大家好,我是微学AI,今天给大家介绍一下人工智能基础部分19-强化学习的原理和简单应用,随着人工智能的不断发展,各种新兴技术不断涌现。作为人工智能的一个重要分支,强化学习近年来受到了广泛关注。本文将介绍强化学习的原理,并通过一个简单的实例来分析强化学习的运用。
一、强化学习的原理
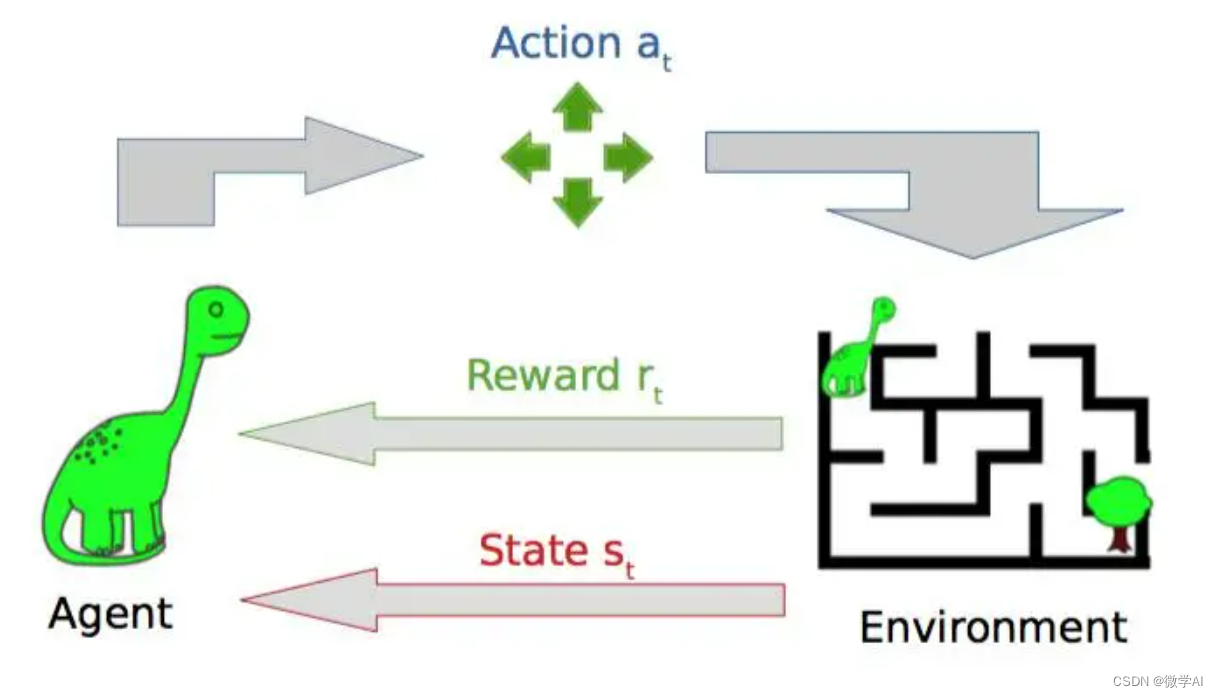
强化学习(RL)是一种通过智能体(Agent)与环境(Environment)的交互,通过试错来学习控制策略的方法。智能体在环境中执行动作,观察到环境状态的变化,并根据所获得的奖励,不断改进自己的策略以适应未来的任务。强化学习的基本组成部分包括:状态、动作、奖励和策略函数。其中状态和动作是智能体的内部状态,奖励是智能体从环境中获取的反馈信号,策略是决定智能体下一步应该采取哪种行动的规则。在强化学习中,智能体通过采用不同的策略分布来探索环境,在不同的状态下采取不同的行动,从而得到奖励,并利用这些奖励重新调整策略,以获得累积奖励的最大化。
强化学习的主要原理包括:
环境模型:强化学习中,智能体需要与环境进行交互,因此需要对环境进行建模和描述。环境模型描述了智能体在哪些状态下可以采取哪些行动,并给定了每个状态下采取不同行动的奖励信号。
状态空间和动作空间:在强化学习中,智能体的行为是由状态空间和动作空间决定的。状态空间是指智能体可以处于的所有状态的集合,动作空间是指智能体可以采取的所有行动的集合。
奖励函数:奖励函数是指智能体从环境中获得的反馈信号。奖励函数给出了在不同状态下采取不同行动的奖励值,以指导智能体的决策策略。
策略函数:策略函数是指智能体在给定状态下应该采取哪种行动的规则。策略函数可以是确定性的或者随机性的。
自适应学习:强化学习中,智能体需要不断地与环境进行交互,根据获得的奖励信号调整策略和行动,从而逐渐学习到最优的行动策略。自适应学习是指智能体可以根据获得的奖励信号调整策略和行动,以逐渐达到最优化的目标。

二、强化学习的应用
强化学习与监督学习中的预知事先给出的标签不同,强化学习方法不需要事先给出决策的正确答案。强化学习着重于从环境中的反馈学习如何进行决策,而非根据给出的答案。与无监督学习中的学习结构不同,强化学习更多地关注于如何支配产生这些结构的过程。强化学习广泛应用于游戏智能、机器人控制、自动驾驶汽车等领域。例如,DeepMind 的 AlphaGo 通过强化学习技术成功挑战围棋世界冠军;OpenAI 的 DOTA 2 智能体通过强化学习战胜了 DOTA2 世界顶尖选手。
三、强化学习的代码案例
现在我们设计一个简单的Q-learning算法来学习一个6 x 6的网格迷宫。在训练过程中,智能体在每一步都使用epsilon-greedy策略来选择动作,更新Q表格。最终训练完成后,打印出学习到的Q表格。
import numpy as np
# 定义动作和状态空间大小
num_states = 6
num_actions = 2
# 定义奖励矩阵
rewards = np.array([
[0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0],
[0, -1, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1],
[0, 0, 0, 0, 0, -1],
[0, 0, 0, 0, 0, 0]
])
# 定义智能体的Q表格
Q = np.zeros((num_states, num_actions))
# 定义超参数
alpha = 0.1 # 学习率
gamma = 0.99 # 折扣率
epsilon = 0.1 # epsilon-greedy策略
# 定义训练函数
def train(iterations):
for i in range(iterations):
state = np.random.randint(0, num_states) # 随机初始状态
while state != 5: # 直到达到终止状态
# epsilon-greedy选择动作
if np.random.uniform() < epsilon:
action = np.random.randint(0, num_actions)
else:
action = np.argmax(Q[state, :])
# 获取下一个状态和奖励
next_state = np.random.randint(0, num_states)
reward = rewards[state, next_state]
# 更新Q表格
Q[state, action] += alpha * (reward + gamma * np.max(Q[next_state, :]) - Q[state, action])
state = next_state
# 训练10次,并打印最终Q表格
train(50)
print(Q)运行输出Q表格:
[[ 4.11925982e-02 4.39469201e-03]
[ 2.22485294e-01 3.93210790e-02]
[-5.42652962e-03 -1.38996022e-01]
[ 2.54590976e-01 1.54935722e-04]
[-2.71647569e-01 -9.66296584e-02]
[ 0.00000000e+00 0.00000000e+00]]这个Q表格表示了智能体在每个状态下采取两个动作中的一个的Q值。在这个例子中,Q表格的每一行对应一个状态,每一列对应一个动作。例如,第一行表示智能体在状态0下采取两个动作中的一个时的Q值。每次智能体遇到一个新的状态时,会更新Q表格中对应的行。通过学习这些示例,我们可以更好地理解强化学习算法如何工作,并了解如何将它们应用于更广泛的问题领域。