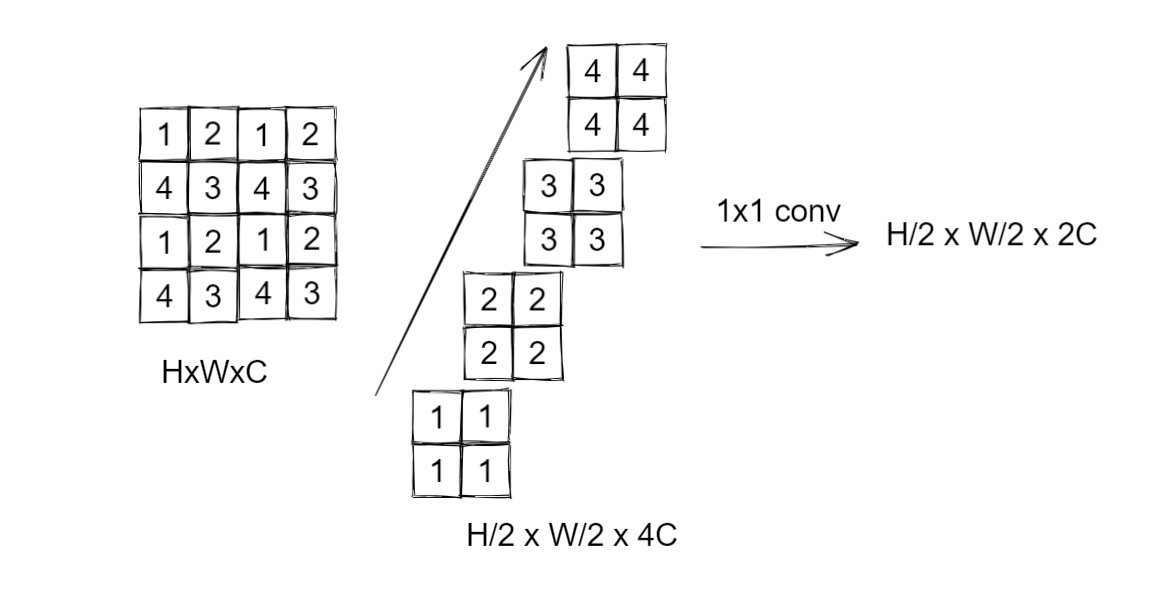
那么想要实现多尺度的特征,就要将图像patch合并,类似CNN里面的池化操作。
合并操作的做法如图,比如我们要上采样两倍,那我们就会间隔一个的取,然后把第一张图中所有标1的位置,标2的位置,拿出来放一起
然后将得到的这四个2x2xC的块cat起来,就得到了 H / 2 , W / 2 , 4 C H/2 ,W/2, 4C H/2,W/2,4C的大小,我们也模仿CNN里面的操作(上采样一次,通道数让他翻倍)
这里通道数翻了4倍,所以我们再使用一个1x1的卷积,将其通道数降为2C。
这就是整个Patch Merging操作 ,我们可以将原来为 H , W , C H,W,C H,W,C的张量,变为 H / 2 , W / 2 , 2 C H/2,W/2,2C H/2,W/2,2C大小的张量
总结
整个swin Transformer就是这样分阶段的堆叠Block,从而达到提取多层次特征的效果。







![[附源码]JAVA毕业设计计算机散件报价系统(系统+LW)](https://img-blog.csdnimg.cn/046c6da2f7bf43d6bcadb2fa6c01c649.png)

![[附源码]计算机毕业设计影院管理系统Springboot程序](https://img-blog.csdnimg.cn/c8b2003fe12c44ac9ad73dfba894c23b.png)

