文章目录
- 摘要
- 手写数字数据集(MNIST)
- 卷积神经网络(Convolution Neural Network, CNN)
- 模型架构搭建
- Softmax函数和CrossEntropy损失函数
- Adam 优化器
- 构造数据迭代器
- 训练、验证、测试模型
- 训练结果可视化
摘要
本文将介绍CNN的开山之作——LeNet-5卷积神经网络;并且实现导入MNIST手写数字识别数据集,对LeNet-5模型进行训练、验证和测试,最后对训练过程的损失、准确率变化进行可视化。
- 参考文献:
- LeNet-5:《Gradient-Based Learning Applied to Document Recognition》
- Adam:《Adam: A Method for Stochastic Optimization》
- 数据集(MNIST):THE MNIST DATABASE
- 完整代码(Github):MNIST_LeNet-5_PyTorch.py
手写数字数据集(MNIST)
MNIST数据集是28x28尺寸的单通道手写数字数据集,由60000张训练+10000张测试图片组成,示例图片如下:

官网下载的数据集源文件,解压后由4个ubyte文件组成,如下:
| 文件名 | 文件大小 | 说明 |
|---|---|---|
| t10k-images-idx3-ubyte | 7,657KB | 测试10000张图片矩阵数据 |
| t10k-labels-idx1-ubyte | 10KB | 测试10000张图片对应标签数据 |
| train-images-idx3-ubyte | 45,938KB | 训练60000张图片矩阵数据 |
| train-labels-idx1-ubyte | 59KB | 训练60000张图片对应标签数据 |
这种类型文件可以通过struct和numpy模块进行读取,案例如下:
import struct
import numpy as np
def load_byte(file, cache='>IIII', dtp=np.uint8):
"""
读取 ubyte 格式数据
Args:
file (str): 文件路径的字符串
cache (str): 缓存字符
dtp (type): 矩阵类型
Returns:
np.array
"""
iter_num = cache.count('I') * 4
with open(file, 'rb') as f:
magic = struct.unpack(cache, f.read(iter_num))
data = np.fromfile(f, dtype=dtp)
return data
# 读取出来的均是Numpy矩阵,可以通过dtype指定矩阵类型
train_data = load_byte("train-images-idx3-ubyte") # shape(47040000,)
test_data = load_byte("t10k-images-idx3-ubyte") # shape(60000,)
train_label = load_byte("train-labels-idx1-ubyte", ">II") # shape(7840000,)
test_label = load_byte("t10k-labels-idx1-ubyte", ">II") # shape(10000,)
根据struct解包后,转换成numpy的矩阵格式,可以根据dtype传参转换成整数或者浮点数类型的矩阵。
卷积神经网络(Convolution Neural Network, CNN)
CNN是Yann Lecun等人于1998年投稿的《Gradient-Based Learning Applied to Document Recognition》中首次提出使用神经网络架构,其网络结构名称为LeNet-5,用于识别32x32手写数字黑白图像。
网络中采用了Conv2D卷积+Subsampliing下采样的组合提取图像特征,最后采用MLP(Multi-Layer Perceptrons)多层感知机的形式,将卷积+下采样得到的特征通过三个线性层映射到输出的10类上。整体结构如下图:
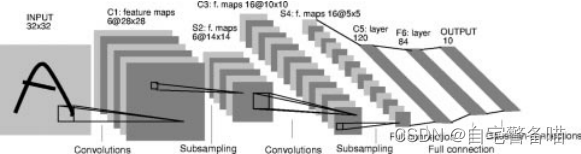
模型架构搭建
在PyTorch框架中,可以采用MaxPool2d代替Subsampling实现下采样操作,即Conv2d+MaxPool2d的组合。由于文中提出的模型结构输入图片是32x32,而MNIST数据集图片是28x28,因此需要对第一个Conv2d卷积层进行调整,输入通道为1,添加一个padding,使得后续的输出能够适应LeNet-5结构输出。搭建PyTorch代码如下:
import torch
import torch.nn as nn
import torchsummary
class Net(nn.Module):
""" CNN 卷积网络在 MNIST 28x28 手写数字灰色图像上应用版本 """
def __init__(self):
super(Net, self).__init__()
# 卷积层 #
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, # 输入通道由 3 调整为 1
kernel_size=5, stride=1, padding=2) # padding 使得模型与原文提供的 32x32 结构保持不变
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16,
kernel_size=5, stride=1)
# 池化层 #
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# 全连接层 #
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
# 激活函数 #
self.relu = nn.ReLU()
def forward(self, x):
# 卷积层 1 #
out = self.conv1(x)
out = self.relu(out)
out = self.pool1(out)
# 卷积层 2 #
out = self.conv2(out)
out = self.relu(out)
out = self.pool2(out)
# 全连接层 #
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.relu(out)
out = self.fc3(out)
return out
model = Net()
torchsummary.summary(net, input_size=(1, 28, 28), device="cpu") # 采用 keras 的方式顺序打印模型结构
可以调用torchsummary输出keras风格的模型结构表:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 6, 28, 28] 156
ReLU-2 [-1, 6, 28, 28] 0
MaxPool2d-3 [-1, 6, 14, 14] 0
Conv2d-4 [-1, 16, 10, 10] 2,416
ReLU-5 [-1, 16, 10, 10] 0
MaxPool2d-6 [-1, 16, 5, 5] 0
Linear-7 [-1, 120] 48,120
ReLU-8 [-1, 120] 0
Linear-9 [-1, 84] 10,164
ReLU-10 [-1, 84] 0
Linear-11 [-1, 10] 850
================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.11
Params size (MB): 0.24
Estimated Total Size (MB): 0.35
----------------------------------------------------------------
Softmax函数和CrossEntropy损失函数
在实现多分类任务时,一般情况下会对最后输出概率的结果进行Softmax转换,目的是为了将线性层输出的结果进行一种类似”归一、标准化“的处理,为每个输出分类的结果赋予一个概率值,公式如下:
S o f t m a x ( z i ) = e z i ∑ c = 1 C e z c \rm{Softmax} (z_i) = \frac{ e ^ {z_i} } { \sum ^ C _ {c=1} e ^ {z_c} } Softmax(zi)=∑c=1Cezcezi
其中, C C C表示输出的类别总数量; z i ∈ R C z_i \in R^{C} zi∈RC表示第 i i i个类别的输出结果。
在损失函数上,最常见的是均方误差MSE(Mean Squared Error)和交叉熵(Cross Entropy)。在本文的MNIST手写数字识别任务,是属于多分类任务;因此为了使模型更好训练、收敛,采用了多分类交叉熵损失函数,具体公式如下:
C r o s s E n t r o p y ( y , y ^ ) = − ∑ i = 1 C y i log ( y ^ i ) = − log ( y ^ c ) \rm{CrossEntropy} (y, \hat{y}) = - \sum ^ {C} _ {i=1} y_i \log(\hat{y}_i) = - \log (\hat{y}_c) CrossEntropy(y,y^)=−i=1∑Cyilog(y^i)=−log(y^c)
其中, C C C表示输出的类别总数量; y ∈ R C y \in R^{C} y∈RC和 y ^ ∈ R C \hat{y} \in R^{C} y^∈RC表示原始类别概率和预测类别概率向量; y ^ c \hat{y}_c y^c表示当前图片原始类别标签对应的预测类别概率。在多分类任务中,每一条数据最后都会输出全部类别的概率,因此原始数据会进行独热编码(One-Hot)的转换,示例如下图:
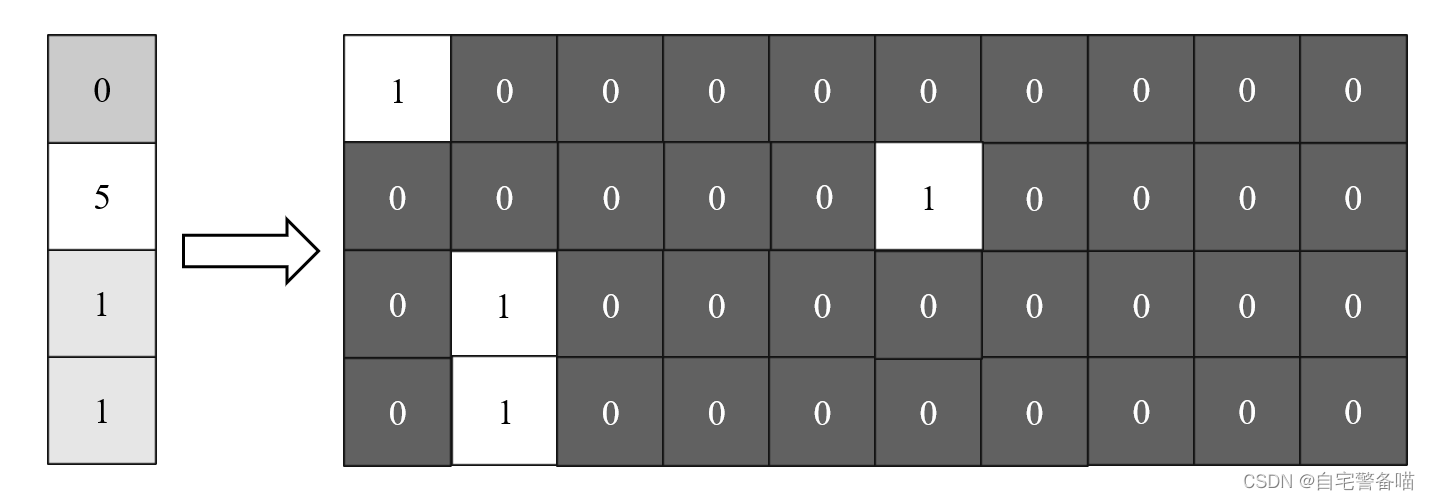
因此计算交叉熵时,比如数字1的图片,对于0,2,3,4,5,6,7,8,9这些类别位置的概率均为0,因此只需要计算数字1类别的预测概率对数负数值即可,对每一条数据同上述操作。
Adam 优化器
在神经网络模型训练过程中,都会基于随机梯度下降法(Single Gradient Descent, SGD)进行反馈传播。为了加快模型的收敛速度、减少训练时间,采用结合AdaGrad和RMSProp两种算法优点的Adam算法,详细原理后期再开专栏介绍。
构造数据迭代器
在PyTorch中,为了实现更快的训练过程,使用torch.utils.data.DataLoader构造批次数据迭代器对象;批次的原理是将数据合并生成一个新维度,从而实现批量训练。DataLoader可以传入torch.utils.data.Dataset对象,在torchvision.dataset中存在一个针对MNIST的Dataset对象,通过root和train传参来快速构造训练、测试数据迭代器,代码如下:
from torchvision import transforms
from torchvision.datasets import MNIST
import torch.utils.data as data
import numpy as np
num_channels = 1 # 图像通道数
image_size = 28 # 图像尺寸
num_workers = 0 # 读取图片进程数
valid_split = .2 # 在训练集上划出验证集的尺寸0
# 训练配置
batch_size = 512 # 批次大小
'''++++++++++++++++++++++
@@@ 数据预处理
++++++++++++++++++++++'''
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量
])
# 读取图片为数据集
train_data = MNIST(root=data_path, train=True, transform=transform)
test_data = MNIST(root=data_path, train=False, transform=transform)
# 训练 data 划分成 train 和 validation
valid_size = int(len(train_data) * valid_split)
indices = np.arange(len(train_data))
np.random.shuffle(indices)
# 构造迭代器
train_db = data.DataLoader(dataset=train_data, batch_size=batch_size, sampler=indices[:-valid_size])
val_db = data.DataLoader(dataset=train_data, batch_size=batch_size, sampler=indices[-valid_size:])
test_db = data.DataLoader(dataset=test_data, batch_size=batch_size)
print('Train: (%i, %i, %i, %i)' % (len(indices[:-valid_size]), num_channels, image_size, image_size))
print('Valid: (%i, %i, %i, %i)' % (len(indices[-valid_size:]), num_channels, image_size, image_size))
print('Test: (%i, %i, %i, %i)' % (len(test_data), num_channels, image_size, image_size))
# 查看单个案例
for (x, y) in train_db:
print(x.shape, y.shape)
break
torch.Size([512, 1, 28, 28]) torch.Size([512])
需要注意,root传入的地址必须包含MNIST文件夹,结构如下:
MNIST.
├─raw
└─t10k-images-idx3-ubyte
└─t10k-labels-idx1-ubyte
└─train-images-idx3-ubyte
└─train-labels-idx1-ubyte
如果想要通过网络下载,可以在MNIST()中加入download=True传参,届时会自动从官网下载数据集的tar.gz压缩包并且自动解压。
训练、验证、测试模型
对于模型训练、验证和测试过程,这里是仿照keras进度条,使用tqdm进度条模块编写了训练过程的变化过程。在每次epoch训练的最后一个batch训练结束后对模型进行验证。完成训练和验证过程最后再对模型进行测试,该部分代码如下:
from tqdm import tqdm
import time
epochs = 20 # 周期
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
'''+++++++++++++++++++++++
@@@ 模型训练和验证
+++++++++++++++++++++++'''
net.to(device)
criterion = nn.CrossEntropyLoss() # 设置损失函数
optimizer = torch.optim.Adam(net.parameters()) # 配置优化器
# 初始化损失和准确率
train_history = {"loss": {"train": [[] for _ in range(epochs)], "val": [[] for _ in range(epochs)]},
"acc": {"train": [[] for _ in range(epochs)], "val": [[] for _ in range(epochs)]}}
st = time.time()
for epoch in range(epochs):
with tqdm(total=len(train_db), desc=f'Epoch {epoch + 1}/{epochs}') as pbar:
for step, (x, y) in enumerate(train_db):
net.train() # 标记模型开始训练,此时权重可变
x, y = x.to(device), y.to(device) # 转移张量至 GPU
output = net(x) # 将 x 送进模型进行推导
# 计算损失
loss = criterion(output, y) # 计算交叉熵损失
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 一步随机梯度下降算法
# 计算准确率
prediction = torch.softmax(output, dim=1).argmax(dim=1) # 将预测值转换成标签
# 记录损失和准确率
train_history["loss"]["train"][epoch].append(loss.item())
train_history["acc"]["train"][epoch].append(((prediction == y).sum() / y.shape[0]).item())
# 进度条状态更新
pbar.update(1)
pbar.set_postfix({"loss": "%.4f" % np.mean(train_history["loss"]["train"][epoch]),
"acc": "%.2f%%" % (np.mean(train_history["acc"]["train"][epoch]) * 100)})
# 每一个 epoch 训练结束后进行验证
net.eval() # 标记模型开始验证,此时权重不可变
for x, y in val_db:
x, y = x.to(device), y.to(device)
output = net(x)
loss_val = criterion(output, y).item() / len(val_db)
prediction = torch.softmax(output, dim=1).argmax(dim=-1)
# 记录验证损失和准确率
train_history["loss"]["val"][epoch].append(loss_val)
train_history["acc"]["val"][epoch].append(((prediction == y).sum() / y.shape[0]).item())
# 更新进度条
pbar.set_postfix({"loss": "%.4f" % np.mean(train_history["loss"]["train"][epoch]),
"acc": "%.2f%%" % (np.mean(train_history["acc"]["train"][epoch]) * 100),
'val_loss': "%.4f" % np.mean(train_history["loss"]["val"][epoch]),
"val_acc": "%.2f%%" % (np.mean(train_history["acc"]["val"][epoch]) * 100)})
et = time.time()
time.sleep(0.1)
print('Time Taken: %d seconds' % (et - st)) # 69
'''+++++++++++++++++++
@@@ 模型测试
+++++++++++++++++++'''
print('Test data in model...')
correct, total, loss = 0, 0, 0
per_time = [] # 计算每个
net.eval()
with tqdm(total=len(test_db)) as pbar:
for step, (x, y) in enumerate(test_db):
x, y = x.to(device), y.to(device)
st = time.perf_counter()
output = net(x)
torch.cuda.synchronize()
et = time.perf_counter()
per_time.append(et - st)
loss += float(criterion(output, y)) / len(test_db)
prediction = torch.softmax(output, dim=1).argmax(dim=1)
correct += int((prediction == y).sum())
total += y.shape[0]
pbar.update(1)
pbar.set_postfix({'loss': '%.4f' % loss,
'accuracy': '%.2f%%' % (correct / total * 100),
'per_time': '%.4fs' % (et - st)})
可以发现,计算损失时不需要对输出概率进行Softmax转换,因为nn.CrossEntropyLoss会自动在内部进行Softmax转换,因此只需要在计算准确率时进行处理即可,一定程度上也能减少模型推理时间(大雾)。
训练过程中命令行窗口将输出以下进度条记录形式:
Epoch 1/20: 100%|██████████| 94/94 [00:03<00:00, 26.21it/s, loss=1.0145, acc=68.89%, val_loss=0.0165, val_acc=88.14%]
Epoch 2/20: 100%|██████████| 94/94 [00:03<00:00, 27.80it/s, loss=0.2832, acc=91.37%, val_loss=0.0095, val_acc=93.23%]
Epoch 3/20: 100%|██████████| 94/94 [00:03<00:00, 28.02it/s, loss=0.1792, acc=94.60%, val_loss=0.0064, val_acc=95.41%]
Epoch 4/20: 100%|██████████| 94/94 [00:03<00:00, 27.47it/s, loss=0.1261, acc=96.10%, val_loss=0.0051, val_acc=96.21%]
Epoch 5/20: 100%|██████████| 94/94 [00:03<00:00, 26.54it/s, loss=0.0972, acc=96.99%, val_loss=0.0042, val_acc=96.94%]
Epoch 6/20: 100%|██████████| 94/94 [00:03<00:00, 27.78it/s, loss=0.0797, acc=97.56%, val_loss=0.0037, val_acc=97.18%]
Epoch 7/20: 100%|██████████| 94/94 [00:03<00:00, 27.48it/s, loss=0.0693, acc=97.90%, val_loss=0.0034, val_acc=97.52%]
Epoch 8/20: 100%|██████████| 94/94 [00:03<00:00, 27.15it/s, loss=0.0620, acc=98.12%, val_loss=0.0030, val_acc=97.81%]
Epoch 9/20: 100%|██████████| 94/94 [00:03<00:00, 26.14it/s, loss=0.0559, acc=98.30%, val_loss=0.0028, val_acc=98.09%]
Epoch 10/20: 100%|██████████| 94/94 [00:03<00:00, 27.63it/s, loss=0.0510, acc=98.48%, val_loss=0.0026, val_acc=98.14%]
Epoch 11/20: 100%|██████████| 94/94 [00:03<00:00, 24.55it/s, loss=0.0466, acc=98.60%, val_loss=0.0025, val_acc=98.23%]
Epoch 12/20: 100%|██████████| 94/94 [00:03<00:00, 26.40it/s, loss=0.0431, acc=98.70%, val_loss=0.0025, val_acc=98.25%]
Epoch 13/20: 100%|██████████| 94/94 [00:03<00:00, 26.93it/s, loss=0.0396, acc=98.79%, val_loss=0.0024, val_acc=98.33%]
Epoch 14/20: 100%|██████████| 94/94 [00:03<00:00, 26.35it/s, loss=0.0376, acc=98.84%, val_loss=0.0024, val_acc=98.36%]
Epoch 15/20: 100%|██████████| 94/94 [00:03<00:00, 27.65it/s, loss=0.0354, acc=98.91%, val_loss=0.0024, val_acc=98.39%]
Epoch 16/20: 100%|██████████| 94/94 [00:03<00:00, 27.16it/s, loss=0.0332, acc=98.99%, val_loss=0.0024, val_acc=98.41%]
Epoch 17/20: 100%|██████████| 94/94 [00:03<00:00, 25.94it/s, loss=0.0305, acc=99.08%, val_loss=0.0025, val_acc=98.36%]
Epoch 18/20: 100%|██████████| 94/94 [00:03<00:00, 27.69it/s, loss=0.0281, acc=99.13%, val_loss=0.0025, val_acc=98.31%]
Epoch 19/20: 100%|██████████| 94/94 [00:03<00:00, 28.22it/s, loss=0.0256, acc=99.21%, val_loss=0.0025, val_acc=98.31%]
Epoch 20/20: 100%|██████████| 94/94 [00:03<00:00, 28.84it/s, loss=0.0234, acc=99.31%, val_loss=0.0024, val_acc=98.32%]
训练结果可视化
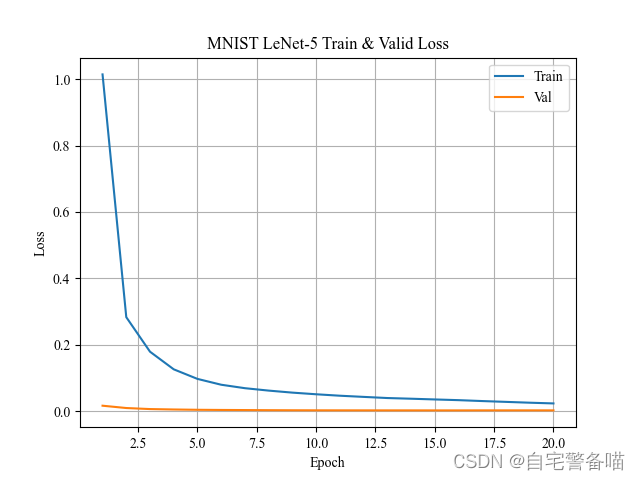
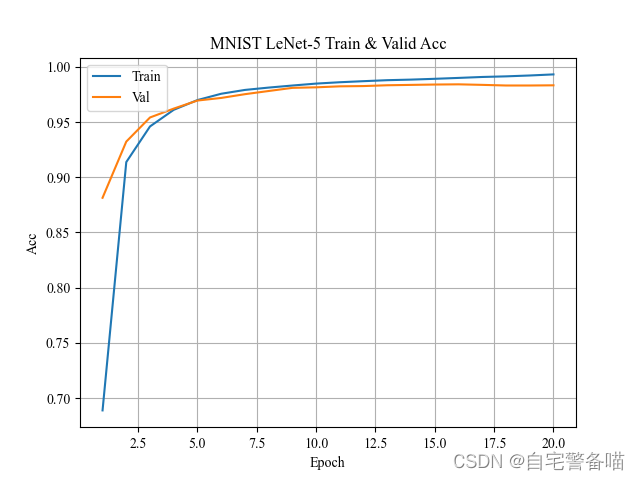
每次训练结束后,对上述训练过程记录的损失、准确率进行可视化,将更直观分析训练过程模型是否收敛。可视化模块采用matplotlib.pyplot,绘制图片如下:
import matplolib.pyplot as plt
mpl.rcParams['font.sans-serif'] = ['Times New Roman'] # 使用新罗马字体
def plot_train_history(history, num_epoch=epochs):
"""
对训练结果的可视化
Args:
history (dict): 训练结果字典(包含 loss 和 accuracy 键)
num_epoch (int): 展示周期数量(默认为 epochs)
Returns:
"""
keys = ['loss', 'acc']
for k in keys:
plt.plot(range(1, num_epoch + 1), np.mean(history[k]["train"][:num_epoch + 1], -1))
plt.plot(range(1, num_epoch + 1), np.mean(history[k]["val"][:num_epoch + 1], -1))
plt.legend(labels=['Train', 'Val'])
plt.title(f'MNIST LeNet-5 Train & Valid {k.title()}')
plt.xlabel('Epoch')
plt.ylabel(k.title())
plt.grid(True)
plt.show()
plot_train_history(train_history, epochs)