前言
在实时计算作业中,往往需要动态改变一些配置,举几个栗子:
- 实时日志ETL服务,需要在日志的格式、字段发生变化时保证正常解析;
- 实时NLP服务,需要及时识别新添加的领域词与停用词;
- 实时风控服务,需要根据业务情况调整触发警告的规则。
那么问题来了:配置每次变化都得手动修改代码,再重启作业吗?答案显然是否定的,毕竟实时任务的终极目标就是7 x 24无间断运行。Spark Streaming和Flink的广播机制都能做到这点,本文分别来简单说明一下。
Spark Streaming的场合
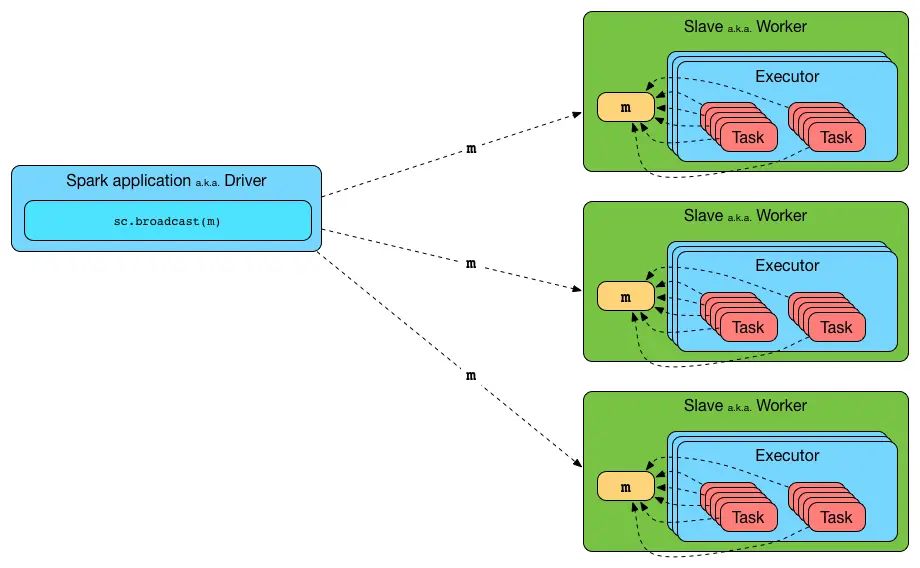
Spark Core内部的广播机制: 广播变量(broadcast variable)的设计初衷是简单地作为只读缓存,在Driver与Executor间共享数据,Spark文档中的原话如下:
Broadcast variables allow the programmer to keep a read-only variable cached on each machine rather than shipping a copy of it with tasks. They can be used, for example, to give every node a copy of a large input dataset in an efficient manner.
也就是说原生并未支持广播变量的更新,所以我们得自己稍微hack一下。直接贴代码吧。
public class BroadcastStringPeriodicUpdater {
private static final int PERIOD = 60 * 1000;
private static volatile BroadcastStringPeriodicUpdater instance;
private Broadcast < String > broadcast;
private long lastUpdate = 0 L;
private BroadcastStringPeriodicUpdater() {}
public static BroadcastStringPeriodicUpdater getInstance() {
if (instance == null) {
synchronized(BroadcastStringPeriodicUpdater.class) {
if (instance == null) {
instance = new BroadcastStringPeriodicUpdater();
}
}
}
return instance;
}
public String updateAndGet(SparkContext sc) {
long now = System.currentTimeMillis();
long offset = now - lastUpdate;
if (offset > PERIOD || broadcast == null) {
if (broadcast != null) {
broadcast.unpersist();
}
lastUpdate = now;
String value = fetchBroadcastValue();
broadcast = JavaSparkContext.fromSparkContext(sc).broadcast(value);
}
return broadcast.getValue();
}
private String fetchBroadcastValue() {}
}这段代码将字符串型广播变量的更新包装成了一个单例类,更新周期是60秒。在Streaming主程序中,就可以这样使用了:
dStream.transform(rdd - > {
String broadcastValue = BroadcastStringPeriodicUpdater.getInstance().updateAndGet(rdd.context());
rdd.mapPartitions(records - > {});
});这种方法基本上解决了问题,但不是十全十美的,因为广播数据的更新始终是周期性的,并且周期不能太短(得考虑外部存储的压力),从根本上讲还是受Spark Streaming微批次的设计理念限制的。接下来看看Flink是怎样做的。
Flink的场合
Flink中也有与Spark类似的广播变量,用法也几乎相同。但是Flink在1.5版本引入了更加灵活的广播状态(broadcast state),可以视为operator state的一种特殊情况。它能够将一个流中的数据(通常是较少量的数据)广播到下游算子的所有并发实例中,实现真正的低延迟动态更新。
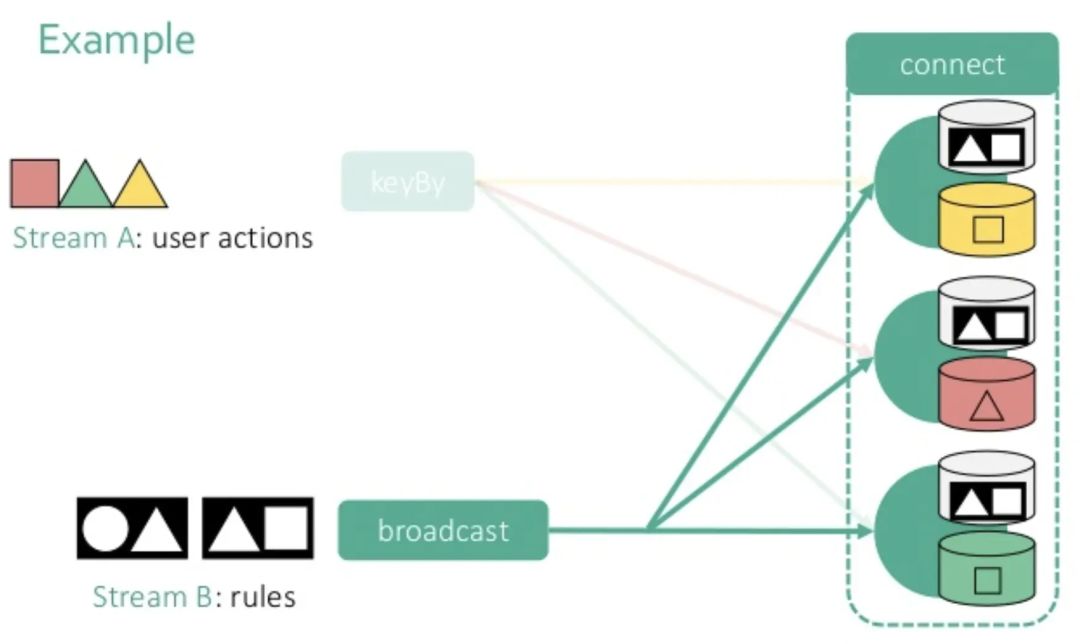
下图来自Data Artisans(被阿里收购了的Flink母公司)的PPT,其中流A是普通的数据流,流B就是含有配置信息的广播流(broadcast stream),也可以叫控制流(control stream)。流A的数据按照keyBy()算子的规则发往下游,而流B的数据会广播,最后再将这两个流的数据连接到一起进行处理。
既然它的名字叫“广播状态”,那么就一定要有与它对应的状态描述符StateDescriptor。Flink直接使用了MapStateDescriptor作为广播的状态描述符,方便存储多种不同的广播数据。示例:
MapStateDescriptor < String, String > broadcastStateDesc = new MapStateDescriptor < > ("broadcast-state-desc", String.class, String.class);接下来在控制流controlStream上调用broadcast()方法,将它转换成广播流BroadcastStream。controlStream的产生方法与正常数据流没什么不同,一般是从消息队列的某个特定topic读取。
BroadcastStream<String> broadcastStream = controlStream .setParallelism(1) .broadcast(broadcastStateDesc);
然后在DataStream上调用connect()方法,将它与广播流连接起来,生成BroadcastConnectedStream。
BroadcastConnectedStream<String, String> connectedStream = sourceStream.connect(broadcastStream);
最后就要调用process()方法对连接起来的流进行处理了。如果DataStream是一个普通的流,
需要定义BroadcastProcessFunction,反之,如果该DataStream是一个KeyedStream,
就需要定义KeyedBroadcastProcessFunction。
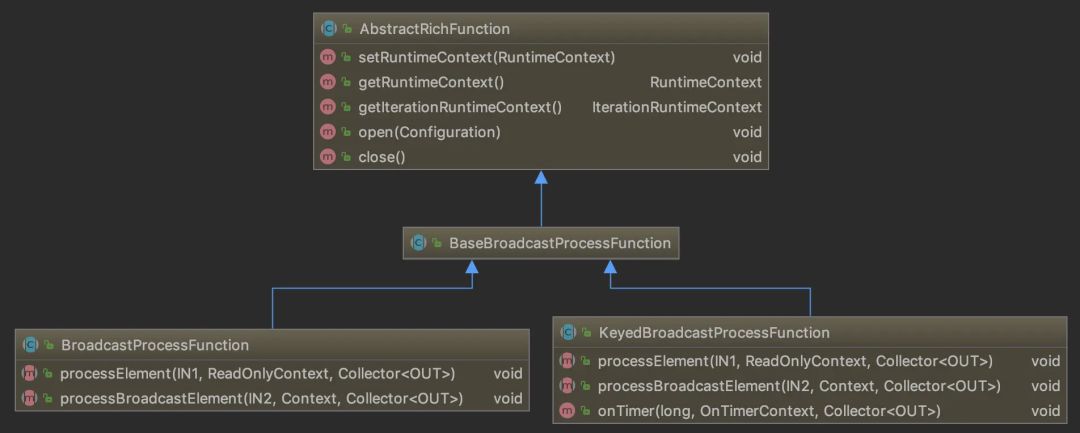
并且与之前我们常见的ProcessFunction不同的是,它们都多了一个专门处理广播数据的方法
processBroadcastElement()。类图如下所示。
下面给出一个说明性的代码示例。
connectedStream.process(new BroadcastProcessFunction < String, String, String > () {
private static final long serialVersionUID = 1 L;@
Override
public void processElement(String value, ReadOnlyContext ctx, Collector < String > out) throws Exception {
ReadOnlyBroadcastState < String, String > state = ctx.getBroadcastState(broadcastStateDesc);
for (Entry < String, String > entry: state.immutableEntries()) {
String bKey = entry.getKey();
String bValue = entry.getValue();
// 根据广播数据进行原数据流的各种处理
}
out.collect(value);
}@
Override
public void processBroadcastElement(String value, Context ctx, Collector < String > out) throws Exception {
BroadcastState < String, String > state = ctx.getBroadcastState(broadcastStateDesc);
// 如果需要的话,对广播数据进行转换,最后写入状态
state.put("some_key", value);
}
});可见,BroadcastProcessFunction的行为与RichCoFlatMapFunction、CoProcessFunction非常相像。其基本思路是processBroadcastElement()方法从广播流中获取数据,进行必要的转换之后将其以键值对形式写入BroadcastState。而processElement()方法从BroadcastState获取广播数据,再将其与原流中的数据结合处理。也就是说,BroadcastState起到了两个流之间的桥梁作用。
最后还有一点需要注意,processElement()方法获取的Context实例是ReadOnlyContext,说明只有在广播流一侧才能修改BroadcastState,而数据流一侧只能读取BroadcastState。这提供了非常重要的一致性保证:假如数据流一侧也能修改BroadcastState的话,不同的operator实例有可能产生截然不同的结果,对下游处理造成困扰。