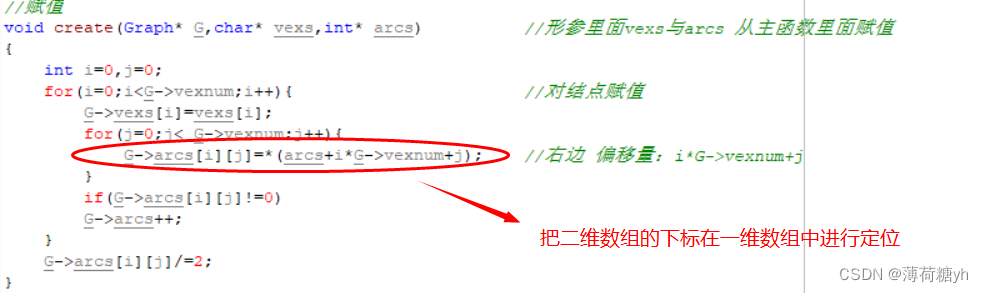
1. 解决了什么问题?
自动驾驶系统感知周围的环境再进行决策,极具挑战。基于视觉的自动驾驶系统对准确性和效率的要求很严格,人们会采用不同的范式来解决 3D 检测和分割任务。对于多相机 3D 目标检测,image-view-based 方法如 FCOS3D 和 PGD 处于领先位置;对于 BEV 语义分割任务,则由 BEV-based 方法如 PON、LSS 和 VPN 主导。本文试图通过一个范式来解决 3D 目标检测和 BEV 语义分割问题。
2. 提出了什么方法?
BEVDet 在 BEV 空间进行 3D 目标检测。
2.1 网络结构
它包含 4 个模块,一个 image-view encoder (包括主干网络和 neck)提取图像特征、一个 view transformer 将图像特征转换到 BEV、一个 BEV encoder 编码 BEV 特征,最后是一个任务 head 利用 BEV 特征在 BEV 空间进行 3D 目标检测。

Image-view Encoder
图像编码器将输入图像编码为特征,包括一个主干网络进行特征提取,以及一个 neck 进行多分辨率特征融合。主干网络可以使用 ResNet、SwinTransformer、DenseNet、HRNet 等。Neck 使用的是 FPN-LSS,将 1 / 32 1/32 1/32输入分辨率的特征上采样为 1 / 16 1/16 1/16输入分辨率,然后和主干输出的特征 concat。
View Transformer
将图像特征转换到 BEV 空间。View transformer 的输入是图像特征,通过分类的方式对深度值做密集预测。然后,根据分类得分和图像特征来渲染点云。最后,沿着垂直方向(即 Z \text{Z} Z坐标轴)使用池化操作。默认的深度范围在 [ 1 , 60 ] \left[1,60 \right] [1,60]米,间隔是 1.25 × r 1.25\times r 1.25×r, r r r表示输出特征的分辨率。
BEV Encoder
BEV encoder 在 BEV 空间编码特征。其结构和 image-view encoder 相近,包含一个主干和 neck。它能感知到尺度、方向和速度的重要信息。
Head
有了 BEV 特征,我们就可构建任务 head。3D 目标检测要获取到位置、尺度、方向和运动物体的速度,如行人、车辆、障碍物等。本方法直接使用了 CenterPoint 第一阶段的 3D 目标检测 head。
2.2 数据增广策略
Isolated View Spaces
View transformer 以逐像素的方式将特征从图像角度转换到 BEV。给定图像平面的像素点
p
i
m
a
g
e
=
[
x
i
,
y
i
,
1
]
T
\text{p}_{image}=\left[x_i,y_i,1\right]^T
pimage=[xi,yi,1]T,深度值为
d
d
d,对应的 3D 空间坐标是:
p
c
a
m
e
r
a
=
I
−
1
(
p
i
m
a
g
e
∗
d
)
\text{p}_{camera} = \text{I}^{-1}(\text{p}_{image}\ast d)
pcamera=I−1(pimage∗d)
I \text{I} I 是一个 3 × 3 3\times 3 3×3的相机内参矩阵。常用的数据增广方法如翻转、裁剪、旋转,可以用一个 3 × 3 3\times 3 3×3的变换矩阵 A \text{A} A来表示。当我们对输入图像做数据增广(即 p i m a g e ′ = A p i m a g e \text{p}'_{image}=\text{A}\text{p}_{image} pimage′=Apimage),我们也要在 view transformation 时使用 A − 1 \text{A}^{-1} A−1逆变换,保证特征和 BEV 空间目标的一致性:
p c a m e r a ′ = I − 1 ( A − 1 p i m a g e ′ ∗ d ) = p c a m e r a \text{p}'_{camera} = \text{I}^{-1}(\text{A}^{-1}\text{p}'_{image}\ast d)=\text{p}_{camera} pcamera′=I−1(A−1pimage′∗d)=pcamera
这样,对图像做增广不会改变 BEV 空间的特征分布。我们就可以在图像空间使用复杂的数据增广策略。
BEV Space Learning with Data Augmentation
对于 BEV 空间的学习,数据量要少于图像空间的,因为每个样本包括多个相机图像。BEV 空间的学习会很容易过拟合。因为 view transformer 在数据增广时将两个空间分开进行,作者在 BEV 空间构建了另一个增广策略,达到正则效果。作者采用了 2D 空间常见的操作(如翻转、缩放、旋转),对 view transformer 的输出特征和 3D 检测的 ground-truth 进行增广。
2.3 Scale-NMS
BEV 空间里各类别的空间分布和图像空间的区别很大。在图像空间,因为相机成像机制,所有的类别有着相似的空间分布。因此,使用 NMS 和一个固定的阈值就能很好地处理所有类别的预测结果。但是,在 BEV 空间,不同类别所占据的区域是不一样的,各实例之间的重叠面积应该近似于 0。预测结果的 IOU 分布会随着类别而变化。如下图,行人和锥形交通路标在地平面上的面积非常小,经常会小于算法的输出分辨率(如 CenterPoint 中的 0.8 米)。较小的面积可能会造成冗余的检测结果与 true positive 之间的 IOU 是 0。Scale-NMS 会根据每个目标的类别进行缩放,然后再进行 NMS。缩放系数是与具体类别相关的,在验证集上搜索得到。

2.4 实验
数据集
使用了 nuScenes 数据集,共 1000 个场景,用 6 个相机采集。训练集、测试集和验证集各 700、150 和 150 个场景。共有 140 万个 3D 标注框,10 个类别:car, truck, bus, trailer, construction vehicle, pedestrian, motorcycle, bicycle, barrier, traffic cone。
Metrics
对于 3D 检测,报告了 mean Average Precision (mAP), Average Translation Error (ATE), Average Scale Error (ASE), Average Orientation Error (AOE), Average Velocity Error (AVE), Average Attribute Error (AAE), and NuScenes Detection Score(NDS)。mAP 指标与 2D 目标检测使用的类似,但是用地平面上 2D 中心点距离来计算的,而非 IOU。
训练参数
模型使用 AdamW 训练,学习率是 2 e − 4 2e-4 2e−4,batch size 是 64,用了 8 张 3090 GPU。对于 ResNet 图像编码器,使用 step learning rate policy,在第 17 和第 20 个 epoch 时学习率乘以 0.1 0.1 0.1。对于 SwinTransformer 图像编码器,使用了 cyclic policy,在前 40 % 40\% 40%个 epochs,学习率逐渐从 2 e − 4 2e-4 2e−4线性增加到 1 e − 3 1e-3 1e−3,然后在剩余 epochs 中线性地衰减到 0 0 0。总共有 20 个 epochs。
数据处理
输入图像的宽度和高度 W i n W_{in} Win和 H i n H_{in} Hin。训练时的输入分辨率是 1600 × 900 1600\times 900 1600×900,然后经过随机翻转、在 s ∈ [ W i n / 1600 − 0.06 , W i n / 1600 + 0.11 ] s\in\left[W_{in}/1600-0.06, W_{in}/1600+0.11\right] s∈[Win/1600−0.06,Win/1600+0.11]范围内随机缩放,在 r ∈ [ − 5. 4 ∘ , 5. 4 ∘ ] r\in \left[-5.4^\circ, 5.4^\circ\right] r∈[−5.4∘,5.4∘]范围内随机旋转,最后裁剪为大小是 W i n × H i n W_{in}\times H_{in} Win×Hin。在水平方向上随机进行裁剪,在垂直方向上保持固定, ( y 1 , y 2 ) = ( max ( 0 , s ∗ 900 − H i n ) , y 1 + H i n ) (y_1,y_2)=(\max(0, s\ast 900 - H_{in}), y_1 + H_{in}) (y1,y2)=(max(0,s∗900−Hin),y1+Hin), y 1 , y 2 y_1,y_2 y1,y2分别是目标区域的上边界和下边界。在 BEV 空间,对输入特征和 3D 目标检测 ground-truths 使用随机翻转, [ − 22. 5 ∘ , 22. 5 ∘ ] \left[-22.5^\circ, 22.5^\circ\right] [−22.5∘,22.5∘]的随机旋转,和 [ 0.95 , 1.0 ] \left[0.95,1.0\right] [0.95,1.0]的随机缩放。测试时,使用 s = W i n / 1600 + 0.04 s=W_{in}/1600+0.04 s=Win/1600+0.04的系数缩放,裁剪至分辨率 W i n × H i n W_{in}\times H_{in} Win×Hin,区域范围是 ( x 1 , x 2 , y 1 , y 2 ) = ( 0.5 ∗ ( s ∗ 1600 − W i n ) , x 1 + W i n , s ∗ 900 − H i n , y 1 + H i n ) (x_1,x_2,y_1,y_2)=(0.5\ast (s\ast 1600-W_{in}),x_1 + W_{in}, s\ast 900 - H_{in}, y_1 + H_{in}) (x1,x2,y1,y2)=(0.5∗(s∗1600−Win),x1+Win,s∗900−Hin,y1+Hin)。
3. 有什么优点?
2021年 nuScenes 纯视觉3D目标检测世界第一的方案,BEVDet-Tiny 在 nuScenes 验证集上取得了 31.2 % 31.2\% 31.2%mAP 和 39.2 % 39.2\% 39.2%NDS,计算量是 FCOS3D 的 11 % 11\% 11%,只需 215.3 215.3 215.3GFLOPs,速度为 15.6 15.6 15.6FPS,快了 9.2 9.2 9.2倍。BEVDet-Base 取得了 39.3 % 39.3\% 39.3%mAP 和 47.2 % 47.2\% 47.2%NDS,比 FCOS3D 高了 9.8 % 9.8\% 9.8%mAP 和 10 % 10\% 10%NDS。



![学习open62541 --- [77] 修改String类型变量的注意点](https://img-blog.csdnimg.cn/c36b559c10354afd93dabfb60772fbb0.png)




![[CTF/网络安全] 攻防世界 command_execution 解题详析](https://img-blog.csdnimg.cn/0f3d2a3d813a48318d09c20a07995b56.png#pic_center)