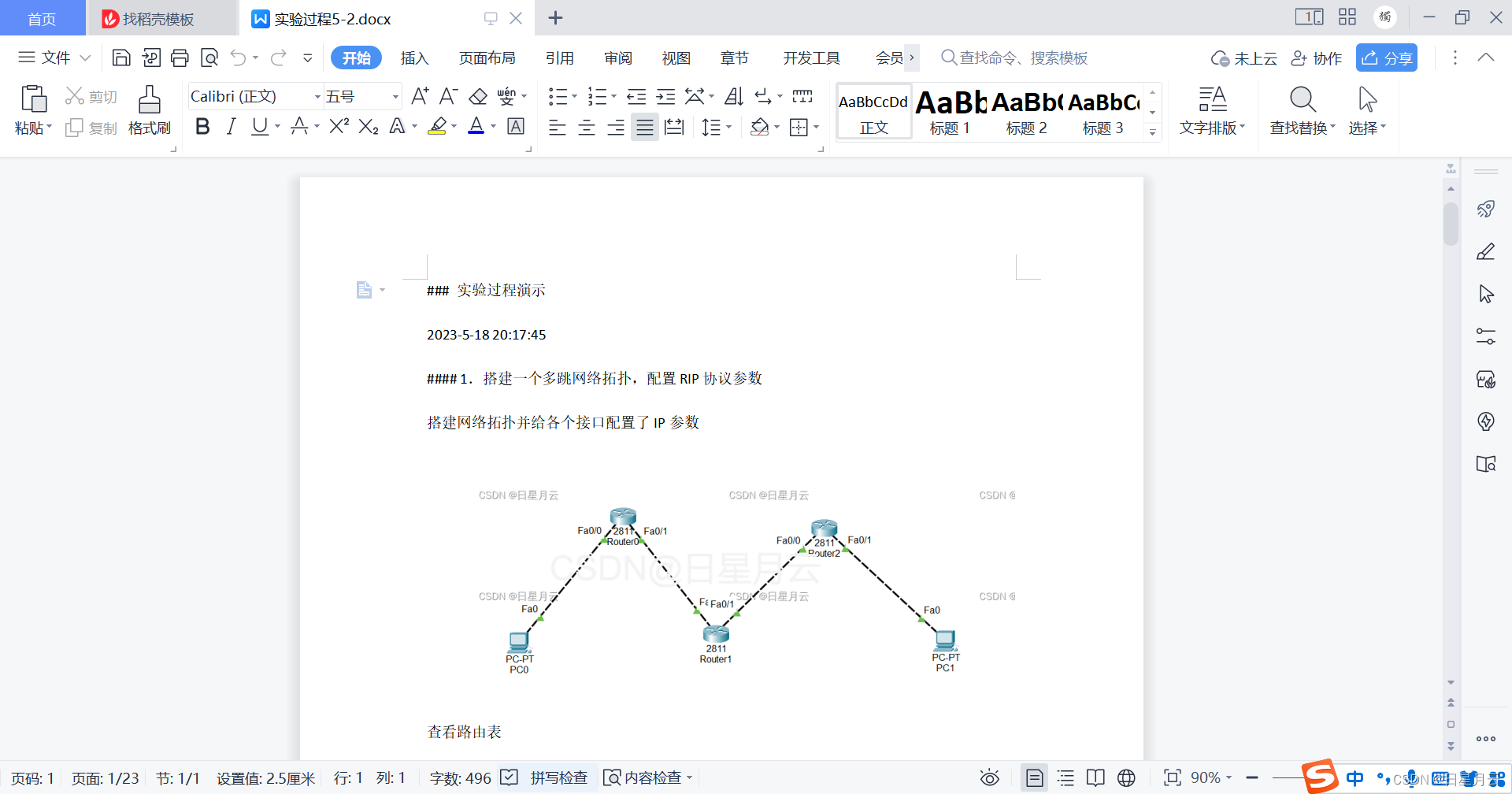
数据偏移:
1、shift函数:
- 在 Pandas 中,shift 函数用于将数组的数据向前或向后平移指定的步数。它可以应用于 Series 或 DataFrame 类型的数据中,并返回一个平移后的新数据结构,其中每个元素都被取代为原始序列中对应位置平移值。
- shift 函数接受一个整数类型的 periods 参数,表示要平移的步数,若该参数为正,则向下平移(即数据后移),若为负,则向上平移(即数据前移)
- 应用实例:求增长率

- 在pandas中求变化率还有一个函数pct_change函数
2、rolling函数:
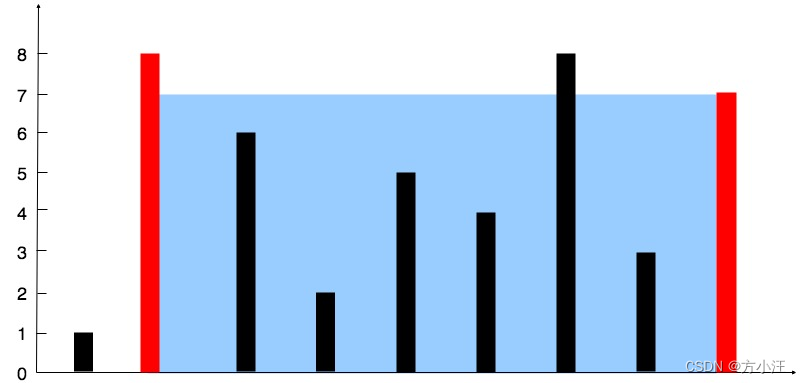
- rolling 函数接受一个 window 参数,表示数据窗口大小,以及一个可选的 min_periods 参数,表示组窗口最小值而不会导致错误结果。然后可以使用许多方法来获得有关每个窗口内的统计信息,例如均值、中位数、和等等
- 注意:窗口每次就向下移动一行,所以前面的n个数据可能是没法满足窗口计算的数据量的,所以要设定最少可计算的行数,这样前面的数据就能够计算了。
- 应用实例:

数据切分
1、数据切分:
- 定义:数据切分其实就是让数据以某个列索引为依据,来按照某种规则划分整个数据。
- 注意:数据切分和数据分组不一样,数据分组本质是分类,而数据切分本质是分段。
2、数据切分会用到的函数总结:
- 函数名:cut
- 参数说明:
- x:必须是一维输入数组,一般就是dataframe数据中某一列数据;
- bins:整型或者列表,是切分的规则;
- right:True表示切分区间是左开右闭,否则是左闭右开;
- 其他参数:【labels,retbins,precision,include_lowest,duplicates,ordered】
- 举例:按照数据中成绩进行数据切分,等距分为10组:tb[‘等距分箱’] = pd.cut(x=tb[‘成绩’], bins=10, right=False)
- 函数名:qcut
- 参数说明:
- x:必须是一维输入数组,一般就是dataframe数据中某一列数据;
- q:整型或者列表,是切分的规则,是分位数,如果是列表的话,应该是0~1之间的数字组成的列表;
- right:True表示切分区间是左开右闭,否则是左闭右开;
- 其他参数:【labels,retbins,precision,dupliactes】
- 举例:按照数据中成绩进行数据切分,等频(每组中的数量基本一致)分为4组:tb[‘等频分箱’] = pd.qcut(x=tb[‘成绩’], q=4)
- 说明:上表中的参数说明中只对必要参数进行了说明,其他参数进行了记录,我也不是很了解,但不影响使用。
数据结构转换
1、字符串内容一列转多列
-
函数名称:str.split()
-
参数:第一个参数是切分标识字符,第二个参数是expand,为True则表示返回的是一个dataframe,为False表示返回的是一个series。
-
举例:


-
注意该方法是明确知道可以分为多少列的,下面一种是不确定可以分为多少列的方法,用到split和join
-
举例:

2、对元组/列表形式的字段进行拆分
- 说明:当然也可以通过字符串处理的方法来完成该任务,但是相对来说这种更简单。
- 举例:

3、数据透视与逆透视
- 数据透视函数名称:pivot()
- 参数:
- index:原来数据中哪个列索引作为新的透视表索引
- columns:原来数据中哪个列索中的所有类作为新的透视表的列名称
- values:原来数据中哪个列索引中的数据作为新的透视表中的值
- 举例:

- 数据逆透视函数名称:melt()
- 参数:
- frame:dataframe数据对象
- id_vars:位置保持不变的字段
- value_vars:列转为行的字段
- var_name:列转为行后,新字段的别名
- value_name:值列的别名
- 举例:

4、DataFrame转为字典或列表
- DataFrame转为字典函数名称:to_dict()
- 举例:

- DataFrame转为列表函数名称:to_dict()
- 说明:dataframe是没法直接转列表的,但是可以先转为数组array类型,然后再转列表
- 举例:

总结:
- 1、pandas是由numpy发展而来的,所以pandas中有很多非常便捷的函数,对于函数的学习无非就是了解其使用场景,掌握参数的意义。
- 2、pandas的很多数据处理工作和函数我自己的感受就是把excel中的功能放到了python中实现,其实在你excel工具使用到炉火纯青的地步也可以在excel中处理好数据,然后再传入python中进行计算分析。当然可能python中通过函数来处理数据的方法计算速度可能更快,同时也可以把所有数据分析的流程放到jupyter中统一完成,就避免了一次数据分析使用多种工具的尴尬。