作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263?spm=1001.2101.3001.5343
邮箱 :291148484@163.com
本文地址:https://blog.csdn.net/qq_28550263/article/details/114637220
保留版权,禁止盗用!
关于本文
大概 2020 年,我参加了一个机器学习兴趣培训,其中部分课程的总结笔记在来年经过整理后放到了我的博客上。可能由于关于决策树算法这部分的比较多,收到了很多邮件,都时想要这部分完整实现和应用的。只是之前整理笔记时没有找到当时的作业了,也没时间去重写,因此一直没有发表这篇文章。好在再后来翻旧文件的时候,找到了这个报告,不过本文里面用到的数据集仍然没找回。我记忆中是一个由著名的 XX联盟 多塔游戏之母公司提供的,多年前将算法任务发布到某网站上,如果有找到这个数据集的朋友可以在评论区留下一个地址,或者是分享该任务数据集的链接,作为给新学习机器学习算法的朋友提供的帮助,不胜感激。另外,下面是以前发布过的相关知识点的总结文章:
部分关联文章链接
- 《决策树学习中如何进行分类预测》:https://blog.csdn.net/qq_28550263/article/details/114995553
- 《决策树如何分裂以拓展节点》: https://blog.csdn.net/qq_28550263/article/details/114967776
- 《决策树中,信息增益、信息增益率计算以及最佳特征挑选的Python实现》:https://blog.csdn.net/qq_28550263/article/details/114891368
- 《决策树中混杂度数值度量的Python编程实现(信息熵和基尼系数的计算)》:https://blog.csdn.net/qq_28550263/article/details/114883862
目 录
- 关于本文
- 部分关联文章链接
- 导入工具包
- 读入数据
- 数据概览
- 增删特征
- 观察特征的取值数量分布
- 特征离散化
- 离散化
- 数据集准备
- 决策树模型的实现
- ⚪ 决策树建立主要应该有两个相互区别又互相统一的方面:一个是如何生长,另外一个是如何在适当时候停止(以免过拟合)。
- ⚪ 决策树预测:
- ⚪单独定义决策树中需要的一些额外数据计算函数
- (1)计算不确定度(不纯度)
- (2)计算信息增益和信息增益比
- 寻找预剪枝最佳参数
- 参数测试结论
- 总结
导入工具包
pandas是数据分析和处理常用的工具包,非常适合处理行列表格数据。numpy是数学运算工具包,支持高效的矩阵、向量运算。sklearn是机器学习常用工具包,包括了一些已经实现好的简单模型和一些常用数据处理方法、评价指标等函数。
from collections import Counter
RANDOM_SEED = 2020 # 固定随机种子
读入数据
假设数据文件放在./data/目录下,标准的csv文件可以用pandas里的read_csv()函数直接读入。文件共有40列,38个特征(红蓝方各19),1个标签列(blueWins),和一个对局标号(gameId)。对局标号不是标签也不是特征,可以舍去。
import pandas as pd
csv_data = './data/high_diamond_ranked_10min.csv' # 数据路径
data_df = pd.read_csv(csv_data, sep=',') # 读入csv文件为pandas的DataFrame
data_df = data_df.drop(columns='gameId') # 舍去对局标号列
数据概览
对于一个机器学习问题,在拿到任务和数据后,首先需要观察数据的情况,比如我们可以通过.iloc[0]取出数据的第一行并输出。不难看出每个特征都存成了float64浮点数,该对局蓝色方开局10分钟有小优势。同时也可以发现有些特征列是重复冗余的,比如blueGoldDiff表示蓝色队金币优势,redGoldDiff表示红色方金币优势,这两个特征是完全对称的互为相反数。blueCSPerMin是蓝色方每分钟击杀小兵数,它乘10就是10分钟所有小兵击杀数blueTotalMinionsKilled。在之后的特征处理过程中可以考虑去除这些冗余特征。
另外,pandas有非常方便的describe()函数,可以直接通过DataFrame进行调用,可以展示每一列数据的一些统计信息,对数据分布情况有大致了解,比如blueKills蓝色方击杀英雄数在前十分钟的平均数是6.14、方差为2.93,中位数是6,百分之五十以上的对局中该特征在4-8之间,等等。
print(data_df.iloc[0]) # 输出第一行数据
data_df.describe() # 每列特征的简单统计信息
blueWins 0.0
blueWardsPlaced 28.0
blueWardsDestroyed 2.0
blueFirstBlood 1.0
blueKills 9.0
blueDeaths 6.0
blueAssists 11.0
blueEliteMonsters 0.0
blueDragons 0.0
blueHeralds 0.0
blueTowersDestroyed 0.0
blueTotalGold 17210.0
blueAvgLevel 6.6
blueTotalExperience 17039.0
blueTotalMinionsKilled 195.0
blueTotalJungleMinionsKilled 36.0
blueGoldDiff 643.0
blueExperienceDiff -8.0
blueCSPerMin 19.5
blueGoldPerMin 1721.0
redWardsPlaced 15.0
redWardsDestroyed 6.0
redFirstBlood 0.0
redKills 6.0
redDeaths 9.0
redAssists 8.0
redEliteMonsters 0.0
redDragons 0.0
redHeralds 0.0
redTowersDestroyed 0.0
redTotalGold 16567.0
redAvgLevel 6.8
redTotalExperience 17047.0
redTotalMinionsKilled 197.0
redTotalJungleMinionsKilled 55.0
redGoldDiff -643.0
redExperienceDiff 8.0
redCSPerMin 19.7
redGoldPerMin 1656.7
Name: 0, dtype: float64
| blueWins | blueWardsPlaced | blueWardsDestroyed | blueFirstBlood | blueKills | blueDeaths | blueAssists | blueEliteMonsters | blueDragons | blueHeralds | ... | redTowersDestroyed | redTotalGold | redAvgLevel | redTotalExperience | redTotalMinionsKilled | redTotalJungleMinionsKilled | redGoldDiff | redExperienceDiff | redCSPerMin | redGoldPerMin | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | ... | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 | 9879.000000 |
| mean | 0.499038 | 22.288288 | 2.824881 | 0.504808 | 6.183925 | 6.137666 | 6.645106 | 0.549954 | 0.361980 | 0.187974 | ... | 0.043021 | 16489.041401 | 6.925316 | 17961.730438 | 217.349226 | 51.313088 | -14.414111 | 33.620306 | 21.734923 | 1648.904140 |
| std | 0.500024 | 18.019177 | 2.174998 | 0.500002 | 3.011028 | 2.933818 | 4.064520 | 0.625527 | 0.480597 | 0.390712 | ... | 0.216900 | 1490.888406 | 0.305311 | 1198.583912 | 21.911668 | 10.027885 | 2453.349179 | 1920.370438 | 2.191167 | 149.088841 |
| min | 0.000000 | 5.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 11212.000000 | 4.800000 | 10465.000000 | 107.000000 | 4.000000 | -11467.000000 | -8348.000000 | 10.700000 | 1121.200000 |
| 25% | 0.000000 | 14.000000 | 1.000000 | 0.000000 | 4.000000 | 4.000000 | 4.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 15427.500000 | 6.800000 | 17209.500000 | 203.000000 | 44.000000 | -1596.000000 | -1212.000000 | 20.300000 | 1542.750000 |
| 50% | 0.000000 | 16.000000 | 3.000000 | 1.000000 | 6.000000 | 6.000000 | 6.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 16378.000000 | 7.000000 | 17974.000000 | 218.000000 | 51.000000 | -14.000000 | 28.000000 | 21.800000 | 1637.800000 |
| 75% | 1.000000 | 20.000000 | 4.000000 | 1.000000 | 8.000000 | 8.000000 | 9.000000 | 1.000000 | 1.000000 | 0.000000 | ... | 0.000000 | 17418.500000 | 7.200000 | 18764.500000 | 233.000000 | 57.000000 | 1585.500000 | 1290.500000 | 23.300000 | 1741.850000 |
| max | 1.000000 | 250.000000 | 27.000000 | 1.000000 | 22.000000 | 22.000000 | 29.000000 | 2.000000 | 1.000000 | 1.000000 | ... | 2.000000 | 22732.000000 | 8.200000 | 22269.000000 | 289.000000 | 92.000000 | 10830.000000 | 9333.000000 | 28.900000 | 2273.200000 |
8 rows × 39 columns
增删特征
传统的机器学习模型大部分都是基于特征的,因此特征工程是机器学习中非常重要的一步。有时构造一个好的特征比改进一个模型带来的提升更大。这里简单展示一些特征处理的例子。首先,上面提到,特征列中有些特征信息是完全冗余的,会给模型带来不必要的计算量,可以去除。其次,相比于红蓝双方击杀、助攻的绝对值,可能双方击杀英雄的差值更能体现出当前对战的局势。因此,我们可以构造红蓝双方对应特征的差值。数据文件中已有的差值是金币差GoldDiff和经验差ExperienceDiff,实际上每个对应特征都可以构造这样的差值特征。
drop_features = ['blueGoldDiff', 'redGoldDiff',
'blueExperienceDiff', 'redExperienceDiff',
'blueCSPerMin', 'redCSPerMin',
'blueGoldPerMin', 'redGoldPerMin'] # 需要舍去的特征列
df = data_df.drop(columns=drop_features) # 舍去特征列
info_names = [c[3:] for c in df.columns if c.startswith('red')] # 取出要作差值的特征名字(除去red前缀)
for info in info_names: # 对于每个特征名字
df['br' + info] = df['blue' + info] - df['red' + info] # 构造一个新的特征,由蓝色特征减去红色特征,前缀为br
# 其中FirstBlood为首次击杀最多有一只队伍能获得,brFirstBlood=1为蓝,0为没有产生,-1为红
df = df.drop(columns=['blueFirstBlood', 'redFirstBlood']) # 原有的FirstBlood可删除
df
| blueWins | blueWardsPlaced | blueWardsDestroyed | blueKills | blueDeaths | blueAssists | blueEliteMonsters | blueDragons | blueHeralds | blueTowersDestroyed | ... | brAssists | brEliteMonsters | brDragons | brHeralds | brTowersDestroyed | brTotalGold | brAvgLevel | brTotalExperience | brTotalMinionsKilled | brTotalJungleMinionsKilled | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 28 | 2 | 9 | 6 | 11 | 0 | 0 | 0 | 0 | ... | 3 | 0 | 0 | 0 | 0 | 643 | -0.2 | -8 | -2 | -19 |
| 1 | 0 | 12 | 1 | 5 | 5 | 5 | 0 | 0 | 0 | 0 | ... | 3 | -2 | -1 | -1 | -1 | -2908 | -0.2 | -1173 | -66 | -9 |
| 2 | 0 | 15 | 0 | 7 | 11 | 4 | 1 | 1 | 0 | 0 | ... | -10 | 1 | 1 | 0 | 0 | -1172 | -0.4 | -1033 | -17 | 18 |
| 3 | 0 | 43 | 1 | 4 | 5 | 5 | 1 | 0 | 1 | 0 | ... | -5 | 1 | 0 | 1 | 0 | -1321 | 0.0 | -7 | -34 | 8 |
| 4 | 0 | 75 | 4 | 6 | 6 | 6 | 0 | 0 | 0 | 0 | ... | -1 | -1 | -1 | 0 | 0 | -1004 | 0.0 | 230 | -15 | -10 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 9874 | 1 | 17 | 2 | 7 | 4 | 5 | 1 | 1 | 0 | 0 | ... | -2 | 1 | 1 | 0 | 0 | 2519 | 0.4 | 2469 | -18 | 35 |
| 9875 | 1 | 54 | 0 | 6 | 4 | 8 | 1 | 1 | 0 | 0 | ... | 5 | 1 | 1 | 0 | 0 | 782 | 0.2 | 888 | 27 | -8 |
| 9876 | 0 | 23 | 1 | 6 | 7 | 5 | 0 | 0 | 0 | 0 | ... | -6 | -1 | -1 | 0 | 0 | -2416 | -0.4 | -1877 | -51 | -15 |
| 9877 | 0 | 14 | 4 | 2 | 3 | 3 | 1 | 1 | 0 | 0 | ... | 2 | 1 | 1 | 0 | 0 | -839 | -0.6 | -1085 | -23 | 8 |
| 9878 | 1 | 18 | 0 | 6 | 6 | 5 | 0 | 0 | 0 | 0 | ... | 1 | -1 | -1 | 0 | 0 | 927 | 0.2 | -58 | 6 | -2 |
9879 rows × 44 columns
part2
作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263?spm=1001.2101.3001.5343
关于本文
邮箱 :291148484@163.com
本文地址:https://blog.csdn.net/qq_28550263/article/details/114637220
保留版权,禁止盗用!!!
观察特征的取值数量分布
discrete_df = df.copy() # 先复制一份数据
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import pylab
def barchart_ax(discrete_df, title='各个特征取值数量统计', xlabel='特征名称', ylabel='特征的不同取值量', background_color= "#EAEAF2", Batch1_color = "#25AFF3"):
feature_values = []
x_text = []
for c in discrete_df.columns[1:]:
x_text.append(c)
ct = discrete_df[c].duplicated(keep ='first')
feature_values.append(len(ct[ct==False]))
batch1=feature_values
pylab.rcParams['figure.figsize'] = (19.0, 10.0)
plt.rcParams['font.sans-serif'] = ['KaiTi']
matplotlib.rcParams['axes.unicode_minus'] = False
x = np.arange(len(x_text))
width = 0.66
fig, ax = plt.subplots()
rects = ax.bar(x - width/2, batch1, width, color = Batch1_color)
ax.patch.set_facecolor(background_color)
ax.set_title(title, fontsize=26)
ax.set_xlabel(xlabel, fontsize=22)
ax.set_ylabel(ylabel, fontsize=22)
ax.set_xticks(x)
ax.set_xticklabels(x_text, fontsize=22)
for rect in rects:
height = rect.get_height()
ax.annotate('{}'.format(height),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0,3),
textcoords="offset points",
ha='center', va='bottom')
plt.grid(linestyle = "dotted",color = "g")
plt.xticks(rotation=89)
fig.tight_layout()
plt.show()
barchart_ax(discrete_df)
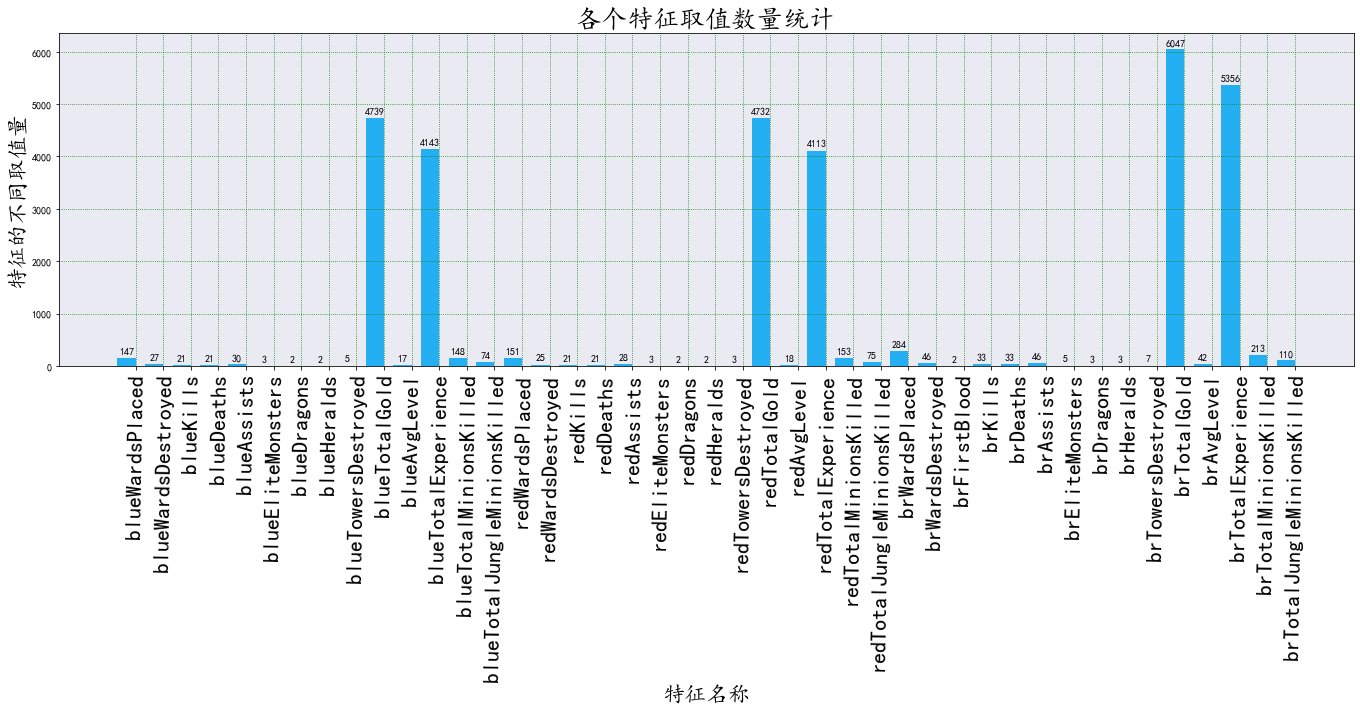
特征离散化
决策树ID3算法一般是基于离散特征的,本例中存在很多连续的数值特征,例如队伍金币。直接应用该算法每个值当作一个该特征的一个取值可能造成严重的过拟合,因此需要对特征进行离散化,即将一定范围内的值映射成一个值,例如对用户年龄特征,将0-10映射到0,11-18映射到1,19-25映射到2,25-30映射到3,等等类似,然后在决策树构建时使用映射后的值计算信息增益。
定义离散化类
import pandas as pd
import numpy as np
import pandas as pd
import numpy as np
class discretization(object):
"""
离散化类:提供几种可供选择的离散化方法。
离散化就是将特征中多个不同的特征值用相对少的取值表示。
每种离散化方法一次工作中对特定的列(特征)进行离散化操作,返回被离散的列的离散化结果
如果最终需要获取完成所有特征离散化的DataFrame,则使用该类实例的DF属性(discretization.DF)即可
"""
def __init__(self,DataF):
"""
初始化:拷贝一份传入的DataFrame。
仅当各备选的离散化方法中,submit = True 时,将改变 self.DF 中该列特征的数据。
"""
self.DF = DataF.copy()
def scaling(self,feature,scale,submit=True):
"""
离散化备选方法1:
数据尺度缩小法离散化——该方法法通过将数值除以特定的数来进行离散化。
Parameters
-------
- feature: str,特征名,将用作从DF中索引该列特征的有序所有取值
- scale: 该列特征数值的放缩尺度。
- submit: bool,离散化后直接提交更改到self.DF中的该特征
"""
dis_feature = self.DF[feature].copy()
dis_feature = np.array(np.floor(np.array(self.DF[feature]/scale)))
if submit:
self.DF[feature] = dis_feature
return dis_feature
def pd_cut(self,feature,bins,submit=True):
"""
离散化备选方法2:
按数值区间分割数据离散化——先按照数据取值将数据分割成n组。
Parameters
-------
- feature: str,特征名,将用作从DF中索引该列特征的有序所有取值
- bins: 若为Series,则序列中数据元素各为分割点;
若为int,则特征值定义范围内的等宽bin数。x的范围在每一侧
都扩展了0.1%,以包括x的最小值和最大值。
- submit: bool,离散化后直接提交更改到self.DF中的该特征
"""
dis_feature = self.DF[feature].copy()
dis_feature = pd.cut(dis_feature ,bins)
if submit:
self.DF[feature] = dis_feature
return dis_feature
def pd_qcut(self,feature,q,submit=True,**kw):
"""
离散化备选方法3:
等元素个数分割数据离散化——分割后每个存储组有相同元素个数。
Parameters
-------
- feature: str,特征名,将用作从DF中索引该列特征的有序所有取值
- q: 频数,int,也就是分割后的组数
- q_label: serial,分割后,必须用新的标签代表旧的数据,标签数目必
须和分割的频数对应一致
- submit: bool,离散化后直接提交更改到self.DF中的该特征
"""
if kw.get('q_label') != None:
q_label = kw.get('q_label')
else:
q_label = list(range(q))
dis_feature = self.DF[feature].copy()
dis_feature = pd.qcut(dis_feature,q,q_label,duplicates="drop") # duplicates="drop"表示如果bin边缘(每组的分位点处)不是唯一则丢弃非唯一变量
if submit:
self.DF[feature] = dis_feature
return dis_feature
# Discretization = discretization(discrete_df)
# Discretization.scaling('brTotalGold',scale=100) # 采用数值尺度缩小进行离散化
# Discretization.pd_cut('brTotalGold',[-10830,-5845,0,6135,11467]) # 划分为[(-10830, -5845] < (-5845, 0] < (0, 6135] < (6135, 11467]]
# Discretization.pd_qcut('brTotalGold',10) # 采用等频(元素个数)分割进行离散化
# barchart_ax(Discretization.DF)
离散化
上面给出了三种离散化方法,但是实际上它们并不都适用于本任务。如果使用方法一和方法二有个问题就是离散化后的存储组中将有恕不不一样的数据,并且有可能导致某些存储组再训练时样本特别多,二有些存储组样本少。因此决定使用方法三,以保证离散化后的特征每组具有相同样本的数量。
Discretization = discretization(discrete_df)
for c in df.columns[1:]: # 遍历每一列特征,跳过标签列
'''
请离散化每一列特征,即discrete_df[c] = ...
提示:
对于有些特征本身取值就很少,可以跳过即 if ... : continue
对于其他特征,可以使用等区间离散化、等密度离散化或一些其他离散化方法
可参考使用pandas.cut或qcut
'''
if len(set(discrete_df[c]))>10: # 当不同特征取值数量超过 10 时进行离散化
Discretization.pd_qcut(c,5)
barchart_ax(Discretization.DF)
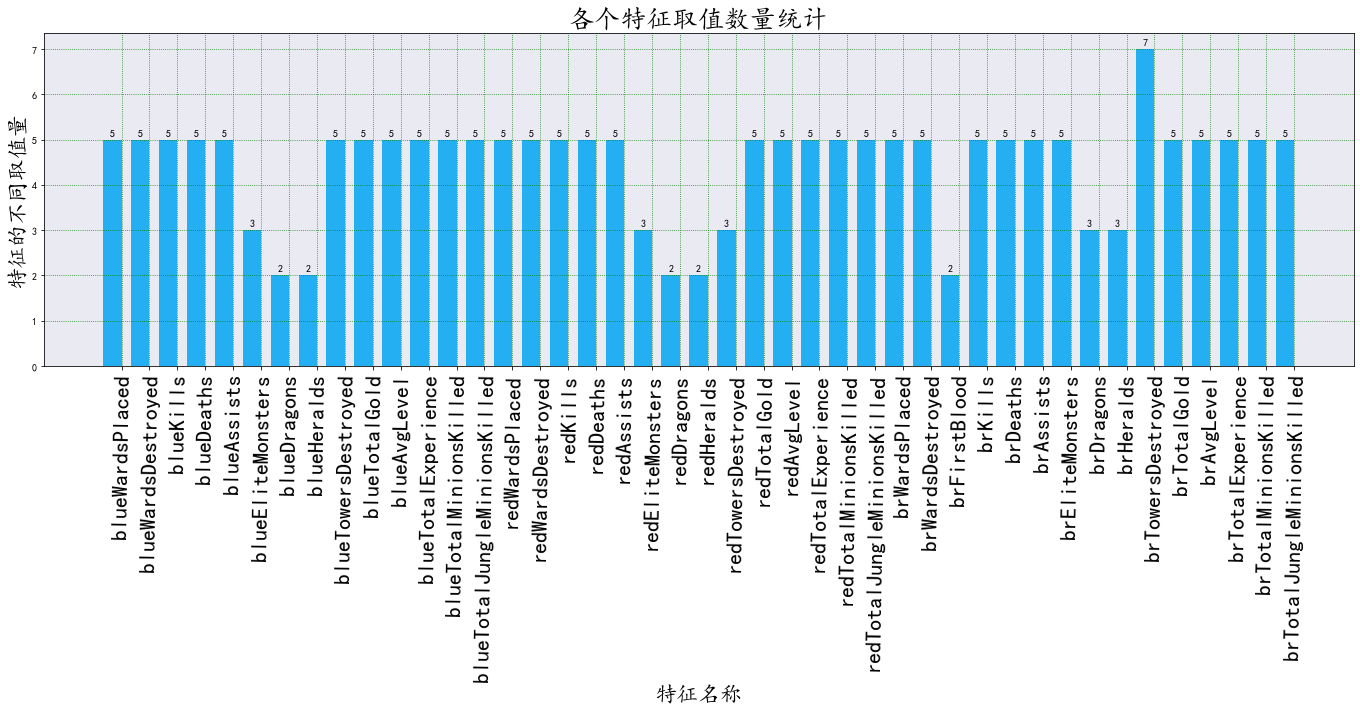
可以看到,离散化效果显著。
数据集准备
构建机器学习模型前要构建训练和测试的数据集。在本例中首先需要分开标签和特征,标签是不能作为模型的输入特征的,就好比作业和试卷答案不能在做题和考试前就告诉学生。测试一个模型在一个任务上的效果至少需要训练集和测试集,训练集用来训练模型的参数,好比学生做作业获得知识,测试集用来测试模型效果,好比期末考试考察学生学习情况。测试集的样本不应该出现在训练集中,否则会造成模型效果估计偏高,好比考试时出的题如果是作业题中出现过的,会造成考试分数不能准确衡量学生的学习情况,估计值偏高。划分训练集和测试集有多种方法,下面首先介绍的是随机取一部分如20%作测试集,剩下作训练集。sklearn提供了相关工具函数train_test_split。sklearn的输入输出一般为numpy的array矩阵,需要先将pandas的DataFrame取出为numpy的array矩阵。
from sklearn.model_selection import train_test_split, cross_validate # 划分数据集函数
discrete_df = Discretization.DF
all_y = discrete_df['blueWins'].values # 所有标签数据
features = np.array(discrete_df.columns )[1:] # 所有特征的名称
all_x = discrete_df[features].values # 所有原始特征值,pandas的DataFrame.values取出为numpy的array矩阵
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(all_x, all_y, test_size=0.2, random_state=RANDOM_SEED)
all_y.shape, all_x.shape, x_train.shape, x_test.shape, y_train.shape, y_test.shape # 输出数据行列信息
y_train[0:10]
array([1, 0, 0, 1, 0, 0, 1, 0, 0, 1], dtype=int64)
决策树模型的实现
⚪ 决策树建立主要应该有两个相互区别又互相统一的方面:一个是如何生长,另外一个是如何在适当时候停止(以免过拟合)。
- 生长:可以是一个递归过程
- 使用函数的递归调用来构建决策树可能会相对容易实现一些。
- 以降低混杂度的能力最大为(朝着数据更加有序的方向)标准,选取第一个特征(当下的最佳特征),作为开始分裂的根节点,根节点处深度为1。
- 每开辟一个节点,包括根节点,都需要在该节点处添加节点属性,如
节点名(特征名)、节点深度、节点处的样本总数、节点特征对应的不存度 - 【划分子数据集】:在生长的过程中,每次生枝前(分裂节点前)都需要划分子数据集,也就是依据(使用)当前所在节点的特征的(不同)取值,得到
子特征集和子标签集。
特别需要注意的一点是,当前节点划分的依据(特征的不同取值),也就是决策树进入下一个子节点的条件,这是预测过程中的重要进入下一个节点的依据信息,在训练时有比较记录下来。 - 【递归】:以
子特征集和子标签集作为新节点的特征集和标签集,重复以上过程。
- 停止生长:在生长递归中引入限制条件
- 自然停止:所有训练样本都被完美地完成分类自然结束分裂
▫ Case 1. 当前子数据集中地所有数据拥有完全相同地输出类别;
▫ Case 2. 当前子数据集中地所有数据拥有完全相同地输出特征。 - 强制停止:不满足允许分裂的预限制条件时不再分裂
▫ Case 1. 如继续分裂,则决策树深度超过预先限定的最大分裂深度;
▫ Case 2. 如继续分裂,则子节点地样本数将少于预先限定的最小分裂样本数。 - 停止生长处的节点:
▫ 停止生长处的节点将成为这颗训练决策树的一个叶子节点;
▫ 叶子节点处有一个其它节点没有的属性,那就是分类标签,标识决策树到达该节点处的分类结果,也就是预测时的预测值. - 叶子节点处的分类标签属性:
▫ 由于所有训练样本都被完美地完成分类而停止分类所产生的叶子节点:这时意味着分裂所剩下的样本都拥有统一标签
——只需要以该标签作为叶子节点处分类标签的值;
▫ 由于某种强制措施而停止了决策树的分类,比如"已经达到最大分类深度"、“剩余样本数小于限制分裂的最小样本数”:这时产生的叶子节点往往有不同的标签
——我们可以使用投票器的方法来选出当前子数据集的标签集中的某个标签作为这时的分类标签,如随机投票法(鲁棒性大)、以比例作做概率投票法,等等
- 自然停止:所有训练样本都被完美地完成分类自然结束分裂
⚪ 决策树预测:
- 对于一条数据,分类决策树预测就时给出这条数据的输出标签的过程
- 和在训练集上训练一样的是,预测往往也是递归过程。
- 从决策树的根节点开始,每次获取当前跟节点下的所有分支;
- 由当前根节(特征名)点查询字典onetestdata_dict获取下一步进入哪一个分支;
- 如果没有一个分支满足,即这个特征值在训练时就没这中条件下的情况,索性返回该节点处样本多的标签,结束当前递归。
- 否则,直到某个节点的孩子节点中只有一个不再含有子孩子(这意味着到了训练树的叶子处),这时返回该叶节点处的分类标签作为这条数据的预测分类标签。
⚪单独定义决策树中需要的一些额外数据计算函数
(1)计算不确定度(不纯度)
不纯度可以用信息熵entropy和基尼系数gini两种方式来数值化,表征特征的混乱程度。
-
如果为’entropy’,则计算步骤为:
1.先确定当前特征有多少取值(i=1,2,3,…),计算每种不同取值的概率pi
2.计算信息熵:
H ( X ) = − ∑ i = 1 n p i ⋅ l o g 2 p i . H(X) = -\sum_{i=1}^n{pi·log_2{pi}}. H(X)=−i=1∑npi⋅log2pi. -
如果为’gini’,则计算步骤为:
1.先确定当前特征有多少取值(i=1,2,3,…),计算每种不同取值的概率pk
2.计算基尼系数
G i n i = ∑ i = 1 n p k ( 1 − p k ) = 1 − ∑ i = 1 n ( p k ) 2 Gini = \sum_{i=1}^n{pk(1-pk)}=1-\sum_{i=1}^n{(pk) ^2} Gini=i=1∑npk(1−pk)=1−i=1∑n(pk)2
(2)计算信息增益和信息增益比
决策树每次分裂时需要衡量哪一个特征是分裂的最佳特征。总所周知,最佳的衡量标准是更好地降低混杂度。
但是同时也要意识到,取值更多地特征本身也会带来更大地混杂度,这会使得最佳特征偏向于选取拥有更多不同取值地特征,当然不是我们愿意看到的。
因此,我们采用信息增益比(gain rate)作为衡量标准。
-
【信息增益】用于度量混杂度再数据划分前后的差值,也就相当于当前数据集以某个特征的互信息。
一般而言,随着数据集的划分将带来不确定度的减小,用划分前混杂度值减去划分后混杂度值得到的信息增益将是一个恒为正的数。
关键点为:一个特征依据不同的取值分裂后,应该依据所有子数据集各自分得的样本数量取他们 加权 信息增益作为当前的信息增益。- 那么具体如何衡某特征依据取值的加权信息增益?
采取的方法是按照取值的比例计算。也就是说:
某特征信息增益 = Σ(i=1,n)|(第i个划分的标签混杂度·该划分所分得样本数量比例)
- 那么具体如何衡某特征依据取值的加权信息增益?
-
【信息增益比】主要是为了消除由于特征取值数目所带来的不确定度的增加。
信息增益衡量某个特征的不确定程度在数据划分前后的变化值。
采用信息熵作为衡量混杂度的标准时,取值越多的特征,取值数目将会该来更大的混杂度。
一般的信息增益只是计算如果以某个特征划分数据后,计算特征取值的加权混杂度,以划分前的混杂度减去划分后的加权混杂度为信息增益;
信息增益比通过信息增益/特征取值带来的不确定度抵消掉了由于特征数目不同带来的影响。
from math import log
import numpy as np
import random
from collections import Counter
RANDOM_SEED = 2021 # 固定随机种子
random.seed(random)
class Selector(object):
"""
选择器
【我的博客地址】:https://blog.csdn.net/qq_28550263/article/details/114867848
"""
def __init__(self,labels):
"""
Parameters
----------
labels: an Array-like object
"""
self.labels = labels
def majorityLabel(self):
"""
选择出现次数最多的元素
Return
------
result: labels中出现次数最多的那个成员
"""
return Counter(list(self.labels)).most_common()[0][0]
def maxProbability_elem(self):
"""
有元素权重随机选择(元素随机)
Return
------
result: labels 中的某个成员
"""
return self.labels[int(random.random()* len(self.labels))]
def maxProbability_class(self):
"""
无元素权重随机选择(元素类随机)
Return
------
result: labels 中的某个成员
"""
return list(set(self.labels))[int(random.random()* len(self.labels))]
class ClassificationTree(object):
"""分类树"""
def __init__(self, features, max_depth=10, min_samples_split=10, impurity_t='entropy',selector_t = 'majority_label',test=False):
"""
Parameters
----------
impurity_t: str,表示混杂度的度量方式,只能是{"entropy","gini"}中的一个。
"""
self.tree = None
self.impurity_t = impurity_t
self.features = features
self.max_depth = max_depth
self.min_samples_split = min_samples_split
self.selector_t = selector_t
self.test = test
def get_lable(self,labels):
"""
剪枝叶节点标签集选择标签
Parameters
----------
labels: an Array-like object,某个节点处的标签集
"""
Slor = Selector(labels)
if self.selector_t == "majority_label": # 直接选取出现最多的标签返回
return Slor.majorityLabel()
elif self.selector_t == "random": # 按权重随机选一个标签返回
return Slor.maxProbability_elem()
def impurity(self, anArray):
"""
计算混杂度
【我的博客地址】:https://blog.csdn.net/qq_28550263/article/details/114883862
Parameters
----------
anArray: an Array like object,由某特征依次对应每条数据下的取值构成。
Return
result: float,
表示计算得到的不纯度impurity的数值。
"""
cnt = Counter(anArray)
data_length = len(anArray)
pis = [cnt[i]/data_length for i in cnt]
if self.impurity_t == "entropy": # 信息熵:Entropy = -∑(i=1,n)|(pi·logpi)
return -np.sum([pi * np.log2(pi) for pi in pis if pi > 0])
elif self.impurity_t == "gini": # 基尼系数:Gini = 1-∑(k=1,n)|(Pk)^2
return 1 - np.sum([Pi**2 for Pi in pis])
else:
raise ValueError("impurity_t can only be one of {'entropy','gini'}")
def dividing_data_set(self, data_set,node_feature,node_feature_value):
"""
划分数据集
【我的博客地址】:https://blog.csdn.net/qq_28550263/article/details/114892718
整个划分方法的思想是"记录索引-重索引"。简而言之就是先记住特征取值为指定取值的索引号,然
后依据记录索引号保对其它特征下同索引号的元素进行保留。最终实现留下当前划分数据条的目的。
Parameters
----------
data_set: "dict"结构的数据集,其中键为”labels“的键值对对应为标签集(源于x_train),其余
的对应为特征取值键值对(源于y_train)。
node_feature:可以是num、str等类型,但是必须和data_set中的键的类型保持一致。表示需要划分
数据集的节点处对应的特征名。
node_feature_value:是对应与 node_feature 的一个特定取值。
Returns
-------
result : dict
返回子数据集字典,其形式与data_set保持一致。其中键`labels`对应的值类似是子标签集数组。
"""
# 先获取对应特征 node_feature 在数据集中所有条数据的有序取值数组
feature_in_sets = data_set[node_feature]
# 记录所有取值为 node_feature_value 数据编号
reserved_group = [i for i in range(len(feature_in_sets)) if feature_in_sets[i]==node_feature_value]
# 接着依据 reserved_group 中的组号保留属于当前分支的数据
sub_data_set = {}
for the_key in data_set:
sub_data_set[the_key] = np.array([data_set[the_key][i] for i in reserved_group])
# 最后,删除用过的特征列
del(sub_data_set[node_feature])
return sub_data_set
def gain(self, impurity_before_divide, data_set, probable_feature):
"""
计算信息增益
【我的博客地址】:https://blog.csdn.net/qq_28550263/article/details/114891368
需要传入数据集划分前的不纯度、划分数据集所依赖特征对应的取值数组。考虑到在同一个节点测试不同子特征增益时都有用
到划分前的不纯度,为了提升运行效率故在gain()外计算好该节点分裂前的不纯度后再传入gain()函数。其中数据集划分前的
熵就是划分前的标签集labels的熵。其中按某特征划分后的不确定度,为依该特征各个取值划分的子数据集的中的标签集(即
该特征划分完后所有的子标签集)的不确定度总和。
Parameters
----------
impurity_before_divide: float,表示数据集划分前的不纯度。
data_set: dict,划分前的数据集。
probable_feature: str,用于划分数据集的特征。
Return
------
result: float,表征信息增益值。
"""
impurity_after_divide = 0 # 初始化数据集划分后的不存度为0
for value in set(data_set[probable_feature]): # 获取该特征所有的取值并使用集合去重,遍历之
one_sublabel_array = self.dividing_data_set( # 获取该子数据集中的标签集数组
data_set = data_set,
node_feature = probable_feature,
node_feature_value = value
)['labels']
impurity_after_divide = self.impurity(one_sublabel_array) # 累加每个子数据标签集的不存度
return impurity_before_divide - impurity_after_divide # 做差得到这个特征的增益并返回
def gain_rate(self, impurity_before_divide, data_set, probable_feature):
"""
计算信息增益率
【我的博客地址】:https://blog.csdn.net/qq_28550263/article/details/114891368
相对于信息增益的计算,信息增益率还要求解出由于该特征的不同取值带来的不确度。
- 若由于特征取值带来的不确定度为0,说明无特征取值连续化影响,直接返回信息增益;
- 若特征取值带来的不确定度不是0,则使用信息增益除以特征取证带来的不确定度。
Parameters
----------
impurity_before_divide: float,表示数据集划分前的不纯度。
data_set: dict,划分前的数据集。
probable_feature: str,用于划分数据集的特征。
Return
------
result: float,表征信息增益值。
"""
impurity_after_divide = 0 # 初始化数据集划分后的不存度为0
for value in set(data_set[probable_feature]): # 获取该特征所有的取值并使用集合去重,遍历之
one_sublabel_array = self.dividing_data_set( # 获取该子数据集中的标签集数组
data_set = data_set,
node_feature = probable_feature,
node_feature_value = value
)['labels']
impurity_after_divide = self.impurity(one_sublabel_array) # 累加每个子数据标签集的不存度
gain = impurity_before_divide - impurity_after_divide # 做差得到这个特征的增益
feature_impurity = self.impurity(data_set[probable_feature])
return gain/feature_impurity if feature_impurity > 0 else gain
def best_feature(self, data_set):
"""
求取节点处的最佳特征
【我的博客地址】:https://blog.csdn.net/qq_28550263/article/details/114891368
Parameters
----------
data_set: dict,与某个节点处的对应的数据集
Return
------
result: str,数据集data_set所属节点处可用于分裂的最佳特征
"""
features = [i for i in data_set if i != "labels"] # 获取数据集中当前节点处所有特征
impurity_before_divide = self.impurity(data_set["labels"]) # 数据集划分前labels的混杂度
max_gain_rate = -1 # 不会小于0,因此随便给个负数初始值
the_best_feature = ""
for probable_feature in features:
rate = self.gain_rate(impurity_before_divide, data_set, probable_feature)
if rate > max_gain_rate:
max_gain_rate = rate
the_best_feature = probable_feature
return the_best_feature
def expand_node(self, data_set, depth, branch):
"""
递归拓展节点
【我的博客地址】:https://blog.csdn.net/qq_28550263/article/details/114967776
Parameters
----------
data_set: dict,该节点的数据集。键为特征名,值为该特征名对应的训练集数据。
labels: an Array-like object,当前标签集。根节点的标签集即原始训练集的标签集。
depth: int,上一节点的深度。根节点进来时从0开始。
branch: str or a num object,表示节点来时的路。
- 除了``根节点``外,其它的节点由于是由分裂而来,都有“来时的路”
- 根节点没有来处,只剩归途(分支)。
Return
------
result: dict, 表征当前节点(及其预期的子节点)的字典。
如果是``非叶子节点``在递归调用拓展节点后必须返回该非叶子节点给
其父节点。
这也就是说,这类字典是依次连接一个个从``根节点``到所有``非叶子
节点``的纽带。
"""
node = {} # 初始化节点
if depth == 0: # 仅根节点不属于任何分支,不需要记录来时的路
if self.test == False:
print('正在训练决策树,请稍后...')
else:
node['branch'] = branch # 对于非根节点,都需要记住来时的路
nodedepth = depth + 1 # 每递归一次节点的深度就在父节点基础上加1
the_best_feature = self.best_feature(data_set)
labels = data_set["labels"] # 当前数据集的标签集
bestfeature_values = list(set(data_set[the_best_feature])) # 最佳特征的多有取值
samples = len(data_set) # 当前节点的样本数,也就是节点数据集中标签集的元素个数
node_label = self.get_lable(labels) # 节点标签。非叶子节点也给一个标签,因为测试集的数据不一定是训练集见过的!
# 记录当前节点处的相关数据
node['depth'] = nodedepth # 记录当前节点的深度
node['the_best_feature'] = the_best_feature # 记录当前节点最佳特征
node['bestfeature_values'] = bestfeature_values # 记录当前节点的最佳特征取值,也就是节点分支名称们
node['samples'] = len(labels) # 记录当前节点处的样本数量
# 停止递归:所有特征的类别标签labels完全相同,这包含两种情况
# 一种是还有很多样本时已经被完美地分类
# 另外一种是,之前一直没有完成分类,直到现在都已经最后一个样本了
if len(set(labels)) == 1: # 如果只有一种类别了,无需分裂,已经是叶节点
node['label'] = list(labels)[0]
return node
# 停止递归:没有要求的足够样本数了
elif node['samples'] < self.min_samples_split:
node['label'] = node_label
return node
# 停止递归:到达最大分裂深度
elif node['depth'] >= self.max_depth:
node['label'] = node_label
return node
else: # 递归扩展节点
branchs = [] # 是该非叶子节点的branch容器
node['label'] = node_label # 非叶子节点的标签可以预防测试集中遇到未学习过的数据
for value in node['bestfeature_values']:
subdata_set = self.dividing_data_set( # 划分子数据集
data_set=data_set,
node_feature=node['the_best_feature'],
node_feature_value=value
)
child_node = self.expand_node(subdata_set, nodedepth, branch=value) # 递归调用
branchs.append(child_node)
node['branchs'] = branchs # 每个node的分支们装在一个列表里,列表中装一个node字典就有一个分支
return node
def fit(self, x_train, y_train):
"""
训练模型
- x_train : an Array-like object,为最初的训练数据集;
- y_train : an Array-like object,为最初的标签集。
"""
assert len(self.features) == len(x_train[0]) # 输入数据的特征数目应该和模型定义时的特征数目相同
data_set = dict(zip(self.features,x_train.T)) # 转换为数据集字典
data_set.update({"labels":y_train}) # 将标签集(labels,也就是输出y们)也加入数据集
# 拓展节点:初始深度为0,到第一个节点自动先变1,递归拓展
self.tree = self.expand_node(data_set=data_set, depth=0, branch=None)
if self.test == False:
print('训练完成,可以使用show()方法展示决策树。')
def predict_one(self,tree, one_features_data):
"""
预测测试集中的一条数据
这个过程实际上就是基于节点的递归查询过程,在某个节点:
是否有分支:
- 有分支:必为非叶子节点:
使用测试集该节点对应的特征名索引出测试特征值,决定接下来查询的分支:
如测试数据的特征值在分支列表中,进入特征值决定的分支,递归以上过程。
如测试数据的特征值不在分支列表中,说明是训练时没有遇到过的新情况:
可以用投票器投出一个标签:即可以按照该节点数据集的标签集各标签占比投票一个,
也可以直接选该节点标签集中出现次数最多的标签作为投票结果。
- 无分支:必为叶子节点:
返回叶子节点处的标签值为预测结果。
- tree:递归过程中的树(除了根节点是原决策树,其它的节点都是其子树);
- one_features_data:单条数据各个特征的取值。
"""
# 先将测试的这单条数据与原始的特征名依次组合成字典以待查询
onetestdata_dict = dict(zip(self.features,list(one_features_data)))
the_best_feature = tree.get('the_best_feature') # 当前的节点(特征名)
branchs = tree.get('branchs') # 当前特征节点下树的所有分支,是一个包含分支的列表
if branchs == None: # 没有分支时,时叶子节点
return tree.get('label') # 返回叶子节点处的标签
else: # 否则是非叶子节点
node_values = tree['bestfeature_values'] # 获取该非叶子节点所有分支值
feature_value = onetestdata_dict.get(the_best_feature) # 这条数据中当前特征对应的标签值
if feature_value not in node_values: # 这条来自测试集的特征值没有在训练时出现过(未学习到的样本)
return tree.get('label') # 不得不终止递归预测,返回本节点处的预测标签
else: # 仍然在学习到的分支中
for i in range(len(branchs)):
if branchs[i].get('branch') == feature_value:
subtree = branchs[i] # 进入该分支(获取子节点)
return self.predict_one(subtree, one_features_data) # 递归预测之
def predict(self, features):
assert len(features.shape) == 1 or len(features.shape) == 2 # 只能是1维或2维
'''
预测测试集中数据标签
使用它调用self.predict_one()对训练集中的每一条数据一次预测获取预测结果
'''
if len(features.shape) == 1:
features = np.array([features])
tree = self.tree # 准备决策树
predict_list = [] # 训练结果容器
# 对每一条数据依次调用predict_one()方法预测并以及将结果装入训练结果容器
for one_features_data in features:
one_pre_value = self.predict_one(tree, one_features_data) # 计算出一条数据的预测标签
predict_list.append(one_pre_value) # 将这一条数据的预测标签插入预测标签列表predict_list中
return np.array(predict_list) # 以np.array的形式返回预测标签数组
def show(self, stype="text"):
"""可视化决策树"""
if stype=="text": # 打印文本
print(self.tree)
elif stype=="draw": # 绘制图像
pass
clt = ClassificationTree(features=features, max_depth=4, min_samples_split=40, impurity_t='entropy',selector_t = 'majority_label')
clt.fit(x_train, y_train)
正在训练决策树,请稍后...
训练完成,可以使用show()方法展示决策树。
from sklearn.metrics import accuracy_score # 准确率函数
p_test = clt.predict(x_test)
test_acc = accuracy_score(p_test, y_test) # 将测试预测值与测试集标签对比获得准确率
print('accuracy: {:.4f}'.format(test_acc)) # 输出准确率
accuracy: 0.7060
寻找预剪枝最佳参数
parameters = {
'impurity_t':['entropy', 'gini'],
'max_depth': range(2, 6),
'min_samples_split': [100, 200, 400, 500, 800],
#"selector_t" : ["majority_label","random"],
#"RANDOM_SEED":[100,500,1000,2000,4000,8000] # 当 selector_t = random 时还可以测试随机种子对分类的影响
}
from multiprocessing import Process
max_acc = 0
max_acc_parameters = None
def one_test(features,max_depth,min_samples_split,impurity_t,selector_t,x_train,y_train,x_test,y_test):
global max_acc
global max_acc_parameters
clt = ClassificationTree(features, max_depth, min_samples_split, impurity_t, selector_t,test=True)
clt.fit(x_train, y_train)
p_test = clt.predict(x_test)
test_acc = accuracy_score(p_test, y_test)
print("max_depth:",max_depth, "min_samples_split:",min_samples_split, "impurity_t:",impurity_t, "selector_t:",selector_t,"test_acc:",test_acc)
if test_acc > max_acc:
max_acc = test_acc
print("\n>[更新latest_max_acc]:latest_max_acc=",max_acc)
max_acc_parameters = {"max_depth":max_depth, "min_samples_split":min_samples_split, "impurity_t":impurity_t, "selector_t":selector_t,"test_acc":test_acc}
print("[更新max_acc_parameters]:",max_acc_parameters)
for impurity_t in parameters["impurity_t"]:
for max_depth in parameters["max_depth"]:
for min_samples_split in parameters["min_samples_split"]:
one_test(features,max_depth,min_samples_split,impurity_t,selector_t=selector_t,x_train=x_train,y_train=y_train,x_test=x_test,y_test=y_test)
#for selector_t in parameters["selector_t"]:
#if selector_t == "random":
#for RANDOM_SEED in parameters["RANDOM_SEED"]:
#one_test(features,max_depth,min_samples_split,impurity_t,selector_t,x_train,y_train,x_test,y_test)
#else:
#one_test(features,max_depth,min_samples_split,impurity_t,selector_t,x_train,y_train,x_test,y_test)
print("\n【最终测试到】:\nMax_Acc=",max_acc,"\nMax_Acc_Parameters=",max_acc_parameters)
max_depth: 2 min_samples_split: 100 impurity_t: entropy selector_t: majority_label test_acc: 0.5167004048582996
>[更新latest_max_acc]:latest_max_acc= 0.5167004048582996
[更新max_acc_parameters]: {'max_depth': 2, 'min_samples_split': 100, 'impurity_t': 'entropy', 'selector_t': 'majority_label', 'test_acc': 0.5167004048582996}
max_depth: 2 min_samples_split: 200 impurity_t: entropy selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 2 min_samples_split: 400 impurity_t: entropy selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 2 min_samples_split: 500 impurity_t: entropy selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 2 min_samples_split: 800 impurity_t: entropy selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 3 min_samples_split: 100 impurity_t: entropy selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 3 min_samples_split: 200 impurity_t: entropy selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 3 min_samples_split: 400 impurity_t: entropy selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 3 min_samples_split: 500 impurity_t: entropy selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 3 min_samples_split: 800 impurity_t: entropy selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 4 min_samples_split: 100 impurity_t: entropy selector_t: majority_label test_acc: 0.7059716599190283
>[更新latest_max_acc]:latest_max_acc= 0.7059716599190283
[更新max_acc_parameters]: {'max_depth': 4, 'min_samples_split': 100, 'impurity_t': 'entropy', 'selector_t': 'majority_label', 'test_acc': 0.7059716599190283}
max_depth: 4 min_samples_split: 200 impurity_t: entropy selector_t: majority_label test_acc: 0.7059716599190283
max_depth: 4 min_samples_split: 400 impurity_t: entropy selector_t: majority_label test_acc: 0.7059716599190283
max_depth: 4 min_samples_split: 500 impurity_t: entropy selector_t: majority_label test_acc: 0.7059716599190283
max_depth: 4 min_samples_split: 800 impurity_t: entropy selector_t: majority_label test_acc: 0.7059716599190283
max_depth: 5 min_samples_split: 100 impurity_t: entropy selector_t: majority_label test_acc: 0.7201417004048583
>[更新latest_max_acc]:latest_max_acc= 0.7201417004048583
[更新max_acc_parameters]: {'max_depth': 5, 'min_samples_split': 100, 'impurity_t': 'entropy', 'selector_t': 'majority_label', 'test_acc': 0.7201417004048583}
max_depth: 5 min_samples_split: 200 impurity_t: entropy selector_t: majority_label test_acc: 0.7201417004048583
max_depth: 5 min_samples_split: 400 impurity_t: entropy selector_t: majority_label test_acc: 0.7201417004048583
max_depth: 5 min_samples_split: 500 impurity_t: entropy selector_t: majority_label test_acc: 0.7201417004048583
max_depth: 5 min_samples_split: 800 impurity_t: entropy selector_t: majority_label test_acc: 0.7201417004048583
max_depth: 2 min_samples_split: 100 impurity_t: gini selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 2 min_samples_split: 200 impurity_t: gini selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 2 min_samples_split: 400 impurity_t: gini selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 2 min_samples_split: 500 impurity_t: gini selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 2 min_samples_split: 800 impurity_t: gini selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 3 min_samples_split: 100 impurity_t: gini selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 3 min_samples_split: 200 impurity_t: gini selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 3 min_samples_split: 400 impurity_t: gini selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 3 min_samples_split: 500 impurity_t: gini selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 3 min_samples_split: 800 impurity_t: gini selector_t: majority_label test_acc: 0.5167004048582996
max_depth: 4 min_samples_split: 100 impurity_t: gini selector_t: majority_label test_acc: 0.7059716599190283
max_depth: 4 min_samples_split: 200 impurity_t: gini selector_t: majority_label test_acc: 0.7059716599190283
max_depth: 4 min_samples_split: 400 impurity_t: gini selector_t: majority_label test_acc: 0.7059716599190283
max_depth: 4 min_samples_split: 500 impurity_t: gini selector_t: majority_label test_acc: 0.7059716599190283
max_depth: 4 min_samples_split: 800 impurity_t: gini selector_t: majority_label test_acc: 0.7059716599190283
max_depth: 5 min_samples_split: 100 impurity_t: gini selector_t: majority_label test_acc: 0.7201417004048583
max_depth: 5 min_samples_split: 200 impurity_t: gini selector_t: majority_label test_acc: 0.7201417004048583
max_depth: 5 min_samples_split: 400 impurity_t: gini selector_t: majority_label test_acc: 0.7201417004048583
max_depth: 5 min_samples_split: 500 impurity_t: gini selector_t: majority_label test_acc: 0.7201417004048583
max_depth: 5 min_samples_split: 800 impurity_t: gini selector_t: majority_label test_acc: 0.7201417004048583
【最终测试到】:
Max_Acc= 0.7201417004048583
Max_Acc_Parameters= {'max_depth': 5, 'min_samples_split': 100, 'impurity_t': 'entropy', 'selector_t': 'majority_label', 'test_acc': 0.7201417004048583}
参数测试结论
通过测试不同的的参数,发现在参数组合:
{‘max_depth’: 5, ‘min_samples_split’: 100, ‘impurity_t’: ‘entropy’, ‘test_acc’: 0.7201417004048583}下,分类性能表现最佳。
总结
一个完整的机器学习任务包括:确定任务、数据分析、特征工程、数据集划分、模型设计、模型训练和效果测试、结果分析和调优等多个阶段,本案例以 XX联盟游戏胜负预测任务为例,给出了每个阶段的一些简单例子,帮助大家入门机器学习,希望大家有所收获!