在HBase命令行工具中执行“list”命令,查看HBase数据库中的所有数据表。学习目标/Target
掌握热门品类Top10分析实现思路
掌握如何创建Spark连接并读取数据集
掌握利用Spark获取业务数据
掌握利用Spark统计品类的行为类型
掌握利用Spark过滤品类的行为类型
掌握利用Spark合并相同品类的行为类型
掌握利用Spark根据品类的行为类型进行排序
掌握将数据持久化到HBase数据库
熟悉通过Spark On YARN运行程序
概述
品类指商品所属分类,用户在访问电商网站时,通常会产生很多行为,例如查看商品的信息、将感兴趣的商品加入购物车和购买商品等,这些行为都将作为数据被网站存储。本章我们将通过对电商网站存储的用户行为数据进行分析,从而统计出排名前10的热门品类。
1. 数据集分析
某电商网站2019年11月产生的用户行为数据存储在文件user_session.txt,该文件中的每一行数据都表示一个用户行为。
{"user_session":"0000007c-adbf-4ed7-af17-d1fef9763d67","event_type":"view","category_id":"2053013553090134275", "user_id":"560165420","product_id":"8900305","address_name":"Maryland","event_time":"2019-11-18 09:16:19"}
user_session:用于标识用户行为的唯一值。
event_type:表示用户行为的类型,包括view(查看)、cart(加入购物车)和purchase(购买)行为。
category_id:表示商品品类ID。
user_id:表示用户ID。
product_id:表示商品ID。
address_name:表示产生事件的区域。
event_time:表示产生事件的具体时间。
2. 实现思路分析

分别统计各个品类商品的查看次数、 加入购物车次数以及购买次数。

将同一品类中商品的查看、加入购物车 以及购买次数进行合并。

自定义排序规则按照各个品类中商品的查看、 加入购物车和购买次数进行降序排序,获取 排名前10的品类,就是热门品类Top10。排 序时,优先按照各个品类商品的查看次数降 序排列,如果查看次数相同,则按照各个品 类商品的加入购物车次数进行降序排列。如 果查看次数和加入购车次数都相同,那么按 照各品类商品的购买次数进行降序排列。

将同一品类中商品的查看、加入购物车和 购买次数映射到自定义排序规则中进行排 序处理。


读取数据集中的行为类型(event_type)和品类ID(category_id)数据,为了便于后续聚合处理时,将相同Key的Value值进行累加,计算每个品类中不同行为出现的总次数,这里需要对输出结果的数据格式进行转换处理,将行为类型和品类ID作为Key,值1作为Value。
统计各个品类的查看、加入购物车和购买次数。
将聚合结果进行过滤处理,并分为三部分数据,分别是各个品类查看次数、各个品类加入购物车次数和各个品类购买次数。对过滤后的三部分数据进行转换处理,去除数据中的行为类型字段。此步目的是为了后续合并操作时,明确同一品类中不同行为类型所处位置。
将Key值相同的Value进行合并处理,目的是为了将相同品类的查看次数、加入购物车次数和购买次数合并到一行。
对每个品类中查看次数(viewcount)、加入购物车次数(cartcount)和购买次数(purchasecount)进行排序处理,在排序过程会涉及三类值的排序,因此这里需要使用Spark的二次排序,在排序操作时使用自定义排序的方式进行处理。
3. 实现热门品类Top10
3.1 创建项目
 本项目在Windows环境下通过IntelliJ IDEA工具构建Maven项目实现,需要提前在Windows环境下安装JDK1.8环境。
本项目在Windows环境下通过IntelliJ IDEA工具构建Maven项目实现,需要提前在Windows环境下安装JDK1.8环境。
创建Maven项目
打开IntelliJ IDEA开发工具进入IntelliJ IDEA欢迎界面。

在IntelliJ IDEA欢迎界面单击下拉框“Configure”,依次选择“Project Defaults”→“Project Structure”选项,配置项目使用的JDK。
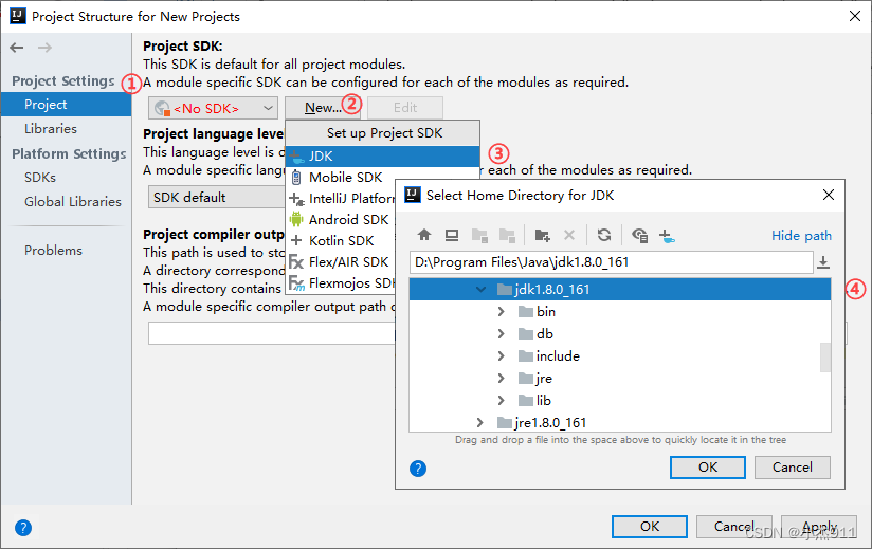
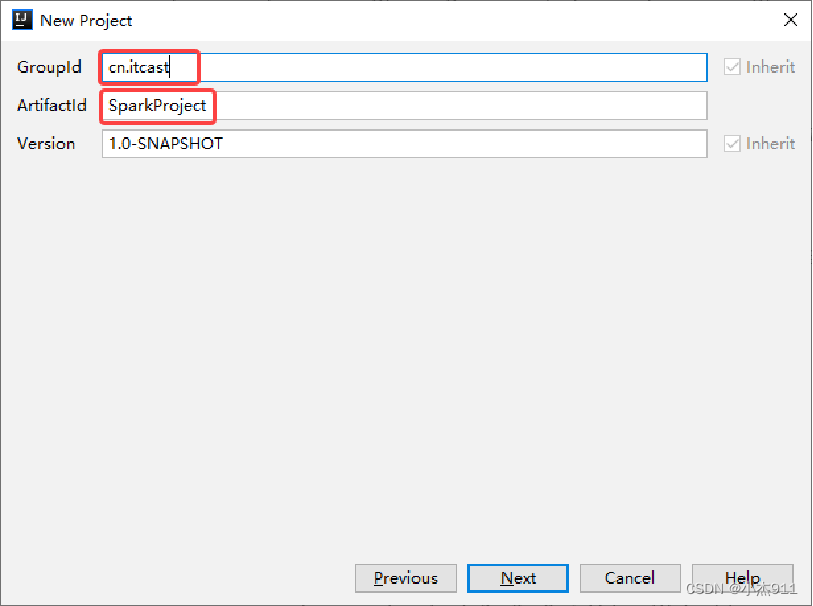
配置Maven项目的组织名(GroupId)和项目工程名(ArtifactId)。
配置项目名称(Project name)和项目本地的存放目录(Project location)。

Maven项目创建完成后的目录结构。

导入依赖
在项目pom.xml文件中添加如下配置内容: 对项目中Netty依赖进行多版本管理,避免本地运行出现多个版本的Netty导致程序出现NoSuchMethodError异常。 引入JSON依赖,用于解析JSON数据。 引入HBase依赖,用于操作HBase数据库。 引入Spark依赖,用于开发Spark数据分析程序。 指定Maven编译的JDK版本。 配置程序打包方式并指定程序主类。
创建项目目录
在项目SparkProject中新建Package包。

在“New Package”窗口的文本输入框“Enter new package name”中输入“cn.itcast.top10”设置Package名称,用于存放实现热门品类Top10分析的类文件。

在Package包“cn.itcast.top10”新建类。
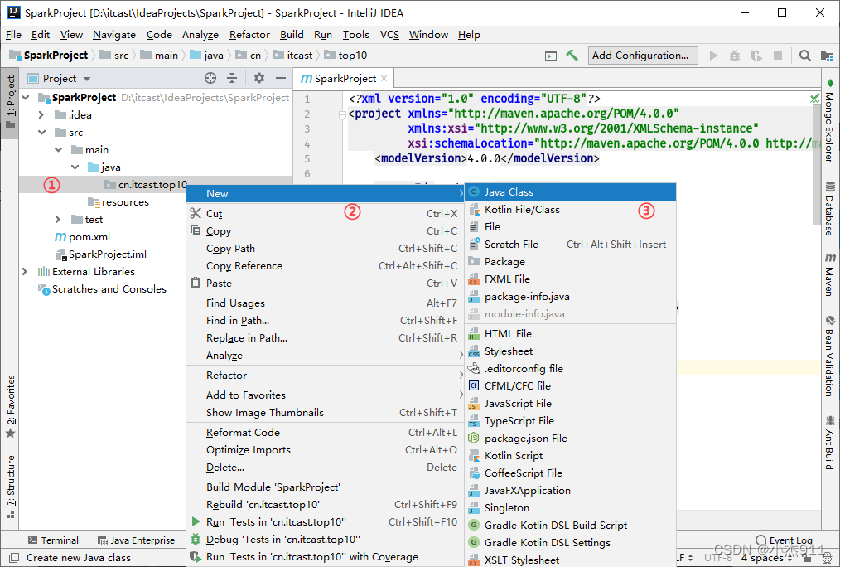
在“Create New Class”窗口的文本输入框“Name”中输入“CategoryTop10”设置类名称,在类中实现热门品类Top10分析。

3.2创建Spark连接并读取数据集
在类CategoryTop10中定义main()方法,该方法是Java程序执行的入口,在main()方法中实现Spark Core程序。
public class CategoryTop10 { public static void main(String[] arg){ //实现热门品类Top10分析 } }
在main()方法中,创建JavaSparkContext和SparkConf对象,JavaSparkContext对象用于实现Spark程序,SparkConf对象用于配置Spark程序相关参数。
SparkConf conf = new SparkConf(); //设置Application名称为top3_area_product conf.setAppName("top10_category"); JavaSparkContext sc = new JavaSparkContext(conf);
在main()方法中,调用JavaSparkContext对象的textFile()方法读取外部文件,将文件中的数据加载到textFileRDD。
JavaRDD<String> textFileRDD = sc.textFile(arg[0]);
3.3 获取业务数据
在main()方法中,使用mapToPair()算子转换textFileRDD的每一行数据,用于获取每一行数据中的行为类型和品类ID数据,将转换结果加载到transProductRDD。
JavaPairRDD<Tuple2<String,String>,Integer> transformRDD = textFileRDD.mapToPair(new PairFunction<String,Tuple2<String, String>, Integer>() { @Override public Tuple2<Tuple2<String, String>, Integer> call(String s) throws Exception { JSONObject json = JSONObject.parseObject(s); String category_id = json.getString("category_id"); String event_type = json.getString("event_type"); return new Tuple2<>(new Tuple2<>(category_id,event_type), new Integer(1)); } });
3.4 统计品类的行为类型
在main()方法中,使用reduceByKey()算子对transformRDD进行聚合操作,用于统计每个品类中商品被查看、加入购物车和购买的次数,将统计结果加载到aggregationRDD。
JavaPairRDD<Tuple2<String, String>, Integer> aggregationRDD = transformRDD.reduceByKey( new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer integer1, Integer integer2) throws Exception { return integer1 + integer2; } });
3.5 过滤品类的行为类型
在main()方法中,首先使用filter()算子过滤aggregationRDD每一行数据中行为类型为加入购物车和购买的数据,只保留行为类型为查看的数据,然后使用mapToPair()算子对过滤结果进行转换,获取每一行数据中品类被查看次数和品类ID数据,最终将转换结果加载到getViewCategoryRDD。
JavaPairRDD<String,Integer> getViewCategoryRDD =aggregationRDD .filter(new Function<Tuple2<Tuple2<String, String>, Integer>, Boolean>() { @Override public Boolean call(Tuple2<Tuple2<String, String>, Integer> tuple2) throws Exception { String action = tuple2._1._2; return action.equals("view"); } }).mapToPair(new PairFunction<Tuple2<Tuple2<String, String>, Integer>, String, Integer>() { @Override public Tuple2<String, Integer> call(Tuple2<Tuple2<String, String>, Integer> tuple2)throws Exception { return new Tuple2<>(tuple2._1._1,tuple2._2); } });
在main()方法中,首先使用filter()算子过滤aggregationRDD每一行数据中行为类型为查看和购买的数据,只保留行为类型为加入购物车的数据,然后使用mapToPair()算子对过滤结果进行转换,获取每一行数据中品类被加入购物车次数和品类ID数据,最终将转换结果加载到getCartCategoryRDD。
JavaPairRDD<String,Integer> getCartCategoryRDD = aggregationRDD .filter(new Function<Tuple2<Tuple2<String, String>, Integer>, Boolean>() { @Override public Boolean call(Tuple2<Tuple2<String, String>, Integer> tuple2) throws Exception { String action = tuple2._1._2; return action.equals("cart"); } }).mapToPair(new PairFunction<Tuple2<Tuple2<String, String>, Integer>, String, Integer>() { @Override public Tuple2<String, Integer> call(Tuple2<Tuple2<String, String>, Integer> tuple2) throws Exception { return new Tuple2<>(tuple2._1._1,tuple2._2); } });
在main()方法中,首先使用filter()算子过滤aggregationRDD每一行数据中行为类型为查看和加入购物车的数据,只保留行为类型为购买的数据,然后使用mapToPair()算子对过滤结果进行转换,获取每一行数据中品类被购买次数和品类ID数据,最终将转换结果加载到getPurchaseCategoryRDD。
JavaPairRDD<String,Integer> getPurchaseCategoryRDD = aggregationRDD .filter(new Function<Tuple2<Tuple2<String, String>, Integer>, Boolean>() { @Override public Boolean call(Tuple2<Tuple2<String, String>, Integer> tuple2) throws Exception { String action = tuple2._1._2; return action.equals("purchase"); } }).mapToPair(new PairFunction<Tuple2<Tuple2<String, String>, Integer>, String, Integer>() { @Override public Tuple2<String, Integer> call(Tuple2<Tuple2<String, String>, Integer> tuple2) throws Exception { return new Tuple2<>(tuple2._1._1,tuple2._2); } });
3.6 合并相同品类的行为类型
在main()方法中,使用leftOuterJoin(左外连接)算子合并getViewCategoryRDD、getCartCategoryRDD和getPurchaseCategoryRDD,用于合并同一品类的查看次数、加入购物车次数和购买次数,将合并结果加载到joinCategoryRDD。
JavaPairRDD<String,Tuple2<Integer, Optional<Integer>>> tmpJoinCategoryRDD =getViewCategoryRDD.leftOuterJoin(getCartCategoryRDD); JavaPairRDD<String,Tuple2<Tuple2<Integer, Optional<Integer>>,Optional<Integer>>> joinCategoryRDD = tmpJoinCategoryRDD.leftOuterJoin(getPurchaseCategoryRDD);
Optional类是一个包含有可选值的包装类,它既可以含有对象也可以为空,主要为了解决空指针异常的问题,因为某些品类中的商品可能被查看但并未被购买或加入购物车。
3.7 根据品类的行为类型进行排序
在包“cn.itcast.top10”中创建文件CategorySortKey.java,用于实现自定义排序。在类CategorySortKey中继承比较器接口Comparable和序列化接口Serializable,并实现Comparable接口的compareTo()方法。
import java.io.Serializable; public class CategorySortKey implements Comparable<CategorySortKey>,Serializable{ ...... @Override public int compareTo(CategorySortKey other) { if(viewCount - other.getViewCount() != 0) { return (int) (viewCount - other.getViewCount()); } else if(cartCount - other.getCartCount() != 0) { return (int) (cartCount - other.getCartCount()); } else if(purchaseCount - other.getPurchaseCount() != 0) { return (int) (purchaseCount - other.getPurchaseCount()); } return 0; } }
在main()方法中,使用mapTopair()算子转换joinCategoryRDD,将joinCategoryRDD中品类被查看次数、加入购物车次数和购买次数映射到自定义排序类CategorySortKey,通过transCategoryRDD加载转换结果。
JavaPairRDD<CategorySortKey,String> transCategoryRDD = joinCategoryRDD .mapToPair(new PairFunction<Tuple2<String, Tuple2<Tuple2<Integer, Optional<Integer>>,Optional<Integer>>>,CategorySortKey,String>() { @Override public Tuple2<CategorySortKey,String> call(Tuple2<String, Tuple2<Tuple2<Integer, Optional<Integer>>, Optional<Integer>>> tuple2) throws Exception { String category_id = tuple2._1; int viewcount = tuple2._2._1._1; int cartcount = 0; int purchasecount = 0; if (tuple2._2._1._2.isPresent()){ cartcount = tuple2._2._1._2.get().intValue();} if (tuple2._2._2.isPresent()){ purchasecount = tuple2._2._2.get().intValue(); } CategorySortKey sortKey = new CategorySortKey(viewcount, cartcount, purchasecount); return new Tuple2<>(sortKey,category_id); } });
在main()方法中,通过sortByKey()算子对transCategoryRDD进行排序操作,使transCategoryRDD中品类被查看次数、加入购物车次数和购买次数根据自定义排序类CategorySortKey指定的排序规则进行排序,将排序结果加载到sortedCategoryRDD。
JavaPairRDD<CategorySortKey,String> sortedCategoryRDD = transCategoryRDD.sortByKey(false);
在main()方法中,使用take()算子获取sortedCategoryRDD前10个元素,即热门品类Top10分析结果,将分析结果加载到top10CategoryList。
List<Tuple2<CategorySortKey, String>> top10CategoryList = sortedCategoryRDD.take(10);
3.3.8 数据持久化
封装工具类:
(1)在项目SparkProject的 java目录新建Package包“cn.itcast.hbase”,用于存放实现数据持久化的Java文件。在包“cn.itcast.hbase”下创建文件HbaseConnect.java,用于实现封装HBase数据库连接工具类,在类中实现连接HBase数据库的操作。
(2)在项目SparkProject的包“cn.itcast.hbase”中创建文件HbaseUtils.java,用于实现封装HBase数据库操作工具类,在类中实现创建HBase数据表和向HBase数据表中插入数据的操作。
持久化热门品类Top10分析结果
在类CategoryTop10中添加方法top10ToHbase(),用于将热门品类Top10分析结果持久化到HBase数据库中,该方法包含参数top10CategoryList,表示热门品类Top10分析结果数据。
public static void top10ToHbase(List<Tuple2<CategorySortKey, String>> top10CategoryList) throws Exception{ HbaseUtils.createTable("top10","top10_category"); String[] column = {"category_id","viewcount","cartcount","purchasecount"}; String viewcount = "" , cartcount = "", purchasecount = "", category_id = ""; int count = 0; for (Tuple2<CategorySortKey, String> top10: top10CategoryList) { count++; viewcount = String.valueOf(top10._1.getViewCount()); cartcount = String.valueOf(top10._1.getCartCount()); purchasecount = String.valueOf(top10._1.getPurchaseCount()); category_id = top10._2; String[] value = {category_id,viewcount,cartcount,purchasecount}; HbaseUtils.putsToHBase("top10","rowkey_top"+count,"top10_category",column,value); } }
在类CategoryTop10的main()方法中,调用方法top10ToHbase()并传入参数top10CategoryList,用于在Spark程序中实现top10ToHbase()方法,将热门品类Top10分析结果持久化到HBase数据库中的数据表top10。
try { top10ToHbase(top10CategoryList); } catch (Exception e) { e.printStackTrace(); } HbaseConnect.closeConnection(); sc.close();
4. 运行程序
 在IntelliJ IDEA中将热门品类Top10分析程序封装成jar包,并上传到集群环境中,通过spark-submit将程序提交到YARN中运行。
在IntelliJ IDEA中将热门品类Top10分析程序封装成jar包,并上传到集群环境中,通过spark-submit将程序提交到YARN中运行。
封装jar包:
在IntelliJ IDEA主界面单击右侧“Maven”选项卡打开Maven窗口。
![]()
在Maven窗口单击展开Lifecycle折叠框,双击Lifecycle折叠框中的“package”选项,IntelliJ IDEA会自动将程序封装成jar包,封装完成后,若出现“BUILD SUCCESS”内容,则证明成功封装热门品类Top10分析程序为jar包。


在项目SparkProject中的target目录下会生成SparkProject-1.0-SNAPSHOT.jar文件,为了便于后续与其它程序区分,这里将默认文件名称修改为CategoryTop10.jar。
将jar包上传到集群:
使用远程连接工具SecureCRT连接虚拟机Spark01,在存放jar文件的目录/export/SparkJar/(该目录需提前创建)下执行“rz”命令,上传热门品类Top10分析程序的jar包CategoryTop10.jar。
将数据集上传到本地文件系统:
使用远程连接工具SecureCRT连接虚拟机Spark01,在存放数据文件的目录/export/data/SparkData/(该目录需提前创建)下执行“rz”命令,将数据集user_session.txt上传至本地文件系统。
在HDFS创建存放数据集的目录:
将数据集上传到HDFS前,需要在HDFS的根目录创建目录spark_data,用于存放数据集user_session.txt。
hdfs dfs -mkdir /spark_data
上传数据集到HDFS:
将本地文件系统目录/export/data/SparkData/下的数据集user_session.txt上传到HDFS的spark_data目录下。
hdfs dfs -put /export/data/SparkData/user_session.txt /spark_data
提交热门品类Top10分析程序到YARN集群:
通过Spark安装目录中bin目录下的shell脚本文件spark-submit提交热门品类Top10分析程序 到Hadoop集群的YARN运行。
spark-submit \
--master yarn \
--deploy-mode cluster \
--num-executors 3 \
--executor-memory 2G \
--class cn.itcast.top10.CategoryTop10 \
/export/SparkJar/CategoryTop10.jar /spark_data/user_session.txt
查看程序运行状态:
程序运行时在控制台会生成“Application ID”(程序运行时的唯一ID),在浏览器输入“192.168.121.132:8088”,进入YARN的Web UI界面,通过对应“Application ID”查看程序的运行状态,当程序运行完成后State为FINISHED,并且FinalStatus为SUCCEES。

查看程序运行结果:
在虚拟机Spark01执行“hbase shell”命令,进入HBase命令行工具。

在HBase命令行工具中执行“list”命令,查看HBase数据库中的所有数据表。
> list TAB
test
top10
2 row(s) in 0.1810 seconds
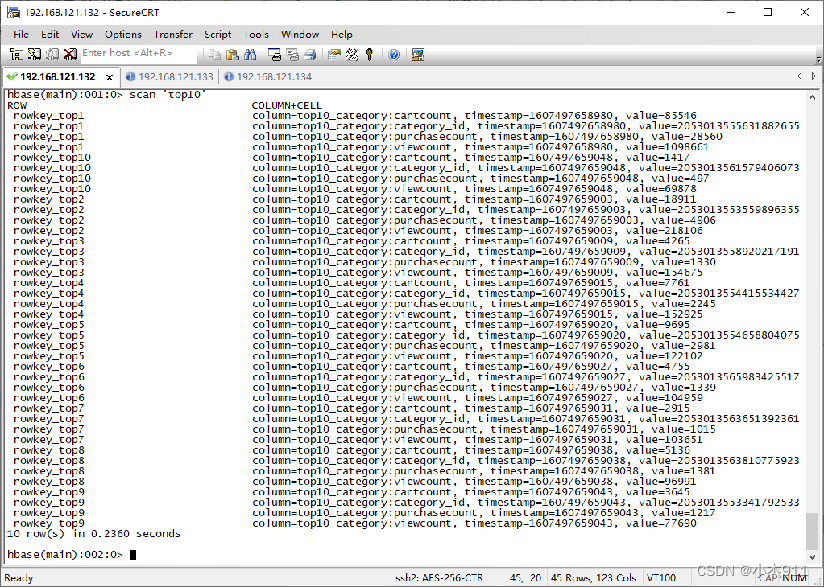
在HBase命令行工具执行“scan 'top10'”命令,查询数据表top10中的数据。
本文主要讲解了如何通过用户行为数据实现热门品类Top10分析,首先我们对数据集进行分析,使读者了解用户行为数据的数据结构。接着通过实现思路分析,使读者了解热门品类Top10分析的实现流程。然后通过IntelliJ IDEA开发工具实现热门品类Top10分析程序并将分析结果存储到HBase数据库,使读者掌握运用Java语言编写Spark Core和HBase程序的能力。最后封装热门品类Top10分析程序并提交到集群运行,使读者掌握运用IntelliJ IDEA开发工具封装Spark Core程序以及Spark ON YARN模式运行Spark Core程序的方法。






![[AI图片生成]自己搭建StableDiffusion安装过程](https://img-blog.csdnimg.cn/dff563e8d8dd407aa3d5e60f097467ee.png)