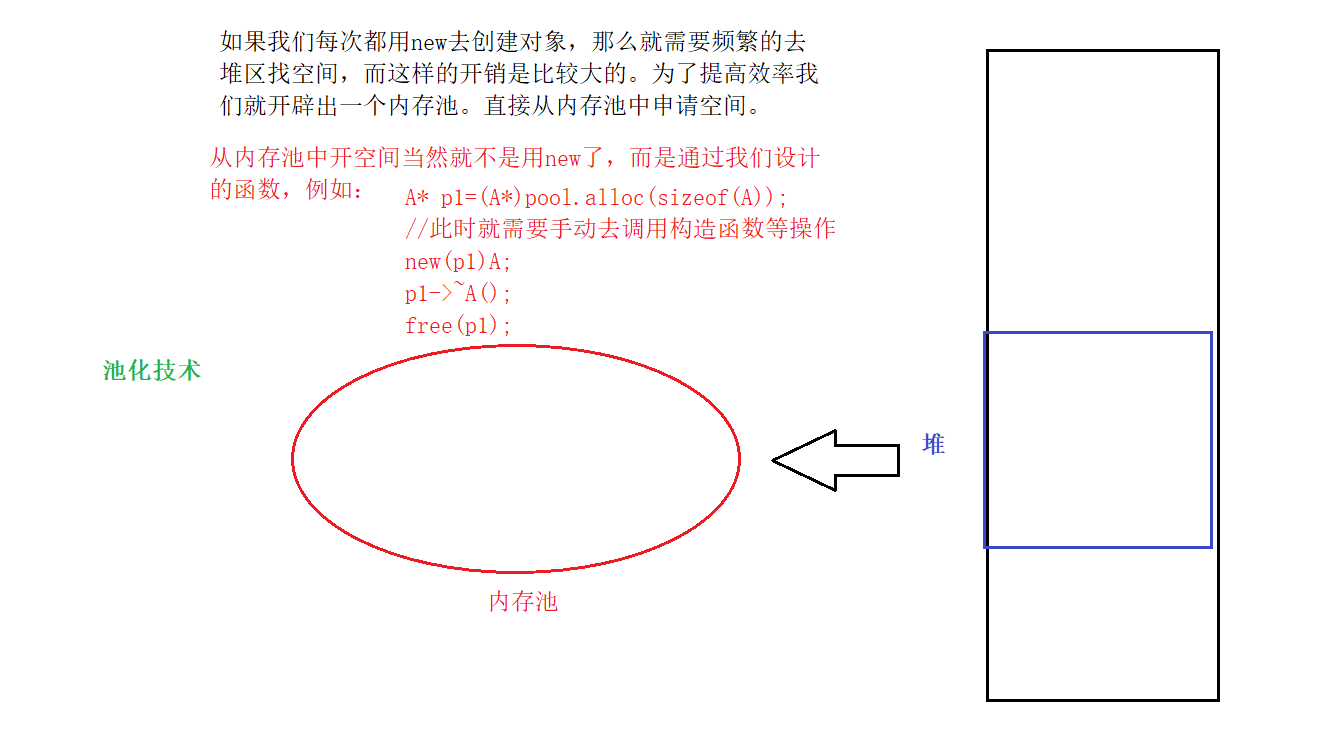
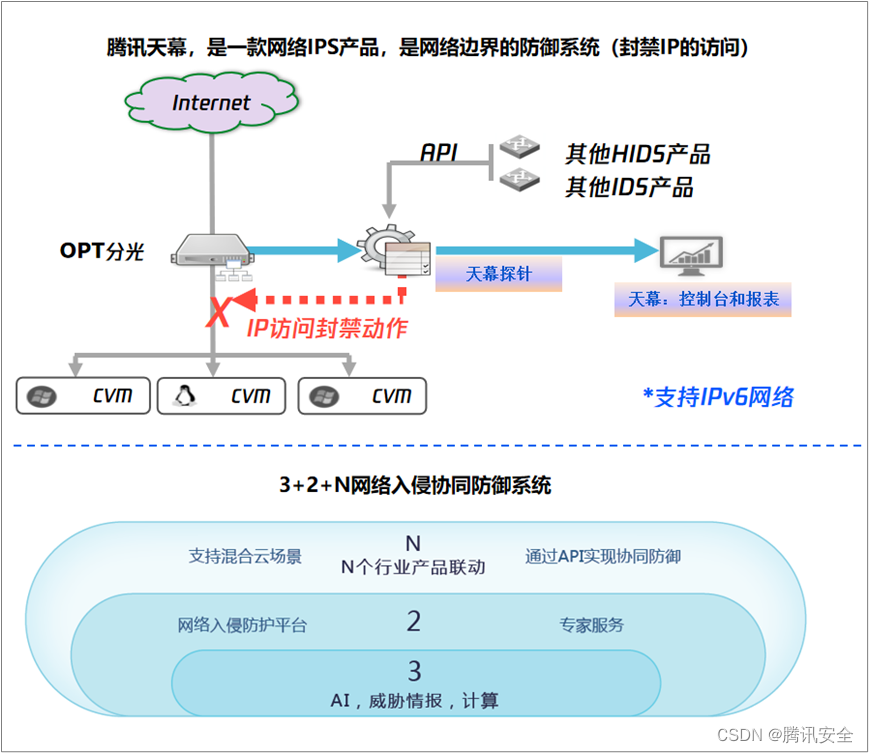
文章目录
- 背景
- 问题
- 分析
- 难点
- 解决方案:
- 总结公式
- 多字段作为分组如何处理
背景
最近笔者在进行对广告业务的数据统计时遇到这种情况,业务方嫌弃离线数仓太慢,又无需太高的实时性本该使用即席查询的OLAP去做,但是当前公司调研的OLAP还没有推到广告业务侧,无奈只得使用mysql暂时顶一下。我们当前使用的是mysql5.7。
一充用户:当日只有一次充值的用户,二充三充一次类推
笔单价:用户充值金额 / 用户充值笔数
问题
本次遇到了一个广告业务监控的指标,统计在一充、二充、三充用户最后一笔充值的笔单价
分析
我们发现一二三充这种维度并不难做,分析发现要想实现用户最后一笔订单笔单价的统计,首先需要实现分组下用户最后一笔订单金额和充值笔数的统计,这就需要把订单按照用户分组交易时间倒排取出用户的最后一次充值,这时候我们想到了开窗函数。
难点
但是mysql在mysql8之后才支持开窗函数,mysql5.7本身是没有开窗函数的,而做这个需求实现一个和hive一样开窗函数的功能。
解决方案:
笔者在调研了之后发现可以使用定义常量的方式进行实现。首先我们看如何实现分组排序,首先想要实现
row_number() over(partition by user_id order by trade_time desc)
这样的功能,我们需要
1. 首先定义好分组变量(@user_id)和顺序变量(@rank),这一步非常重要,否则会造成第二次执行会在第一次排名的基础继续增加。坑笔者已踩,希望大家避免不要暴雷。
2. 对数据先按user_id排序,正序倒序都可以,目的是使得同一个用户的数据聚集在一起,模拟开窗函数的partition by的分组聚集的功能,但是这里仅仅是聚集数据而非分组数据。数据在变量对比中实现的分组
3. 然后在按照trade_time降序排序,模拟开窗函数order by的排序功能
4. 这个时候我们就需要利用变量进行函数累计实现类似的一个排名操作,实际上它只是数据的行号
@rank :=CASE WHEN @user_id=o.user_id THEN @rank + 1 ELSE 1 END
逻辑中我们判断当@user_id等于user_id时,这个时候是同一个用户的订单数据来了所以我们对这个用户的数据的行号进行+1,因为数据已经在前面做过排序所以行号+1 正是数据在分组中的顺序。那么问题来了第一条数据或者用户的第一条数据来的时候变量中明显不是当前的user_id,第一条数据来的时候user_id是null,用户第一条数据来的时候他是另一个用户id或者null。我们分析第一条数据那他的顺序就是1,所以我们将这种情况rank else为1指定排名。然后将排名更新到顺序变量中,等待下次累加。
于是我们写出了如下代码:
set @user_id=null;
set @rank=0;
select
o.user_id AS user_id,
o.id,
o.amount,
(@rank :=CASE WHEN @user_id=o.user_id THEN @rank + 1 ELSE 1 END ) as row_number
from (
select
o.user_id AS user_id,
o.id,
o.amount
from (
select 1 as user_id,1001 as id, 90 AS amount, '2023-05-19 00:01:11' as trade_time union all
select 1 as user_id,1002 as id, 67 AS amount, '2023-05-19 03:01:38' as trade_time union all
select 1 as user_id,1003 as id, 88 AS amount, '2023-05-19 02:01:21' as trade_time union all
select 2 as user_id,1004 as id, 78 AS amount, '2023-05-19 01:01:12' as trade_time union all
select 2 as user_id,1005 as id, 66 AS amount, '2023-05-19 02:01:47' as trade_time union all
select 2 as user_id,1006 as id, 55 AS amount, '2023-05-19 05:01:19' as trade_time union all
select 3 as user_id,1007 as id, 99 AS amount, '2023-05-19 05:01:51' as trade_time union all
select 3 as user_id,1008 as id, 94 AS amount, '2023-05-19 04:01:30' as trade_time union all
select 3 as user_id,1009 as id, 90 AS amount, '2023-05-19 07:01:57' as trade_time
) o
order by o.user_id,o.trade_time desc
) o;
- 不要以为这就完了,我们测试现在我们代码
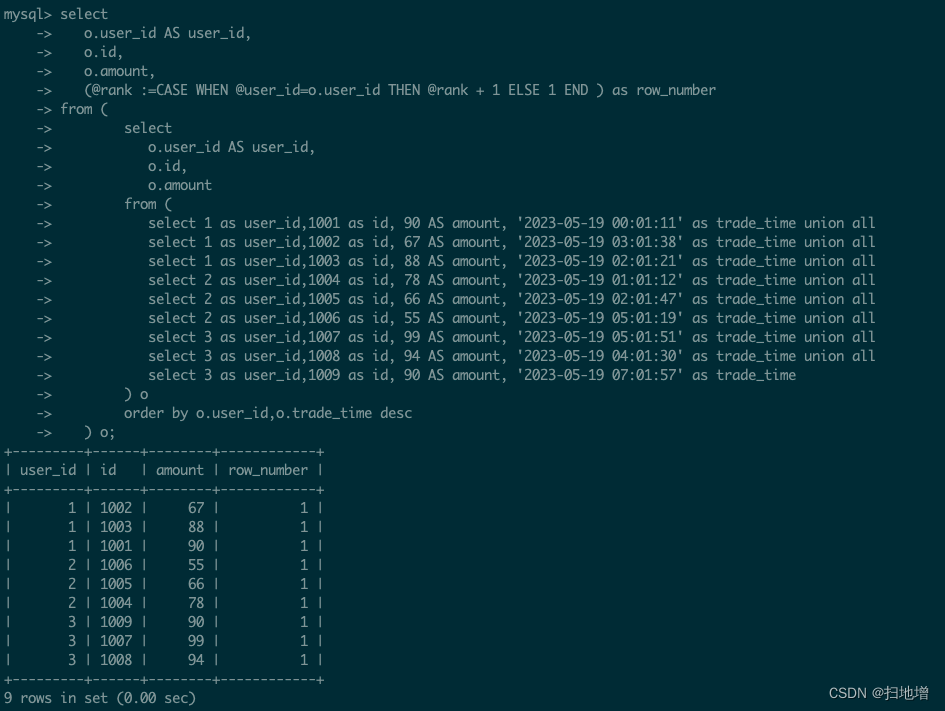
发现现在的结果并不是我们想要的,我们分析一下,我们光判断了@user_id=user_id,那么我们什么时候向里面写我们的值了呢?,突然发现原来万丈高楼连个地基都没有是空中楼阁啊!所以我们(铁律1:)在字段中必须有字段给常量赋值的逻辑 ( @user_id := o.user_id ),否则不能实现分组排序;好了,现在要想java一样给变量赋值了,那好我们进行赋值操作:
set @user_id=null;
set @rank=0;
select
@user_id:=o.user_id AS user_id,
o.id,
o.amount,
(@rank :=CASE WHEN @user_id=o.user_id THEN @rank + 1 ELSE 1 END ) as row_number
from (
select
o.user_id AS user_id,
o.id,
o.amount
from (
select 1 as user_id,1001 as id, 90 AS amount, '2023-05-19 00:01:11' as trade_time union all
select 1 as user_id,1002 as id, 67 AS amount, '2023-05-19 03:01:38' as trade_time union all
select 1 as user_id,1003 as id, 88 AS amount, '2023-05-19 02:01:21' as trade_time union all
select 2 as user_id,1004 as id, 78 AS amount, '2023-05-19 01:01:12' as trade_time union all
select 2 as user_id,1005 as id, 66 AS amount, '2023-05-19 02:01:47' as trade_time union all
select 2 as user_id,1006 as id, 55 AS amount, '2023-05-19 05:01:19' as trade_time union all
select 3 as user_id,1007 as id, 99 AS amount, '2023-05-19 05:01:51' as trade_time union all
select 3 as user_id,1008 as id, 94 AS amount, '2023-05-19 04:01:30' as trade_time union all
select 3 as user_id,1009 as id, 90 AS amount, '2023-05-19 07:01:57' as trade_time
) o
order by o.user_id,o.trade_time desc
) o;
我们执行代码结果如下:
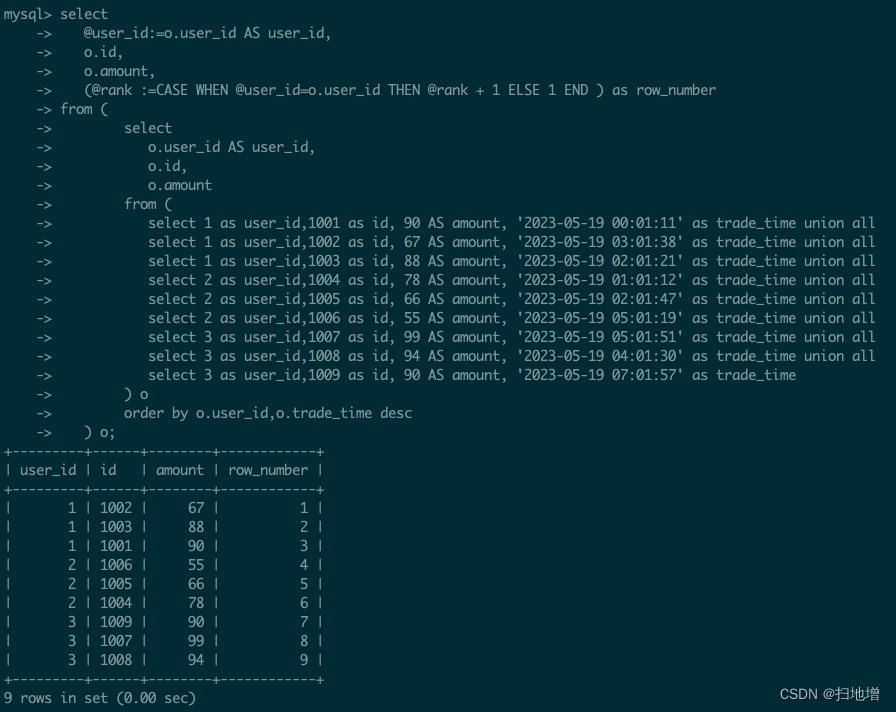
wtf ?什么鬼不是说好了给我赋值我就能行了吗?我们接着分析我的代码逻辑是如何判断的我判断第一个变量来的时候@user_id直接被赋值为实际user_id,判断相等这时候为1了,可是我们想我们都在判断前赋值了他还有机会为不相等的时候吗?显然没有了,这就出现了我们常量中的值因为一直相等,一直+1,最后成了全局排序。那我们于是乎把赋值移到判断后边。测试代码如下:
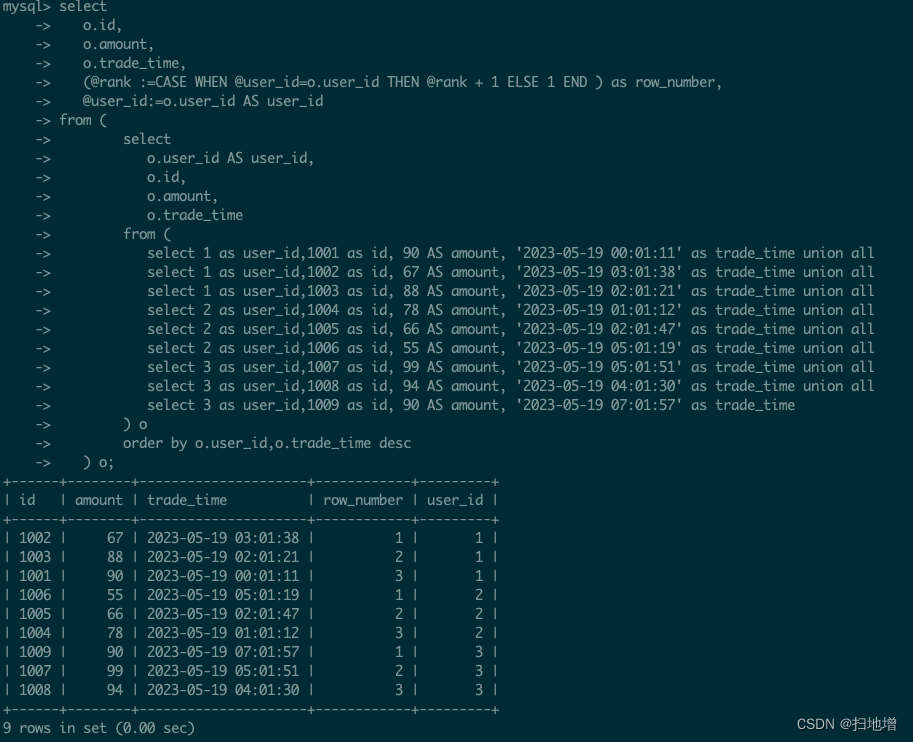
我们发现这一次的结果正是我们想要的,于是我们总结下:
(铁律2:)分组赋值字段必须在排序字段后面,否则是针对所有数据排序。最终排序代码如下:
set @user_id=null;
set @rank=0;
select
o.id,
o.amount,
o.trade_time,
(@rank :=CASE WHEN @user_id=o.user_id THEN @rank + 1 ELSE 1 END ) as row_number,
@user_id:=o.user_id AS user_id
from (
select
o.user_id AS user_id,
o.id,
o.amount,
o.trade_time
from (
select 1 as user_id,1001 as id, 90 AS amount, '2023-05-19 00:01:11' as trade_time union all
select 1 as user_id,1002 as id, 67 AS amount, '2023-05-19 03:01:38' as trade_time union all
select 1 as user_id,1003 as id, 88 AS amount, '2023-05-19 02:01:21' as trade_time union all
select 2 as user_id,1004 as id, 78 AS amount, '2023-05-19 01:01:12' as trade_time union all
select 2 as user_id,1005 as id, 66 AS amount, '2023-05-19 02:01:47' as trade_time union all
select 2 as user_id,1006 as id, 55 AS amount, '2023-05-19 05:01:19' as trade_time union all
select 3 as user_id,1007 as id, 99 AS amount, '2023-05-19 05:01:51' as trade_time union all
select 3 as user_id,1008 as id, 94 AS amount, '2023-05-19 04:01:30' as trade_time union all
select 3 as user_id,1009 as id, 90 AS amount, '2023-05-19 07:01:57' as trade_time
) o
order by o.user_id,o.trade_time desc
) o;
到这里分组排序就已经给大家说完了。
总结公式
学学其他大佬我们也来总结总结公式
要想实现
row_number() over(partition by 分组字段 order by 排序字段 desc)
的功能我们进行如下替换:
set @分组字段=null;
set @顺序字段=0;
select
o.cloumn1,
o.cloumn2,
o.cloumn3,
(@rank :=CASE WHEN @分组字段=o.分组字段 THEN @rank + 1 ELSE 1 END ) as row_number,
@user_id:=o.分组字段 AS 分组字段
from (
select
o.分组字段,
[o.cloumn1,
o.cloumn2,
o.cloumn3,
排序字段]
from table o
order by o.分组字段,o.排序字段 desc
) o;
那么到这里有同学就来提问了我要多字段分组怎么办?我们一次发挥一下:
多字段作为分组如何处理
我们依照公式直接在相关地方加上分组字段看看行不行?我们在数据中加上我想看一充二充三充用户在不同广告id下的最后一笔客单价,我们在数据中加上ad_id。按照以上公式逻辑得出代码:
set @user_id=null;
set @ad_id=null;
set @rank=0;
select
o.id,
o.amount,
o.trade_time,
(@rank :=CASE WHEN @user_id=o.user_id and @ad_id=o.ad_id THEN @rank + 1 ELSE 1 END ) as row_number,
@user_id:=o.user_id AS user_id,
@ad_id:=o.ad_id AS ad_id
from (
select
o.user_id,
o.ad_id,
o.id,
o.amount,
o.trade_time
from (
select 1 as user_id,1001 as id, 1111 AS ad_id, 90 AS amount, '2023-05-19 00:01:11' as trade_time union all
select 1 as user_id,1002 as id, 1112 AS ad_id, 67 AS amount, '2023-05-19 03:01:38' as trade_time union all
select 1 as user_id,1003 as id, 1111 AS ad_id, 88 AS amount, '2023-05-19 02:01:21' as trade_time union all
select 2 as user_id,1004 as id, 1112 AS ad_id, 78 AS amount, '2023-05-19 01:01:12' as trade_time union all
select 2 as user_id,1005 as id, 1112 AS ad_id, 66 AS amount, '2023-05-19 02:01:47' as trade_time union all
select 2 as user_id,1006 as id, 1112 AS ad_id, 55 AS amount, '2023-05-19 05:01:19' as trade_time union all
select 3 as user_id,1007 as id, 1114 AS ad_id, 99 AS amount, '2023-05-19 05:01:51' as trade_time union all
select 3 as user_id,1008 as id, 1114 AS ad_id, 94 AS amount, '2023-05-19 04:01:30' as trade_time union all
select 3 as user_id,1009 as id, 1113 AS ad_id, 90 AS amount, '2023-05-19 07:01:57' as trade_time
) o
order by o.ad_id,o.user_id,o.trade_time desc
) o;
测试结果如下:
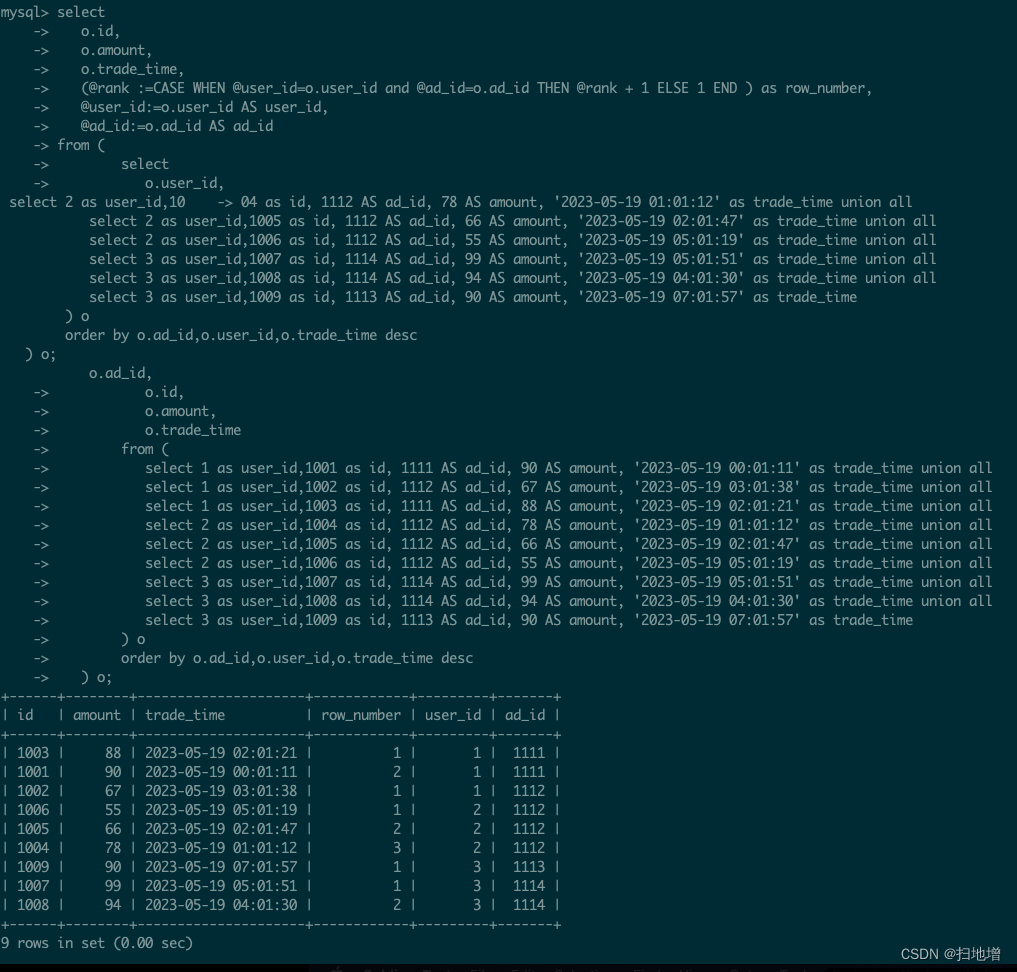
果然好用,到此结束本篇,希望可以帮助到大家。
注意:多分组维度覆盖范围大的维度放在前面



![[AI图片生成]自己搭建StableDiffusion安装过程](https://img-blog.csdnimg.cn/dff563e8d8dd407aa3d5e60f097467ee.png)