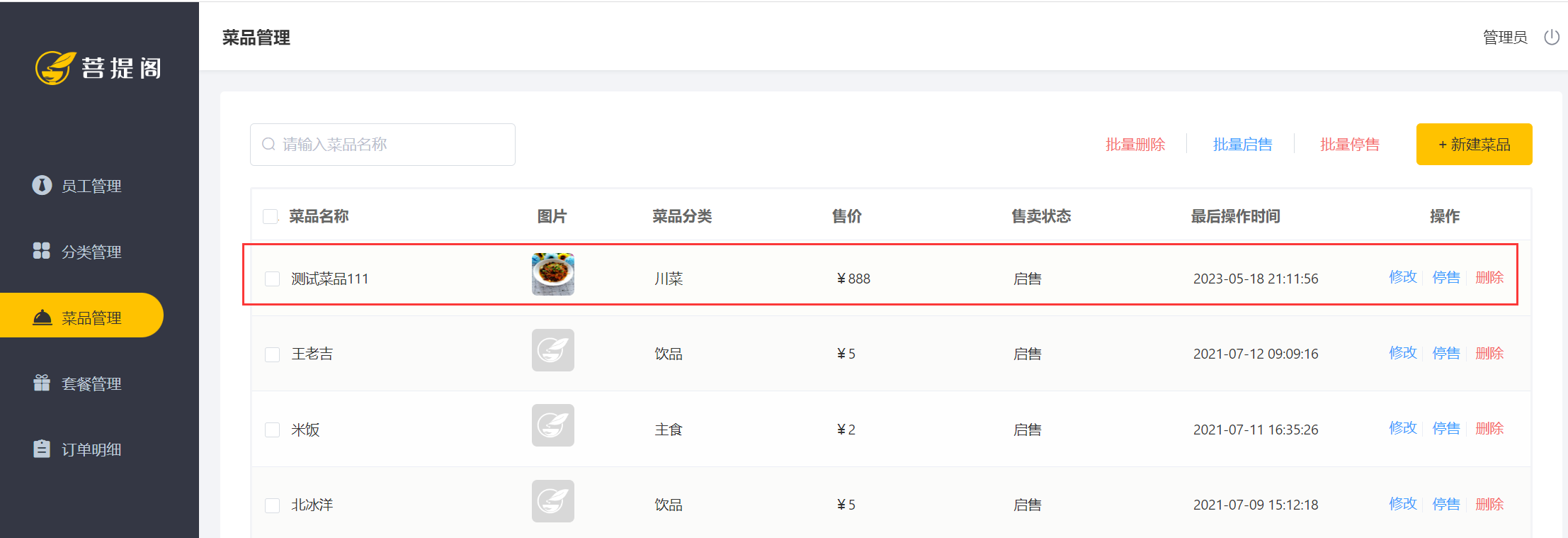
阅读文本大概需要 10 分钟,今天,不要面向监狱编程了。
序言
前段时间有一篇名为《只因写了一段爬虫,公司200多人被抓!》的文章非常火,相信大家应该都看到了。
这篇文章火起来之后,本来经过了一个多月的时间已经冷静下来了的爬虫圈子又开始人心惶惶了,各种说法层出不穷,大家都害怕自己一不小心就违法、进监狱过年,各种论坛、群看到爬虫就在说面向监狱编程,但是,事情真的是那样吗?
辟谣
我们先来看几个明显有误,且传播很广的说法吧。
“最近很多做爬虫的被抓了”
那篇文章的故事中提到的,是一家名为「巧达数据」的公司,如果之前有关注过相关新闻的朋友应该不难发现,这个公司实际上在19年上半年的时候就已经被查封了!
而文章后面提到的天翼征信、新颜科技、魔蝎科技、公信宝、同盾科技相关事件,实际上也都是19年下半年的事情了,都不是最近才发生的。
“最近一直有做爬虫的公司被抓”
很多人跟我说他看到一直有公司因为做爬虫被抓,但其实都是错觉,说白了,这只是因为你关注的信息来源(微信公众号)或者是你朋友圈内的人关注的信息来源都很集中、搞来搞去都是同一个圈子里的人导致的。
同一个圈子里的公众号关注得多了之后,会出现一个很神奇的现象:
你会发现你时不时地就看到某一篇文章在换了个标题之后,又出现在了你的消息列表/朋友圈/看一看中,而这篇文章很可能你已经看到过很多遍了。
这种现象你见得多了之后,很可能就会不再点开文章查看,也自然就不会知道它里面到底写了什么,你只是感觉好像一直有新的被抓的公司,但是实际上那些文章都只是换了个名字的旧文章。
“只要不遵守robots协议就会被抓”、“伪造UA(User-Agent)就会被抓”、“只要绕过、破解反爬虫措施就会被抓”
这几个说法的起源,是「某离职的头条员工做了一个头条的竞品,还爬了头条的数据,结果被告了」的那个案件的相关新闻。
但将这几个说法再次搬出来并且还传播开了的,是源于某个法律领域的公众号在魔蝎科技等公司被抓后,写的一篇对相关案件和法律的解读(当时是爆文,朋友圈都在刷屏)。
我们先来说说传播最广的这个法律领域的公众号所说的吧。律师毕竟不是做技术的,对很多技术方面的东西了解的并不多,所以有些内容在做技术的人看来其实是挺搞笑的。
但由于那位律师的文章当时太火了,很多人直接复制粘贴了他对相关法律的解读,所以这几种说法就被迅速流传了开来。
那么这几个说法的问题在哪里呢?
robots协议
robots协议实际上是君子协议,并不是法律明文规定的限制,最早只是针对搜索引擎爬虫而定的东西,但现在做搜索引擎爬虫的并不多,通常我们说的爬虫都是垂直爬虫(意思是针对某一个或多个网站/APP采集数据的爬虫)。
而这个“不遵守robots协议就会被抓”的说法最搞笑的地方就在于,现在几乎所有的网站robots.txt文件里都会像这样写:
注意这里的最后一个User-Agent,这个星号的意思是其他所有的爬虫,而Disallow后面跟着的斜杠,意思是禁止访问所有页面。
好了,如果遵守这个协议的话,除了搜索引擎的爬虫以外,谁都别玩了,要知道现在国内的大环境就是大家都不愿意把数据给开放出来,生怕别人拿了之后直接做一个竞品出来跟自己抢生意,所以根本没有国外网站上很常见的开放平台。
注:开放平台就是一个官方的、提供数据的地方。
所以如果真的都遵守这个协议的话,各种大数据分析都要凉凉,连数据都拿不到,分析啥呢?
注:别扯自家生产数据,没人只分析自家、不分析别人的。
伪造UA(User-Agent)
这个比说robots协议还搞笑,因为…现在根本没人直接根据UA来判断是否是同一个用户,改不改UA对人家反爬虫机制的判断一点影响都没有。
那位律师的这个说法,多半因为看了一些比较水的爬虫文章里说“修改UA可以绕过反爬”而理解出来的。
然后肯定有人要说了:“不管怎么样你都把UA改了啊”(有人跟我这么说过类似的话),你知道UA是干啥的么?
UA就只是一个特征字符串而已,它和robots一样,同样算是一个君子协议(不懂的朋友请阅读RFC中HTTP协议的部分),说白了这玩意就跟软件的名字一样,叫啥都行!
你看哪个明星很有名,你把自己的名字改得跟他一样,也没人会说你,因为这本来就没有任何问题!
绕过、破解反爬虫措施
说个最常见、最初级的解决反爬虫措施的办法:自动化测试工具控制浏览器进行请求。
请问浏览器请求时,如果没有触发反爬虫措施,算绕过、破解了吗?
如果你觉得机器操作的算,那请问我找一群人手动打开浏览器进行同样的操作算吗?
然后肯定还会有人说:“这根本不算破解反爬虫措施,破解是把验证码自动输入了才算”(同样有人这么跟我说过)。
那么请问,人工输入验证码算破解吗?找一群人人工输入验证码呢?
然后我们再来回顾一下那个头条的案件吧,那个案件一开始是各种新闻、文章都说是” 使用伪造device_id绕过服务器的身份校验,使用伪造UA及IP绕过服务器的访问频率限制 ”。
但从后来被爆出来的消息来看,说白了只是因为那人从头条离职了之后,不仅做了个竞品还爬老东家的数据直接放到自己那用而已,他的“tt_spider”所用到的那些操作并不是导致他被告的关键因素。
怎么避免违法
以下内容是根据本人对目前见到的知名案例的理解而写的,仅供参考,如有疑问建议联系律师协助你对具体情况进行分析。
个人隐私信息不要碰
很明显,今年的净网行动中,被一窝端的那些公司大部分都是做征信、风控、简历检索相关的,它们有个共同的特点,就是都采集了个人隐私信息并对外售卖。
做征信和风控的基本都是对社保、公积金、账单等信息进行了采集,它们的做法也都很类似:让用户在自己的APP中登录各种账号,从而获取到登录Cookie,接着就能使用Cookie随心所欲地监控用户的情况。
做简历检索的则是在各种招聘平台上注册了大量虚假企业账号,并通过招聘平台提供的功能获取了大量简历,有些做这方面的甚至还会有用虚假招聘的方式骗简历的操作,极其恶劣。
再次提醒,个人隐私信息千万不要碰!大部分公司根本没有那个权力去碰这些数据,一碰既死!
别人的东西不要拿了之后放到自己家里
在早些时候, 百度与大众点评不正当竞争纠纷案(上海市第一中级人民法院(2016)沪73民终242号)也挺火的,从案件内容中可以看到,百度采集了大众点评等APP上的店铺和评论信息,并直接在百度地图上进行展示。
这个案件大家应该都能理解得了吧?很简单的一个事情,我没有允许你拿走这个东西,但你直接拿走了,还放在了自己家里炫耀,这当然不行!
同理,所有不通过官方渠道(开放平台等)爬了其他网站的数据之后直接放到自己网站上的,都有风险,包括但不限于:
•爬了视频、音乐网站后把视频、音乐直接搬到自己网站上,为用户提供播放服务的。•爬了小说网站后把小说文本直接搬到自己网站上,为用户提供盗版阅读服务的。•爬了论坛网站后把所有贴子直接搬到自己网站上,改个名字假装自己是另一个论坛的。
不过,这方面除了盗版问题以外,大部分情况其实没人管,只要你不过分、不出名,搞个小破站出来其实人家也懒得搞你,容易出问题的是有些专门做此类事情的公司。
再次提醒,如果你正在某个公司做这种事情,建议尽早弃坑!
请求速度不要太过分
很多小白写爬虫的时候,并发毫无限制(可参考携程反爬虫部门某位老哥写的文章),这种做法实际上是会对对方服务器造成一定影响的,在数据量较大的情况下,如果对方的带宽很小,很有可能就会被你的高并发请求直接弄挂,这就相当于CC攻击了。
CC攻击是Dos攻击的一种,主要表现是对目标网站发起大量的HTTP请求,使其服务器性能被消耗殆尽,从而达到让对方服务器拒绝服务的效果。
Dos攻击就是让对方服务器拒绝服务的攻击的总称,而我们常听说的DDoS攻击其实是分布式拒绝服务攻击的意思,只是在Dos的基础上加了个分布式而已。
所以,千万注意控制自己的请求速度,控制在一个合理的范围内,如果你司老板或产品经理给你提了一个像“一天采集一遍淘宝全站”一样的这种需求,建议你直接怼回去。
这个请求速度,一方面你们这边的成本会非常高,另一方面,你们的法律风险极大,被爬的那一方完全可以以你们的爬虫对他们服务器的资源消耗过高为由(可参考某数据管理办法意见稿),直接将你们告上法庭,至于最后怎么判,完全看你们爬了数据做什么用。
不要碰黑色产业
这方面被抓的个人很多,基本都是接了个外包,然后对方是做黑产的,接外包的这位也不知道或者根本没去了解对方要他做的这个工具是用来干啥的,稀里糊涂地就被抓了。
举两个例子吧:
1.有人找你说做一个直播平台的登录、进直播间、刷弹幕、刷免费礼物一条龙服务的程序,但他们实际上是用来造假数据的,这个情况下,如果他们出事被抓了(刷量属于黑色产业,大概率出事),你就是从犯。2.之前知乎上有个很火的“接外包接进监狱的”回答,那个回答现在已经被删除了,但从内容上来看,与之前被抓的知名打码平台站长——微凉的情况很像,都是做了个验证码识别服务,都是给别人使用了,最后莫名其妙就被抓了。按回答中所说的,被抓的那个公司多半是做了上面那个例子中的事情,而且量非常大,而他提供了打码服务,所以就被连带上了。
所以,如果感觉自己在做的事情不对劲,千万要搞清楚,如果有问题,赶紧弃坑!
接外包的时候,建议在可以保留聊天记录的IM上与对方详细了解一下对方会用这个程序做什么,有问题的千万别接!
不要碰黄赌毒
这个其实就不怎么跟爬虫有关了,因为目前我看到的案例都是说接外包做了个菠菜网站,最后被连带一起抓了的,但与上一条一样,建议搞清楚自己做的东西会被用来干什么,并保留好聊天记录,涉及黄赌毒的千万别接!
不要对别人的软件进行逆向工程后还到处得瑟
很多人以为写对某个网站/APP的逆向文章是没有风险、可以随便写的,但实际情况只是人家懒得弄你而已,因为几乎所有的网站、APP的用户协议中,都会有类似这样的条款:
“在使用过程中,您将承担因下述行为而产生的全部法律责任:未经本公司授权,修改、破解、反编译、反汇编、逆向工程本产品,发布本产品的修改版、破解版等。”
有些游戏类的APP甚至还会有这样的条款:
“严禁修改、破译或进行任何影响游戏程序和游戏网络数据传输封包的行为。”
简单地说就是,只要你对他们的网站、APP进行了逆向,甚至是抓包,他们就有理由告你。
当然,这就跟遵守robots协议一样扯淡,现在做垂直爬虫的基本没有不逆向、不抓包的,而目前见到的案例也就只是对方要求删文而已,还没到抓人的程度。
但是,如果某篇文章的传播面过广,对对方造成的一定的损失,而且对方想要搞你的话,那你就凉凉了。
不要影响别人的正常业务
这个应该很好理解吧?抢票、刷单、薅羊毛之类的其实都是属于这一类的,只要你的操作量大了,就会影响到别人的正常业务,而且还很有可能会涉及到其他的利益关系,你说这情况不抓你抓谁?
非公开数据不要乱搞
这个也很简单,别人用来商业化的数据(如天眼查、企查查、启信宝等工商信息查询网站),你通过公开手段爬了之后拿去用,人家当然要告你。
并非指上面说的三家,指的是其它领域的东西,工商数据这一块目前还没看到相关案例。
总结
好了,差不多应该就是这些,这篇文章是想到啥就说啥了,对于一些细节方面的问题建议自行判断,判断不了的建议联系律师帮你分析,不要不知道什么情况还往里冲,这样子面向监狱编程是迟早的事情。
再引用一下之前看到过的《又一家数据公司被查,爬虫到底做错了什么?》这篇文章时,我总结的一个判断方法:
有个很简单的方法能判断出一件事情是否有违法风险,如果你不知道做某件事情会不会违法,但你觉得做这件事情似乎不太好,那么这件事情做完以后多半会出事!
最后说一下,技术无罪,但人的做法有罪,最核心的点是你做的事情合不合理、合不合法,希望各位读者能洁身自好,敬畏法律、敬畏人性。
如果你觉得文章还不错,请大家点赞分享下。你的肯定是我最大的鼓励和支持。