1 写大型数据
因为网络饱和的可能性,如何在异步框架中高效地写大块的数据是特殊问题。由于写操作是非阻塞的,所以即使没有写出所有的数据,写操作也会在完成时返回并通知 ChannelFuture。当这种情况发生时,如果仍然不停地写入,就有内存耗尽的风险。所以在写大型数据时,需要准备好处理到远程节点的连接是慢速连接的情况,这种情况会导致内存释放的延迟。
考虑下将一个文件内容写出到网络。讨论传输(见 4.2 节)的过程中,提到 NIO 的零拷贝,这消除了将文件内容从文件系统移动到网络栈的复制过程。所有的这一切都发生在 Netty 的核心中,所以应用程序所有需要做的就是使用FileRegion接口实现,其在 Netty 的 API 文档中的定义是: “通过支持零拷贝的文件传输的 Channel 来发送的文件区域。”
代码11-11展示如何通过从FileInputStream创建一个DefaultFileRegion,并将其写入Channel(甚至可利用 io.netty.channel.ChannelProgressivePromise实时获取传输的进度),从而利用零拷贝特性来传输一个文件的内容。
package io.netty.example.cp11;
import io.netty.channel.*;
import io.netty.channel.socket.nio.NioSocketChannel;
import java.io.File;
import java.io.FileInputStream;
/**
* Listing 11.11 使用 FileRegion 传输文件的内容
*/
public class FileRegionWriteHandler extends ChannelInboundHandlerAdapter {
private static final Channel CHANNEL_FROM_SOMEWHERE = new NioSocketChannel();
private static final File FILE_FROM_SOMEWHERE = new File("");
@Override
public void channelActive(final ChannelHandlerContext ctx) throws Exception {
File file = FILE_FROM_SOMEWHERE; //get reference from somewhere
Channel channel = CHANNEL_FROM_SOMEWHERE; //get reference from somewhere
//...
// 创建一个FileInputStream
FileInputStream in = new FileInputStream(file);
// 以该文件的完整长度创建一个新的 DefaultFileRegion
FileRegion region = new DefaultFileRegion(in.getChannel(), 0, file.length());
// 发送该 DefaultFileRegion,并注册一个ChannelFutureListener
channel.writeAndFlush(region).addListener(
new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
if (!future.isSuccess()) {
// 处理失败
Throwable cause = future.cause();
// Do something
}
}
});
}
}
该示例只适用于文件内容的直接传输,不包括应用程序对数据的任何处理。在需要将数据从文件系统复制到用户内存中时,可以使用 ChunkedWriteHandler,它支持异步写大型数据流,而又不会导致大量内存消耗。
关键是 interface ChunkedInput,类型参数 B 是 readChunk()方法返回的类型。Netty 预置该接口的 4 个实现,如表 11-7:
 每个都代表了一个将由 ChunkedWriteHandler 处理的不定长度的数据流。
每个都代表了一个将由 ChunkedWriteHandler 处理的不定长度的数据流。
代码清单 11-12 说明 ChunkedStream 用法,最常用的实现。所示类使用File及SslContext进行实例化。当initChannel()被调用,它将使用所示的 ChannelHandler 链初始化该 Channel。

当 Channel 的状态变为活动的时,WriteStreamHandler 将会逐块地把来自文件中的数据作为 ChunkedStream 写入。数据在传输之前将会由 SslHandler 加密。
package io.netty.example.cp11;
import io.netty.channel.*;
import io.netty.handler.ssl.SslContext;
import io.netty.handler.ssl.SslHandler;
import io.netty.handler.stream.ChunkedStream;
import io.netty.handler.stream.ChunkedWriteHandler;
import java.io.File;
import java.io.FileInputStream;
/**
* 11.12 使用 ChunkedStream 传输文件内容
*/
public class ChunkedWriteHandlerInitializer extends ChannelInitializer<Channel> {
private final File file;
private final SslContext sslCtx;
public ChunkedWriteHandlerInitializer(File file, SslContext sslCtx) {
this.file = file;
this.sslCtx = sslCtx;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
// 将 SslHandler 添加到ChannelPipeline
pipeline.addLast(new SslHandler(sslCtx.newEngine(ch.alloc())));
// 添加 ChunkedWriteHandler以处理作为ChunkedInput传入的数据
pipeline.addLast(new ChunkedWriteHandler());
// 一旦连接建立,WriteStreamHandler就开始写文件数据
pipeline.addLast(new WriteStreamHandler());
}
public final class WriteStreamHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
// 当连接建立时,channelActive()将使用ChunkedInput写文件数据
super.channelActive(ctx);
ctx.writeAndFlush(new ChunkedStream(new FileInputStream(file)));
}
}
}
逐块输入
要使用你自己的 ChunkedInput 实现,请在 ChannelPipeline 中安装一个ChunkedWriteHandler。
本节讨论如何通过使用零拷贝特性来高效地传输文件,以及如何通过使用ChunkedWriteHandler写大型数据而又不必冒OOM风险。下一节研究几种序列化 POJO 方法。
2 序列化数据
JDK 提供了 ObjectOutputStream 和 ObjectInputStream,用于通过网络对 POJO 的基本数据类型和图进行序列化和反序列化。该 API 并不复杂,而且可以被应用于任何实现了java.io.Serializable接口的对象。但其性能也不是非常高效。这节,我们将看到 Netty 必须为此提供什么。
2.1 JDK 序列化
若你的应用程序必须要和使用了ObjectOutputStream、ObjectInputStream的远程节点交互,并且兼容性也是你最关心的,那么JDK序列化将是正确的选择,表11-8列出Nett y提供的用于和JDK进行互操作的序列化类:

CompatibleObjectDecoder类已经在 Netty 3.1 中废弃,并不存在于 Netty 4.x 中:https://issues.jboss.org/browse/NETTY-136
若你能自由使用外部依赖,则JBoss Marshalling将是理想选择:它比JDK序列化最多快3倍,且更紧凑。在JBoss Marshalling官方网站主页的概述对其定义:JBoss Marshalling 是一种可选的序列化 API,它修复 JDK 序列化 API 所发现的许多问题,同时保留与 java.io.Serializable 及其相关类的兼容性,并添加几个新的可调优参数及额外特性,所有这些都能通过工厂配置(如外部序列化器、类/实例查找表、类解析以及对象替换等)实现可插拔的。
2.2 使用 JBoss Marshalling 进行序列化
Netty 通过表11-9所示的两组解码器/编码器对为 Boss Marshalling 提供支持:
- 第一组兼容只使用 JDK 序列化的远程节点
- 第二组提供最大性能,适用于和使用 JBoss Marshalling 的远程节点一起使用

代码11-13展示如何使用 MarshallingDecoder 和 MarshallingEncoder。同样,几乎只是适当地配置 ChannelPipeline。
package io.netty.example.cp11;
import io.netty.channel.*;
import io.netty.handler.codec.marshalling.MarshallerProvider;
import io.netty.handler.codec.marshalling.MarshallingDecoder;
import io.netty.handler.codec.marshalling.MarshallingEncoder;
import io.netty.handler.codec.marshalling.UnmarshallerProvider;
import java.io.Serializable;
/**
* 11.13 使用 JBoss Marshalling
*/
public class MarshallingInitializer extends ChannelInitializer<Channel> {
private final MarshallerProvider marshallerProvider;
private final UnmarshallerProvider unmarshallerProvider;
public MarshallingInitializer(UnmarshallerProvider unmarshallerProvider, MarshallerProvider marshallerProvider) {
this.marshallerProvider = marshallerProvider;
this.unmarshallerProvider = unmarshallerProvider;
}
@Override
protected void initChannel(Channel channel) throws Exception {
ChannelPipeline pipeline = channel.pipeline();
// 添加 MarshallingDecoder 以 将 ByteBuf 转换为 POJO
pipeline.addLast(new MarshallingDecoder(unmarshallerProvider));
// 添加 MarshallingEncoder 以将POJO 转换为 ByteBuf
pipeline.addLast(new MarshallingEncoder(marshallerProvider));
pipeline.addLast(new ObjectHandler());
}
// 添加 ObjectHandler,以处理普通的实现了Serializable 接口的 POJO
public static final class ObjectHandler extends SimpleChannelInboundHandler<Serializable> {
@Override
public void channelRead0(ChannelHandlerContext channelHandlerContext, Serializable serializable) throws Exception {
// Do something
}
}
}
2.3 通过 Protocol Buffers 序列化
Netty序列化的最后一个解决方案是利用Protocol Buffers(https://protobuf.dev/)的编解码器,由Google开发、现已开源的数据交换格式。可在https://github.com/google/protobuf找到源代码。Protocol Buffers 以紧凑高效方式对结构化的数据进行编解码。它具有许多的编程语言绑定,使得它很适合跨语言项目。表 11-10 展示Netty为支持 protobuf 所提供ChannelHandler 实现。
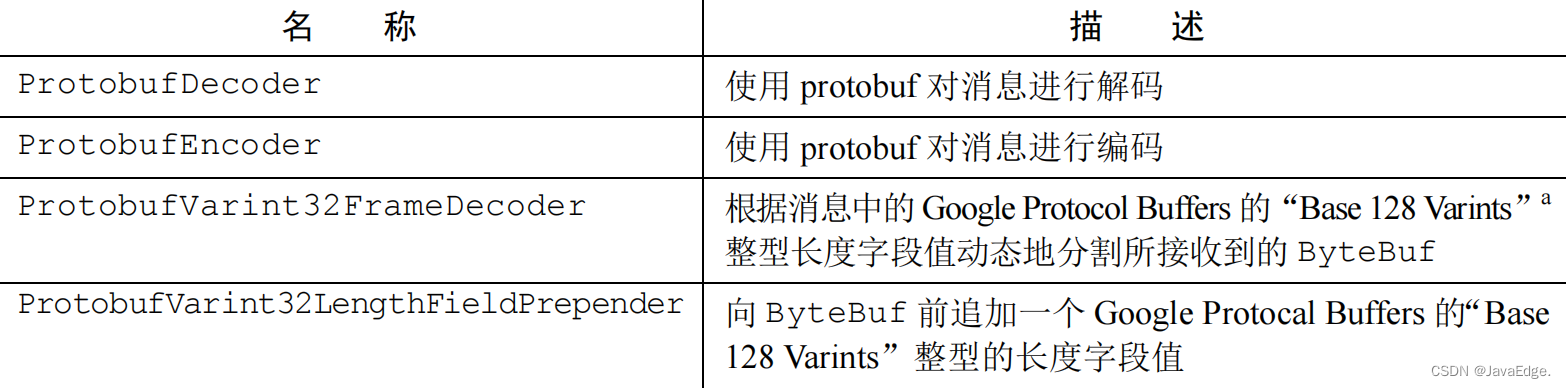
使用 protobuf 只不过是将正确的 ChannelHandler 添加到 ChannelPipeline 中,如代码清单 11-14 所示。
package io.netty.example.cp11;
import com.google.protobuf.MessageLite;
import io.netty.channel.*;
import io.netty.handler.codec.protobuf.ProtobufDecoder;
import io.netty.handler.codec.protobuf.ProtobufEncoder;
import io.netty.handler.codec.protobuf.ProtobufVarint32FrameDecoder;
/**
* Listing 11.14 Using protobuf
*/
public class ProtoBufInitializer extends ChannelInitializer<Channel> {
private final MessageLite lite;
public ProtoBufInitializer(MessageLite lite) {
this.lite = lite;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
// 添加 ProtobufVarint32FrameDecoder 以分隔帧
pipeline.addLast(new ProtobufVarint32FrameDecoder());
// 还需要在当前的 ProtobufEncoder 之前添加一个相应的 ProtobufVarint32LengthFieldPrepender 以编码进帧长度信息
// 添加 ProtobufEncoder以处理消息的编码
pipeline.addLast(new ProtobufEncoder());
// 添加 ProtobufDecoder以解码消息
pipeline.addLast(new ProtobufDecoder(lite));
// 加 ObjectHandler 以处理解码消息
pipeline.addLast(new ObjectHandler());
}
public static final class ObjectHandler extends SimpleChannelInboundHandler<Object> {
@Override
public void channelRead0(ChannelHandlerContext ctx, Object msg) throws Exception {
// Do something with the object
}
}
}
这节探讨由 Netty 专门的解码器和编码器所支持的不同的序列化选项:标准JDK序列化、JBoss Marshalling 及 Google 的 Protocol Buffers。
3 总结
Netty 提供的编解码器以及各种 ChannelHandler 可以被组合和扩展,以实现非常广泛的处理方案。此外,它们也是被论证的、健壮的组件,已经被许多的大型系统所使用。
我们只涵盖最常见示例;Netty 的 API 文档提供了更加全面的覆盖。
下一章学习另一种先进的协议——WebSocket,被开发用以改进 Web 应用程序的性能以及响应性。Netty 提供你将会需要的工具,以便你快速、轻松地利用它强大的功能。