一、介绍
今天和大家一起学习下使用LangChain+LLM 来构建本地知识库。
我们先来了解几个名词。
二、什么是LLM?
LLM指的是大语言模型(Large Language Models),大语言模型(LLM)是指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。大语言模型可以处理多种自然语言任务,如文本分类、问答、对话等,是通向人工智能的一条重要途径。
所以,LLM就是AI模型。
三、什么是Embeddings?
embedding中文翻译为嵌入,并不能很好的理解embedding的概念。我们看一下OpenAI的文档是怎么解释:

用中文翻译总结一下就是:
嵌入(Embedding)是一种将文本或对象转换为向量表示的技术,将词语、句子或其他文本形式转换为固定长度的向量表示。嵌入向量是由一系列浮点数构成的向量。通过计算两个嵌入向量之间的距离,可以衡量它们之间的相关性。距离较小的嵌入向量表示文本之间具有较高的相关性,而距离较大的嵌入向量表示文本之间相关性较低。
embedding在自然语言处理的许多任务中发挥重要作用。例如:
- 在搜索任务中,可以使用embedding来度量查询字符串与文本结果之间的相关性,从而对搜索结果进行排序。
- 在聚类任务中,可以使用embedding将相似的文本字符串进行分组。
- 在推荐系统中,可以根据embedding的相似性来推荐与用户兴趣相关的文本或物品。
- 还可用于异常检测、多样性分析和文本分类等任务。
总之,Embedding是将文本或对象转换为向量表示的技术,可以衡量文本之间的相关性,在各种自然语言处理任务中发挥重要作用。
四、LangChain🦜️🔗
ok,上面解释了LLM和Embedding的概念,我们现在来介绍一下LangChain是什么?
LangChain是一个基于语言模型开发应用程序的框架。可以将语言模型与其他数据源相连接,并允许语言模型与环境进行交互,提供了丰富的API。
官方文档:https://python.langchain.com/en/latest/index.html
Github(已经有4W多的star):https://github.com/hwchase17/langchain
更多关于LangChain的内容,大家可以自行查阅文档研究。这里给大家简单介绍几个组件。
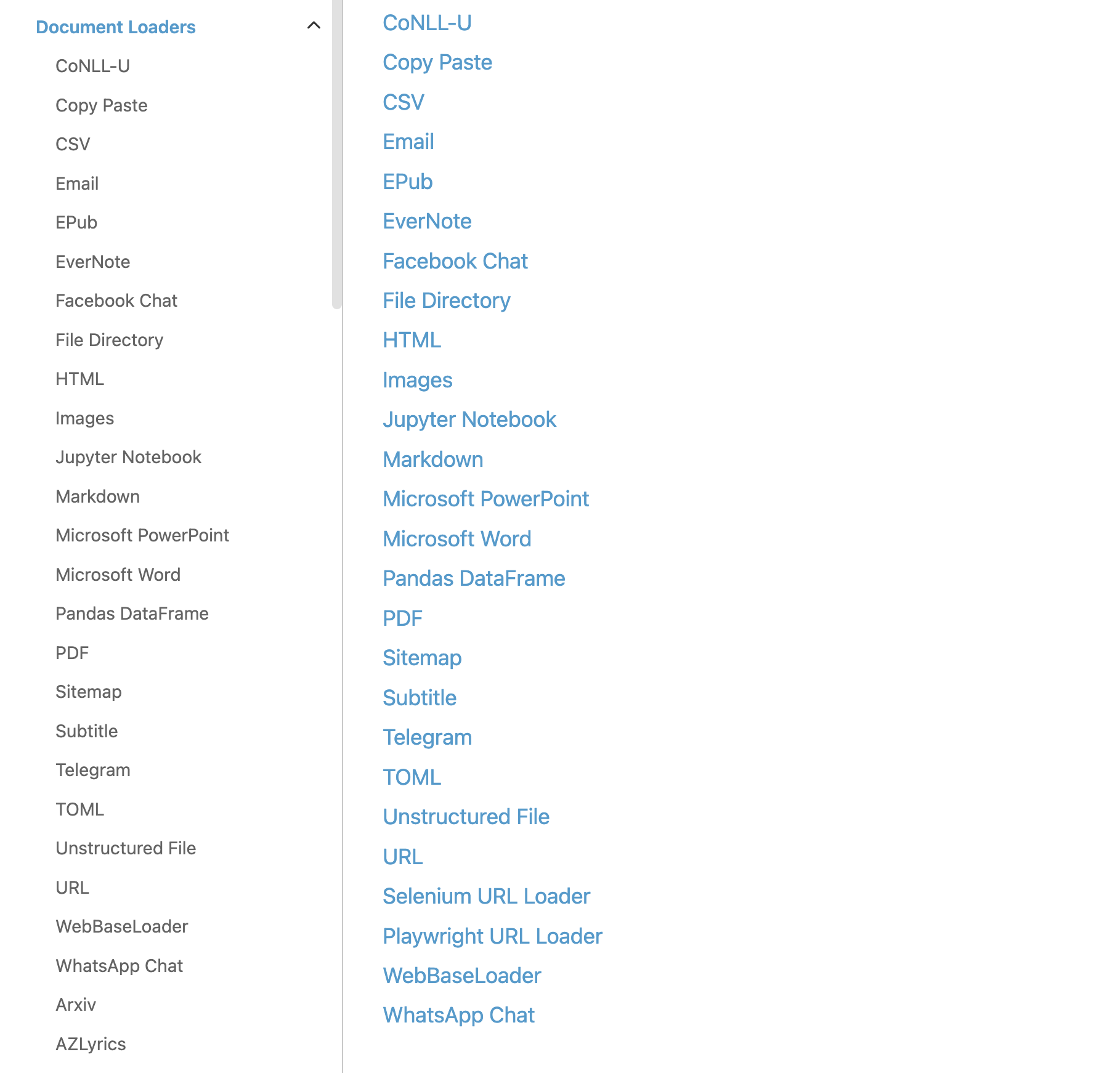
4.1 Document Loader 文档加载器
文档加载器可以将我们的文件加载到内存中,例如txt、md、csv、pdf,甚至是B站视频都可以直接通过Document Loaders加载到内存中。LangChain提供了各种文件格式的文档加载器:
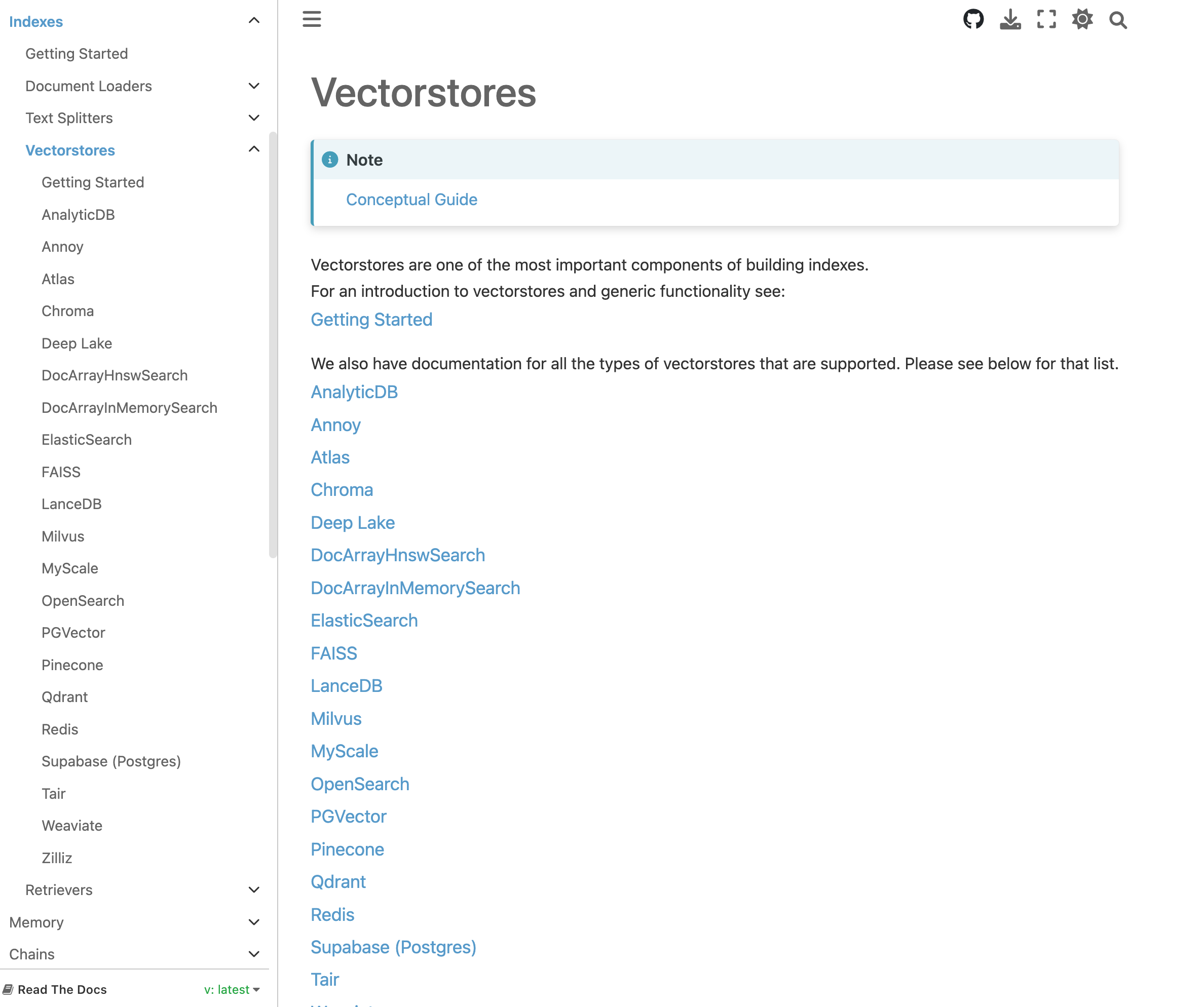
4.2 Vectorstore 矢量数据库
在上一步通过Document Loader将我们的文档加载到内存中,然后通过Embedding Model将文字转化为向量,Vectorstore要做的就是把这些向量存储起来,并且提供快速查找文档内容的接口(即Retrievers)。
同样,LangChain也提供了丰富的方式作为Vectorstore:
4.3 Question Answering over Docs (代码)
ok,了解了以上的概念之后,现在我们开始构建我们自己的知识库。
主要流程:
- 加载文档
- 文本分割
- 构建矢量数据库
- 引入LLM
- 创建qa_chain,开始提问
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
import os
os.environ["OPENAI_API_KEY"] = "OPENAI_API_KEY"
"""
Question Answering Chain
"""
with open("../test.txt") as f:
state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts(texts, embeddings, metadatas=[{"source": str(i)} for i in range(len(texts))]).as_retriever()
query = "What did the president say about Justice Breyer"
docs = docsearch.get_relevant_documents(query)
chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff")
answer = chain.run(input_documents=docs, question=query)
print(answer)
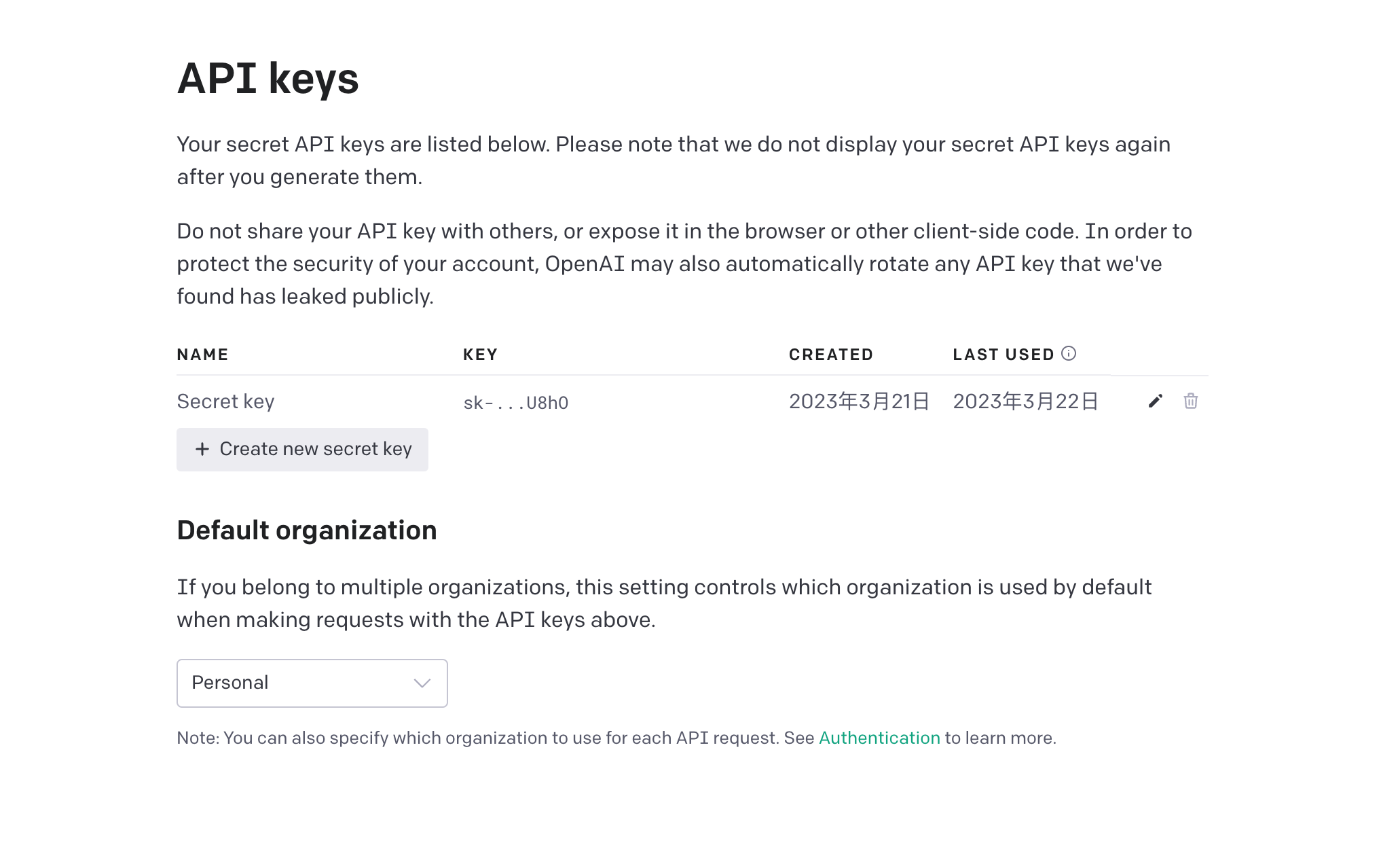
ok,其实到这里我们的本地知识库就完成了,但是上面的OpenAIEmbeddings()和OpenAI()中,默认使用的都是OpenAI公司的模型,是需要OpenAI API Key的,这个需要注册OpenAI账号,是有几美元的免费额度的,但是现在官方已经停止注册了,并且免费额度是会过期的,如果想要继续使用,就需要添加国外信用卡支付方式,这个也是很麻烦的。所以我们就只能使用其他开源的AI模型。
五Huggingface🤗
Hugging Face是一个为自然语言处理(NLP)开发者提供工具和库的开源社区和平台。该平台提供了丰富的NLP模型和预训练模型。
我们可以使用开源的google/flan-t5-xlAI模型
5.1 使用Huggingface开源AI模型构建本地知识库
from langchain import HuggingFacePipeline
from langchain.chains import RetrievalQA
from langchain.chains.question_answering import load_qa_chain
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms.base import LLM
import os
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
os.environ["HUGGINGFACEHUB_API_TOKEN"] = 'HUGGINGFACEHUB_API_TOKEN'
# Document Loaders
loader = TextLoader('../example_data/test.txt', encoding='utf8')
documents = loader.load()
# Text Splitters
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select embeddings
embeddings = HuggingFaceEmbeddings()
# create vectorstores
db = Chroma.from_documents(texts, embeddings)
# Retriever
retriever = db.as_retriever(search_kwargs={"k": 2})
query = "what is embeddings?"
docs = retriever.get_relevant_documents(query)
for item in docs:
print("page_content:")
print(item.page_content)
print("source:")
print(item.metadata['source'])
print("---------------------------")
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-xl")
model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-xl")
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=512,
temperature=0,
top_p=0.95,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=pipe)
chain = load_qa_chain(llm, chain_type="stuff")
llm_response = chain.run(input_documents=docs, question=query)
print(llm_response)
print("done.")
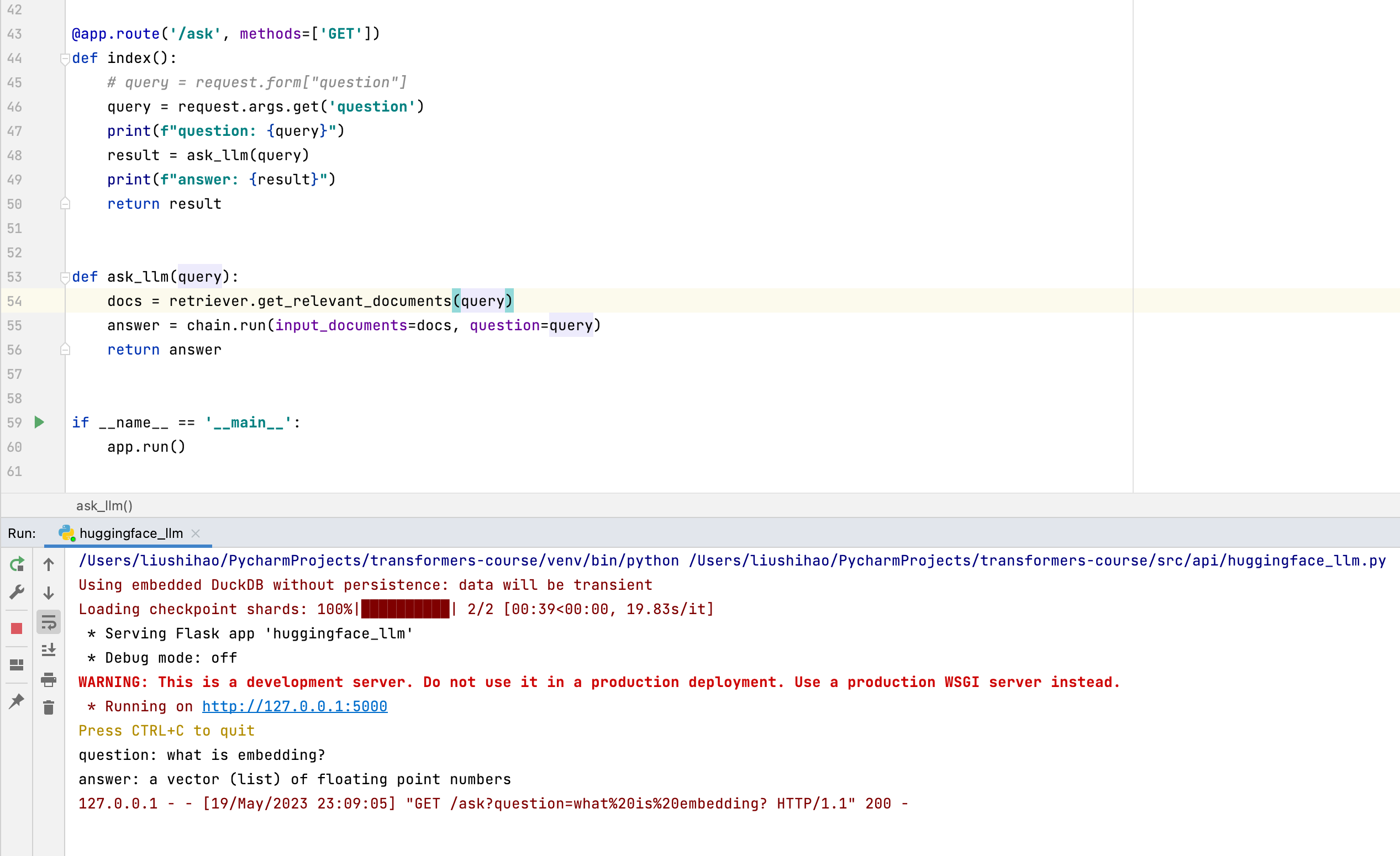
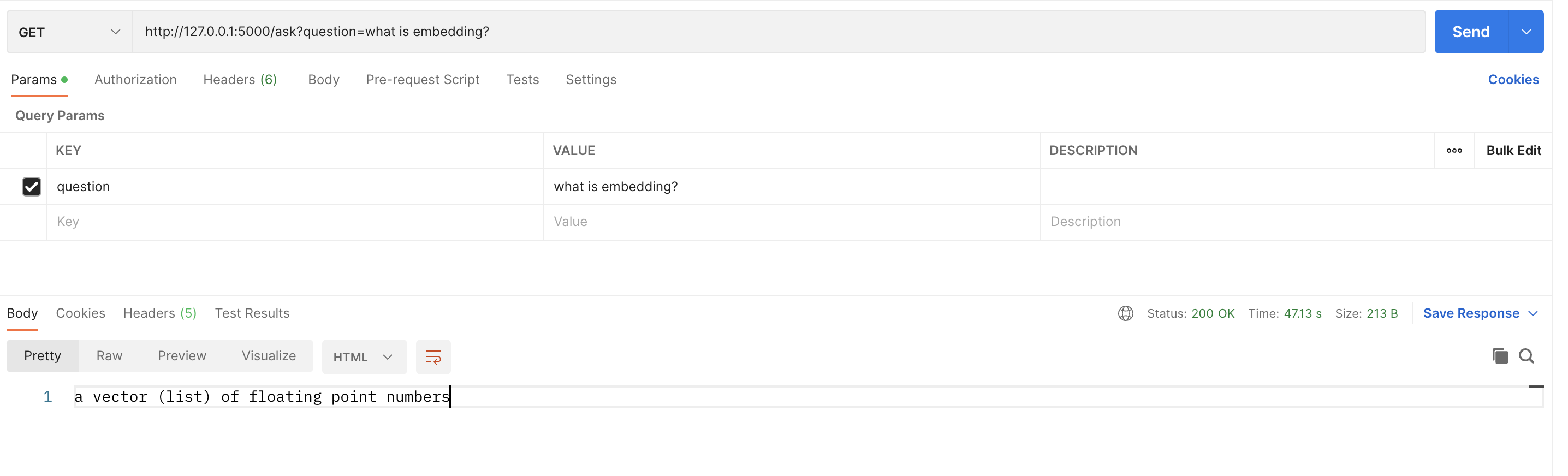
5.2 使用Flask构建 Web API
另外使用Flask构建Web API,实现问答机器人
六、最后
源码已上传https://github.com/Liu-Shihao/transformers-course
如果您有什么问题或者经验,欢迎评论区交流。
如果您觉得本文对您有帮助,欢迎点赞、评论、分享。
您的支持是我创作的最大动力。