文章目录
- 概述
- 项目复现
- 配置环境
- 下载并配置文件
- 运行代码
- 第一阶段,训练提取DTFR特征的模型
- 资料搜集
- train_vqvae.py
- 第二阶段,使用训练好的模型提取声音的DTFR特征
- torch.cuda.OutOfMemoryError: CUDA out of memory.
- 第三阶段,基于特征训练合成声音的模型
- 第四阶段,生成声音,并保存结果
- 重新使用colab进行复现
- 下载代码库并配置环境
- 鬼扯,崩溃,因为到了时间限额,然后他就给我自动刷新,原来训练好的一些模型都无了,生成的声音样例也没有了!寄!!!!
- 换了一个简单使用VAE进行生成,使用tensorflow进行训练
概述
- 这部分准备先复现项目,看看能不能跑起来,只要能跑起来,就剩下看论文了,然后根据论文讲讲代码,这个任务基本上就算是完成了,至少下周的课程没啥问题了。
- 项目的地址
- 论文地址
项目复现

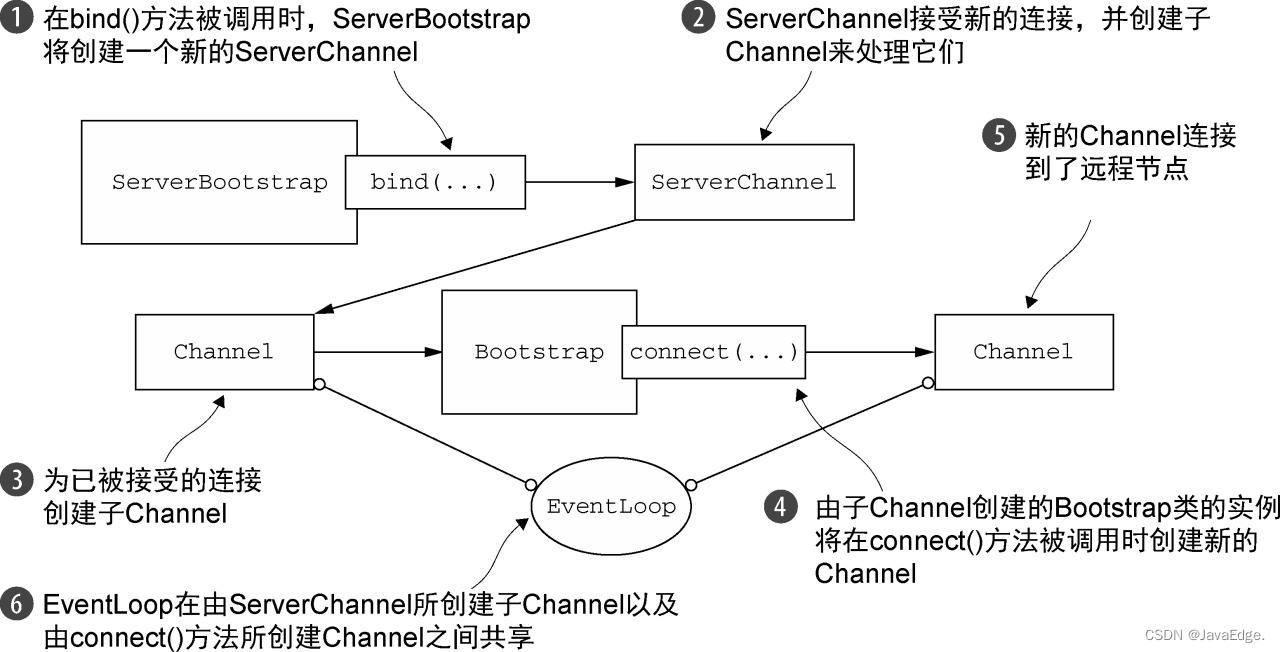
开头一张图
配置环境
- 首先安装如下的包
- torch==1.13.1,深度学习框架
- 这个安装之前已经研究过了,基本上懂了之后很快的,如果感谢兴趣自己看这篇文章。
- librosa==0.10.0
- 这个是用来做于音频、音乐分析和处理的python工具包,一些常见的时频处理、特征提取、绘制声音图形等功能应有尽有,功能十分强大。
- 安装,直接输入
pip install librosa
- python-lmdb==1.4.0,
- 高效快速的内存映射数据库,用来打开lmdb数据库文件的,数据集就是类似的文件。
- 安装,直接输入
pip install lmdb
- tqdm
- python的进度条库,使用链接
- torch==1.13.1,深度学习框架
下载并配置文件
- 下载指令如下
git clone https://github.com/DCASE2023-Task7-Foley-Sound-Synthesis/dcase2023_task7_baseline.git
- 下载数据集到特定的目录
./DCASEFoleySoundSynthesisDevSet- 下载地址
- 将数据集解压并存放到对应的路径中
- 将项目分享到gitee上了,gitee项目地址
运行代码
第一阶段,训练提取DTFR特征的模型
- 训练一个多尺度的VQ-VAE模型去提取声音离散的T-F特征表示(Discrete T-F Representation),训练好的模型将会被保存在
checkpoint/vqvae/路径下,并且输入如下的指令
python train_vqvae.py --epoch 80
- 完全可以运行

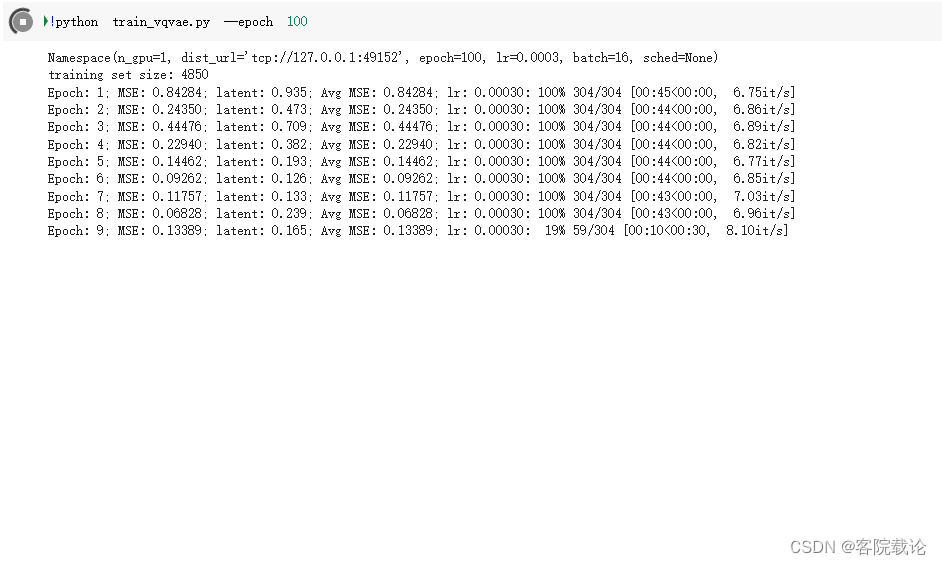
- 因为我的卡比较水,所以我就训练了80个epoches,模型保存结果如下
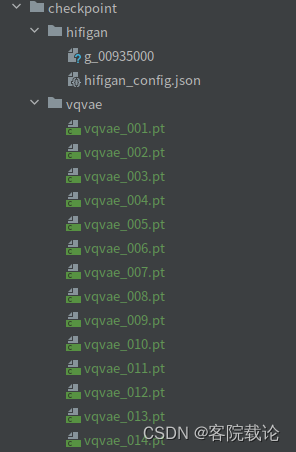
资料搜集
【MIT公开课】6.003 信号和系统 · 2011年秋
train_vqvae.py
第二阶段,使用训练好的模型提取声音的DTFR特征
- 使用上一个阶段训练的模型提取出对应的DTFR特征,输入如下的命令
python extract_code.py --vqvae_checkpoint [VQ-VAE CHECKPOINT]
- 虽然在上一部就生成了pt文件,不是按照要求的pth文件,不过保存的信息都是相同的,都是模型的参数,可以直接使用。这里需要修改一下路径,这里是根据我的路径修改之后的命令
python extract_code.py --vqvae_checkpoint /root/PycharmProjects/FoleySound/dcase2023_task7_baseline/checkpoint/vqvae/vqvae_080.pt
torch.cuda.OutOfMemoryError: CUDA out of memory.
-
运行之后会显示如下的异常,大概是说CUDA的内存不够

-
减少batch_size的数量即可,修改如下的代码,我的显存是3G,只能改成32
-
修改extract_code.py,中第55行中的batch_size,原来是128。
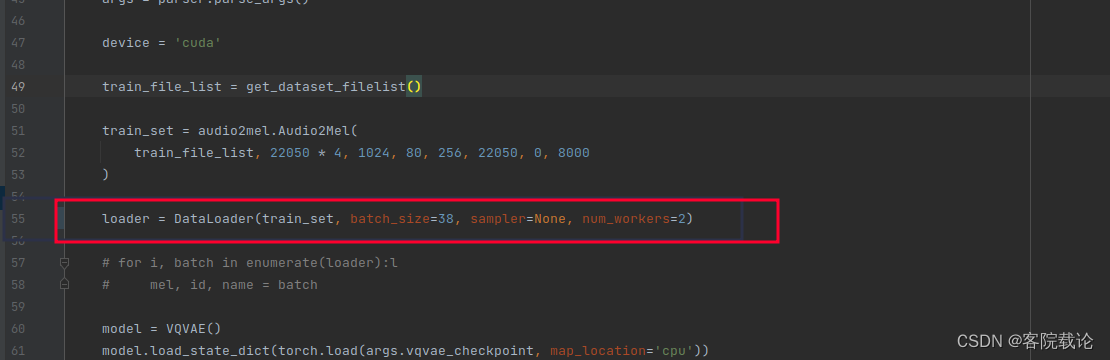
第三阶段,基于特征训练合成声音的模型
- 基于已经提取出来的DTFR特征,训练一个PixelSNAIL 模型。训练结果将会被保存在
checkpoint/pixelsnail-final/中。运行如下指令
python train_pixelsnail.py --epoch 1500
- 直接运行,又遇到了上述的情况,截图如下
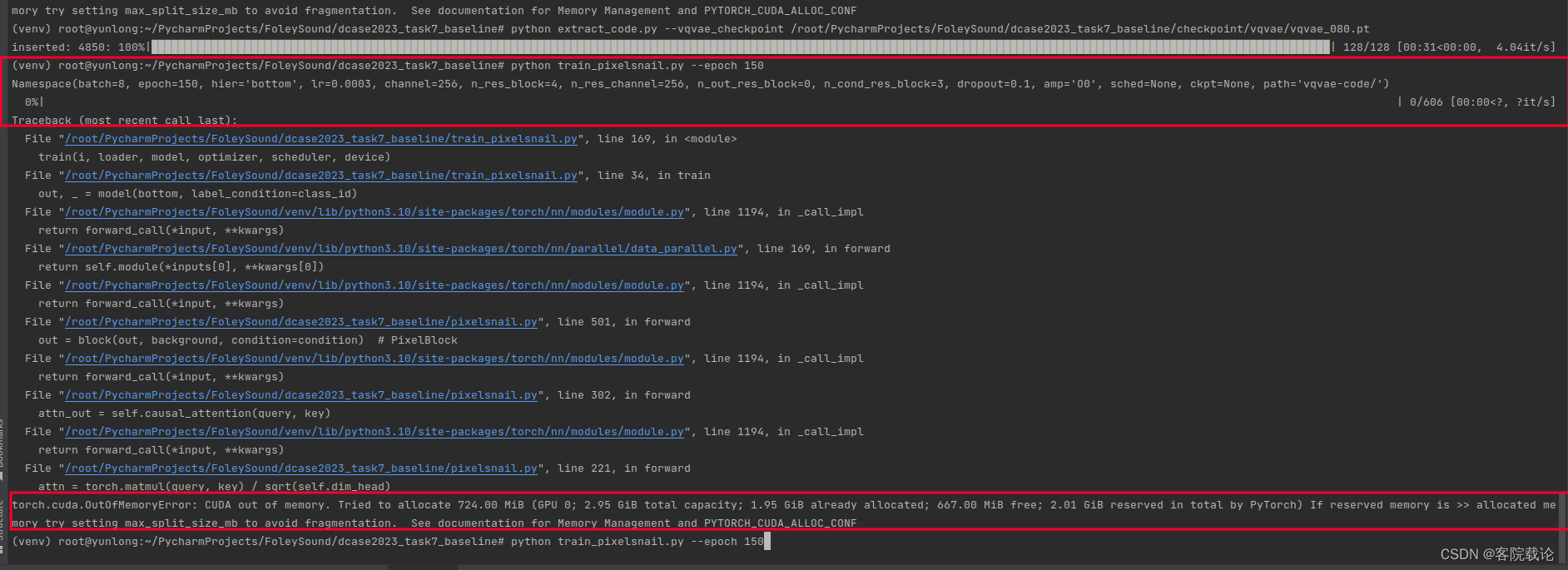
- 直接修改batch_size,找到train_pixelsnail.py文件,修改batch_size,对应是72行

- 原来是8改成了2还是不行,也有其他的方法,不过都是要求能跑完一个epoch,我这个进行一次前向传播都困难,估计是悬了。我只能用工作站上上的跑了,或者用colab跑一下了。
第四阶段,生成声音,并保存结果
- 合成声音,将合成的声音保存到
./synthesized,运行如下指令
python inference.py --vqvae_checkpoint [VQ-VAE CHECKPOINT] --pixelsnail_checkpoint [PIXELSNAIL CHECKPOINT] --number_of_synthesized_sound_per_class [NUMBER OF SOUND SAMPLES]
重新使用colab进行复现
这里遇到了各种问题,之前那种胡乱摸索尝试,不看学习文档的方法当真是祸害无穷,得得,用一天,从头开始学习colab,趁着今天的份额还没有浪费,加油吧!
- 具体详见这篇 Colab的基本使用
下载代码库并配置环境
- 下载代码,并将之复制到对应的云端硬盘中
# 挂载硬盘
from google.colab import drive
drive.mount('/content/drive/')
# 下载文档,并且复制到特定目录中
!git clone https://gitee.com/blackoutdragon/FoleySound.git
!cp -R FoleySound drive/MyDrive/FoleySound
- 配置对应的环境,这里并不需要配置pytorch,这里是自带的
!pip install lmdb
!pip install librosa
!pip install tqdm
- 设置当前笔记本为GPU

- 直接可以使用,这里默认是pytorch2.0并且cuda的版本是12.0,直接使用
鬼扯,崩溃,因为到了时间限额,然后他就给我自动刷新,原来训练好的一些模型都无了,生成的声音样例也没有了!寄!!!!
换了一个简单使用VAE进行生成,使用tensorflow进行训练
请看论文复现4,新的篇章