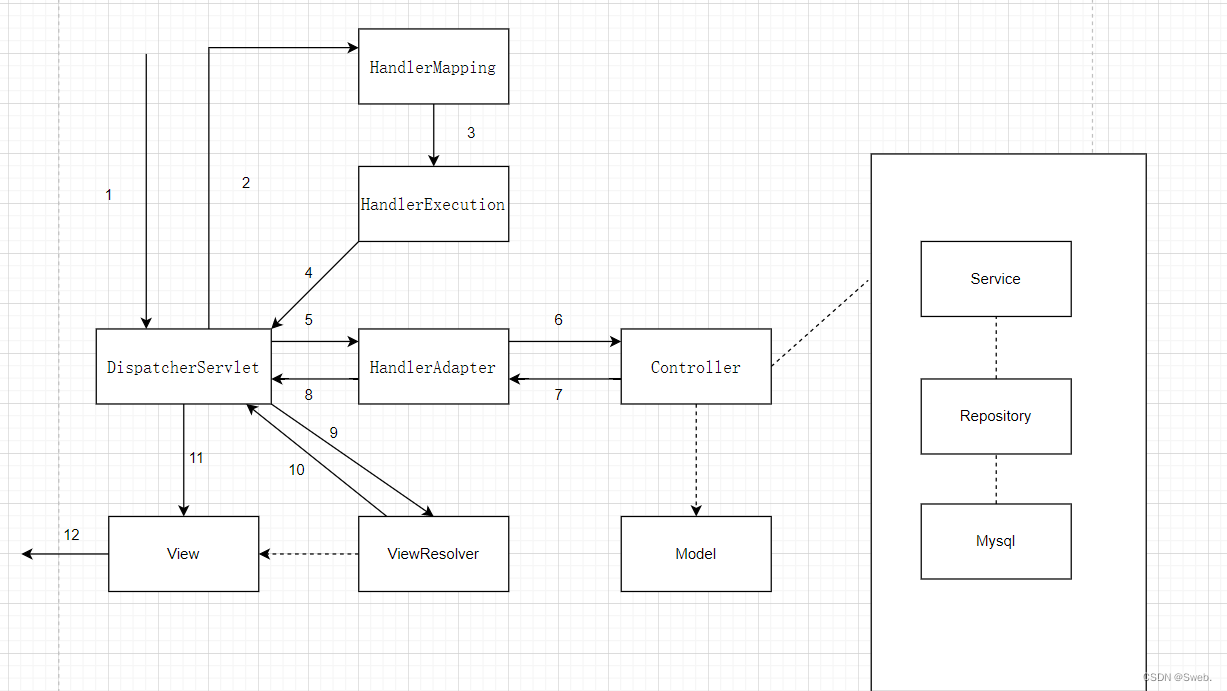
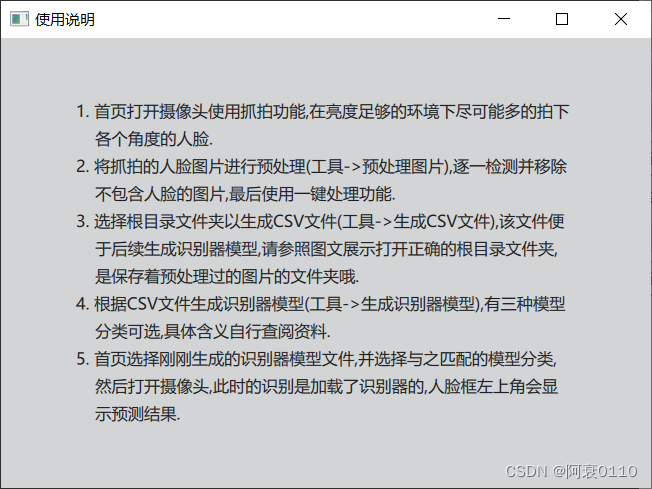
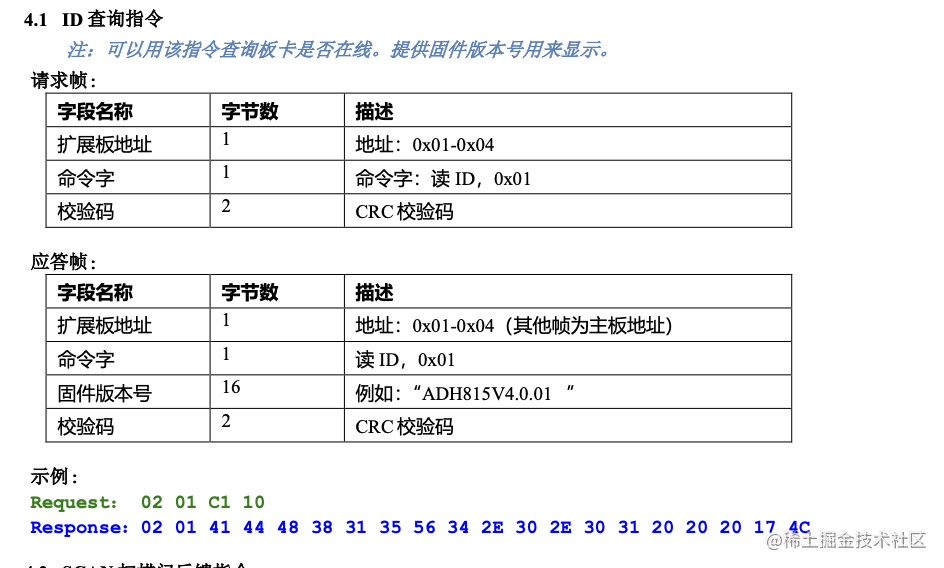
目录
一、数据分析与数据集构建
二、所有相关的脚本
三、模型效果
一、数据分析与数据集构建
由于电科院数据集有17w-18w张,标签错误的非常多,且漏标非常多,但是所有有效时间只有半个月左右,显卡是M60,训练速度特别慢,所以需要尽量留足训练时间,至少是1周左右,而且为了保证训练的轮数尽量多,还需要使得数据集尽量有效,减少冗余
数据复杂情况如下:
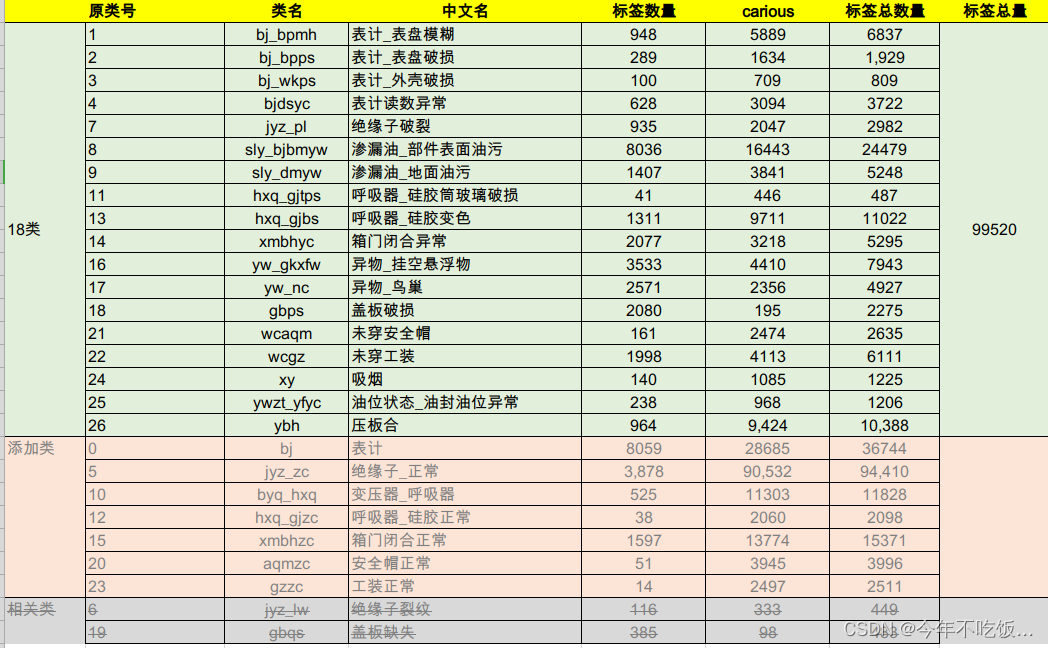
由于只训练缺陷类,效果难以达到较好的情况,所以这里考虑加入正常数据,作为辅助,做法流程是:
只筛选缺陷看看带出来多少正常——在里面剔除不需要的类(这里是6和19)——然后由于正常类不能和异常交叉存在,所以剔除和异常交叉的正常类的标,IOU阈值取0.5
得到数据情况如下:
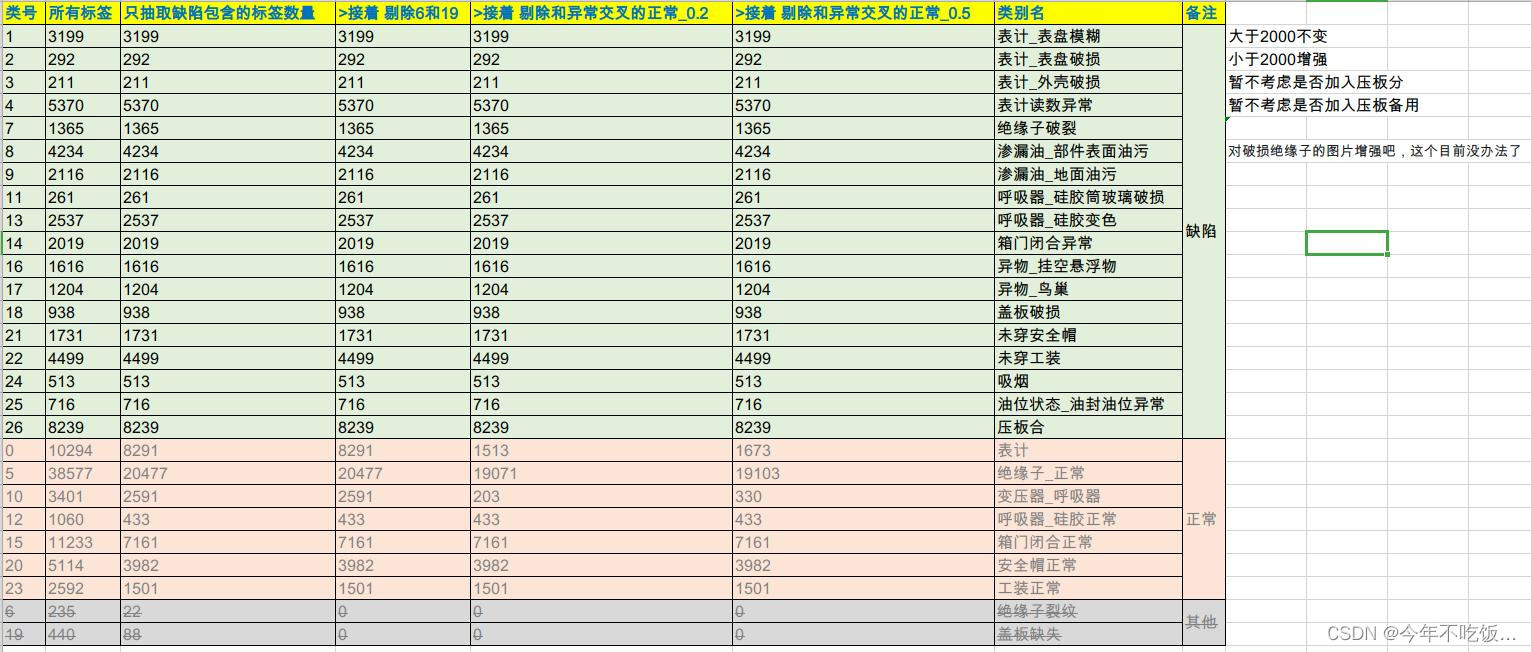
由于“绝缘子正常”太多,这里考虑删除一部分,使得绝缘子正常的数量也能在1000-2000,做法是先统计“5_class27_0518_接着剔除和异常交叉的正常_0.5_抽取绝缘子正常”,然后统计每个类和绝缘子共存的情况,看看哪些较多,能否剔除该类中共存的绝缘子达到目的,数据统计如下:
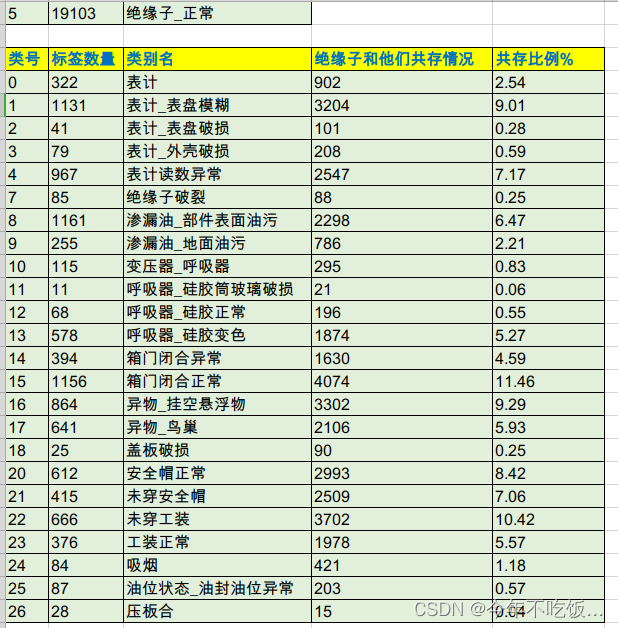
可见绝缘子并不是很大一部分分布在某一个或者几个类里面的,所以这里无法剔除,只是对“绝缘子破损”进行增强来弥补该类的数据不足
最终训练使用的数据是“6_2_class27_0518_接着剔除和异常交叉的正常_0.5_split”,然后将数据20-25%作为val,其余进行train,进行训练,寻找最佳的方法
数据集每类平衡的规则是:不足2000的增强到2000幅,补充的对照样本(绝缘子正常等)不足1000的增强到1000,尽量均衡的前提下正样本不能多
寻找到最佳方法后,所有是train,不留val,使得尽量多的数据参与训练,以得到最佳模型
二、所有相关的脚本
1_abcd当指定类和它相关类iou过大时剔除该指定类
import os
def calculate_iou(box1, box2):
# 提取边界框的坐标和尺寸
x1, y1, w1, h1 = box1[1:]
x2, y2, w2, h2 = box2[1:]
# 计算边界框的右下角坐标
x1_right, y1_bottom = x1 + w1, y1 + h1
x2_right, y2_bottom = x2 + w2, y2 + h2
# 计算相交区域的坐标
x_intersect = max(x1, x2)
y_intersect = max(y1, y2)
x_intersect_right = min(x1_right, x2_right)
y_intersect_bottom = min(y1_bottom, y2_bottom)
# 计算相交区域的宽度和高度
intersect_width = max(0, x_intersect_right - x_intersect)
intersect_height = max(0, y_intersect_bottom - y_intersect)
# 计算相交区域的面积
intersect_area = intersect_width * intersect_height
if intersect_area<0.000001:
return 1
# 计算两个边界框的面积
box1_area = w1 * h1
box2_area = w2 * h2
# 计算最小并集
whole_area = float(box1_area + box2_area - intersect_area)
min_area = float(min(box1_area,min(box2_area,whole_area)))
# 计算IOU
iou = intersect_area /min_area
return iou
def filter_annotations(queding_id,id_list,filename):
list1 = []
list2 = []
filtered_annotations = []
with open(filename, 'r') as file:
lines = file.readlines()
print('all:\n',lines)
for line in lines:
class_label, x, y, width, height = line.split(' ')
x, y, width, height = float(x), float(y), float(width), float(height)
class_id = int(class_label)
if int(class_id) == queding_id:
list1.append([class_id, x, y, width, height])
elif int(class_id) in id_list:
list2.append([class_id, x, y, width, height])
else:
filtered_annotations.append(line)
for annotation1 in list1:
iou_greater_than_0_2 = False
for annotation2 in list2:
iou = calculate_iou(annotation1, annotation2)
if iou > 0.2:
print('iou,',iou)
iou_greater_than_0_2 = True
break
if not iou_greater_than_0_2:
line_dst1 = str(annotation1[0])+" "+str(annotation1[1])+" "+str(annotation1[2])+" "+str(annotation1[3])+" "+str(annotation1[4])+"\n"
filtered_annotations.append(line_dst1)
for annotation2 in list2:
line_dst2 = str(annotation2[0])+" "+str(annotation2[1])+" "+str(annotation2[2])+" "+str(annotation2[3])+" "+str(annotation2[4])+"\n"
filtered_annotations.append(line_dst2)
with open(filename,"w",encoding="utf-8") as f:
for line in filtered_annotations:
f.write(line)
return filtered_annotations
if __name__=='__main__':
"""
queding_id = 0
id_list = [1,2,3,4]
--------------------------
queding_id = 5
id_list = [6,7]
--------------------------
queding_id = 10
id_list = [11,12,13]
"""
queding_id = 10
id_list = [11,12,13]
folder_path='./1_class27'
for root,_,files in os.walk(folder_path):
if len(files)>0:
for file in files:
if file.endswith('.txt'):
print('---------------')
print(file)
file_path=os.path.join(root,file)
res = filter_annotations(queding_id,id_list,file_path)
for l in res:
print(l)
2splitImgAndLabelByLabelid
# -*- encoding:utf-8 -*-
import os
import cv2
import sys
import shutil
from pathlib import Path
suffixs = [".png"]
if len(sys.argv) != 2:
print("input as:\n python 1splitImgAndLabelByLabelid.py imgFolder")
sys.exit()
path = sys.argv[1]
if not os.path.exists(path):
print("sorry, you input empty floder ! ")
sys.exit()
file_type_list = ['txt']
for name in os.listdir(path):
print("-"*20)
print("name,",name)
file_path=os.path.join(path,name)
file_type=file_path.split('.')[-1]
for suffix in suffixs:
file_name=file_path[0:file_path.rfind('.', 1)]+suffix
if os.path.exists(file_name):
image=cv2.imread(file_name)
if image is None:
continue
else:
break
if(file_type in file_type_list):
bef=open(file_path)
ids=[]
for line in bef.readlines():
linenew = line.strip().split(" ")
if len(linenew) == 5:
ids.append(int(linenew[0]))
ids_len=len(ids)
if ids_len == 0:
save_path = "empty"
if not os.path.exists(save_path):
os.mkdir(save_path)
shutil.move(file_path,save_path)
shutil.move(file_name,save_path)
elif ids_len == 1:
save_path = str(ids[0])
if not os.path.exists(save_path):
os.mkdir(save_path)
shutil.move(file_path,save_path)
shutil.move(file_name,save_path)
else:
ids.sort()
if ids[0] == ids[-1]:
save_path = str(ids[0])
if not os.path.exists(save_path):
os.mkdir(save_path)
shutil.move(file_path,save_path)
shutil.move(file_name,save_path)
else:
save_path = "various"
if not os.path.exists(save_path):
os.mkdir(save_path)
shutil.move(file_path,save_path)
shutil.move(file_name,save_path)
print(ids)3_copyfilesbyclassid
# encoding:utf-8
import os
import cv2
import shutil
suffixs = [".JPG",".PNG",".bmp",".jpeg",".jpg",".png"]
def backup_txt_files(src_dir, dst_dir):
for root,_,files in os.walk(src_dir):
for file in files:
if file.endswith('.txt'):
# select label
src_path = os.path.join(root, file)
rel_path = os.path.relpath(src_path,src_dir)
dst_path = os.path.join(dst_dir, rel_path)
new_label_data = []
with open(src_path, "r", encoding="utf-8") as f:
for line in f:
line_tmp = line.strip().split(" ")
if len(line_tmp) == 5:
if int(line_tmp[0]) == 6 :
continue
line_dst = line_tmp[0]+" "+line_tmp[1]+" "+line_tmp[2]+" "+line_tmp[3]+" "+line_tmp[4]+"\n"
new_label_data.append(line_dst)
if len(new_label_data)>0:
# process label
dst_folder=os.path.dirname(dst_path)
os.makedirs(dst_folder, exist_ok=True)
with open(dst_path,"w",encoding="utf-8") as f:
for line in new_label_data:
f.write(line)
# process image
for suffix in suffixs:
file_name=src_path[0:src_path.rfind('.', 1)]+suffix
if os.path.exists(file_name):
image=cv2.imread(file_name)
if image is not None:
shutil.copy(file_name, dst_folder)
break
# 指定源路径和备份路径(最好使用绝对路径)
src_dir = 'various'
dst_dir = 'various_6'
# 执行备份操作
backup_txt_files(src_dir, dst_dir)
4_ccccc补充various到单类中
# encoding:utf-8
import os
import shutil
from termios import PARODD
import cv2
import random
def backup_txt_files(src_dir, sample_dir,class_id,num_thresh):
src_num_files = len([f for f in os.listdir(src_dir) if os.path.isfile(os.path.join(src_dir, f))])//2
if src_num_files > num_thresh:
exit()
#
search_res=[]
for root,_,files in os.walk(sample_dir):
for file in files:
if file.endswith('.txt'):
flag = False
label_path = os.path.join(root, file)
with open(label_path, "r", encoding="utf-8") as f:
for line in f:
line_tmp = line.strip().split(" ")
if len(line_tmp) == 5:
if int(line_tmp[0]) == class_id :
flag = True
if flag == False:
continue
file_name=label_path[0:label_path.rfind('.', 1)]+".jpg"
if os.path.exists(file_name):
image=cv2.imread(file_name)
if image is not None:
search_res.append((file_name,label_path))
# shuf
random.shuffle(search_res)
sample_num_files = len(search_res)//2
#
save_path=src_dir+"_various"
os.makedirs(save_path,exist_ok=True)
#
add_num = num_thresh - src_num_files
print(src_dir,' ',src_num_files,' ',add_num)
if sample_num_files < add_num:
for file,label in search_res:
shutil.move(file,save_path)
shutil.move(label,save_path)
else:
for i in range(add_num):
shutil.move(search_res[i][0],save_path)
shutil.move(search_res[i][1],save_path)
# 指定源路径和备份路径(最好使用绝对路径)
src_dir = 'single'
sample_dir = 'various'
num_thresh = 3000
# 执行备份操作
for folder in os.listdir(src_dir):
print('-'*40)
backup_txt_files(os.path.join(src_dir,folder),sample_dir,int(folder),num_thresh)
5_dedadada当指定类标过多时删去标抹去标签区域
import os
import random
import cv2
def process(label_path,class_id):
if label_path.endswith('.txt'):
# select label
# print('-'*40)
# print('label_path,',label_path)
new_label_data = []
with open(label_path, "r", encoding="utf-8") as f:
for line in f:
line_tmp = line.strip().split(" ")
if len(line_tmp) == 5:
if int(line_tmp[0]) == class_id :
# print(class_id)
# process image
file_name=label_path[0:label_path.rfind('.', 1)]+'.jpg'
if os.path.exists(file_name):
# print('draw&ignore ',class_id,' ',file_name)
image=cv2.imread(file_name)
if image is not None:
# class_label = line_tmp[0]
x, y, width, height = map(float, line_tmp[1:])
x_min = int((x - width/2) * image.shape[1])
y_min = int((y - height/2) * image.shape[0])
x_max = int((x + width/2) * image.shape[1])
y_max = int((y + height/2) * image.shape[0])
cv2.rectangle(image, (x_min, y_min), (x_max, y_max), (125, 125, 125), -1)
cv2.imwrite(file_name,image)
# ignore label
continue
line_dst = line_tmp[0]+" "+line_tmp[1]+" "+line_tmp[2]+" "+line_tmp[3]+" "+line_tmp[4]+"\n"
# print('~~~~liuxia,',int(line_tmp[0]),class_id,line_dst)
new_label_data.append(line_dst)
# print('new_label_data,',new_label_data)
with open(label_path,"w",encoding="utf-8") as f:
for line in new_label_data:
f.write(line)
def getfilelistbyclassid(path,class_id,ignoreid):
file_list=[]
for folder in os.listdir(path):
if ignoreid==1:
if str(class_id) in folder:
continue
elif ignoreid==2:
if str(class_id)+"_various" != folder:
continue
folder_path=os.path.join(path,folder)
for file in os.listdir(folder_path):
if file.endswith('.txt'):
label_path=os.path.join(folder_path,file)
with open(label_path, "r", encoding="utf-8") as f:
for line in f:
line_tmp = line.strip().split(" ")
if len(line_tmp) == 5:
if int(line_tmp[0]) == class_id :
file_list.append(label_path)
break
return file_list
if __name__=='__main__':
id_list = [0,1]
path='./images'
for class_id in id_list:
# print('-'*40)
# print('dddd,',class_id)
id_path=os.path.join(path,str(class_id))
file_num=len([f for f in os.listdir(id_path) if os.path.isfile(os.path.join(id_path, f))])//2
if file_num > 1000:
# 当前超出限制,把当前之外的抹去(注意当前的还未处理,需要加,2023年05月20日11:44:58)
for folder in os.listdir(path):
if folder == str(class_id):
continue
for file in os.listdir(os.path.join(path,folder)):
if file.endswith('.txt'):
label_path = os.path.join(os.path.join(path,folder), file)
process(label_path,class_id)
else:
various_id_path=os.path.join(path,str(class_id)+"_various")
various_file_num=len([f for f in os.listdir(id_path) if os.path.isfile(os.path.join(id_path, f))])//2
file_various_num=various_file_num+file_num
if file_various_num < 1000:
# 另外的超出的标抹去
file_list=getfilelistbyclassid(path,class_id,ignoreid=1)
if len(file_list)+file_various_num>1000:
random.shuffle(file_list)
for i in range(len(file_list)+file_various_num-1000):
process(file_list[i],class_id)
else:
# various超出的标抹去
various_file_list=getfilelistbyclassid(path,class_id,ignoreid=2)
random.shuffle(various_file_list)
for i in range(len(various_file_list)+file_num-1000):
process(various_file_list[i],class_id)
# 另外的需要全部抹去
other_file_list=getfilelistbyclassid(path,class_id,ignoreid=1)
random.shuffle(other_file_list)
for i in range(len(other_file_list)):
process(other_file_list[i],class_id)
# 抹去数据过多类的标:
# 0,5,10,12,15,20,23
# 1、如单类大于1000
# 则删除various及其他中的标,同时抹去图像上的区域
# 2、如单类小于1000,但是结合various大于1000
# 则删除其他中的标,同时抹去图像上的区域
# 3、单类+various还是小于1000
# 则在其他中找到满足1000,则删除剩余的标,同时抹去图像上的区域
三、模型效果
待补充