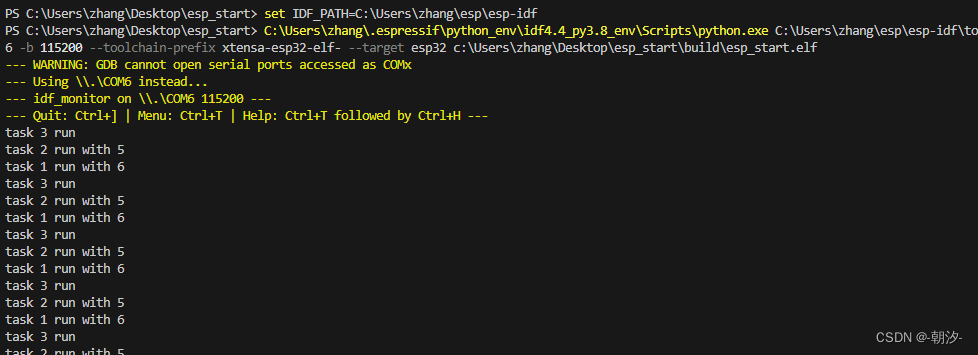
组会讨论帖
1. 图像修复
图像修复(Image Inpainting),顾名思义,就是将图像中损坏的部分修复起来,是一种图像编辑技术,可以应用在移除物体、修复老照片、图像补全(eg,地震插值)等等。



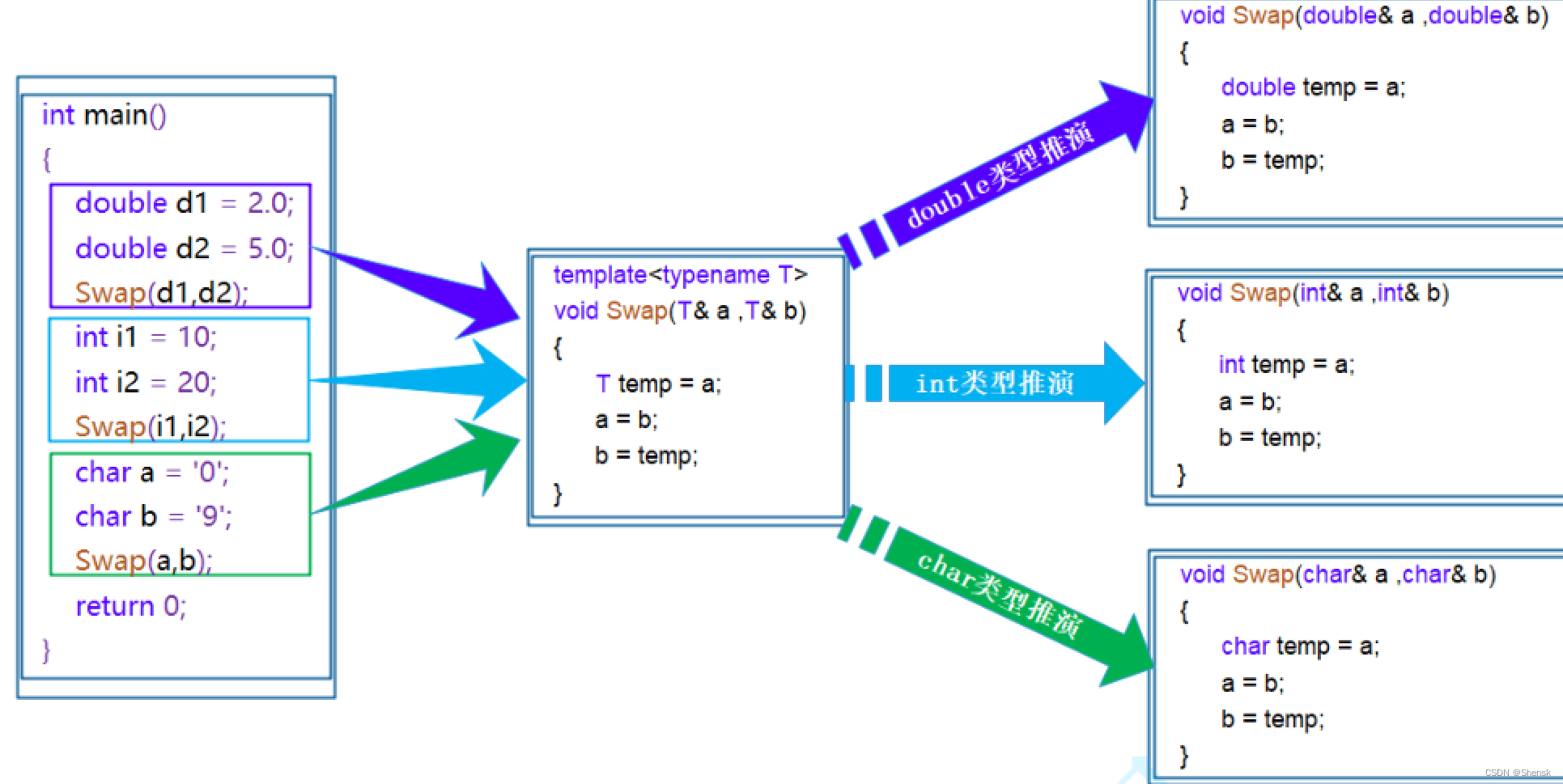
2. Partial convolution
论文链接:Image Inpainting for Irregular Holes Using Partial Convolutions (2018 ECCV)
在这之前的深度学习图像补全方法都是使用CNN来做,即把损坏的图像作为输入,完整图像作为标签来进行学习。而普通的卷积(Vanilla convolutions)作用在图像的损坏区域时,大多数计算都被浪费掉了,因为损坏区域的像素点为0或者1;同时,卷积核在做运算时不能区别损坏和未损坏的区域,对两部分的信息差并不敏感。
Pconv通过加入mask掩码参与到卷积运算中,大大提升了运算效率,且将损坏与未损坏区域的像素区分开来,提升了其敏感性。
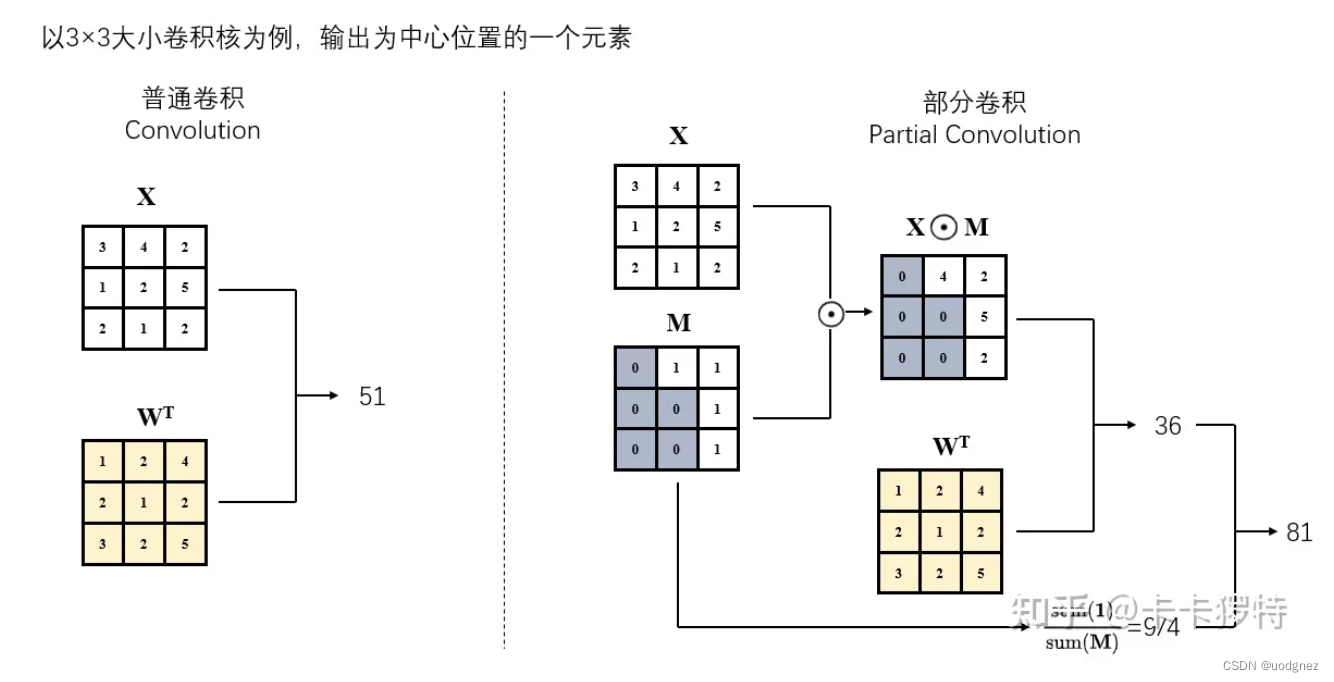
Partial convolutional layer:
x
′
=
{
W
T
(
X
⊙
M
)
sum
(
1
)
sum
(
M
)
+
b
,
if sum
(
M
)
>
0
0
,
otherwise
x' = \begin{cases} \mathbf{W}^{T}(\mathbf{X} \odot \mathbf{M}) \frac{\text{sum}(\mathbf{1})}{\text{sum}(\mathbf{M})} + b, & \text{if sum} (\mathbf{M}) >0 \\ 0, & \text{otherwise} \\ \end{cases}
x′={WT(X⊙M)sum(M)sum(1)+b,0,if sum(M)>0otherwise
其中
X
\mathbf{X}
X为当前卷积(滑动)窗口的特征值(像素值),
M
\mathbf{M}
M是相应的二进制掩码。对于第一层Pconv,1代表未损坏区域,0代表损坏区域。
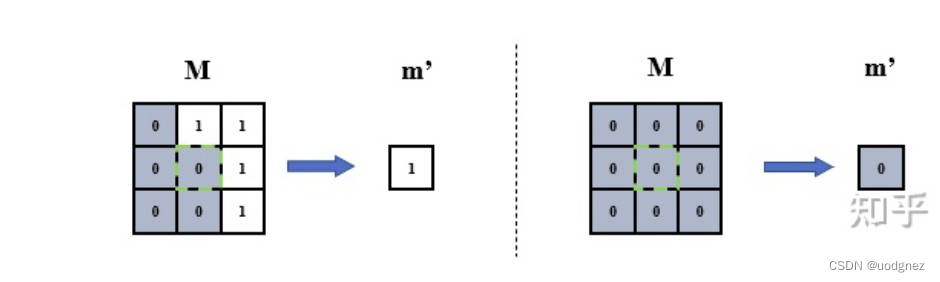
Mask 更新:
m
′
=
{
1
,
if sum
(
M
)
>
0
0
,
otherwise
m' = \begin{cases} 1, & \text{if sum} (\mathbf{M}) >0 \\ 0, & \text{otherwise} \\ \end{cases}
m′={1,0,if sum(M)>0otherwise
2.1 其在超分辨率任务上的应用

网络的输入是从低分辨率图像,通过偏移像素和插入孔来构建的。
3. Gated convolution
论文链接:Free-Form Image Inpainting with Gated Convolution (ICCV 2019)
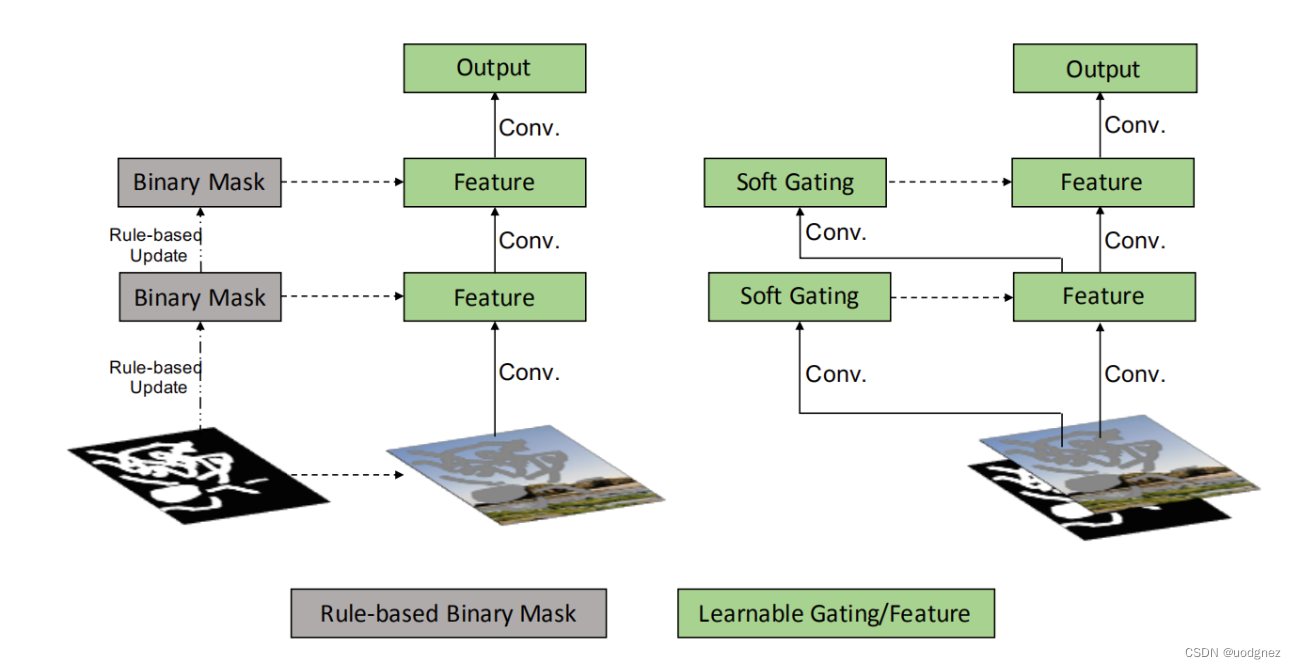
部分卷积存(partial conv)在什么不足之处?
无论像素多少,只要存在至少一个,就将mask设置为1(即1 valid pixel和9 valid pixels对于更新当前mask是无差别的);没有满足用户的意愿来进行修复;每一层的所有channel都共享同一个mask;PConv是不可学习的;它对于额外的用户输入不兼容。

部分卷积与门控卷积:
Gated convolution layer:
G
a
t
i
n
g
y
,
x
=
∑
∑
W
g
⋅
I
Gating_{y,x}= \sum \sum W_g \cdot I
Gatingy,x=∑∑Wg⋅I
F
e
a
t
u
r
e
y
,
x
∑
∑
W
f
⋅
I
Feature_{y,x}\sum \sum W_f \cdot I
Featurey,x∑∑Wf⋅I
O
y
,
x
=
ϕ
(
F
e
a
t
u
r
e
y
,
x
)
⊙
σ
(
G
a
t
i
n
g
y
,
x
)
O_{y,x}=\phi(Feature_{y,x}) \odot \sigma(Gating{_{y,x}})
Oy,x=ϕ(Featurey,x)⊙σ(Gatingy,x)
其中
W
g
W_g
Wg
W
f
W_f
Wf表示相应卷积核权重,
I
I
I为特征图,
ϕ
\phi
ϕ可以是任何激活函数(比如ReLU),而
σ
\sigma
σ表示sigmold函数。
门控卷积使得网络可以针对每个channel和每个空间位置,学习一种动态特征选择机制。有趣的是,中间门控值的可视化显示,它不仅能根据背景、遮罩、草图来选择特征,还能考虑到某些通道的语义分割。即使在深层,门控卷积也会学习在不同的通道中突出显示mask区域和草图信息,以更好地生成修复结果。
实现代码:
class GatedConv2d(nn.Module):
"""
Gated Convlution layer with activation (default activation:LeakyReLU)
Params: same as conv2d
Input: The feature from last layer "I"
Output:\phi(f(I))*\sigmoid(g(I))
"""
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True,
batch_norm=True, activation=torch.nn.LeakyReLU(0.2, inplace=True)):
super(GatedConv2d, self).__init__()
self.batch_norm = batch_norm
self.activation = activation
self.conv2d = torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
self.mask_conv2d = torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups,
bias)
self.batch_norm2d = torch.nn.BatchNorm2d(out_channels)
self.sigmoid = torch.nn.Sigmoid()
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
def gated(self, mask):
return self.sigmoid(mask)
def forward(self, input):
x = self.conv2d(input)
mask = self.mask_conv2d(input)
if self.activation is not None:
x = self.activation(x) * self.gated(mask)
else:
x = x * self.gated(mask)
if self.batch_norm:
return self.batch_norm2d(x)
else:
return x
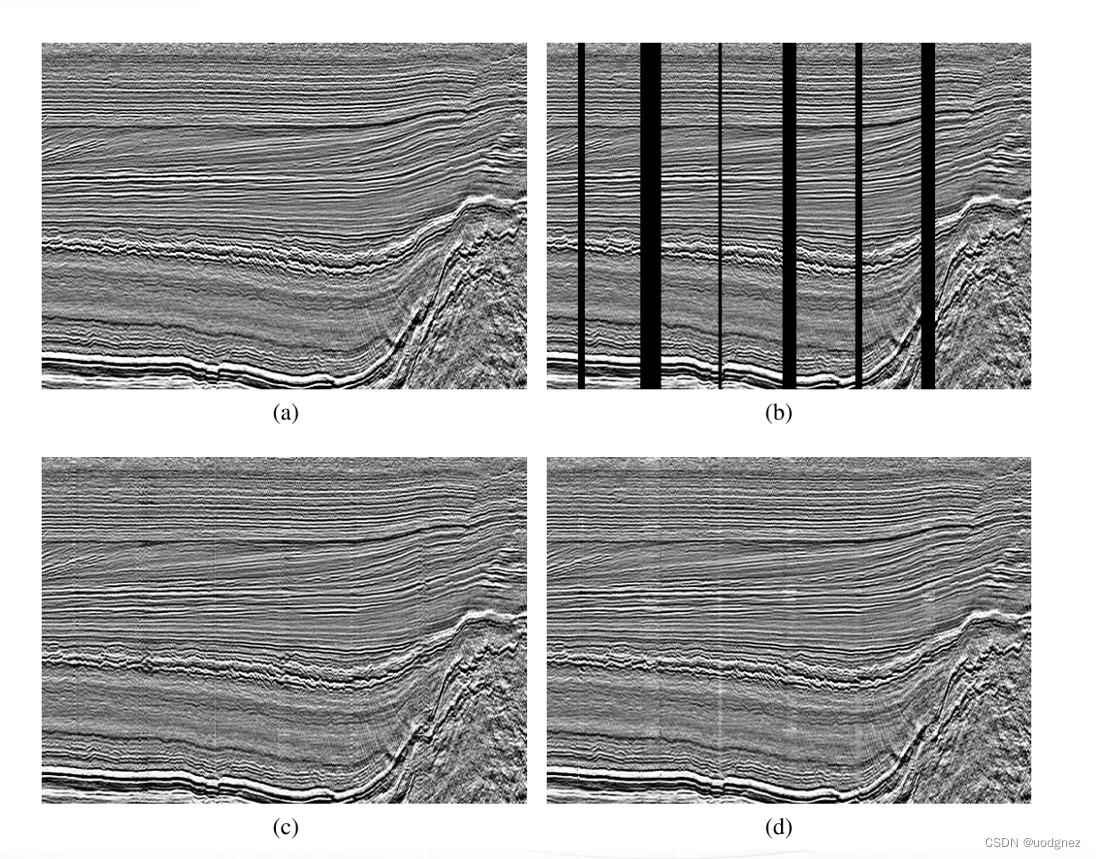
4. 总结与延申

参考文献:
https://zhuanlan.zhihu.com/p/519446359
https://www.cnblogs.com/wenshinlee/p/12591947.html
https://blog.csdn.net/weixin_43135178/article/details/123229497
https://cloud.tencent.com/developer/article/1759006
https://blog.csdn.net/yexiaogu1104/article/details/88293200?ydreferer=aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzEzNTE3OC9hcnRpY2xlL2RldGFpbHMvMTIzMjI5NDk3




![Rasa 3.x 学习系列-Rasa [3.5.8] -2023-05-12新版本发布](https://img-blog.csdnimg.cn/a9437d24cb0d48f78e2f4b0bc016212d.png)