转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn]
目录
无监督的GraphSAGE
加载 CORA 网络数据
按需采样的无监督GraphSAGE
无监督取样器(UnsupervisedSampler)
提取节点嵌入
节点嵌入的可视化
下游任务
数据拆分
分类器训练
无监督的图表示学习的用途
随着更新迭代,代码不一定能完全运行,仅供学习一下思想~
Stellargraph Unsupervised GraphSAGE是论文中所述GraphSAGE方法的实现: 大图上的归纳表征学习。W.L. Hamilton, R. Ying, and J. Leskovec arXiv:1706.02216 [cs.SI], 2017。
本笔记本是一个简短的演示,说明如何使用Stellargraph无监督GraphSAGE来学习CORA引文网络中代表论文的节点的嵌入。此外,这个笔记本展示了在下游节点分类任务中使用学习到的嵌入(按主题对论文进行分类)。请注意,节点嵌入也可用于其他图机器学习任务,如链接预测、社区检测等。
无监督的GraphSAGE
对无监督GraphSAGE图表示学习方法的高层次解释如下。
目标: 给定一个图,只使用图的结构和节点特征来学习节点的嵌入,而不使用任何已知的节点类别标签(因此是 "无监督的";关于节点嵌入的半监督学习,见此演示)。
无监督的GraphSAGE模型: 在无监督GraphSAGE模型中,节点嵌入是通过解决一个简单的分类任务来学习的:给定一大组从图上进行的随机行走中产生的 "正"(目标、背景)节点对(即在随机行走中某个背景窗口内共同出现的节点对),以及同样大的 "负 "节点对(根据某种分布从图上随机选择),学习一个二进制分类器,预测任意节点对是否可能在图上进行的随机行走中共同出现。通过学习这个简单的二进制节点对分类任务,该模型自动学习了从节点及其邻居的属性到高维向量空间中的节点嵌入的归纳映射,这保留了节点的结构和特征相似性。与Node2Vec等算法获得的嵌入不同,这种映射是归纳式的:给定一个新的节点(有属性)及其与图中其他节点的链接(在模型训练期间未见过),我们可以评估其嵌入,而不必重新训练模型。
在我们的无监督GraphSAGE的实现中,节点对的训练集是由图中同等数量的正负(目标,背景)节点对组成。阳性(目标,背景)节点对是在图上随机行走时共同出现的节点对,而负节点对是从图的全局节点度分布中随机抽取的。
节点对分类器的结构如下:输入的节点对(含节点特征)与图结构一起被送入一对相同的GraphSAGE编码器,产生一对节点嵌入。然后,这些嵌入被送入一个节点对分类层,该层对这些节点嵌入应用一个二进制运算符(例如,连接它们),并将产生的节点对嵌入通过一个线性变换和一个二进制激活(例如,sigmoid),从而为节点对预测一个二进制标签。
整个模型通过最小化所选择的损失函数(例如,预测的节点对标签和真实链接标签之间的二进制交叉熵),使用随机梯度下降法(SGD)更新模型参数来进行端到端的训练,按要求生成迷你批次的 "训练 "链接并输入模型。
从经过训练的分类器的编码器部分获得的节点嵌入可以用于各种下游任务。在这个演示中,我们展示了这些如何用于预测节点标签。
# install StellarGraph if running on Google Colab
import sys
if 'google.colab' in sys.modules:
%pip install -q stellargraph[demos]==1.2.1
# verify that we're using the correct version of StellarGraph for this notebook
import stellargraph as sg
try:
sg.utils.validate_notebook_version("1.2.1")
except AttributeError:
raise ValueError(
f"This notebook requires StellarGraph version 1.2.1, but a different version {sg.__version__} is installed. Please see <https://github.com/stellargraph/stellargraph/issues/1172>."
) from Noneimport networkx as nx
import pandas as pd
import numpy as np
import os
import random
import stellargraph as sg
from stellargraph.data import EdgeSplitter
from stellargraph.mapper import GraphSAGELinkGenerator
from stellargraph.layer import GraphSAGE, link_classification
from stellargraph.data import UniformRandomWalk
from stellargraph.data import UnsupervisedSampler
from sklearn.model_selection import train_test_split
from tensorflow import keras
from sklearn import preprocessing, feature_extraction, model_selection
from sklearn.linear_model import LogisticRegressionCV, LogisticRegression
from sklearn.metrics import accuracy_score
from stellargraph import globalvar
from stellargraph import datasets
from IPython.display import display, HTML加载 CORA 网络数据
(参见 "从Pandas加载"演示,了解如何加载数据的细节)。
Cora数据集由2708份科学出版物组成,分为七个类别之一。引文网络由5429个链接组成。数据集中的每份出版物都由一个0/1值的单词向量描述,表示字典中相应单词的缺席/存在。词典由1433个独特的词组成。
dataset = datasets.Cora()
display(HTML(dataset.description))
G, node_subjects = dataset.load()
print(G.info())
'''
StellarGraph: Undirected multigraph
Nodes: 2708, Edges: 5429
Node types:
paper: [2708]
Edge types: paper-cites->paper
Edge types:
paper-cites->paper: [5429]
'''按需采样的无监督GraphSAGE
无监督GraphSAGE需要一个训练样本,这个样本可以以(目标,上下文)节点对列表的形式提供,也可以用一个UnsupervisedSampler实例来提供,该实例负责按需生成节点对的正负样本。在这个演示中,我们讨论后一种技术。
无监督取样器(UnsupervisedSampler)
UnsupervisedSampler类接收了一个Stellargraph图的实例。UnsupervisedSampler中的生成器方法负责从图中生成同等数量的正负节点对样本用于训练。这些样本是通过使用UniformRandomWalk对象在图上进行均匀的随机行走而产生的。正面(目标,背景)节点对从散步中提取,对于每个正面的节点对(目标,节点),通过从图的度分布中随机抽取节点来生成相应的负面节点对。一旦样本的数量达到batch_size,生成器就会得到一个正负节点对的列表,以及它们各自的1/0标签。
在目前的实现中,我们使用统一的随机行走来探索图的结构。漫步的长度和数量,以及开始漫步的根节点都可以由用户指定。根节点的默认列表是图的所有节点,默认的行走次数是1(每个根节点至少有一次行走),默认的行走长度是2(需要在行走中至少有一个超出根节点的节点作为潜在的正面背景)。
1. 指定其他可选参数值:根节点、每个节点的行走次数、每个行走的长度和随机种子。
nodes = list(G.nodes())
number_of_walks = 1
length = 52. 创建UnsupervisedSampler实例,并向其传递相关参数。
unsupervised_samples = UnsupervisedSampler(
G, nodes=nodes, length=length, number_of_walks=number_of_walks
)图G和无监督采样器将被用来生成样本。
3. 创建一个节点对生成器:
接下来,创建节点对生成器,用于取样并将训练数据流向模型。节点对生成器本质上是将节点对(目标,上下文)"映射 "到GraphSAGE的输入中:它要么接受节点对的分批,要么接受一个UnsupervisedSampler实例,该实例按要求生成节点对的分批。生成器从这些节点对中提取带有(目标,上下文)头部节点的2跳子图,并将其与相应的二进制标签一起送入带有GraphSAGE节点编码器的节点对分类器的输入层,用于模型参数的SGD更新。
指定:
- 迷你批大小(每个迷你批的节点对数量)。
- 训练模型的 epochs 数目。
- GraphSAGE的1跳和2跳邻居样本的大小:
注意,num_samples列表的长度定义了GraphSAGE编码器的层数/迭代数。在这个例子中,我们定义的是一个2层的GraphSAGE编码器。
batch_size = 50
epochs = 4
num_samples = [10, 5]下面我们将展示节点对生成器与无监督采样器的工作,它将按要求生成样本。
generator = GraphSAGELinkGenerator(G, batch_size, num_samples)
train_gen = generator.flow(unsupervised_samples)建立模型:一个2层GraphSAGE编码器作为节点表示学习器,在连接的(引用-论文,被引用-论文)节点嵌入上有一个链接分类层。
该模型的GraphSAGE部分,两个GraphSAGE层的隐藏层大小为50,有一个偏置项,没有剔除。(可以通过指定一个正的辍学率来开启辍学,0<辍学<1)。注意,layer_sizes列表的长度必须等于num_samples的长度,因为len(num_samples)定义了GraphSAGE编码器的跳数(层数)。
layer_sizes = [50, 50]
graphsage = GraphSAGE(
layer_sizes=layer_sizes, generator=generator, bias=True, dropout=0.0, normalize="l2"
)
# Build the model and expose input and output sockets of graphsage, for node pair inputs:
x_inp, x_out = graphsage.in_out_tensors()最终的节点对分类层,采取由graphsage编码器产生的一对节点嵌入,对其应用二进制运算符以产生相应的节点对嵌入(ip为内积;二进制运算符的其他选项可以通过运行带有?link_classification的单元查看),并将其传递给稠密层:
prediction = link_classification(
output_dim=1, output_act="sigmoid", edge_embedding_method="ip"
)(x_out)将GraphSAGE编码器和预测层堆叠到Keras模型中,并指定损失。
model = keras.Model(inputs=x_inp, outputs=prediction)
model.compile(
optimizer=keras.optimizers.Adam(lr=1e-3),
loss=keras.losses.binary_crossentropy,
metrics=[keras.metrics.binary_accuracy],
)4. 训练模型。
history = model.fit(
train_gen,
epochs=epochs,
verbose=1,
use_multiprocessing=False,
workers=4,
shuffle=True,
)请注意,多进程是关闭的,因为在有大量节点对的训练集时,多进程会随着数据在不同进程之间的传输而大大减慢训练过程。
另外,在Keras 2.2.4及以上版本中可以使用多个工作者,由于多线程,它可以大大加快训练过程。
提取节点嵌入
现在,节点对分类器已经训练完毕,我们可以使用其节点编码器部分作为节点嵌入评估器。下面我们将节点嵌入评估为GraphSAGE层栈输出的激活,并将其可视化,根据主题标签给节点着色。
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
from stellargraph.mapper import GraphSAGENodeGenerator
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline建立一个新的基于节点的模型
(src, dst) 节点对分类器模型有两个相同的节点编码器:一个用于节点对中的源节点,另一个用于传递给模型的节点对中的目的节点。我们可以使用这两个相同的编码器中的任何一个来评估节点嵌入。下面我们通过定义一个新的Keras模型来创建一个嵌入模型,x_inp_src(x_inp中奇数元素的列表)和x_out_src(x_out中的第1个元素)分别作为输入和输出。注意,这个模型的权重与之前训练的节点对分类器中相应的节点编码器的权重相同。
x_inp_src = x_inp[0::2]
x_out_src = x_out[0]
embedding_model = keras.Model(inputs=x_inp_src, outputs=x_out_src)我们还需要一个节点生成器来给embedding_model提供图的节点。我们想为图中的所有节点评估节点嵌入:
node_ids = node_subjects.index
node_gen = GraphSAGENodeGenerator(G, batch_size, num_samples).flow(node_ids)我们现在使用node_gen将所有节点送入嵌入模型并提取它们的嵌入:
node_embeddings = embedding_model.predict(node_gen, workers=4, verbose=1)节点嵌入的可视化
接下来我们用t-SNE将节点嵌入可视化。节点的颜色描述了节点的真实类别(在Cora数据集为主题的情况下)。
node_subject = node_subjects.astype("category").cat.codes
X = node_embeddings
if X.shape[1] > 2:
transform = TSNE # PCA
trans = transform(n_components=2)
emb_transformed = pd.DataFrame(trans.fit_transform(X), index=node_ids)
emb_transformed["label"] = node_subject
else:
emb_transformed = pd.DataFrame(X, index=node_ids)
emb_transformed = emb_transformed.rename(columns={"0": 0, "1": 1})
emb_transformed["label"] = node_subject
alpha = 0.7
fig, ax = plt.subplots(figsize=(7, 7))
ax.scatter(
emb_transformed[0],
emb_transformed[1],
c=emb_transformed["label"].astype("category"),
cmap="jet",
alpha=alpha,
)
ax.set(aspect="equal", xlabel="$X_1$", ylabel="$X_2$")
plt.title(
"{} visualization of GraphSAGE embeddings for cora dataset".format(transform.__name__)
)
plt.show()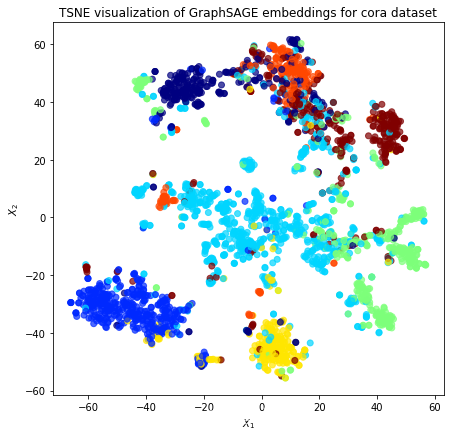
观察到嵌入空间中相同颜色的节点集中在一起,说明相同主题的论文的嵌入是相似的。我们在此再次强调,节点嵌入是以无监督的方式学习的,没有使用真实的类别标签。
下游任务
使用无监督的GraphSAGE计算的节点嵌入可以作为节点特征向量用于下游任务,如节点分类。
在这个例子中,我们将使用节点嵌入来训练一个简单的逻辑回归分类器来预测Cora数据集中的论文题目。
# X will hold the 50 input features (node embeddings)
X = node_embeddings
# y holds the corresponding target values
y = np.array(node_subject)数据拆分
我们把数据分成训练集和测试集。
我们使用5%的数据进行训练,其余95%的数据作为测试集。
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=0.05, test_size=None, stratify=y
)分类器训练
我们在训练数据上训练一个Logistic回归分类器。
clf = LogisticRegression(verbose=0, solver="lbfgs", multi_class="auto")
clf.fit(X_train, y_train)预测持有的测试集。计算分类器在测试集上的准确性。
y_pred = clf.predict(X_test)
accuracy_score(y_test, y_pred)获得的准确率相当不错,比使用node2vec获得的节点嵌入要好,node2vec忽略了节点属性,只考虑了图结构(见这个演示)。
预测的类别
pd.Series(y_pred).value_counts()真正的类
pd.Series(y).value_counts()无监督的图表示学习的用途
无监督的GraphSAGE学习无标签的图节点的嵌入。这是非常有用的,因为大多数现实世界的数据通常都是无标签的,或者有嘈杂的、不可靠的或稀疏的标签。在这种情况下,通过利用图形结构和节点的特征来学习图形中节点的低维有意义表示的无监督技术是非常有用的。
此外,GraphSAGE是一种归纳技术,使我们能够获得未见过的节点的嵌入,而不需要重新训练嵌入模型。也就是说,GraphSAGE不是为每个节点训练单独的嵌入(如node2vec等算法中学习节点嵌入的查询表),而是学习一个函数,通过从每个节点的本地邻域采样和聚合属性,并将这些属性与节点自身的属性相结合,来生成嵌入。