摘要:GaussDB(for MySQL)是华为自研云原生数据库,具有高性能,高扩展,高可靠的特点,完全兼容MySQL协议,自研架构和友好的生态兼容性,可以同时满足数据库管理员、应用开发者、CTO的运维、使用和业务发展需求,本次主要介绍GaussDB(for MySQL)在云原生技术方向上遇到的挑战和未来的发展演进路径。
在2023云数据库技术沙龙 “MySQL x ClickHouse” 专场上,华为云数据库高级产品经理周家恩,为大家分享一下《GaussDB(for MySQL)云原生数据库技术演进和挑战》的一些技术内容。

周家恩,华为云数据库高级产品经理,10年以上数据库技术运维,产品管理经验,先后在多家TOP云厂商任职产品经理,熟悉MySQL,SQL Server等多款数据库管理,维护以及商业运营工作,现任华为云数据库高级产品经理,负责原生数据库GaussDB(for MySQL)产品管理和设计,运营工作。
本文内容根据演讲录音以及PPT整理而成。
大家好,先让我自我介绍一下。目前我在华云数据库团队担任数据库产品经理,主要负责MySQL领域的产品规划。今天我带来的主题是《GaussDB(for MySQL)云原生技术的演进和挑战》。

让我们先来看一下华为数据库的发展历程。可能在许多人的眼中,华为是以硬件起家的公司。但实际上,华为数据库的发展已经开始了十几年,起步非常早。在云这块的话有几个阶段,我们主要分成两条线:开源和云原生数据库。
开源方面,我们涉及到的是RDS和MySQL。而对于云托管,我们早在2014年15年左右就开始了内部业务的使用。此外,我们还推出了云原生数据库,其中包括云原生MySQL。亚马逊在2014年推出后,很多云厂商都不断地在借鉴和学习。在2018年和2019年,我们发布了第一个商用版本。
在我们看来,云原生数据库与存储的可用性、可靠性和性能密切相关。华为的企业级存储在中国市场拥有非常不错的市场占有率,因此我们将云原生数据库与华为的企业级存储紧密融合。随着架构和技术的不断演进,我们在2019年推出的商用版本,这就是我们华为数据库发展的历程。

让我们来了解一下GaussDB(for MySQL)的系统架构。GaussDB(for MySQL)是一款基于存算分离架构的云原生数据库,完全兼容MySQL协议,并由华为自主研发的分布式存储系统作为底层支撑。它采用active架构,相比传统开源架构,不需要备库进行数据同步,从而节省了用户的成本。最关键的一点是,GaussDB(for MySQL)采用日志即数据架构,这一架构最早由亚马逊的Aurora推出。该架构的优势在于优化了MySQL事务提交路径,从而显著提升了整个事务提交的性能。
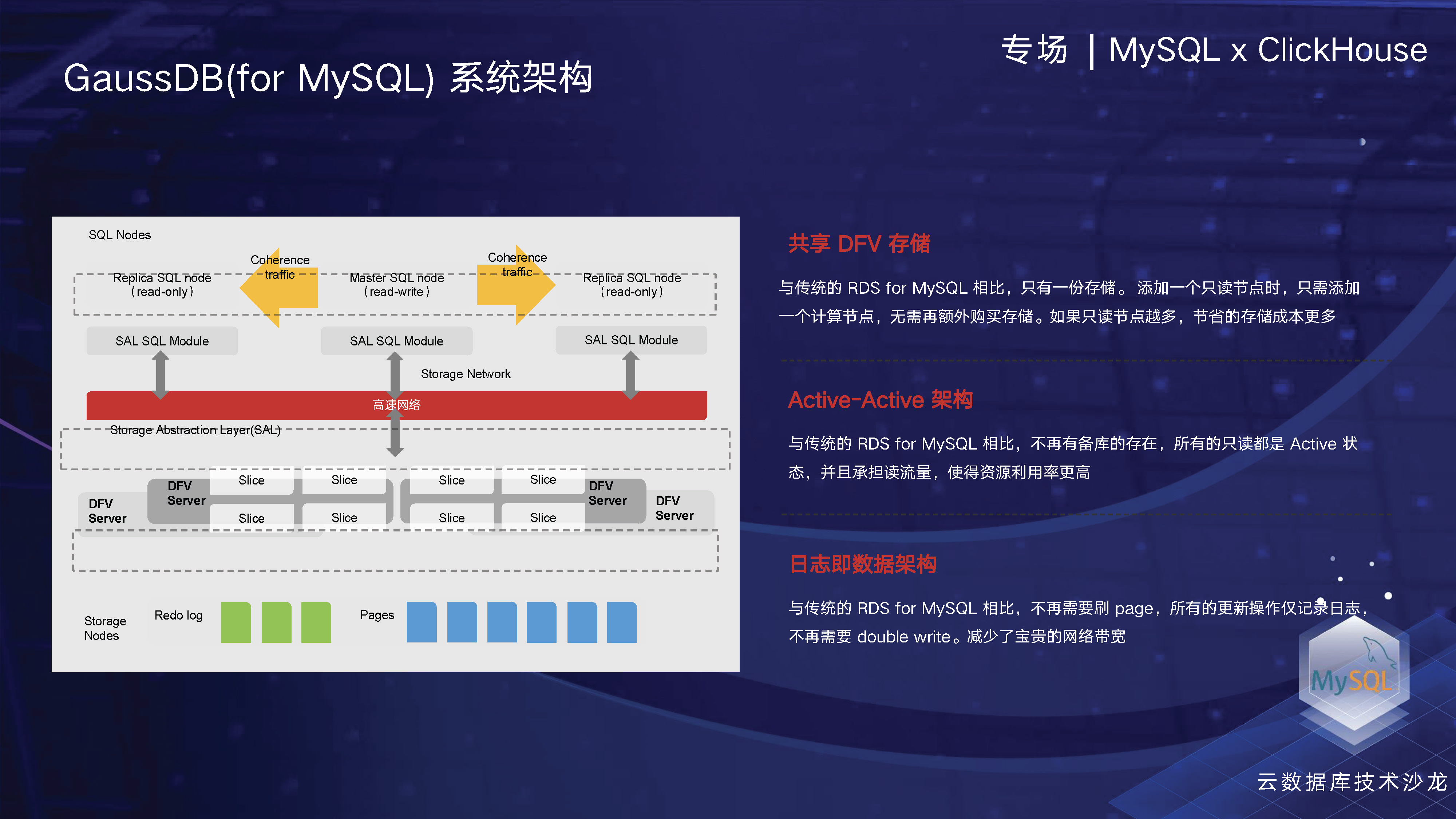
让我们先来了解一下我们在性能方面做了哪些工作。通常来说,云原生数据库在性能方面领先于传统架构。我们经过实测发现,在写入性能方面,我们的性能是开源架构的七倍。这主要归功于我们的架构设计。
我们采用了存算分离架构,不同厂商的设计会有所不同,但我们的设计与亚马逊的Aurora比较相似,可以说华为的架构与亚马逊最接近。我们采用了日志即数据架构,即在整个事务写入时,我们会直接进行REDO落盘即事务提交,不需要再从计算节点刷脏页到磁盘,从而大幅减少了整个事务提交的网络负载和开销。因此,我们的写入性能比开源架构和没有采用这种架构的厂商都要高。
本次活动中我们主要讨论MySQL x ClickHouse,在TPCH领域,我们也做了很多优化工作,并开发了并行查询技术,从而在性能方面取得了很大的提升。
下面看一下我们在性能这块做了一些优化。
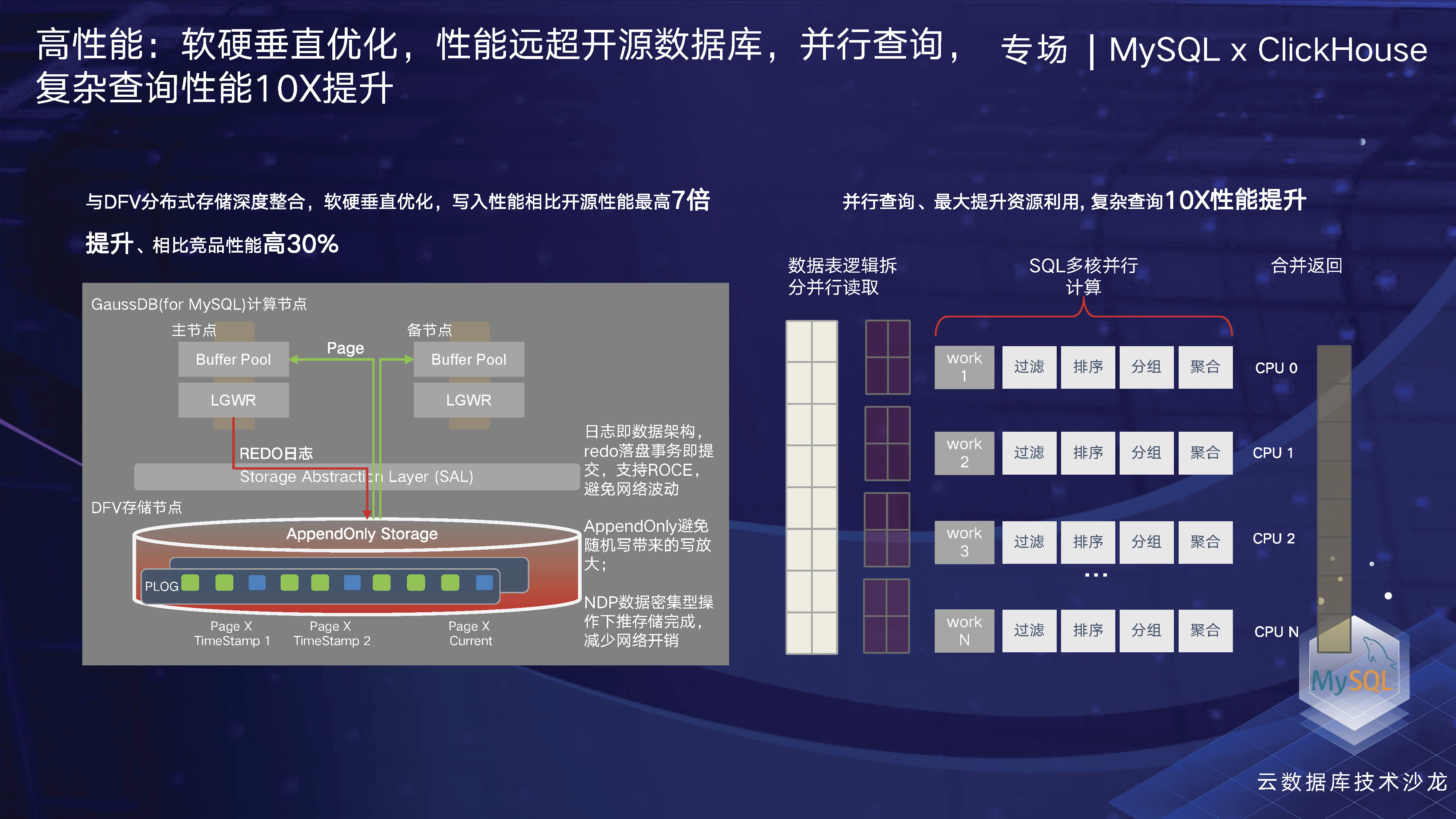
就并行查询而言,目前我们在TPCH的22个SQL中的整体性能提升可以达到26倍。华为在并行查询方面所做的一些工作与其他厂商也稍有不同。
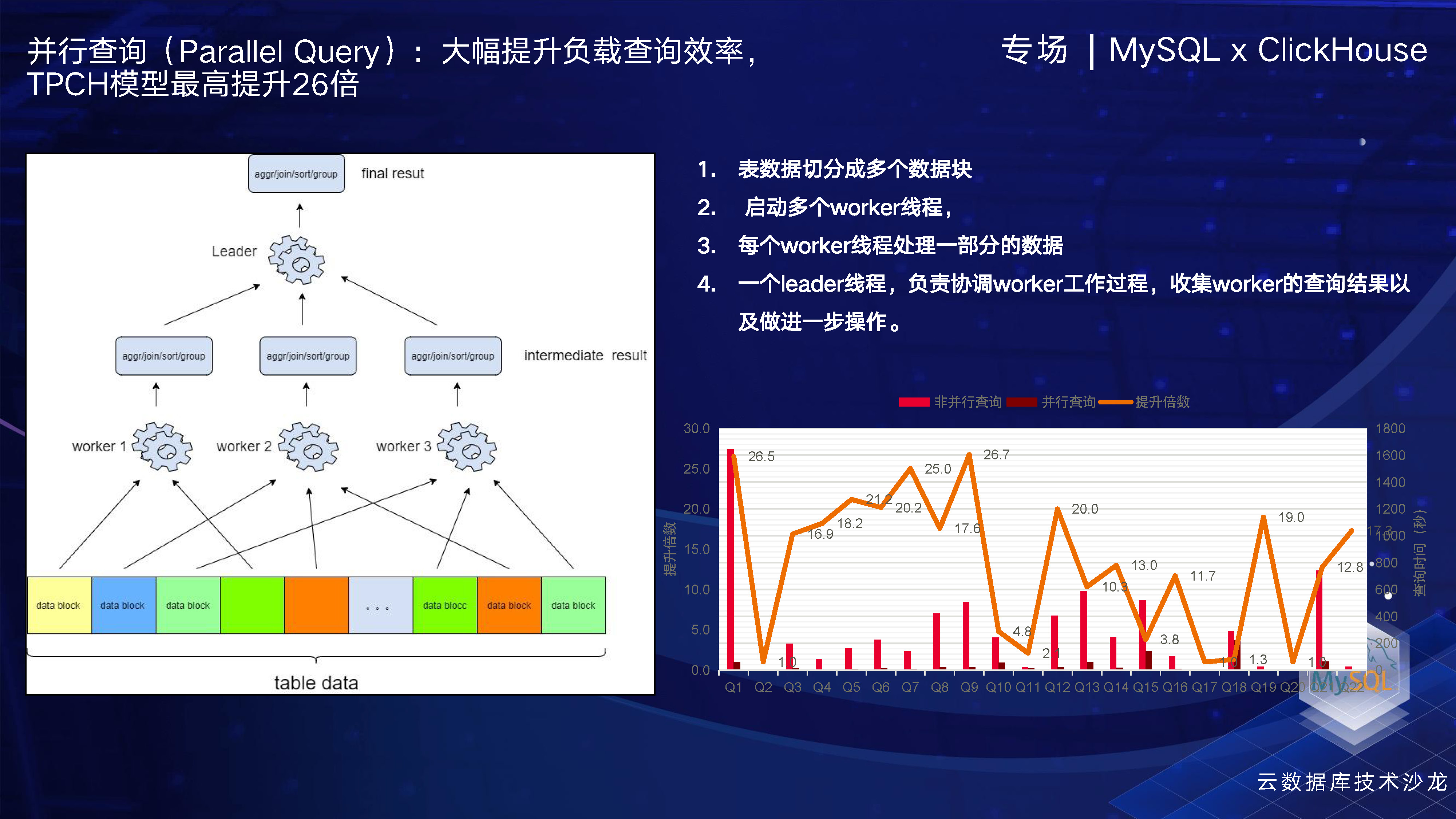
就目前在云原生数据库领域比较大的几家友商来说,例如Aurora,在并行查询这个方面,它是通过将算子下推到存储引擎上来实现的。而亚马逊并不是在SQL引擎这一层面进行并行操作,它主要是充分利用了其分布式存储来提升性能。而像国内其他友商,则主要是在SQL引擎层面进行并行操作。
其实我们做了两个方面的工作。一方面,在SQL引擎层面,我们实现了并行操作,就像上一页所讲的那样。另一方面,我们还实现了NDP算子下推,充分利用了分布式存储的性能,将底层存储资源充分利用起来。我们对复杂的算子、Filter、Projection、谓词包括比较运算等进行了下推优化,同时也对快速列和虚拟列进行了下推。因此,在复杂查询方面,我们称之为“双轮驱动”,这也是我们与其他厂商不同的地方。接下来,看下实际的性能表现。

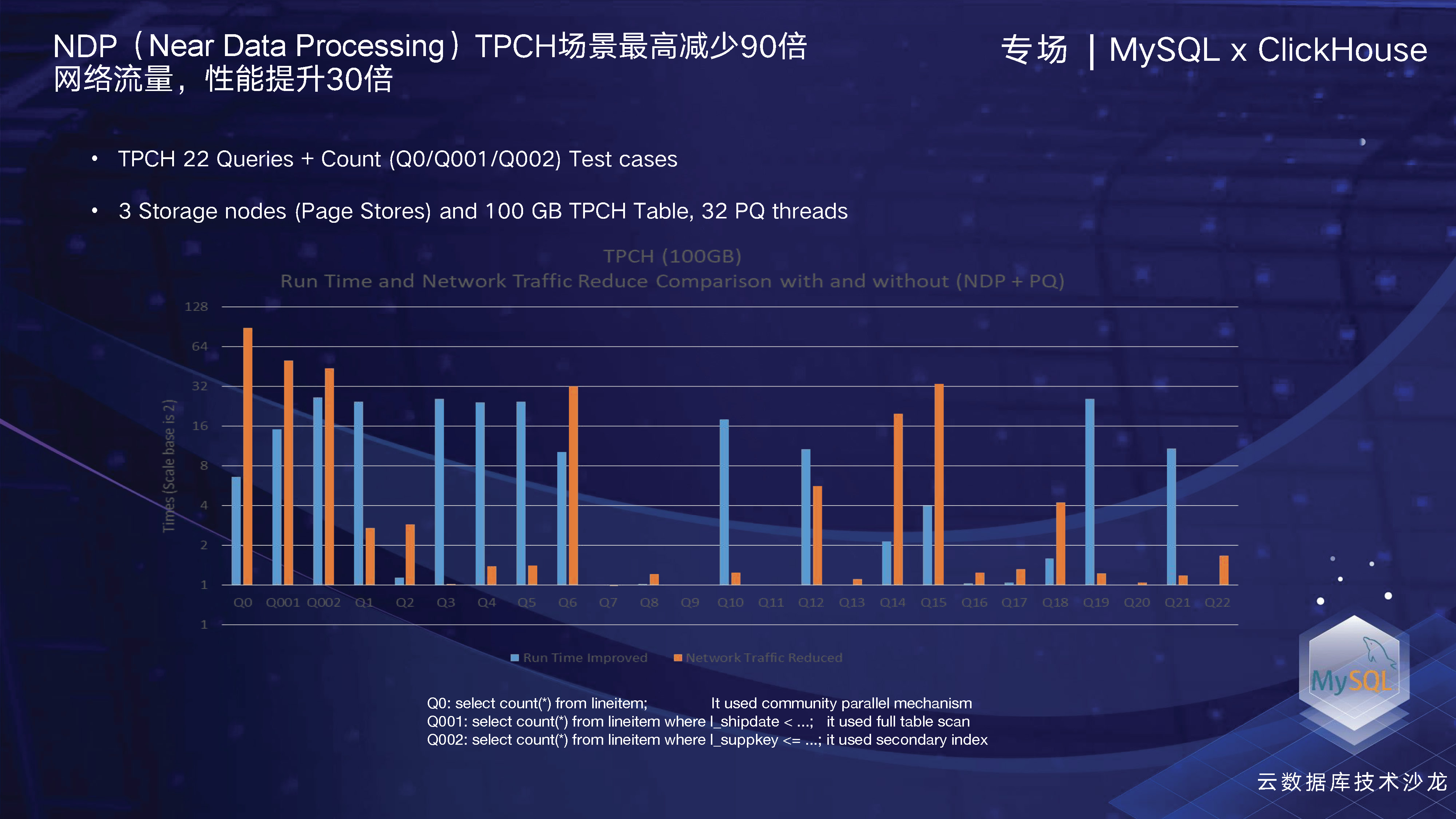
这个就是开启NDP在TPCH场景下的一个性能表现。开启以后,最高场景是可以就是计算到网络之间的开销。开源的MySQL在进行大的复杂查询时,我们需要将数据从磁盘传输到计算层进行计算,会有大量网络开销,而通过算子下推技术,TPCH处理多个SQL时,我们看到网络开销的最高节省率超过90倍。在性能方面,我们测试了NDP+PQ场景,该技术品牌被称为NDPQ。性能表现最高提升高达30倍以上。
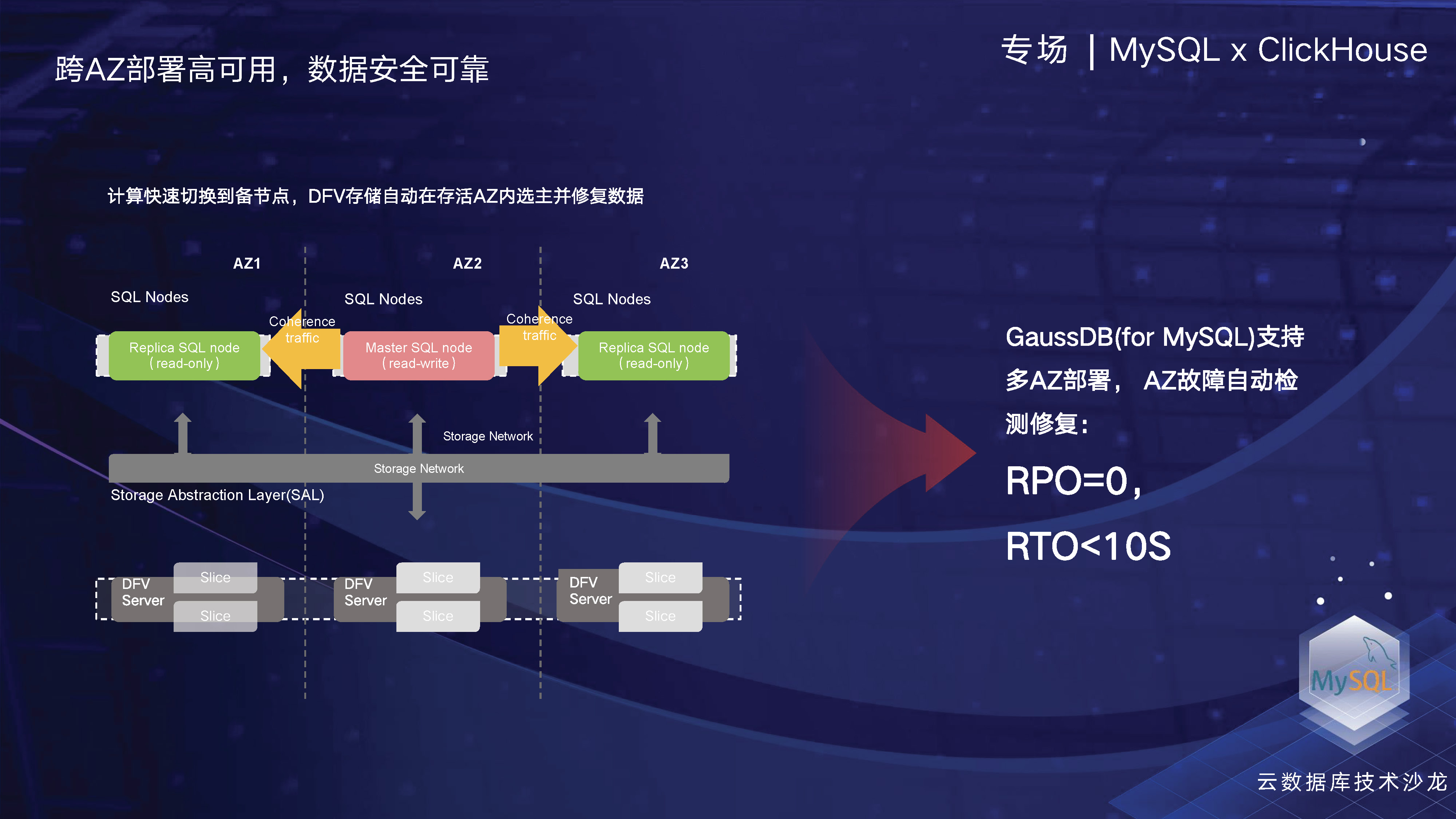
在可用性方面,我们的DFV支持跨AZ能力。目前,华为云国内的主力region包括上海、北京、广州、贵阳、乌兰察布等都支持3AZ部署。未来,3AZ部署也将成为华为云GaussDB(for MySQL)的默认架构。今年我们正在开通的节点中,包括香港、曼谷以及拉美、中东等地区。在欧洲,我们与德国电信和法国电信合作,推动GaussDB(for MySQL)全球化进程。我们的跨AZ能力可以实现RPO=0,保证数据的高可靠性。
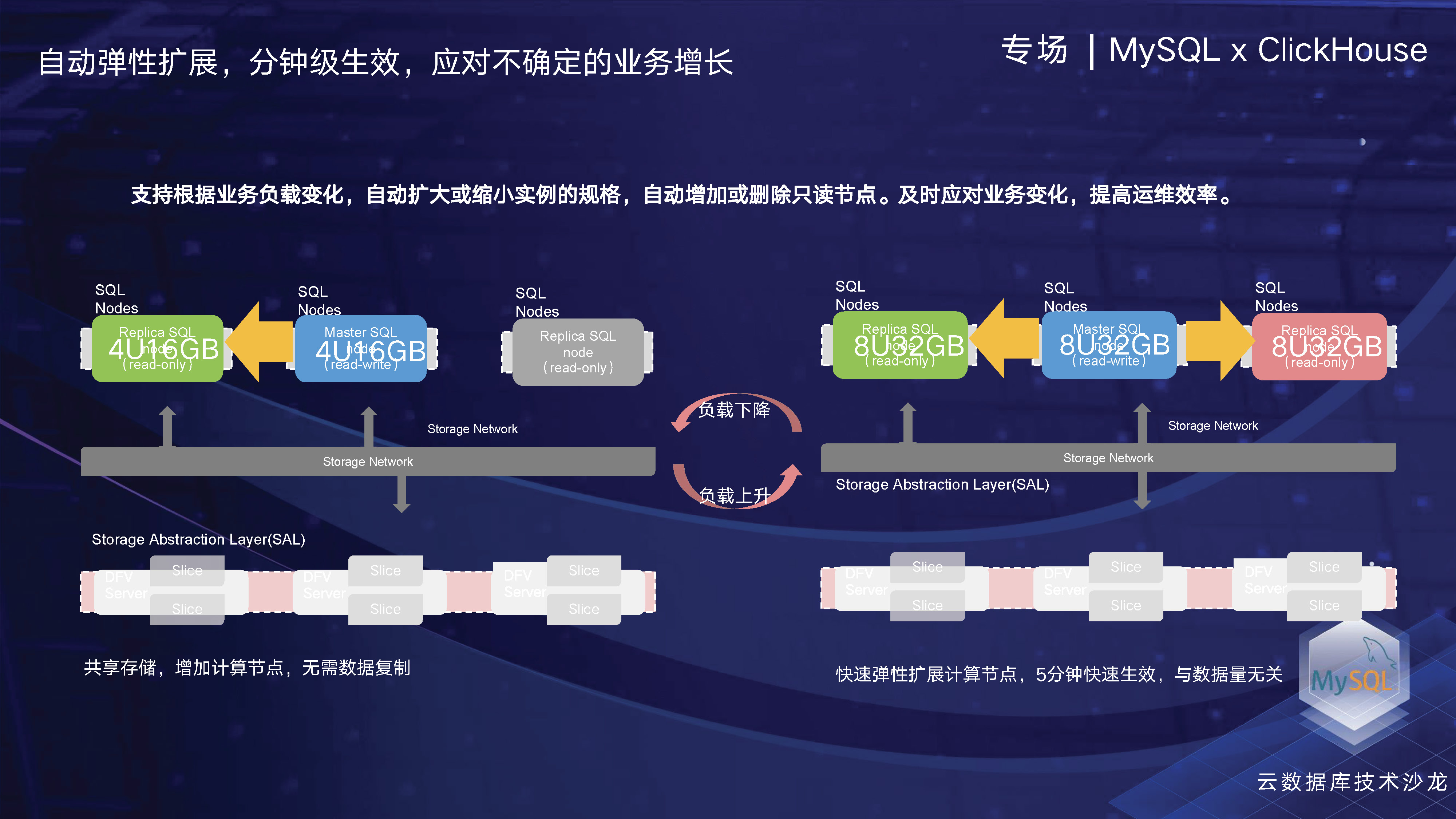
关于扩展性,我们知道在云上使用MySQL数据库,它更适合互联网业务,尤其是互联网、游戏和电商等用户。当然,现在政企客户也越来越多地上云,我们也为此做了节点的自动扩展,以满足更多不同类型客户的需求。目前,我个人觉得现在云有一个非常重要的的趋势发展,其中一个关键的趋势是HTAP。另外,Serverless也是一个重要的趋势。我们可以看到,像亚马逊去年的invent大会上最核心的发布之一,就是所有数据库开始向是Serverless化发展。
在云上除非技术实力特别强之外,用户最关注的问题就是成本。因此,我们提供了一种类似于Serverless的服务,支持按需自动弹性扩展。这是我们早期推出的一个雏形,其中包括自动弹性扩展周期和按需模式。由于采用了存算分离架构,加节点的弹性过程非常快速,一般只需要五到十分钟即可完成。因此,它的速度比传统的MySQL快得多。传统的MySQL在数据量不断增加时,进行规格变更和加节点所需的时间非常长。
在备份方面,我们的存储采用基于AppendOnly模式的DFV存储。我们实现了秒级快照,这是我们自己开发的快照系统。我们进行了测算,发现大约1TB的数据备份恢复只需要三四十分钟即可完成。
我们还将在今年年底推出backtrack功能,该功能基于存储的多版本特性,用户可以在选择的时间点范围内进行回溯操作,往前或往后。我们可以将1TB数据这个级别的回溯时间控制在五分钟以内。

再看数据库代理服务,我们目前支持用户按需购买服务。默认情况下,我们不提供代理服务。如果用户有需求,可以按需购买读写分离服务,无需对其业务进行任何改动即可自动实现读写分离。
我们今年对读写分离进行了大量的优化,其中包括基于负载均衡模式的支持,我们还根据业务特征,支持用户选择最终一致性、会话一致性和全局一致性三种一致性级别。
我们的代理服务支持只读模式和读写模式。如果用户需要在分析型业务和交易型业务之间进行物理隔离,可以选择只读模式。在只读模式下,代理服务会为用户创建不同的只读节点,从而实现对分析业务和交易业务的物理隔离。

接下来介绍我们的HTAP只读分析节点。这是我们在HTAP领域中不断推进的一步。正如我之前所述,我们在复杂查询方面采用了并行查询和算子下推等技术。然而这些还不足以满足所有用户的需求,因为这2个技术本质上仍在同一份数据上进行操作,也就是说还是在整个一套系统里面。
因为大家都知道,在做TPCH这样的场景时,对整个资源的消耗是不可控的。一个分析业务可能会影响到交易型业务。为了解决这个问题,我们开发了只读分析节点,它基于ClickHouse实现。通过CDC模式,我们可以将用户交易数据从GaussDB(for MySQL)同步到ClickHouse。正如之前的嘉宾所介绍的,我们也是采用了基于binlog的方案。
我们目前还处于公测阶段,主要服务于华为内部的终端消费者,例如华为手机、手环和运动健康等业务。这些业务的一部分分析业务已经迁移至我们的只读分析节点上。

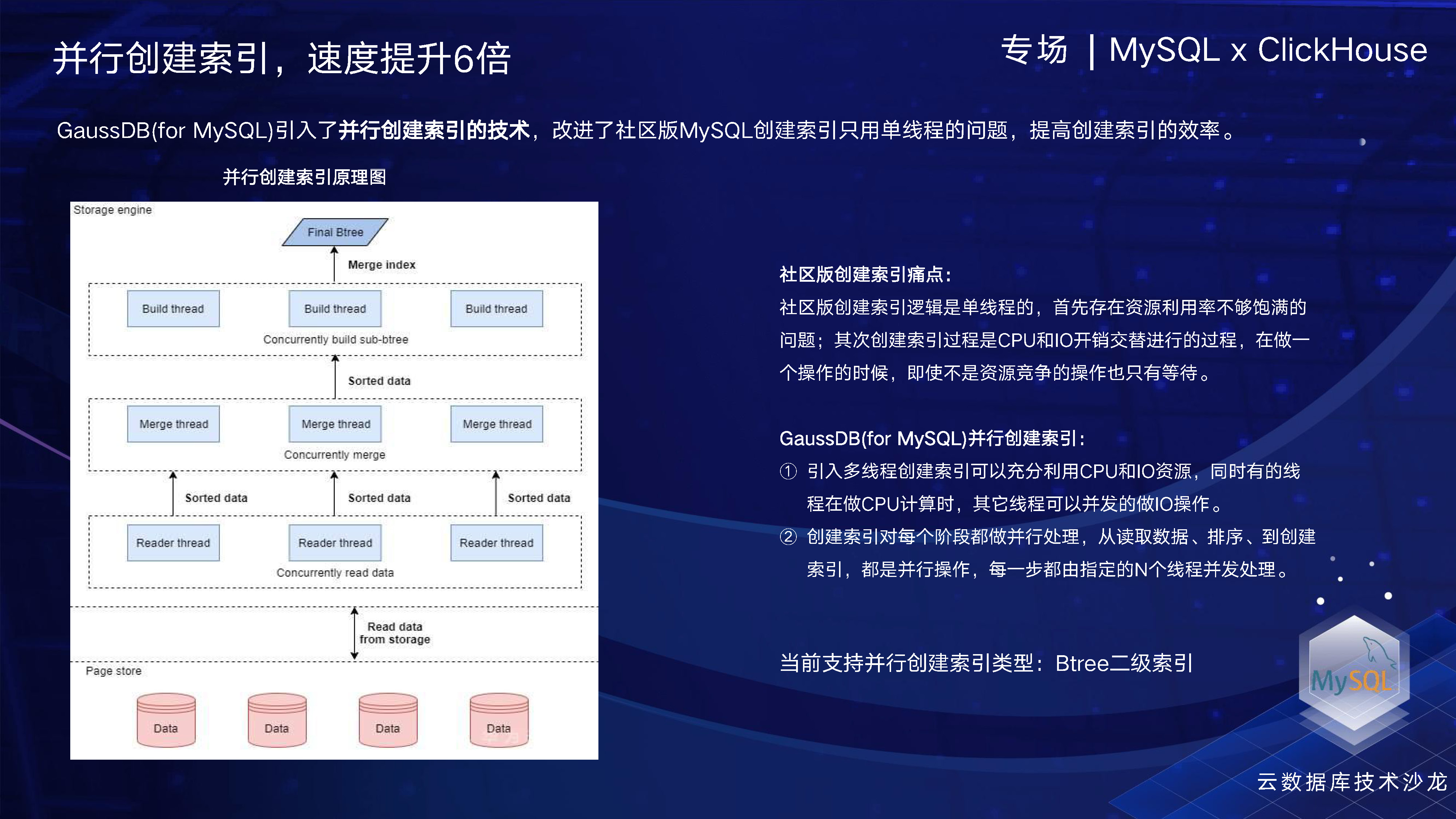
关于并行创建索引,我们都知道社区版的MySQL在创建索引时是单线程操作,无法实现多线程。因此,如果要创建一个较大的索引,耗时会非常高。为了解决这个问题,我们开发了多线程的索引创建功能,多线程被设计用于从存储读取数据、排序以及创建索引等操作。经过测试,该功能相比于开源版本的MySQL,可以提升性能六到七倍。
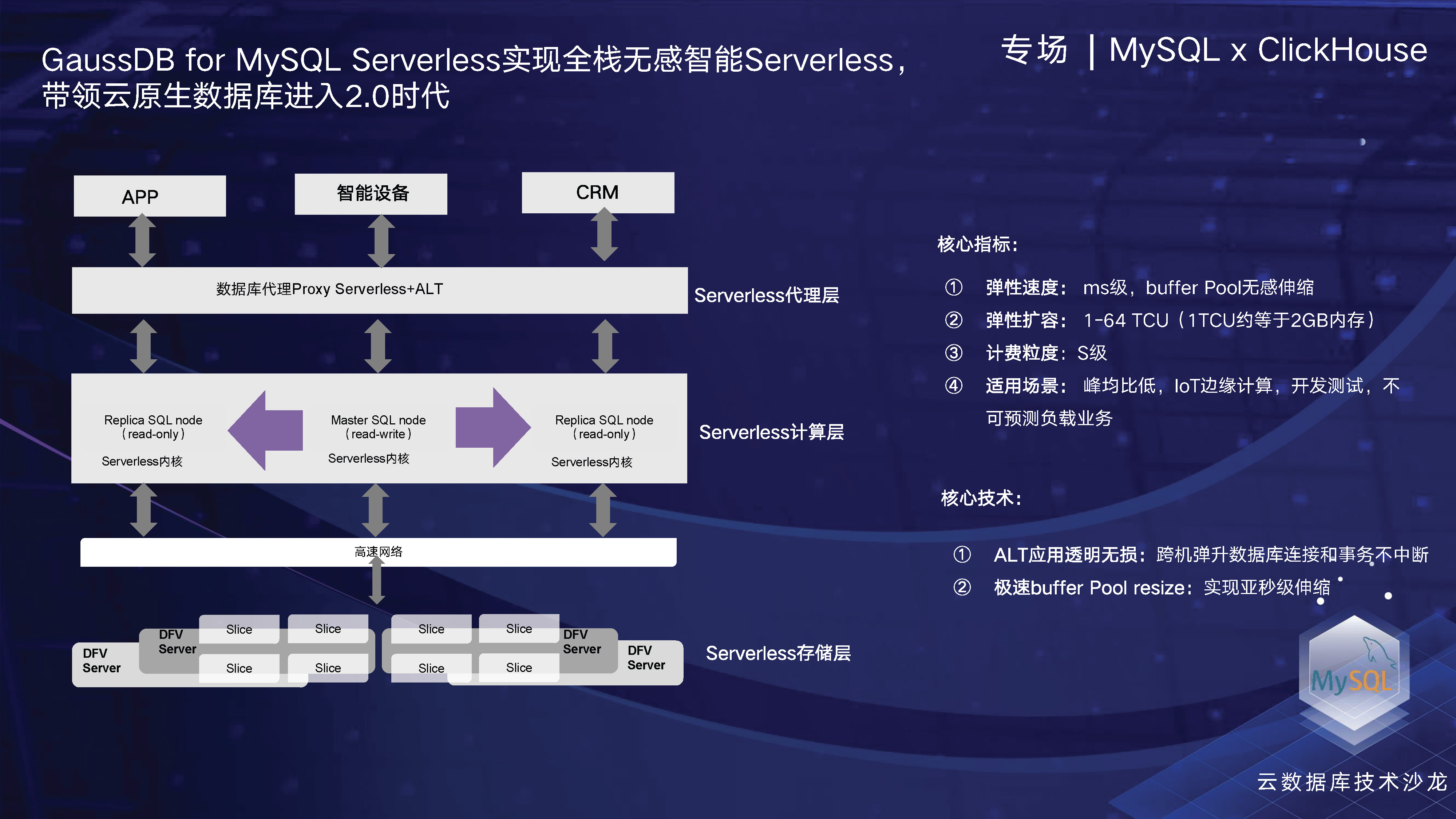
在我们后续产品的演进中,Serverless将是一个非常关键的方向。我们计划在今年上半年(五六月份)进行Serverless的公测,下半年则会正式商用。在Serverless领域,我们已经做了很多探索。目前业内最为出色的Serverless产品是亚马逊的Serverless V2。虽然亚马逊在最初推出的Serverless V1已经引起了不少关注,但它仍存在某些局限性,例如扩缩的粒度和速度可能不够理想。但是随着Serverless V2的推出,它的扩缩粒度可以达到0.5 ACU,而且端到端的感知速度只需十秒钟。因此,当时的亚马逊Serverless V2可以说是引领了整个云原生数据库Serverless的发展趋势。
我们还在技术方面进行了很多创新。其中,我们实现了快速弹性的缓冲池(buffer pool),并在内核层面对其进行了加速。通过这一技术,我们可以实现毫秒级的扩展,从而在端到端的运行过程中,经过内部环境测试后,可在大约十秒钟内(甚至可能更快,大约八秒左右)完成。
我们还探索了一些技术,例如ALT应用透明迁移。在Serverless领域,跨机操作是一个关键点。在单机内,我们可以相对简单地实现弹性伸缩,但是在云上,我们需要考虑如何跨多台物理机运营,如何扩大资源池规模。这带来的问题是资源池水位可能会比较高,在扩展过程中可能会出现资源不足的情况,这时我们需要跨机操作,因此保证迁移的平稳性和不中断就显得尤为重要。我们实现了ALT应用透明迁移技术,通过事务状态保持等方式,实现了平稳迁移。
在Serverless领域,我们已经实现了按需付费的存储,计算层计划在今年五六月份推出,而Serverless代理层预计会在今年年底推出。
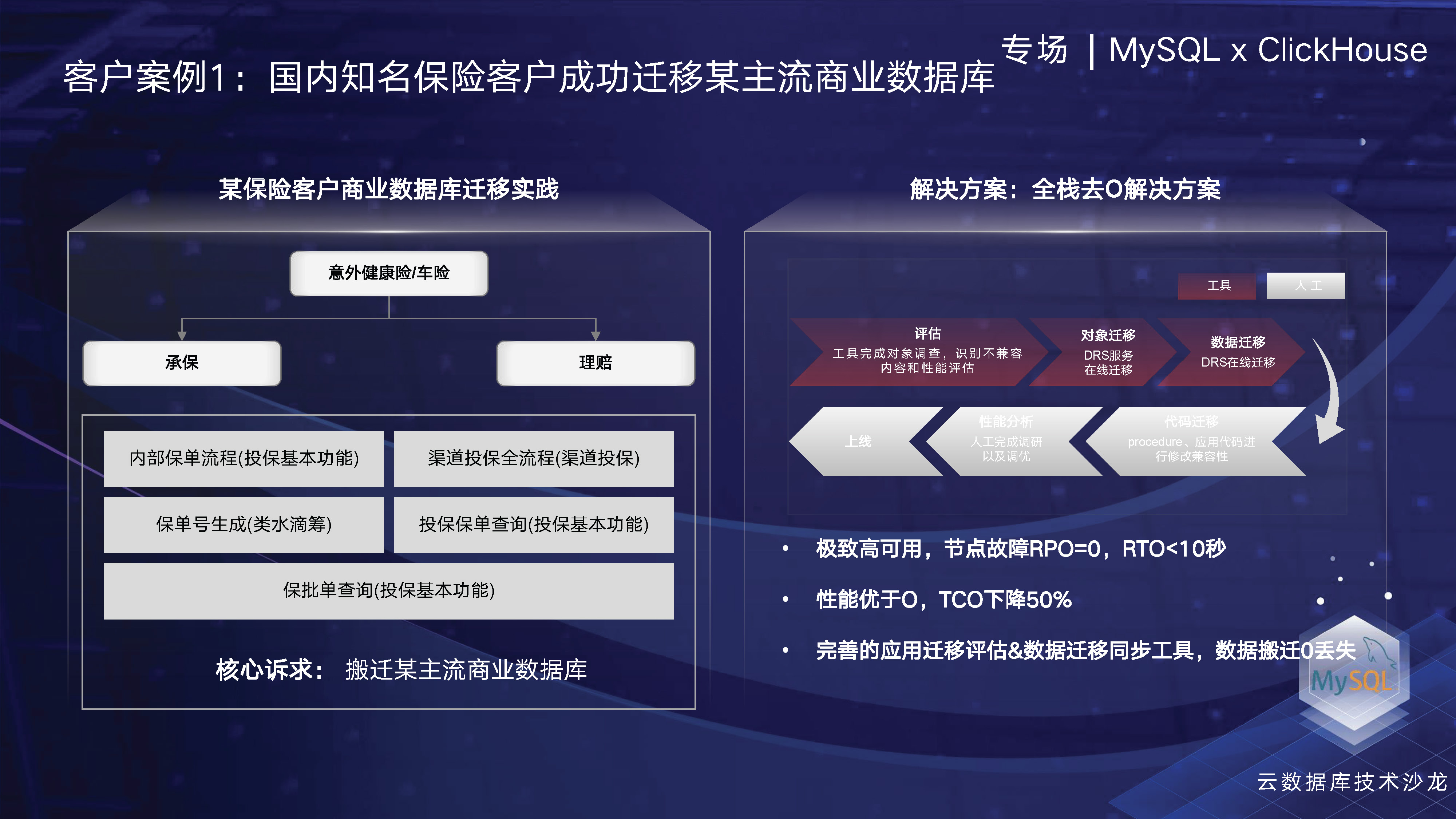
最后再看一下我们的几个案例,其中第一个种子用户是国内比较大的保险公司。他之前使用的是Oracle,但由于国产化的需求和去O的需求,他们选择了我们的服务。由于我们的服务可以部署在公有云上,我们通过一些专家服务和相关工具对该公司业务进行评估,并将其迁移到GaussDB(for MySQL)。迁移完成后,该公司的TCO降低了50%。
我们的另一个案例是华为终端。整个业务规模非常大,涵盖了华为整个手机业务、汽车业务以及应用商店等实例,实例数量可以达到非常大的规模。以前,由于线下的自建数据库存在许多痛点,他们有一个庞大的DBA团队来维护。经常面临可用性和运维相关的问题,以及如果发生切换,可能会面临数据丢失的情况。
迁移到GaussDB(for MySQL)后,他们面临的问题像数据丢失就已经不存在了。此外,我们不断演进,扩展了自动弹性伸缩等特性。让用户的成本降低了40%左右。同时,他们以前使用了商业的分析型数据库软件,也开始逐步使用我们的HTAP分析只读节点,这进一步降低了整体的成本。

好,那我今天分享就到这里,谢谢大家。
本次大会围绕“技术进化,让数据更智能”为主题,汇聚字节跳动、阿里云、玖章算术、华为云、腾讯云、百度的6位数据库领域专家,深入 MySQL x ClickHouse 的实践经验和技术趋势,结合企业级的真实场景落地案例,与广大技术爱好者一起交流分享。