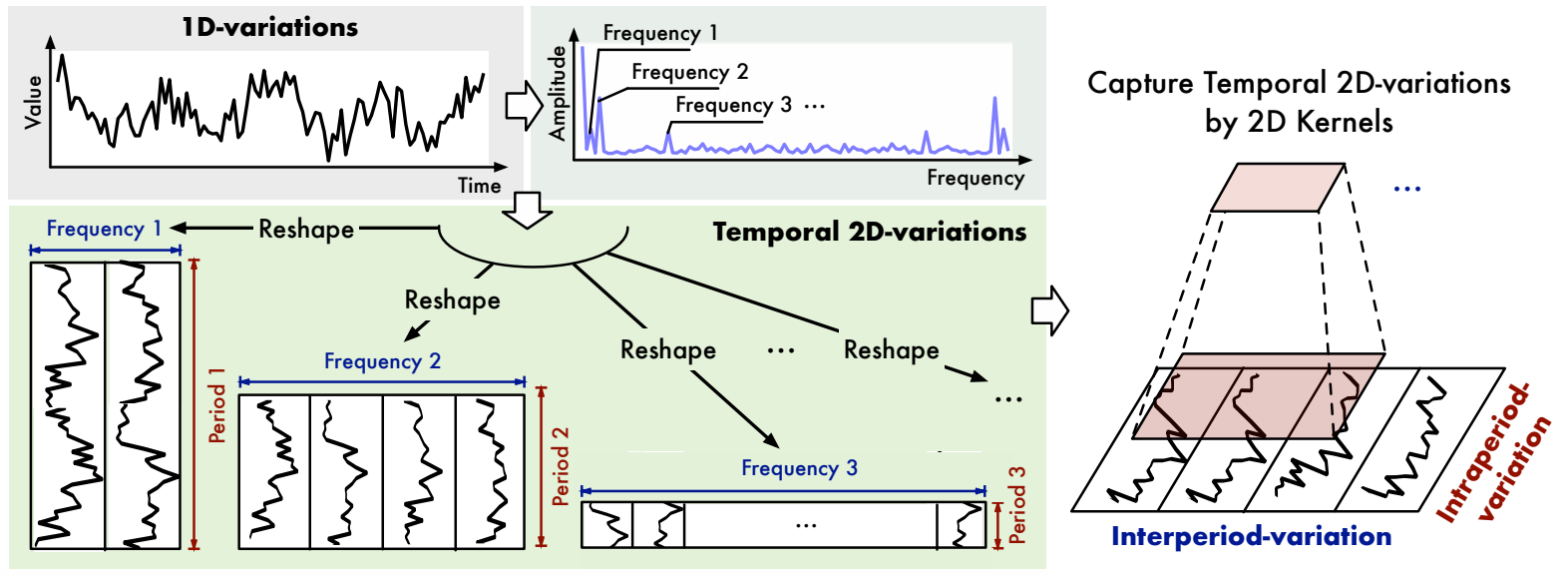
周二收到一篇推送 一次云上网络毫秒级的优化与实践,很有意义的实践和探索,建议阅读,文章不长,没有冗长的源码分析,结论很清晰。
谈谈我的看法。
多少有种感觉,Linux 越来越像个响应系统而不是服务器。
虚拟化容器,计算存储,RPC 微服务,cache 数据库,大包吞吐,小包时延,虽没有接鼠标键盘,但这些对响应时间的要求远大于鼠标键盘,Linux 早就不仅仅承载高并发,大吞吐了。但 Linux kernel 调度器并没有为此做好准备。
再说绑核。
原文中也提到,不绑核就 OK 了。往大了说,绑核是自废武功的行为。绑核用弹性换性能,但有时丢了弹性不说,反而劣化性能,如原文所举实例:
网络协议栈收包软中断以一种奇怪的方式执行,在任意上下文中它是高优的,但它同时也可以在 ksoftirqd 中以普通 task 执行,取决于不确定。
softirq 之所以在非 ksoftirqd 上下文执行时获得更高权重,完全仗着它是被 hardirq 带飞的,softirq 在 irq_exit 时狐假虎威而已,一旦进入 ksoftirqd 上下文就泯然众人。
Linux kernel 调度器自 CFS 以来没有大动作,一直基于优先级摊大饼,配合启发算法作 workaround,这非常适合服务器,但不利用快速响应,如今云主机需要比桌面环境更花式的响应度,摊大饼策略肯定有问题。
摊大饼对所有 task_struct 一视同仁,仅做优先级区分,无法区分紧急性和重要性维度,紧急性需立即响应,而重要性需赋予更多时间片,这就是四象限时间管理。
Windows 采用了类四象限法调度,为一类不同事件赋予了不同的响应优先级。比如鼠标键盘优先磁盘被响应,而绘制请求优先于声音,因此它作为桌面才优秀。详见早期的一篇文章:Linux 桌面为何卡顿。
显然,网络收包无论从紧急性还是重要性看,都要比进程权重更高。可 Linux kernel 在这方面表现很随意。
即使取消 ksoftirqd 的执行判断用硬调用 softirq 来替换也没有解决根本问题,硬调用虽解放了收包 softirq,却又损害了其它 task 的弹性,如果进程真的既紧急又重要(我是说如果),硬调用 softirq 和绑核没本质区别。如果有其它不紧急也不重要的 softirq,取消 ksoftirqd 反而有问题,此时需要区别对待网络子系统,而这又是 workaround。
并不是所有进程都不紧急不重要,也不是所有 softirq 都高优,除这两者外,系统中难免出现别的 task,有些需保障固定时间,有些需固定时间比例,有些需第一时间响应,有些则微不足道。依靠 Linux kernel 现有的 sched_class + interrupt 调度体系根本无法区分对待以上的细粒度。
比如拉屎,无论再忙,有些人拉屎时间总固定在 2 分钟,而另一些人则固定在 30 分钟,而不是忙时 2 秒,闲时 30 分钟。拉屎是一个紧急任务,相对拉屎,工作则是重要任务,但依然要把固定时间让给拉屎,无论工作再满,拉屎时间也不能无限挤压,况且,对于一部分人,拉屎不但紧急,而且重要。
Linux kernel 不知道一个进程是不是仅在一个时间段有密集 IO 行为的 CPU 型,不知道进程被唤醒是因为键盘,还是无关紧要的信号,Linux kernel 只能启发预测,但这并不可靠。
同 TCP 端到端 cc,Linux kernel 追求简单,通用,高效的调度算法,看不上对额外信息有所依赖的算法,笃信所谓纯粹技术含量,这绝对是自视清高庸人自扰,他们假装不知道,高效是尽可能精确的信息堆起来的,信息量有上限,误判后的补偿必然损失效率,换句话说就是启发必有概率误判,而误判则带来时间的浪费。
端到端原则和 Linux kernel 社区的这种态度如出一辙,背后的缘由可能是对成本看不上,对定制看不上。
简单看看 ntddk.h 的部分定制化优先级提升值:
// Priority increment definitions. The comment for each definition gives
// the names of the system services that use the definition when satisfying
// a wait.
//
// Priority increment used when satisfying a wait on an executive event
// (NtPulseEvent and NtSetEvent)
#define EVENT_INCREMENT 1
//
// Priority increment when no I/O has been done. This is used by device
// and file system drivers when completing an IRP (IoCompleteRequest).
#define IO_NO_INCREMENT 0
//
// Priority increment for completing CD-ROM I/O. This is used by CD-ROM device
// and file system drivers when completing an IRP (IoCompleteRequest)
#define IO_CD_ROM_INCREMENT 1
//
// Priority increment for completing disk I/O. This is used by disk device
// and file system drivers when completing an IRP (IoCompleteRequest)
#define IO_DISK_INCREMENT 1
//
// Priority increment for completing keyboard I/O. This is used by keyboard
// device drivers when completing an IRP (IoCompleteRequest)
#define IO_KEYBOARD_INCREMENT 6
//
// Priority increment for completing mailslot I/O. This is used by the mail-
// slot file system driver when completing an IRP (IoCompleteRequest).
#define IO_MAILSLOT_INCREMENT 2
//
// Priority increment for completing mouse I/O. This is used by mouse device
// drivers when completing an IRP (IoCompleteRequest)
#define IO_MOUSE_INCREMENT 6
//
// Priority increment for completing named pipe I/O. This is used by the
// named pipe file system driver when completing an IRP (IoCompleteRequest).
#define IO_NAMED_PIPE_INCREMENT 2
//
// Priority increment for completing network I/O. This is used by network
// device and network file system drivers when completing an IRP
// (IoCompleteRequest).
// 网卡IO之所以优先级提升并不是很多,是因为首先网卡是有队列缓存的,而大多数的报文都是burst而来的,
// 队列缓存可以平滑掉首包延迟,其次,由于光速极限,相比于网络延迟,主机调度延迟真的可以忽略不计。
#define IO_NETWORK_INCREMENT 2
//
// Priority increment for completing parallel I/O. This is used by parallel
// device drivers when completing an IRP (IoCompleteRequest)
#define IO_PARALLEL_INCREMENT 1
//
// Priority increment for completing serial I/O. This is used by serial device
// drivers when completing an IRP (IoCompleteRequest)
#define IO_SERIAL_INCREMENT 2
//
// Priority increment for completing sound I/O. This is used by sound device
// drivers when completing an IRP (IoCompleteRequest)
#define IO_SOUND_INCREMENT 8
//
// Priority increment for completing video I/O. This is used by video device
// drivers when completing an IRP (IoCompleteRequest)
#define IO_VIDEO_INCREMENT 1
//
// Priority increment used when satisfying a wait on an executive semaphore
// (NtReleaseSemaphore)
#define SEMAPHORE_INCREMENT 1
这绝不是 Linux kernel 风格,Linux kernel 总希望在统一的优先级调度框架下解决问题,看不上引入额外信息增强定制。类似的,在处理 TCP cc 时,当我建议利用底层链路信息及 application 信息做决策,也经常被鄙视。不是得不到这些信息,如果得到了,大家会用吗?可能不会,这就是看不上。纯程序员笃信闭环,对外部信息的以来颇为不屑。
我觉得理想的调度器应该类似四象限时间管理法。在传统的重要性优先级外扩展一个紧急优先级就是了:
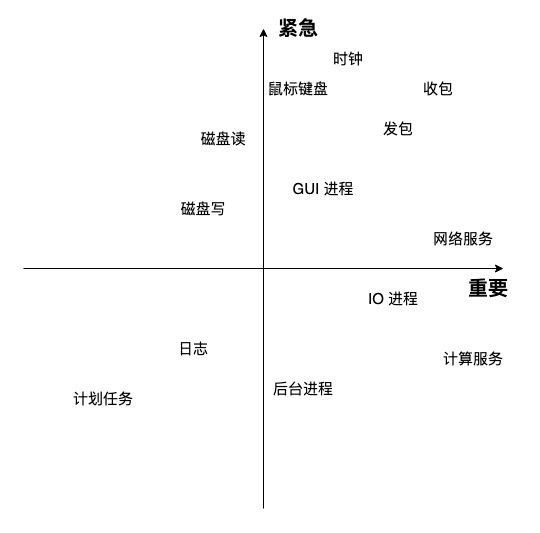
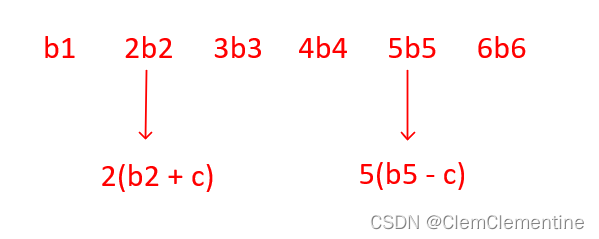
转换到二维坐标系,y 轴表示重要性,x 轴表示时间片,每个三角形表示一个任务的执行,下图是图示及一个例子:
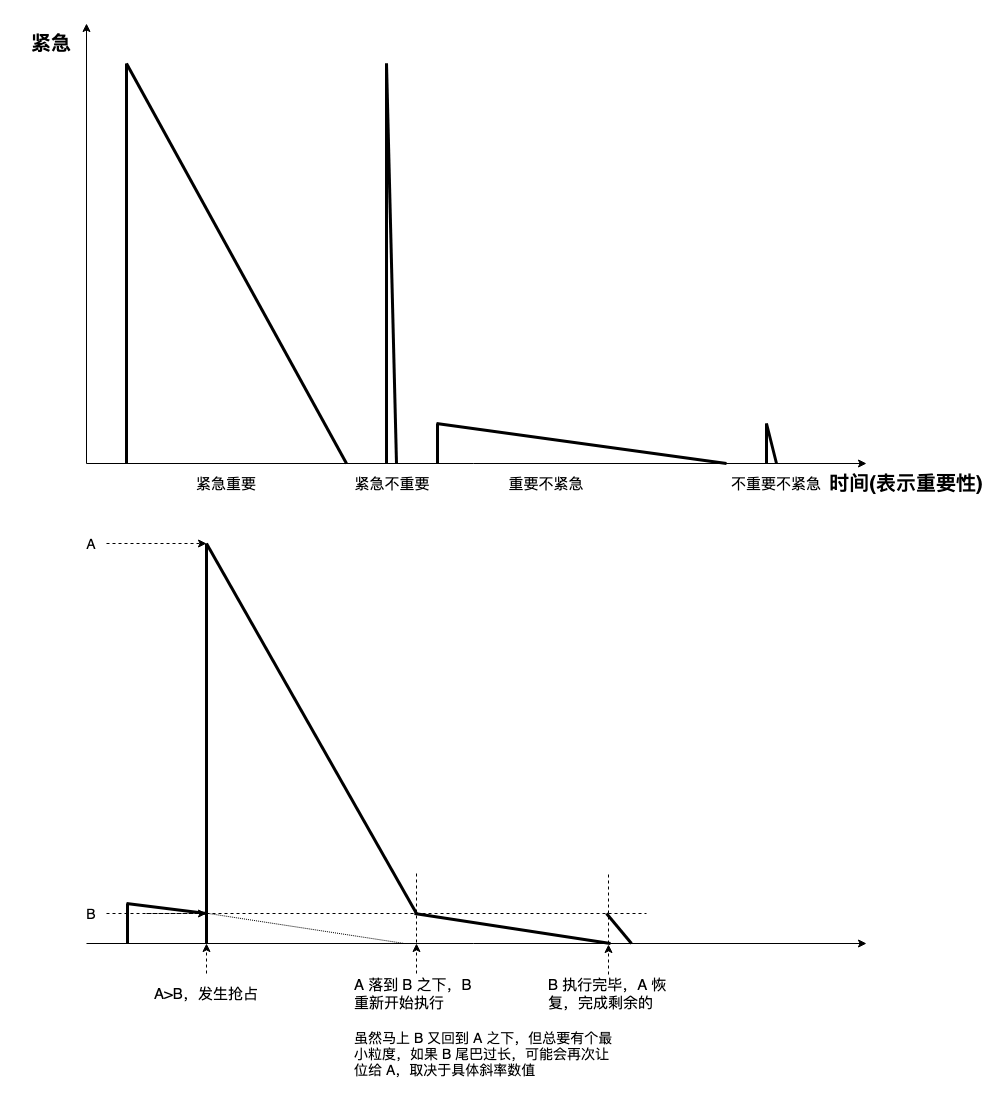
所有 task 展示为各种形状的三角形,这些三角形以图示实例方式不断抢占执行,更矮的三角形被更高的三角形切割,最终什么也不耽误,既能体现紧急程度,又能体现重要性。即使绑核,紧急且重要的 task 仍可获得足够的 CPU 时间,整体看,三角形越宽,获得 CPU 总时间越多,三角形越高,越优先执行。
大概就是 Windows 的样子,优先级在不同事件后根据其紧急性获得不同提升,然后再根据其重要性以负相关的不同速度下降。
注意到 Linux kernel 曾为实时性引入中断线程化,但在现有调度机制下,很难为中断线程适配一个合适的执行权重,但采用上述四象限方法就很容易解决这问题。
Windows,Linux 哪个更好,我没有答案,但有一点很明确,Linux kernel 并非什么都对,但如今它拥有庞大但逐渐封闭的圈子,以至于 Linux kernel 涉及的一切 “越来越合理”,以至于争论不得。本文只谈观点,无意涉足名利场,有时间还是更多聊聊 TCP/IP。
浙江温州皮鞋湿,下雨进水不会胖。