链接
特征
features = ['user_questions', 'user_mean', 'content_questions', 'content_mean', 'prior_question_elapsed_time']
user_df = train[train.answered_correctly != -1].groupby('user_id').agg({'answered_correctly': ['count', 'mean']}).reset_index()
user_df.columns = ['user_id', 'user_questions', 'user_mean']
content_df = train[train.answered_correctly != -1].groupby('content_id').agg({'answered_correctly': ['count', 'mean']}).reset_index()
content_df.columns = ['content_id', 'content_questions', 'content_mean']
train['prior_question_elapsed_time'].fillna(mean_prior, inplace = True)
得分: 0.75
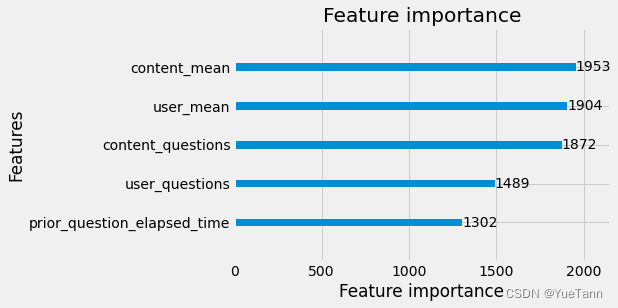
使用的五个特征含义分别是
- 用户回答所有问题的个数
- 用户回答问题的正确率
- 问题被回答的个数总和
- 问题被回答的正确率
- 用户在上一个question bundle中平均消耗时间
特征2
链接
FEATS = ['answered_correctly_avg_u', 'answered_correctly_sum_u', 'count_u', 'answered_correctly_avg_c', 'part', 'prior_question_had_explanation', 'prior_question_elapsed_time']
def add_user_feats(df, answered_correctly_sum_u_dict, count_u_dict):
acsu = np.zeros(len(df), dtype=np.int32)
cu = np.zeros(len(df), dtype=np.int32)
for cnt,row in enumerate(tqdm(df[['user_id','answered_correctly']].values)):
acsu[cnt] = answered_correctly_sum_u_dict[row[0]]
cu[cnt] = count_u_dict[row[0]]
answered_correctly_sum_u_dict[row[0]] += row[1]
count_u_dict[row[0]] += 1
user_feats_df = pd.DataFrame({'answered_correctly_sum_u':acsu, 'count_u':cu})
user_feats_df['answered_correctly_avg_u'] = user_feats_df['answered_correctly_sum_u'] / user_feats_df['count_u']
df = pd.concat([df, user_feats_df], axis=1)
return df
# answered correctly average for each content
content_df = train[['content_id','answered_correctly']].groupby(['content_id']).agg(['mean']).reset_index()
content_df.columns = ['content_id', 'answered_correctly_avg_c']
# changing dtype to avoid lightgbm error
train['prior_question_had_explanation'] = train.prior_question_had_explanation.fillna(False).astype('int8')
得分 0.76
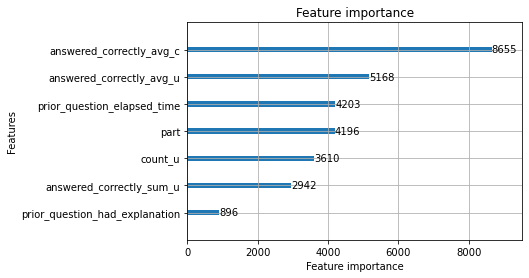
使用的7个特征是
- 使用的特征是增量特征,截止到目前该用户的回答正确率
- 截止到目前该用户回答正确的题目个数
- 截止到目前该用户回答问题所有个数
- content在所有回答中的正确率
- part
- 是否有解释
- 平均消耗时间
特征3
链接
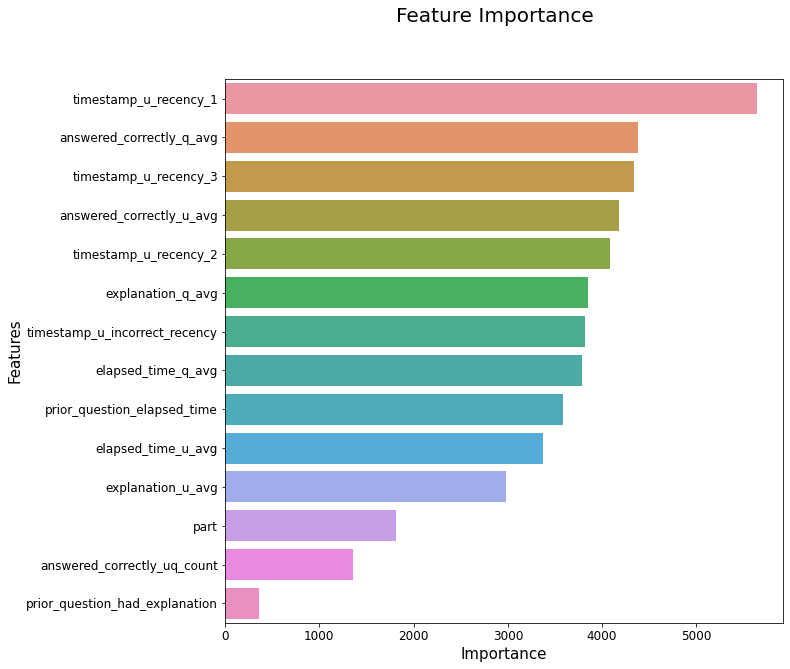
FEATURES = ['prior_question_elapsed_time', 'prior_question_had_explanation', 'part',
'answered_correctly_u_avg', 'elapsed_time_u_avg', 'explanation_u_avg',
'answered_correctly_q_avg', 'elapsed_time_q_avg', 'explanation_q_avg',
'answered_correctly_uq_count', 'timestamp_u_recency_1', 'timestamp_u_recency_2', 'timestamp_u_recency_3',
'timestamp_u_incorrect_recency']
使用的特征14个
特征4
https://www.kaggle.com/code/a763337092/lgb1215
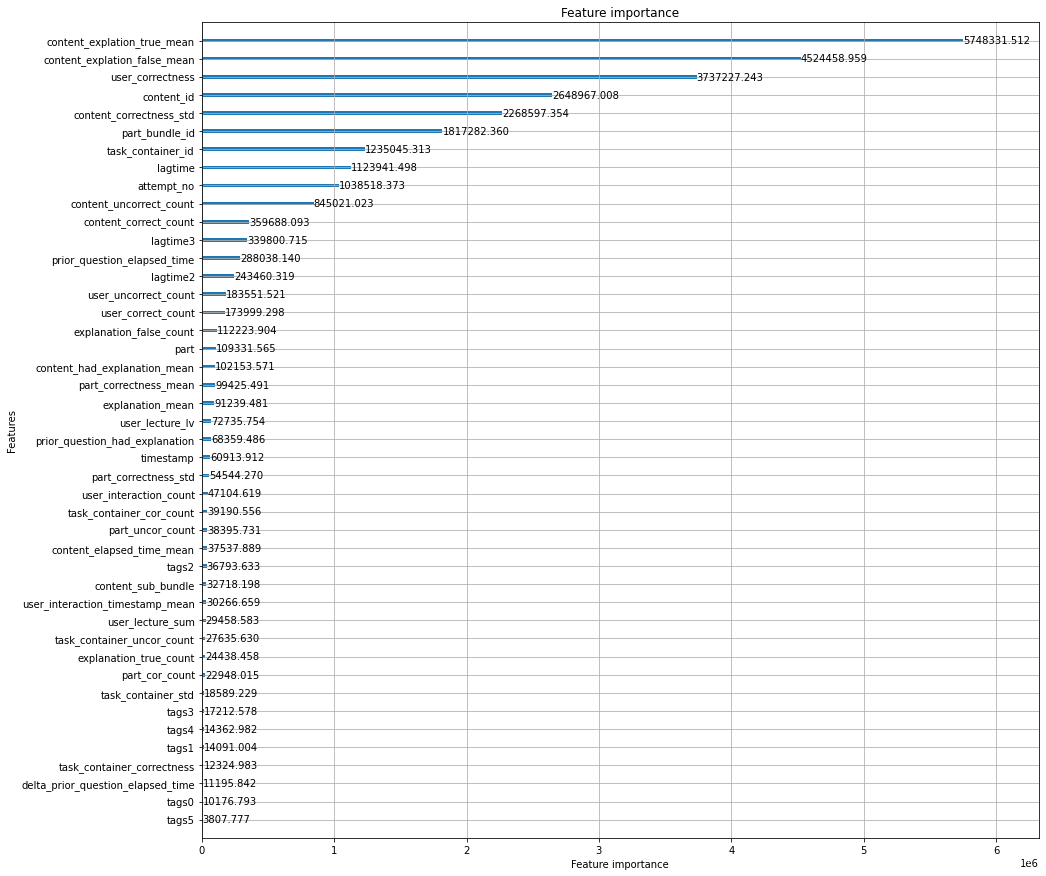
features_dict = {
#'user_id',
'timestamp':'float16',#
'user_interaction_count':'int16',
'user_interaction_timestamp_mean':'float32',
'lagtime':'float32',#
'lagtime2':'float32',
'lagtime3':'float32',
#'lagtime_mean':'int32',
'content_id':'int16',
'task_container_id':'int16',
'user_lecture_sum':'int16',#
'user_lecture_lv':'float16',##
'prior_question_elapsed_time':'float32',#
'delta_prior_question_elapsed_time':'int32',#
'user_correctness':'float16',#
'user_uncorrect_count':'int16',#
'user_correct_count':'int16',#
#'content_correctness':'float16',
'content_correctness_std':'float16',
'content_correct_count':'int32',
'content_uncorrect_count':'int32',#
'content_elapsed_time_mean':'float16',
'content_had_explanation_mean':'float16',
'content_explation_false_mean':'float16',
'content_explation_true_mean':'float16',
'task_container_correctness':'float16',
'task_container_std':'float16',
'task_container_cor_count':'int32',#
'task_container_uncor_count':'int32',#
'attempt_no':'int8',#
'part':'int8',
'part_correctness_mean':'float16',
'part_correctness_std':'float16',
'part_uncor_count':'int32',
'part_cor_count':'int32',
'tags0': 'int8',
'tags1': 'int8',
'tags2': 'int8',
'tags3': 'int8',
'tags4': 'int8',
'tags5': 'int8',
# 'tags6': 'int8',
# 'tags7': 'int8',
# 'tags0_correctness_mean':'float16',
# 'tags1_correctness_mean':'float16',
# 'tags2_correctness_mean':'float16',
# 'tags4_correctness_mean':'float16',
# 'bundle_id':'int16',
# 'bundle_correctness_mean':'float16',
# 'bundle_uncor_count':'int32',
# 'bundle_cor_count':'int32',
'part_bundle_id':'int32',
'content_sub_bundle':'int8',
'prior_question_had_explanation':'int8',
'explanation_mean':'float16', #
#'explanation_var',#
'explanation_false_count':'int16',#
'explanation_true_count':'int16',#
# 'community':'int8',
# 'part_1',
# 'part_2',
# 'part_3',
# 'part_4',
# 'part_5',
# 'part_6',
# 'part_7',
# 'type_of_concept',
# 'type_of_intention',
# 'type_of_solving_question',
# 'type_of_starter'
}
categorical_columns= [
#'user_id',
'content_id',
'task_container_id',
'part',
# 'community',
'tags0',
'tags1',
'tags2',
'tags3',
'tags4',
'tags5',
#'tags6',
#'tags7',
#'bundle_id',
'part_bundle_id',
'content_sub_bundle',
'prior_question_had_explanation',
# 'part_1',
# 'part_2',
# 'part_3',
# 'part_4',
# 'part_5',
# 'part_6',
# 'part_7',
# 'type_of_concept',
# 'type_of_intention',
# 'type_of_solving_question',
# 'type_of_starter'
]
features=list(features_dict.keys())
top solution
https://www.kaggle.com/competitions/riiid-test-answer-prediction/discussion/209597
- Firstly, the data are sorted by [‘user_id’, ‘timestamp’, ‘content_id’]
- created features in different array via self-designed rolling function or self-designed cumlative function
- use catboost
https://www.kaggle.com/code/tomooinubushi/62nd-solution-lightgbm-single-model-lb-0-801