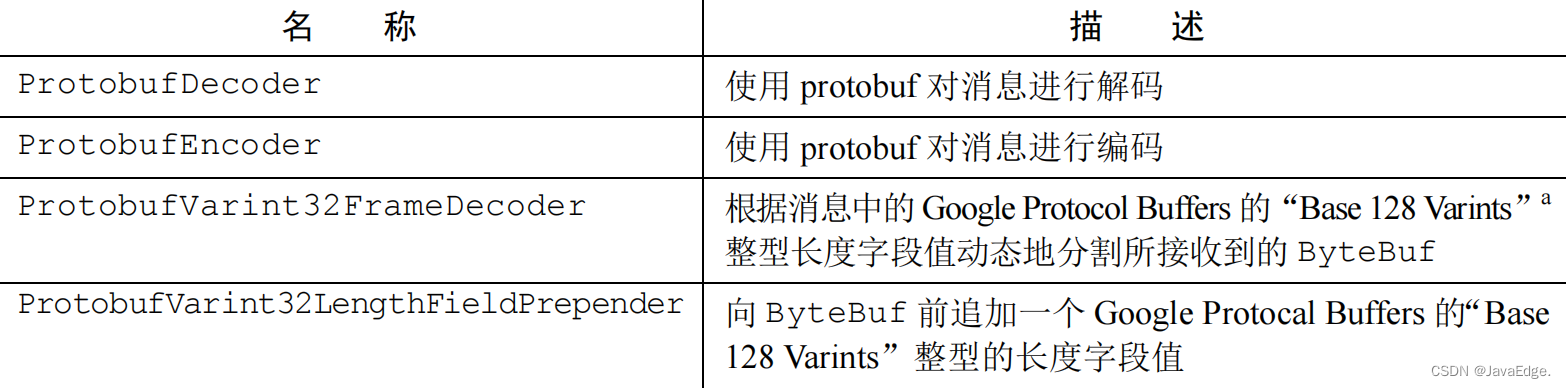
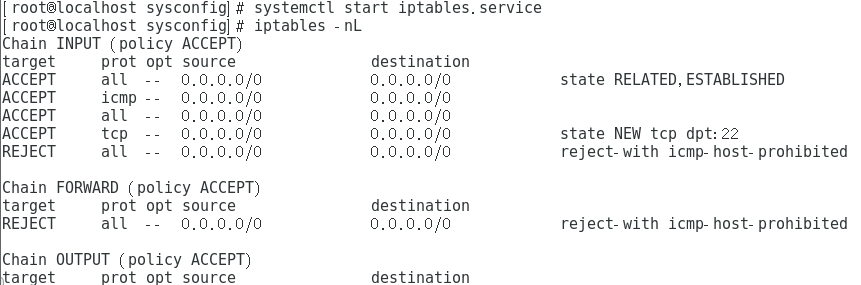
1. 解决了什么问题?
DETR3D 为端到端的 3D 目标检测提供了一个思路。但是,DETR3D 中的 2D 到 3D 的变换会带来一些问题。
- Reference point 的预测坐标可能不够准确,采样特征可能位于目标区域之外;
- 只有映射点周围的特征会被选取,无法从全局角度学习特征;
- 特征采样过程复杂,很难实际应用。
所以,要想摆脱 2D-to-3D 变换和特征采样,构建一个在线端到端的 3D 检测器仍是一个难题。
2. 提出了什么方法?
对于上述问题,作者基于 DETR 设计了一个简单而优雅的方案。通过编码 3D position embedding,将多相机的 2D 特征变换为 3D 特征,这样 object query 直接在 3D 环境下更新。作者提出了 position embedding transformation(PETR),将 3D 位置信息编码到图像特征中,输出特征就带有了 3D 位置信息。这样 object queries 能感知到 3D 位置特征,实现端到端的目标检测。
下图比较了 DETR、DETR3D 和 PETR。在 DETR 中,object query 和 2D 特征相互作用,完成 2D 检测。DETR3D 将预测的 3D reference points 投影到图像平面,采样投影点附近的 2D 特征,然后在 decoder 里面和 object queries 相互作用,重复这一过程,不断地优化。PETR 会输出带有 3D 位置信息的特征,将 3D position embedding 编码进 2D 图像特征中。Object queries 直接和带有 3D 位置的特征发生作用,输出 3D 预测结果。

2.1 整体架构
给定
N
N
N个相机视角的图像
I
=
{
I
i
∈
R
3
×
H
I
×
W
I
,
i
=
1
,
2
,
.
.
.
,
N
}
I=\lbrace I_i\in \mathcal{R}^{3\times H_I \times W_I},i=1,2,...,N \rbrace
I={Ii∈R3×HI×WI,i=1,2,...,N},输入进主干网络(ResNet-50)提取 2D 多角度特征
F
2
d
=
{
F
i
2
d
∈
R
C
×
H
F
×
W
F
,
i
=
1
,
2
,
.
.
.
,
N
}
F^{2d}=\lbrace F_i^{2d}\in \mathcal{R}^{C\times H_F \times W_F}, i=1,2,...,N \rbrace
F2d={Fi2d∈RC×HF×WF,i=1,2,...,N}。在 3D coordinate generator 中,相机视锥空间(camera frustum space)首先会离散为一个 3D meshgrid,然后通过相机参数转换该 meshgrid 的坐标,生成 3D 世界坐标系的坐标。将 3D 坐标和多视角的 2D 特征一起输入 3D position encoder,输出带有 3D 位置的特征
F
3
d
=
{
F
i
3
d
∈
R
C
×
H
F
×
W
F
,
i
=
1
,
2
,
.
.
.
,
N
}
F^{3d}=\lbrace F_i^{3d}\in \mathcal{R}^{C\times H_F\times W_F}, i=1,2,...,N \rbrace
F3d={Fi3d∈RC×HF×WF,i=1,2,...,N}。然后将
F
3
d
F^{3d}
F3d 输入 transformer decoder,更新由 query generator 提出的 object queries。最后用这些 object queries 来预测目标的类别和 3D 边框。

2.2 3D Coordinate Generator
为了在 2D 图像和 3D 空间之间建立联系,我们将相机视锥空间的点映射到 3D 空间,这两个空间是一一对应的。首先离散化视锥空间,生成一个大小是
(
W
F
,
H
F
,
D
)
(W_F,H_F,D)
(WF,HF,D) 的 meshgrid。Meshgrid 中的每一个点可以表示为
p
j
m
=
(
u
j
×
d
j
,
v
j
×
d
j
,
d
j
,
1
)
T
p_j^m=(u_j\times d_j, v_j\times d_j, d_j, 1)^T
pjm=(uj×dj,vj×dj,dj,1)T,
(
u
j
,
v
j
)
(u_j, v_j)
(uj,vj)是图像中的像素坐标,
d
j
d_j
dj是垂直于相机平面的深度值。不同的相机视角会共享这个 meshgrid,3D 空间对应的坐标
p
i
,
j
3
d
=
(
x
i
,
j
,
y
i
,
j
,
z
i
,
j
,
1
)
T
p_{i,j}^{3d}=(x_{i,j},y_{i,j},z_{i,j},1)^T
pi,j3d=(xi,j,yi,j,zi,j,1)T可通过 3D 逆映射计算得到:
p
i
,
j
3
d
=
K
i
−
1
p
j
m
p^{3d}_{i,j}=K_i^{-1} p_{j}^m
pi,j3d=Ki−1pjm
其中
K
i
∈
R
4
×
4
K_i\in \mathcal{R}^{4\times 4}
Ki∈R4×4是第
i
i
i个相机视角的变换矩阵,执行从 3D 世界坐标系到相机视锥空间的变换。下面进一步归一化 3D 坐标:
{
x
i
,
j
=
(
x
i
,
j
−
x
m
i
n
)
/
(
x
m
a
x
−
x
m
i
n
)
y
i
,
j
=
(
y
i
,
j
−
y
m
i
n
)
/
(
y
m
a
x
−
y
m
i
n
)
z
i
,
j
=
(
z
i
,
j
−
z
m
i
n
)
/
(
z
m
a
x
−
z
m
i
n
)
\left\{ \begin{aligned} x_{i,j} & = & (x_{i,j}-x_{min})/(x_{max}-x_{min})\\ y_{i,j} & = & (y_{i,j}-y_{min})/(y_{max}-y_{min})\\ z_{i,j} & = & (z_{i,j}-z_{min})/(z_{max}-z_{min}) \end{aligned} \right.
⎩
⎨
⎧xi,jyi,jzi,j===(xi,j−xmin)/(xmax−xmin)(yi,j−ymin)/(ymax−ymin)(zi,j−zmin)/(zmax−zmin)
其中 [ x m i n , y m i n , z m i n , x m a x , y m a x , z m a x ] \left[ x_{min}, y_{min}, z_{min}, x_{max}, y_{max}, z_{max}\right] [xmin,ymin,zmin,xmax,ymax,zmax]是 3D 世界坐标系中的兴趣区域。这 H F × W F × D H_F\times W_F\times D HF×WF×D个点经过归一化的坐标最终被转置为 P 3 d = { P i 3 d ∈ R ( D × 4 ) × H F × W F , i = 1 , 2 , . . . , N } . P^{3d}=\lbrace P_i^{3d}\in \mathcal{R}^{(D\times 4)\times H_F \times W_F},i=1,2,...,N \rbrace. P3d={Pi3d∈R(D×4)×HF×WF,i=1,2,...,N}.
2.3 3D Position Encoder
3D position encoder 将 2D 图像特征 F 2 d = { F i 2 d ∈ R C × H F × W F , i = 1 , 2 , . . . , N } F^{2d}=\lbrace F_i^{2d}\in \mathcal{R}^{C\times H_F\times W_F},i=1,2,...,N \rbrace F2d={Fi2d∈RC×HF×WF,i=1,2,...,N}和 3D 位置信息联系起来,得到 3D 特征 F 3 d = { F i 3 d ∈ R C × H F × W F , i = 1 , 2 , . . . , N } F^{3d}=\lbrace F_i^{3d}\in \mathcal{R}^{C\times H_F\times W_F},i=1,2,...,N \rbrace F3d={Fi3d∈RC×HF×WF,i=1,2,...,N}。
F i 3 d = ψ ( F i 2 d , P i 3 d ) , i = 1 , 2 , . . . , N F^{3d}_i=\psi(F_i^{2d},P_i^{3d}),\quad i=1,2,...,N Fi3d=ψ(Fi2d,Pi3d),i=1,2,...,N
其中
ψ
(
⋅
)
\psi(\cdot)
ψ(⋅)是位置编码函数。给定 2D 特征
F
2
d
F^{2d}
F2d和 3D 坐标
P
3
d
P^{3d}
P3d,
P
3
d
P^{3d}
P3d首先输入进一个 MLP,变换为 3D position embedding(3D PE)。然后,
F
2
d
F^{2d}
F2d通过
1
×
1
1\times 1
1×1卷积层做变换,与 3D PE 加起来,得到带有位置信息的 3D 特征。最后,将该 3D 特征作为 key 输入进 transformer decoder。

2.4 Query Generator
借鉴了 Anchor-DETR,根据 uniform distribution 初始化一组 3D 世界坐标系中可学习的 anchors。这些 3D anchors 坐标会输入到一个包含 2 个线性层的 MLP,产生初始的 object queries Q 0 Q_0 Q0。在 3D 空间使用 anchor points 能保证 PETR 收敛。
2.5 Decoder
Decoder 包含了
L
L
L层:
Q
l
=
Ω
l
(
F
3
d
,
Q
l
−
1
)
,
l
=
1
,
.
.
.
,
L
Q_l=\Omega_l(F^{3d}, Q_{l-1}),\quad l=1,...,L
Ql=Ωl(F3d,Ql−1),l=1,...,L
Ω l \Omega_l Ωl是第 l l l个 decoder 层。 Q l ∈ R M × C Q_l\in \mathcal{R}^{M\times C} Ql∈RM×C是第 l l l层更新后的 object queries。 M , C M,C M,C分别是 queries 个数和通道数。在每个 decoder 层内,通过 multi-head attention 和 FFN,object queries 和带有位置的 3D 特征 F 3 d F^{3d} F3d相互作用。经过多轮迭代,object queries 就具备了足够的表征性,可用于后续的预测。
2.6 Head and Loss
检测 head 主要包括分类分支和回归分支。输入是 decoder 输出的 object queries,预测目标类别和 3D 边框。回归分支预测的是关于 anchor points 的相对偏移量。
分类损失使用的是 Focal Loss,3D 边框回归损失用的是 L1 损失。
y
=
(
c
,
b
)
y=(c,b)
y=(c,b)和
y
^
=
(
c
^
,
b
^
)
\hat{y}=(\hat{c},\hat{b})
y^=(c^,b^)表示 ground-truth 集合与预测框集合。使用 Hungarian 算法在 ground-truths 和预测框之间进行标签分配。假设
σ
\sigma
σ是最优分配函数,3D 目标检测的损失函数就是:
L
(
y
,
y
^
)
=
λ
c
l
s
∗
L
c
l
s
(
c
,
σ
(
c
^
)
)
+
L
r
e
g
(
b
,
σ
(
b
^
)
)
)
L(y,\hat{y})=\lambda_{cls}\ast L_{cls}(c,\sigma(\hat{c})) + L_{reg}(b,\sigma(\hat{b})))
L(y,y^)=λcls∗Lcls(c,σ(c^))+Lreg(b,σ(b^)))
λ c l s \lambda_{cls} λcls用于平衡不同的损失。
2.7 实验
2.7.1 数据集和评价度量
使用 nuScenes 基准,用 6 个相机、1 个 LiDAR 和 5 个 Radars 采集。数据集共有 1000 个场景,700 个用于训练,150 个用于验证,150 个用于测试。每个场景有 20 秒的视频帧,每 0.5 秒标注一帧的 3D 边框。本方法提供了以下指标:nuScenes Detection Score(NDS)、mAP、mean Average Translation Error(mATE)、mean Average Scale Error (mASE)、mean Average Orientation Error(mAOE)、mean Average Velocity Error(mAVE)、mean Average Attribute Error(mAAE)。
2.7.2 实现细节
使用 ResNet、Swin-Transformer、VoVNetV2 作为主干网络。C5 特征上采样后,与 C4 特征融合,输出 P4 特征,分辨率是输入大小的 1 / 16 1/16 1/16。
对于 3D coordinate generation,沿着深度轴采样 64 个点。X 轴和 Y 轴的范围是 [ − 61.2 m , 61.2 m ] \left[ -61.2m, 61.2m\right] [−61.2m,61.2m],Z 轴的范围是 [ − 10 m , 10 m ] \left[-10m, 10m \right] [−10m,10m]。3D 世界坐标系的坐标归一化 ∈ [ 0 , 1 ] \in\left[0,1\right] ∈[0,1]。损失函数的 λ c l s = 2.0 \lambda_{cls}=2.0 λcls=2.0。
PETR 使用 AdamW 训练,weight decay 是 0.01 0.01 0.01。初始学习率为 2.0 × 1 0 − 4 2.0\times 10^{-4} 2.0×10−4,采取余弦退火策略。使用了多尺度训练,短边长度随机为 [ 640 , 900 ] \left[640,900\right] [640,900],长边 ≤ 1600 \leq 1600 ≤1600。Ground-truth 实例会在 3D 空间内随机旋转一定角度, [ − 22. 5 ∘ , 22. 5 ∘ ] \left[-22.5^{\circ}, 22.5^{\circ}\right] [−22.5∘,22.5∘]。所有实验在 8 张 V100 卡上训练 24 个 epochs,batch size 为 8。
2.7.3 SOTA 比较

2.8 Ablation
2.8.1 3D Position Embedding
若只用 DETR 中的 2D PE,模型的 mAP 只有
6.9
%
6.9\%
6.9%。若增加一个视角先验(在 PE 中加入 view number)以区分不同的视角,可带来小幅提升。若只用 3D 坐标生成的 3D PE,PETR 取得了
30.5
%
30.5\%
30.5% mAP,说明 3D PE 能提供有效的位置先验。

2.8.2 3D Coordinate Generator
在 3D coordinate generator,相机视锥空间离散化为 3D meshgrid。使用一个 RoI 进一步对 3D 世界坐标系的坐标归一化。下表中,作者尝试了不同的离散方法和兴趣区域范围。Uniform discretization 和 Linear-increasing discretization 表现相近。RoI 范围为 (−61.2m, −61.2m, −10.0m, 61.2m, 61.2m, 10.0m),表现要更好。

2.8.3 3D Position Encoder
3D position encoder 在 2D 特征中编码 3D 位置。相较于不用 MLP,使用 MLP 能提升
4.8
%
4.8\%
4.8% NDS 和
5.3
%
5.3\%
5.3%的 mAP。使用
3
×
3
3\times 3
3×3卷积,模型不会收敛,因为
3
×
3
3\times 3
3×3卷积破坏了 2D 特征和 3D 位置的对应关系。

2.8.4 Query Generator
作者提出了 4 类 anchor points: “None”, “Fix-BEV”, “Fix-3D”, “Learned-3D”。原生的 DETR 直接使用一组可学习参数作为 object queries,没有用 anchor points。
- 不用 anchor points, object query 的全局特征无法让模型收敛。
- “Fix-BEV” 是在 BEV 空间生成的 39 × 39 39\times 39 39×39个固定的 anchor points。
- “Fix-3D” 是在 3D 空间生成的 16 × 16 × 6 16\times 16\times 6 16×16×6个固定的 anchor points。
- “Learnable-3D” 是 3D 空间定义的可学习的 anchor points。
“Learnable-3D” 效果是最好的。另外,anchor points 个数也会有影响,1500 时效果最好,但会增加计算成本。

3. 有什么优点?
PETR 保留了 DETR 端到端的思路,无需复杂的 2D-to-3D 投影以及特征采样。推理时,以离线的方式产生 3D 位置坐标,作为输入 position embedding 使用。