代码优化



typedef struct {
unsigned short red; /* R value */
unsigned short green; /* G value */
unsigned short blue; /* B value */
} pixel
图像用一维数组表示,第(i,j)个像素表示为I[RIDX(i,j,n)],n为图像的维数
#define RIDX(i,j,n) ((i)*(n)+(j))
旋转操作
void naive_rotate(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(dim-1-j,i,dim)] = src[RIDX(i,j,dim)];
return;
}
目标:使用代码优化技术使旋转操作运行的更快
平滑操作
void naive_smooth(int dim, pixel *src, pixel *dst) {
int i, j;
for(i=0; i < dim; i++)
for(j=0; j < dim; j++)
dst[RIDX(i,j,dim)] = avg(dim, i, j, src); /* Smooth the (i,j)thpixel */
return;
}
目标:使用代码优化技术使平滑操作运行的更快
性能评判方法
CPE or Cycles per Element
如果一个函数使用C个周期去执行一个大小为N*N的图像,那么CPE=C/(N*N),因此CPE越小越好
如何定义函数
在kernel.c中有rotate的实现方法,我们需要添加自己的rotate实现,函数名自己命名,然后通过
void register_rotate_functions() {
add_rotate_function(&rotate, rotate_descr);
add_rotate_function(&my_rotate,my_rotate_descr);
}
把自己实现的函数注册进去
编码规则
只能用ANSI C,不能用嵌入式汇编
不能修改测量时间的机制(CPE)
只能修改kernels.c,可以定义宏,全局变量,函数
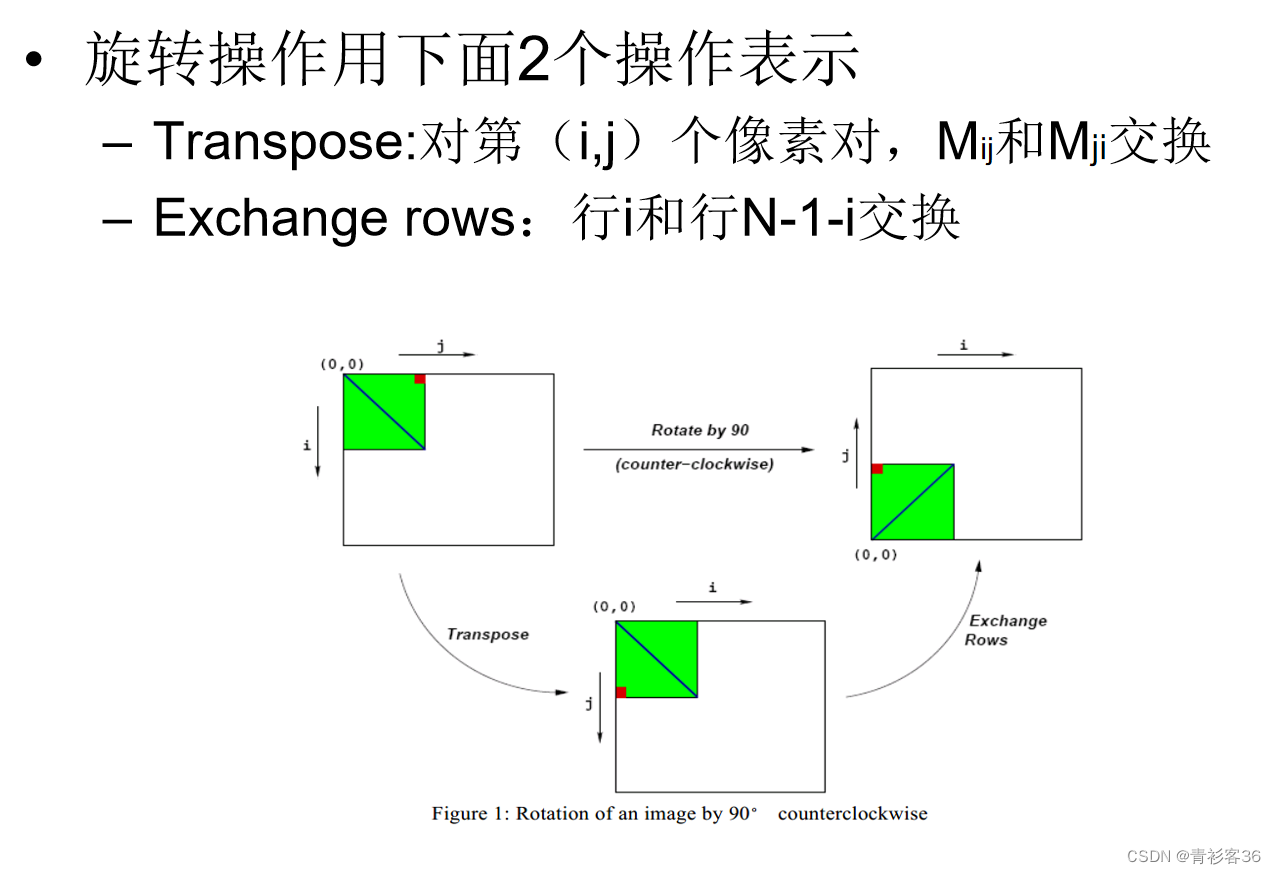
旋转
在旋转过程中,源图像(src)的每一列被逆序复制到目标图像(dst)的每一行。因此,源图像的左上角(src[0])被复制到目标图像的左下角(dst[0]),源图像的第二列的顶部(src[dim])被复制到目标图像的第二行的底部(dst[1]),以此类推。
这是通过以下步骤完成的:
-
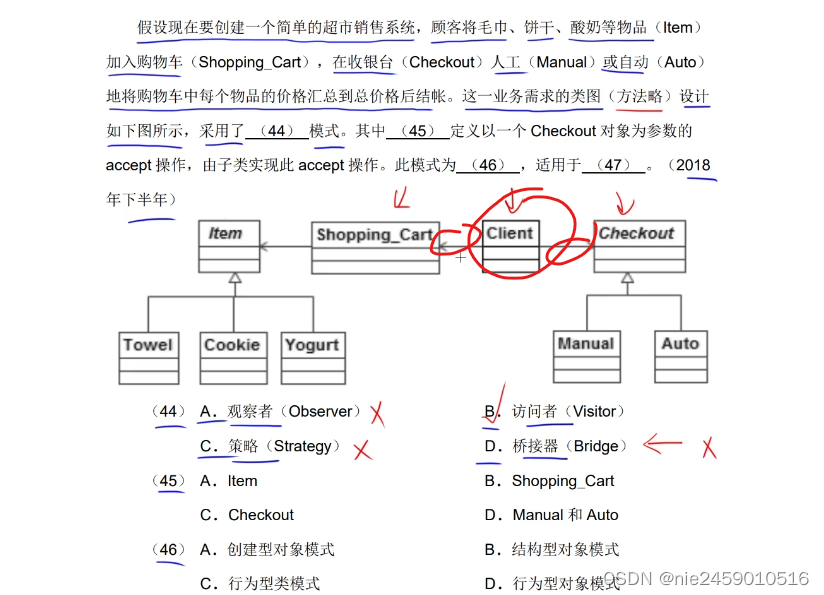
初始时,dst指针被移动到目标图像的底部(dst += (dim * dim - dim))。
-
然后,开始两层循环。外层循环按32像素的步长遍历源图像的列(i);内层循环遍历每列的所有像素(j)。
-
在内层循环中,源图像的每一列(src[i])被逆序复制到目标图像的对应行(dst[j])。这是通过将src的当前元素复制到dst的当前元素,然后递增src指针(src++)并递减dst指针(dst -= dim)实现的。这样,dst指针总是指向目标图像的上一行,而src指针总是指向源图像的下一列。
-
在外层循环的每次迭代结束时,src和dst指针都被调整,以便在下一次迭代中处理源图像的下一组32列和目标图像的下一组32行。
因此,这段代码实现了将源图像旋转90度并复制到目标图像的功能。
/*
* rotate - Your current working version of rotate
* IMPORTANT: This is the version you will be graded on
*/
char rotate_descr[] = "rotate: Current working version";
void rotate(int dim, pixel *src, pixel *dst)
{
// naive_rotate(dim, src, dst);
int i, j;
dst += (dim * dim - dim); // dst指针被移动到目标图像的底部
for (i = 0; i < dim; i += 32)
{
for (j = 0; j < dim; j++)
{
dst[0] = src[0];
dst[1] = src[dim];
dst[2] = src[2 * dim];
dst[3] = src[3 * dim];
dst[4] = src[4 * dim];
dst[5] = src[5 * dim];
dst[6] = src[6 * dim];
dst[7] = src[7 * dim];
dst[8] = src[8 * dim];
dst[9] = src[9 * dim];
dst[10] = src[10 * dim];
dst[11] = src[11 * dim];
dst[12] = src[12 * dim];
dst[13] = src[13 * dim];
dst[14] = src[14 * dim];
dst[15] = src[15 * dim];
dst[16] = src[16 * dim];
dst[17] = src[17 * dim];
dst[18] = src[18 * dim];
dst[19] = src[19 * dim];
dst[20] = src[20 * dim];
dst[21] = src[21 * dim];
dst[22] = src[22 * dim];
dst[23] = src[23 * dim];
dst[24] = src[24 * dim];
dst[25] = src[25 * dim];
dst[26] = src[26 * dim];
dst[27] = src[27 * dim];
dst[28] = src[28 * dim];
dst[29] = src[29 * dim];
dst[30] = src[30 * dim];
dst[31] = src[31 * dim];
src++; // src指针指向源图像的下一列
dst -= dim; // dst指针指向目标图像的上一行
}
// 源图像的下一组32列
src += 31 * dim;
// 目标图像的下一组32行
dst += dim * dim + 32;
}
}平滑
smooth函数的目标是通过对每个像素及其邻近像素的平均值来“平滑”图像,因为它降低了像素与像素之间颜色的突变,使得图像的颜色变得更为均匀。其中涉及到处理图像边界(角落和边缘)的特殊情况,因为这些像素的邻近像素较少。对于图像的其他部分,smooth会计算每个像素及其8个邻居的平均值,并将该平均值分配给输出图像的相应像素。
/*
* smooth - Your current working version of smooth.
* IMPORTANT: This is the version you will be graded on
*/
char smooth_descr[] = "smooth: Current working version";
void smooth(int dim, pixel *src, pixel *dst)
{
// naive_smooth(dim, src, dst);
int i, j, myJ;
// 处理四个角
dst[0].red = (src[0].red + src[1].red + src[dim].red + src[dim + 1].red) >> 2;
dst[0].blue = (src[0].blue + src[1].blue + src[dim].blue + src[dim + 1].blue) >> 2;
dst[0].green = (src[0].green + src[1].green + src[dim].green + src[dim + 1].green) >> 2;
i = dim * 2 - 1;
dst[dim - 1].red = (src[dim - 2].red + src[dim - 1].red + src[i - 1].red + src[i].red) >> 2;
dst[dim - 1].blue = (src[dim - 2].blue + src[dim - 1].blue + src[i - 1].blue + src[i].blue) >> 2;
dst[dim - 1].green = (src[dim - 2].green + src[dim - 1].green + src[i - 1].green + src[i].green) >> 2;
j = dim * (dim - 1);
i = dim * (dim - 2);
dst[j].red = (src[j].red + src[j + 1].red + src[i].red + src[i + 1].red) >> 2;
dst[j].blue = (src[j].blue + src[j + 1].blue + src[i].blue + src[i + 1].blue) >> 2;
dst[j].green = (src[j].green + src[j + 1].green + src[i].green + src[i + 1].green) >> 2;
j = dim * dim - 1;
i = dim * (dim - 1) - 1;
dst[j].red = (src[j - 1].red + src[j].red + src[i - 1].red + src[i].red) >> 2;
dst[j].blue = (src[j - 1].blue + src[j].blue + src[i - 1].blue + src[i].blue) >> 2;
dst[j].green = (src[j - 1].green + src[j].green + src[i - 1].green + src[i].green) >> 2;
// 处理四个边
// 上
i = dim - 1;
for (j = 1; j < i; j++)
{
dst[j].red = (src[j].red + src[j - 1].red + src[j + 1].red + src[j + dim].red + src[j + 1 + dim].red + src[j - 1 + dim].red) / 6;
dst[j].green = (src[j].green + src[j - 1].green + src[j + 1].green + src[j + dim].green + src[j + 1 + dim].green + src[j - 1 + dim].green) / 6;
dst[j].blue = (src[j].blue + src[j - 1].blue + src[j + 1].blue + src[j + dim].blue + src[j + 1 + dim].blue + src[j - 1 + dim].blue) / 6;
}
// 下
i = dim * dim - 1;
for (j = i - dim + 2; j < i; j++)
{
dst[j].red = (src[j].red + src[j - 1].red + src[j + 1].red + src[j - dim].red + src[j + 1 - dim].red + src[j - 1 - dim].red) / 6;
dst[j].green = (src[j].green + src[j - 1].green + src[j + 1].green + src[j - dim].green + src[j + 1 - dim].green + src[j - 1 - dim].green) / 6;
dst[j].blue = (src[j].blue + src[j - 1].blue + src[j + 1].blue + src[j - dim].blue + src[j + 1 - dim].blue + src[j - 1 - dim].blue) / 6;
}
// 右
for (j = dim + dim - 1; j < dim * dim - 1; j += dim)
{
dst[j].red = (src[j].red + src[j - 1].red + src[j - dim].red + src[j + dim].red + src[j - dim - 1].red + src[j - 1 + dim].red) / 6;
dst[j].green = (src[j].green + src[j - 1].green + src[j - dim].green + src[j + dim].green + src[j - dim - 1].green + src[j - 1 + dim].green) / 6;
dst[j].blue = (src[j].blue + src[j - 1].blue + src[j - dim].blue + src[j + dim].blue + src[j - dim - 1].blue + src[j - 1 + dim].blue) / 6;
}
// 左
i = i - (dim - 1);
for (j = dim; j < i; j += dim)
{
dst[j].red = (src[j].red + src[j - dim].red + src[j + 1].red + src[j + dim].red + src[j + 1 + dim].red + src[j - dim + 1].red) / 6;
dst[j].green = (src[j].green + src[j - dim].green + src[j + 1].green + src[j + dim].green + src[j + 1 + dim].green + src[j - dim + 1].green) / 6;
dst[j].blue = (src[j].blue + src[j - dim].blue + src[j + 1].blue + src[j + dim].blue + src[j + 1 + dim].blue + src[j - dim + 1].blue) / 6;
}
// 处理中间部分
myJ = dim; // 第二行的第一个元素
for (i = 1; i < dim - 1; i++)
{
for (j = 1; j < dim - 1; j++)
{
myJ++;
dst[myJ].red = (src[myJ - 1].red + src[myJ].red + src[myJ + 1].red + src[myJ - dim - 1].red + src[myJ - dim].red + src[myJ - dim + 1].red + src[myJ + dim - 1].red + src[myJ + dim].red + src[myJ + dim + 1].red) / 9;
dst[myJ].green = (src[myJ - 1].green + src[myJ].green + src[myJ + 1].green + src[myJ - dim - 1].green + src[myJ - dim].green + src[myJ - dim + 1].green + src[myJ + dim - 1].green + src[myJ + dim].green + src[myJ + dim + 1].green) / 9;
dst[myJ].blue = (src[myJ - 1].blue + src[myJ].blue + src[myJ + 1].blue + src[myJ - dim - 1].blue + src[myJ - dim].blue + src[myJ - dim + 1].blue + src[myJ + dim - 1].blue + src[myJ + dim].blue + src[myJ + dim + 1].blue) / 9;
}
// 跳过这一行的最后一个像素和下一行的第一个像素
myJ += 2;
}
}运行时要将kernels.c文件中的以下三处修改为自己的信息
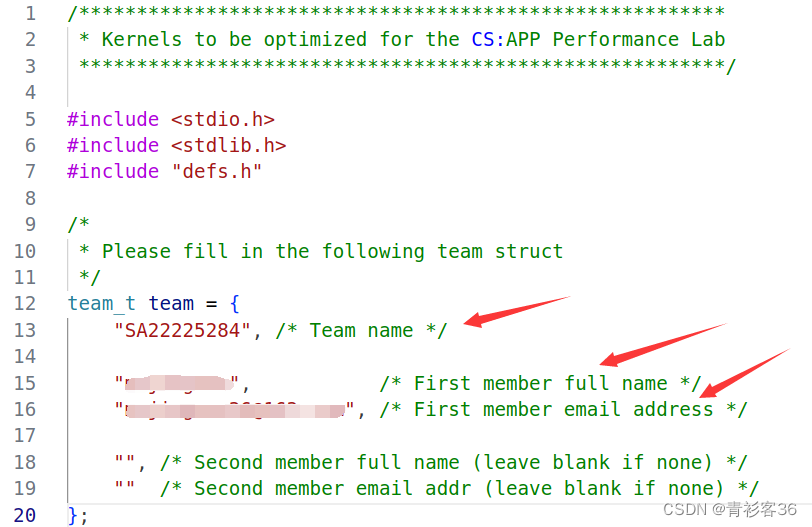
然后依次执行
make driver./driver 


![学习open62541 --- [77] 修改String类型变量的注意点](https://img-blog.csdnimg.cn/c36b559c10354afd93dabfb60772fbb0.png)




![[CTF/网络安全] 攻防世界 command_execution 解题详析](https://img-blog.csdnimg.cn/0f3d2a3d813a48318d09c20a07995b56.png#pic_center)