MeiliSearch是一款开源的全文搜索引擎,它使用Rust编写,具有高效、快速、易用的特点。MeiliSearch支持多种语言,可以轻松地集成到任何应用程序中。它可以处理大量的文本数据,并能够快速地搜索和返回相关的结果。MeiliSearch还提供了一些高级功能,如自定义排名、拼写纠正和同义词处理等,可以帮助用户更好地定制和优化搜索体验。MeiliSearch的API设计简单,易于使用,可以快速地构建和部署搜索功能。
GITHUB地址:https://github.com/meilisearch/MeiliSearch
目录
1、拉取MeiliSearch镜像
2、启动MeiliSearch服务
3、访问MeiliSearch服务
4、Java中使用MeiliSearch
(1)引入依赖
(2)添加索引
(3)基础搜索功能
(4)自定义搜索功能
(5)使用过滤器自定义搜索功能
1、拉取MeiliSearch镜像
docker pull getmeili/meilisearch:latest
2、启动MeiliSearch服务
docker run -itd --rm \
-p 7700:7700 \
-v $(pwd)/meili_data:/meili_data \
getmeili/meilisearch:latest
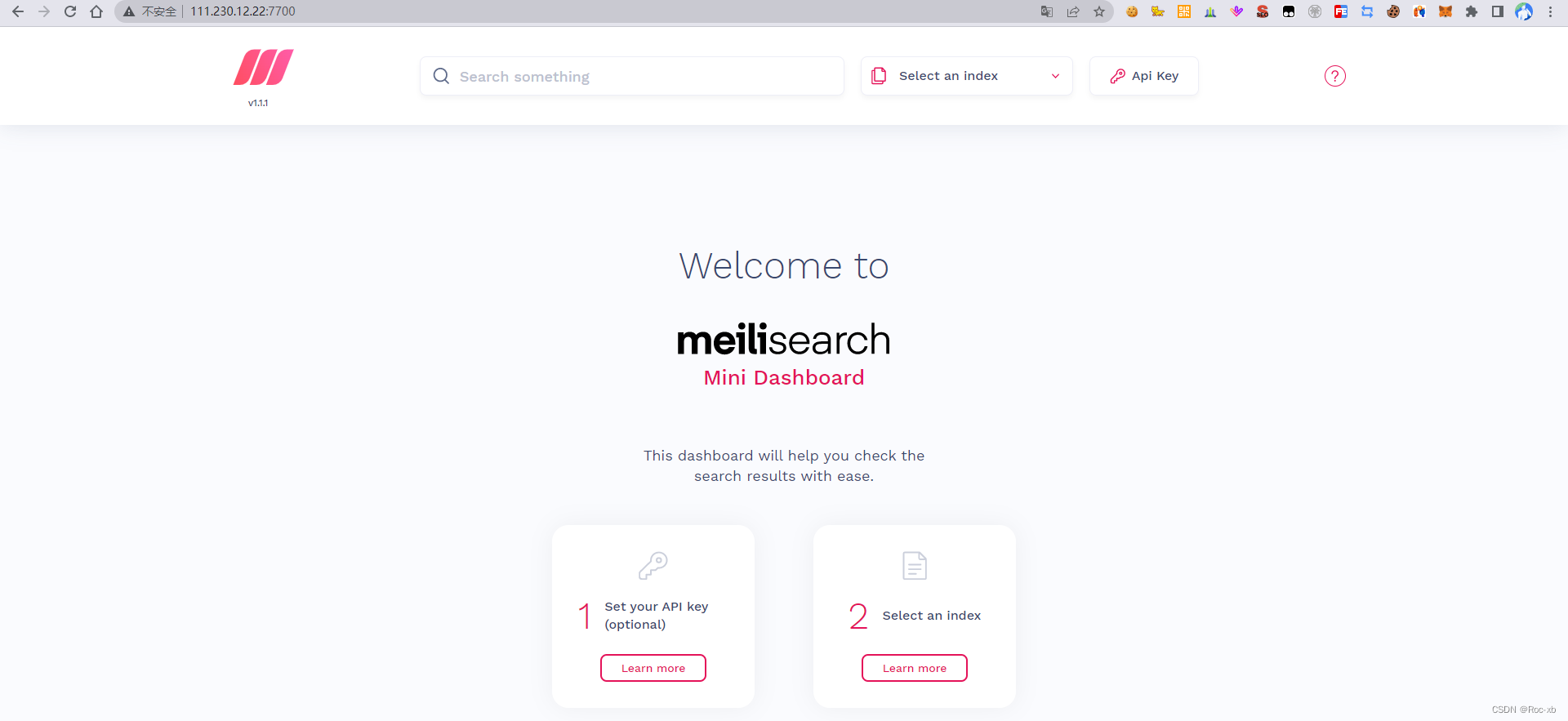
3、访问MeiliSearch服务
启动成功之后,就可以通过ip+端口进行访问了。
例如:http://111.230.12.22:7700/
4、Java中使用MeiliSearch
(1)引入依赖
<dependency>
<groupId>com.meilisearch.sdk</groupId>
<artifactId>meilisearch-java</artifactId>
<version>0.11.1</version>
<type>pom</type>
</dependency>(2)添加索引
package com.meilisearch.sdk;
import org.json.JSONArray;
import org.json.JSONObject;
import java.util.ArrayList;
class TestMeilisearch {
public static void main(String[] args) throws Exception {
JSONArray array = new JSONArray();
ArrayList items = new ArrayList() {{
add(new JSONObject().put("id", "1").put("title", "Carol").put("genres",new JSONArray("[\"Romance\",\"Drama\"]")));
add(new JSONObject().put("id", "2").put("title", "Wonder Woman").put("genres",new JSONArray("[\"Action\",\"Adventure\"]")));
add(new JSONObject().put("id", "3").put("title", "Life of Pi").put("genres",new JSONArray("[\"Adventure\",\"Drama\"]")));
add(new JSONObject().put("id", "4").put("title", "Mad Max: Fury Road").put("genres",new JSONArray("[\"Adventure\",\"Science Fiction\"]")));
add(new JSONObject().put("id", "5").put("title", "Moana").put("genres",new JSONArray("[\"Fantasy\",\"Action\"]")));
add(new JSONObject().put("id", "6").put("title", "Philadelphia").put("genres",new JSONArray("[\"Drama\"]")));
}};
array.put(items);
String documents = array.getJSONArray(0).toString();
Client client = new Client(new Config("http://localhost:7700", "masterKey"));
// An index is where the documents are stored.
Index index = client.index("movies");
// If the index 'movies' does not exist, Meilisearch creates it when you first add the documents.
index.addDocuments(documents); // => { "taskUid": 0 }
}
}(3)基础搜索功能
import com.meilisearch.sdk.model.SearchResult;
// Meilisearch is typo-tolerant:
SearchResult results = index.search("carlo");
System.out.println(results);
// 输出
SearchResult(hits=[{id=1.0, title=Carol, genres:[Romance, Drama]}], offset=0, limit=20, estimatedTotalHits=1, facetDistribution=null, processingTimeMs=3, query=carlo)(4)自定义搜索功能
import com.meilisearch.sdk.SearchRequest;
SearchResult results = index.search(
new SearchRequest("of")
.setShowMatchesPosition(true)
.setAttributesToHighlight(new String[]{"title"})
);
System.out.println(results.getHits());
//输出
[{
"id":3,
"title":"Life of Pi",
"genres":["Adventure","Drama"],
"_formatted":{
"id":3,
"title":"Life <em>of</em> Pi",
"genres":["Adventure","Drama"]
},
"_matchesPosition":{
"title":[{
"start":5.0,
"length":2.0
}]
}
}](5)使用过滤器自定义搜索功能
如果要启用过滤,则必须将属性添加到
filterableAttributes索引设置中。
index.updateFilterableAttributesSettings(new String[]
{
"id",
"genres"
});您只需要执行一次这个操作。
请注意,每当您更新时,MeiliSearch都会重建您的索引filterableAttributes。根据数据集的大小,这可能需要一些时间。您可以使用任务状态跟踪进程。
然后,您可以执行搜索:
index.search(
new SearchRequest("wonder")
.setFilter(new String[] {"id > 1 AND genres = Action"})
);
// 输出
{
"hits": [
{
"id": 2,
"title": "Wonder Woman",
"genres": ["Action","Adventure"]
}
],
"offset": 0,
"limit": 20,
"estimatedTotalHits": 1,
"processingTimeMs": 0,
"query": "wonder"
}更多使用技巧,请参考MeiliSearch的在线文档:Meilisearch Documentation
![[深度学习]大模型训练之框架篇-DeepSpeed](https://img-blog.csdnimg.cn/ab338aaac267488484d9888caebe0c1c.png)