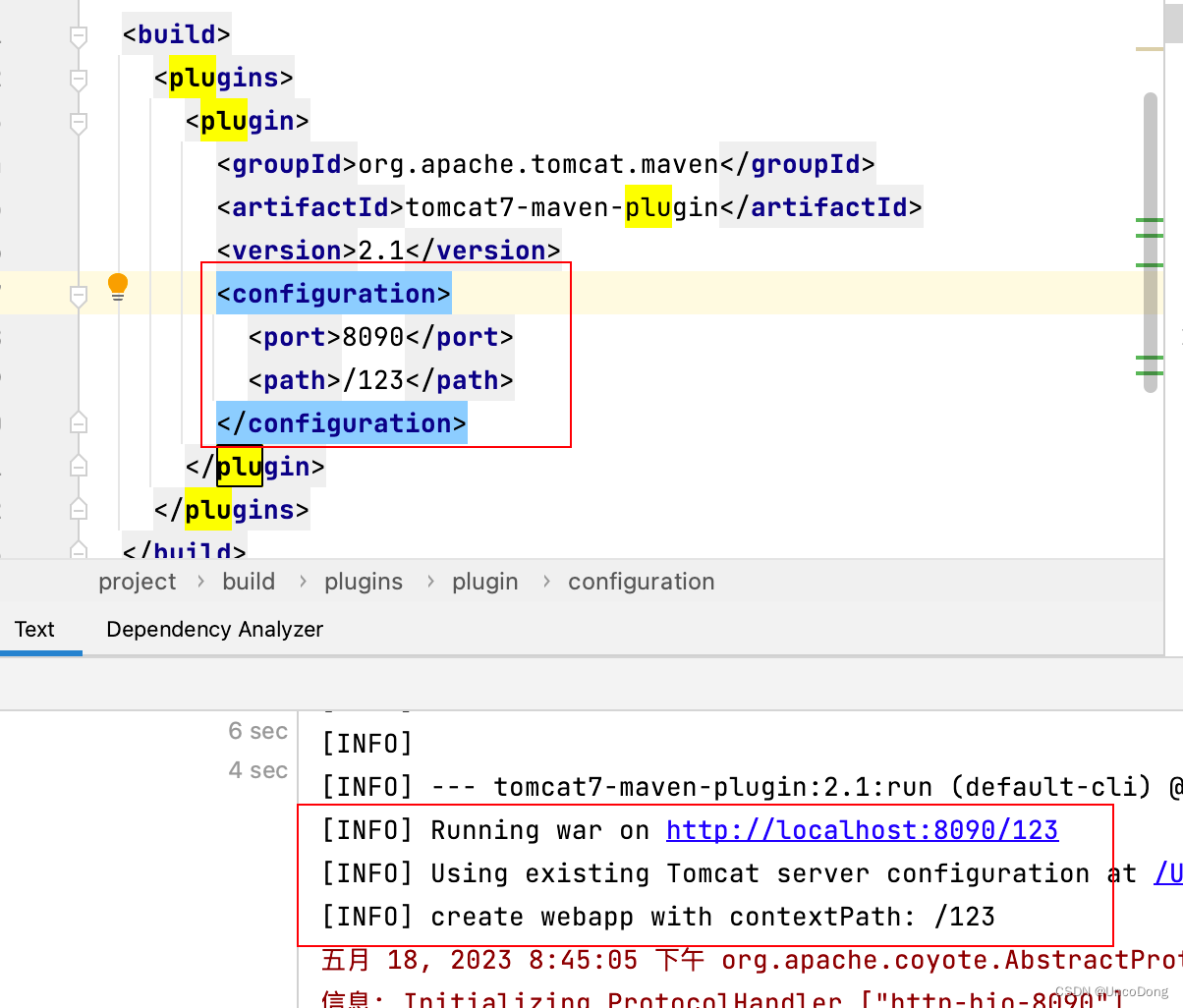
1.扩展统计信息的收集,可以用select dbms_stats.create_extended_stats('scott','test01','(object_name,object_type)')from dual
创建扩展统计列,然后dbms_stats.gather_table_stats('scott','test01')收集统计信息,也可以直接在
dbms_stats.gather_table_stats中的method_opt属性同时建立扩展统计又收集统计数据.
2.oracle 11g不仅可以收集多列扩展统计信息,还可以收集函数和表达式的扩展统计信息.
我们在收集列的统计信息与直方图时,往往都是对某一列的收集。当谓词使用多个相关列时,会导致约束条件的冗余。这几个相关的列也被称作关联列。出现这种情况时,查询优化器也会做出不准确的判断。所以我们必须对这些相关列收集统计信息或直方图来描述这种依赖关系。
幸运的是,从Oracle11g开始,数据库可以收集基于表达式或者一组列上的对象统计信息和直方图,从而解决这种问题。这种新的统计叫做扩展的统计信息(extension statistics)。
这种技术实际上是基于表达式或一组列创建一个隐藏列,叫做扩展(extension),再在扩展列上收集统计信息与直方图。
一、如何定义扩展列
可以调用Oracle自带的包dbms_stats的函数create_extended_stats来实现。下面对测试表的相关列做扩展列。测试表语句参见《Oracle中收集表与列统计信息》(http://www.linuxidc.com/Linux/2013-12/93503.htm)一个基于表达式upper(pad),另一个基于val2和val3组成的列组。在测试表里,val2和val3取值相同,高度关联。
SELECT DBMS_STATS.CREATE_EXTENDED_STATS(OWNNAME => 'TEST',
TABNAME => 'T',
EXTENSION => '(upper(pad))'),
DBMS_STATS.CREATE_EXTENDED_STATS(OWNNAME => 'TEST',
TABNAME => 'T',
EXTENSION => '(val2,val3)')
FROM DUAL;
这样就定义了两个扩展列。他们分别是基于表达式的和基于多列的。
二、如何查询扩展列信息
基于user_stat_extensions、dba_stat_extensions和all_stat_extensions,都能查询相关的扩展列信息。
SELECT COLUMN_NAME, DATA_TYPE, HIDDEN_COLUMN, DATA_DEFAULT
FROM USER_TAB_COLS
WHERE TABLE_NAME = 'T';
COLUMN_NAME DATA_TYPE HID DATA_DEFAULT
---------------------------------------- ---------- --- ----------------------------------------
ID NUMBER NO
VAL1 NUMBER NO
VAL2 NUMBER NO
VAL3 NUMBER NO
PAD VARCHAR2 NO
SYS_STU0KSQX64#I01CKJ5FPGFK3W9 VARCHAR2 YES UPPER("PAD")
SYS_STUPS77EFBJCOTDFMHM8CHP7Q1 NUMBER YES SYS_OP_COMBINED_HASH("VAL2","VAL3")
从data_default这列我们可以观察到,SYS_OP_COMBINED_HASH("VAL2","VAL3"),扩展列统计使用了哈希函数,所以val2和val3只有使用相等(=)谓词时,优化器才使用扩展统计信息。
二、如何删除扩展统计信息
依然使用Oracle自带的dbms_stats提供的过程drop_extended_stats来删除扩展统计信息。
BEGIN
DBMS_STATS.DROP_EXTENDED_STATS(OWNNAME => 'TEST',
TABNAME => 'T',
EXTENSION => '(upper(pad))');
DBMS_STATS.DROP_EXTENDED_STATS(OWNNAME => 'TEST',
TABNAME => 'T',
EXTENSION => '(val2,val3)');
END;
最后提一下,扩展统计信息是基于Oracle11g的另一个新特性——虚拟列。它并不存储数据,那它有什么现实意义呢?我们可以设想,在开发代码中,有很多sql语句用到了upper(varchar2)、trunc(date),此时尽管在这些列上建立索引,执行计划依然不会走索引,为了避免全表扫描,我们最好的方法是改写语法,谓词尽量不被函数转换,但有时候在不好转换语句时,可以创建一个虚拟列,然后在虚拟列上建立索引。比如下面的方法:
CREATE TABLE persons( NAME VARCHAR2(100), name_upper AS (UPPER(NAME)));
如果在频繁查询使用了upper(name)=’MIKE’,就可以使用name_upper=’MIKE’,前提是虚拟列建立索引。当然虚拟列也不不好的地方,比如插入数据不能指定所有列,因为虚拟列是不存数据的。
1.
理论知识必不可少,我们坚持秉承强大的理论知识和工作原理支撑案例输出的做法为大家分享技术,还是一样,第一部分,介绍具体的工作原理和相关扩展统计信息理论知识,帮助各位600成员去更深入的理解统计信息收集中的工作原理:
1.1我们都知道DBMS_STATS能够收集扩展的统计信息,当多个谓词存在于表的不同列上或谓词使用表达式时,这些统计信息可以改善基数反馈的结果
1.2那么所谓扩展可以是列组,也可以是表达式。当SQL语句中同时出现来自同一表的多个列时,列组统计信息可以改善基数反馈结果。同时当谓词使用表达式
(例如内置函数或用户定义函数,例如collect或者是function)时,也可以改变cbo预估的标准。
1.3注意了,我们不能在虚拟列上创建扩展统计信息收集
1.4那么我们如何去管理多列统计信息收集呢?在文档第二部分会详细介绍,案例别着急,都在后面。
2.
如何管理多列统计信息收集,或者叫列组统计信息收集。
2.1以下为oracle官方对于多列统计信息收集的概述:
About Statistics on Column Groups
Individual column statistics are useful for determining the selectivity of a single predicate in a WHERE clause.
Detecting Useful Column Groups for a Specific Workload
You can use DBMS_STATS.SEED_COL_USAGE and REPORT_COL_USAGE to determine which column groups are required for a table based on a specified workload.
Creating Column Groups Detected During Workload Monitoring
You can use the DBMS_STATS.CREATE_EXTENDED_STATS function to create column groups that were detected previously by executing DBMS_STATS.SEED_COL_USAGE.
Creating and Gathering Statistics on Column Groups Manually
In some cases, you may know the column group that you want to create.
Displaying Column Group Information
To obtain the name of a column group, use the DBMS_STATS.SHOW_EXTENDED_STATS_NAME function or a database view.
Dropping a Column Group
Use the DBMS_STATS.DROP_EXTENDED_STATS function to delete a column group from a table.
注意:
1.单个列统计信息对于确定WHERE子句中单个谓词的选择性非常有用。
2.可以使用DBMS_STATS.SEED_COL_USAGE和REPORT_COL_USAGE用于根据指定的工作负载确定表需要哪些列组。
3.我们还可以使用DBMS_STATS.CREATE_EXTENDED_STATS函数用于创建以前通过执行DBMS_STATS.SEED_COL_USAGE检测到的列组。
2.2当WHERE子句包含来自同一表的不同列上的多个谓词时,单个列统计信息不会显示列之间的关系。这是一个列组解决的问题,这里不要误解。
2.3cbo会独立地计算谓词的选择性,然后组合它们。但是,如果单个列之间存在相关性,那么在确定基数估计值时,cbo一般就不能考虑到这一点,那么一般来讲cbo的计算方法都是通过将每个表谓词的选择性乘以行数来创建基数估计值
注意:1.选择性是啥? selectivity参数就是选择性
2.一般来讲优化器使用列组统计信息来表示等式谓词以及inlist谓词
2.4以下的示例演示了列组统计信息如何使cbo能够提供更精确的基数反馈预估结果。我们主要演示三部分内容:
2.4.1包括自动和手动列组统计
2.4.2自动或手动创建列组统计信息。
2.4.3列组统计数据的用户界面
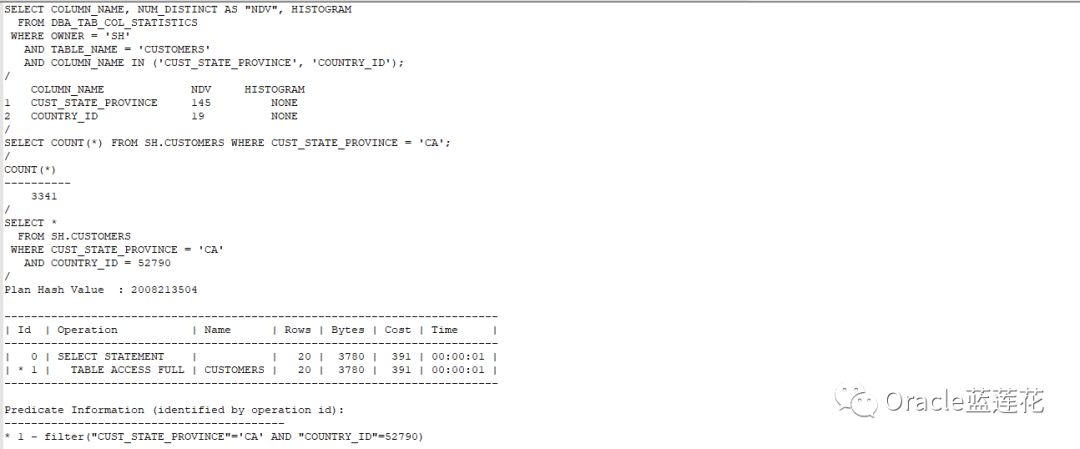
注意:
1.根据country_id和cust_state_province列的单列统计数据,cbo预估的美国加利福尼亚客户的查询将返回20行才。但实际上,有3341个客户居住在加利福尼亚,但是cbo不知道加州是在美国,因此通过假设两个谓词都减少了返回的行数,大大降低了基数反馈预估的结果。
2.我们来看看通过收集列组统计数据,能不能让cbo了解到country_id和cust_state_province中的值之间的实际关系。能不能让cbo预估更准确的基数反馈内容




注意:预估行源返回正确的结果集,OK,我们来看一些扩展知识
3.
与列组相关的DBMS_STATS api
3.1我们可以使用DBMS_STATS.SEED_COL_USAGE和REPORT_COL_USAGE用于根据指定的工作负载确定表需要哪些列组。当我们不知道要创建哪些扩展统计信息时,这种技术非常有用。
这种技术不适用于表达式统计.来看如下示例:


注意:
1.第一个计划显示返回932行查询但cbo预估的基数反馈结果为1。第二个计划显示返回145行查询但cbo预估的基数反馈结果为1949
2.下面我们调用DBMS_STATS生成报表的REPORT_COL_USAGE函数,注意这个调用结果返回clob字段内容:
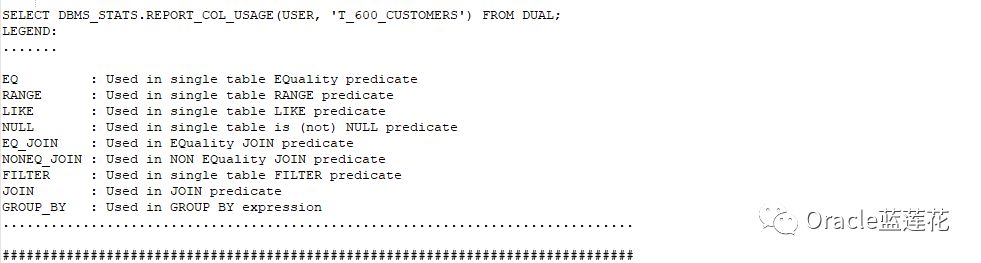

注意:
1.在监视打印的结果日志中我们看到
2.这三列都出现在同一个WHERE子句中,因此报告将它们显示为一个组过滤器。
3.在第二个查询中,GROUP BY子句中出现了两列,因此报告将它们标记为GROUP_BY。过滤器和GROUP_BY报告中的列集是列组的候选列前三列用于等式谓词
4.别着急,继续往下看
......
......
......
3.2刚才我们在创建工作负载监视期间检测到了列组,但有什么用呢?具体作用在哪里?
3.3这时候我们可以使用DBMS_STATS.CREATE_EXTENDED_STATS函数用于创建以前通过执行DBMS_STATS.SEED_COL_USAGE检测到的列组。

注意:1.oracle为T_600_CUSTOMERS创建了两个列组:一个列组用于筛选谓词,另一个组用于按操作分组

注意:
1.从DBMS_STATS返回的两个列组名。CREATE_EXTENDED_STATS函数。在CUST_CITY、CUST_STATE_PROVINCE 和 COUNTRY_ID 上创建的列组具有频率直方图
2.Oracle12c引入了混合直方图。当直方图中不同值的数量大于254时,一些频繁执行的value可能会在bucket中丢失,导致索引使用不太理想。
3.现在,单个桶可以存储该值的流行程度,有效地增加了桶的数量,而实际上没有增加桶的数量。
4.Oracle传统上提供两种优化器直方图,高度平衡和频率平衡。从Oracle 12c开始,我们看到了这两种直方图方法的合并
5.一般混合直方图的算法为:n小于NDV,其中n是用户指定的桶数。如果没有指定数字,那么n默认为254
4.
手动创建列组统计信息
4.1我们还是以刚才创建的临时表为例子,假设我们要为cust_state_province,country_id这两列手动创建列组统计信息

4.2显示列组统计信息通过如下方式:
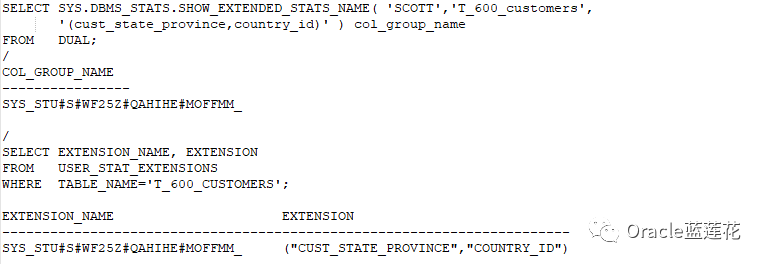
4.3当然了,比如我们要查询不同值的数量,并查找是否为列组创建了直方图,可以做下面的查询:

4.4对于列组统计信息删除就非常简单了:

5.
当WHERE子句具有使用表达式的谓词时,称为表达式统计信息的扩展统计信息类型,那么基于这种情况,如何操作?其实换汤不换药
5.1第一步操作和文档4中介绍方法一样,例如我们收集一个low函数表达式的列组统计信息:

5.2要获得有关表达式统计信息,使用数据库视图DBA_STAT_EXTENSIONS和DBMS_STATS。SHOW_EXTENDED_STATS_NAME函数。

5.3同样的各位,查询不同值的数量,并查找是否为表达式创建了直方图怎么查?
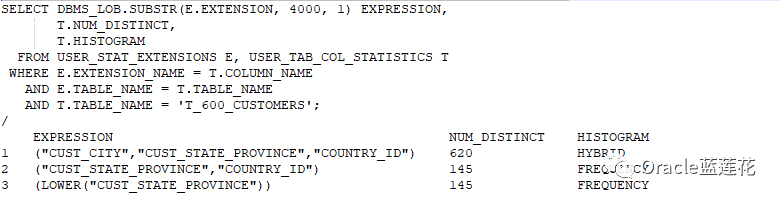
注意:刚才我们用lower表达式创建的列组统计信息生成了频率直方图
5.4删除基于表达式的多列统计信息也是一样的,代码非常简单

6.
案例分享:
6.1初始化操作:
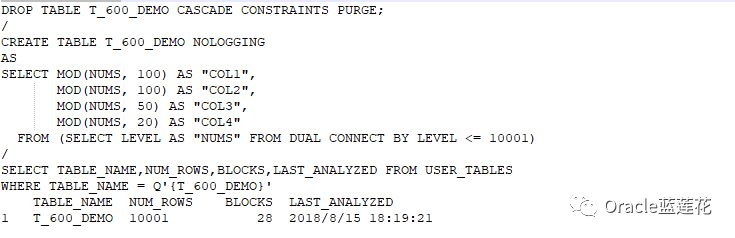
注意:12c版本ctas会自动收集统计信息,无需手动调用dbms_stats API
6.2我们先收集一个直方图统计信息

6.3执行如下查询
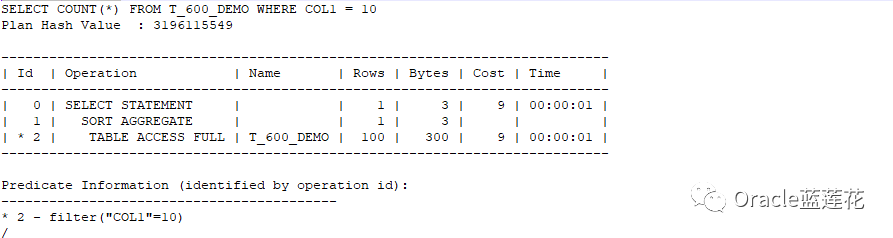
注意:OK的,没问题,cbo全表扫描t_600_demo表,预估的基数反馈结果为100行,实际的a_rows的查询结果也是100行
6.4我们来看如下查询:

注意:
1.id2上存在filter,同时cbo预估全表扫描返回结果为1条,实例的a_rows因为刚才我们做了mod操作, 两列都是10,实际结果应该是100条
2.在不考虑直方图的情况下,简单情况下的选择性为(1/NDV)。这远非事实。至少有100行co1=10, col2=10。
6.5我们来进行列组统计信息收集:
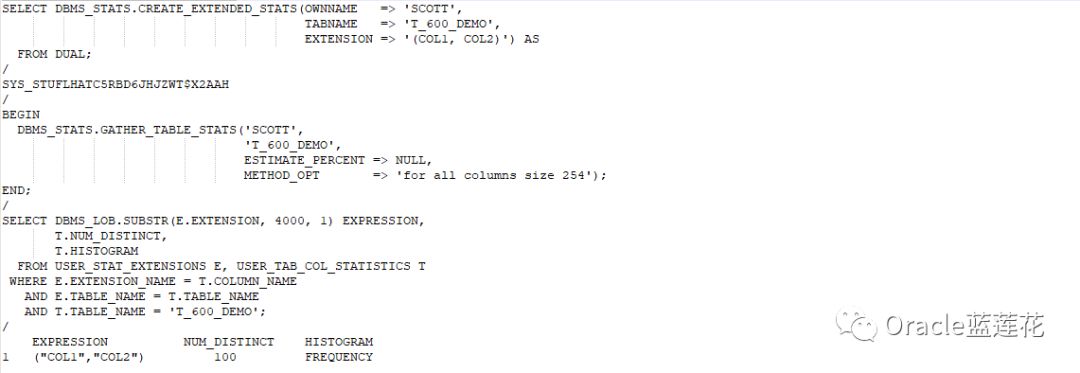
6.6再次查看执行计划:

注意:cbo预估的行数正常了
6.7现在我们删除统计信息
BEGIN
DBMS_STATS.DROP_EXTENDED_STATS('SCOTT',
'T_600_DEMO',
'("COL1","COL2")');
END;
6.8我们添加一个扩展的stats将一个新的虚拟列添加到表中
alter table "SCOTT"."T_600_DEMO" add (SYS_STUFLHATC5RBD6JHJZWT$X2AAH
as (sys_op_combined_hash(COL1, COL2)) virtual BY USER for statistics);
6.9再次收集统计信息:
BEGIN
DBMS_STATS.GATHER_TABLE_STATS('SCOTT',
'T_600_DEMO',
ESTIMATE_PERCENT => NULL,
METHOD_OPT => 'for all columns size 254');
END;
/
6.10结果是一样的

注意:
1.虚拟列名是隐式的,它似乎是从table_name、column_name组合中派生出来的。这就是我们重新分析表的原因。
2.优化器调用了一个新的确定性哈希函数sys_op_combined_hash,以填充这个虚拟列值。对于参数pas的唯一组合,这个确定性函数返回相同的值
3.在所有列上收集直方图也在这个虚拟列上收集直方图
7.
关于ORA-54033
7.1日常工作中我们去modify一个表的字段,但是修改过程中告诉我们不允许修改带有虚拟列表达式的类型,然而我们并没有虚拟列存在,什么情况?
7.1.1例如我们对刚才的测试表做modify操作:
ALTER TABLE T_600_DEMO MODIFY COL1 NVARCHAR2(100);
ORA-54033:要修改的列由某个虚拟列表达式使用
7.2我们来验证一下数据字典内容:

注意:
这个SYS_STUFLHATC5RBD6JHJZWT$X2AAH其实就是刚才我们做列组统计信息收集形成的虚拟列
7.3解决办法也很简单,删除列组统计信息即可,在做modify操作
BEGIN
DBMS_STATS.DROP_EXTENDED_STATS('SCOTT', 'T_600_DEMO', '(COL1,COL2)');
END;