1 RestNet介绍
RestNet是2015年由微软团队提出的,在当时获得分类任务,目标检测,图像分割第一名。该论文的四位作者何恺明、张祥雨、任少卿和孙剑如今在人工智能领域里都是响当当的名字,当时他们都是微软亚研的一员。实验结果显示,残差网络更容易优化,并且加深网络层数有助于提高正确率。在ImageNet上使用152层的残差网络(VGG net的8倍深度,但残差网络复杂度更低)。对这些网络使用集成方法实现了3.75%的错误率。获得了ILSVRC 2015竞赛的第一名。
论文地址:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf 这是一篇计算机视觉领域的经典论文。李沐曾经说过,假设你在使用卷积神经网络,有一半的可能性就是在使用 ResNet 或它的变种。https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdfResNet 论文被引用数量突破了 10 万+。
2 RestNet网络结构
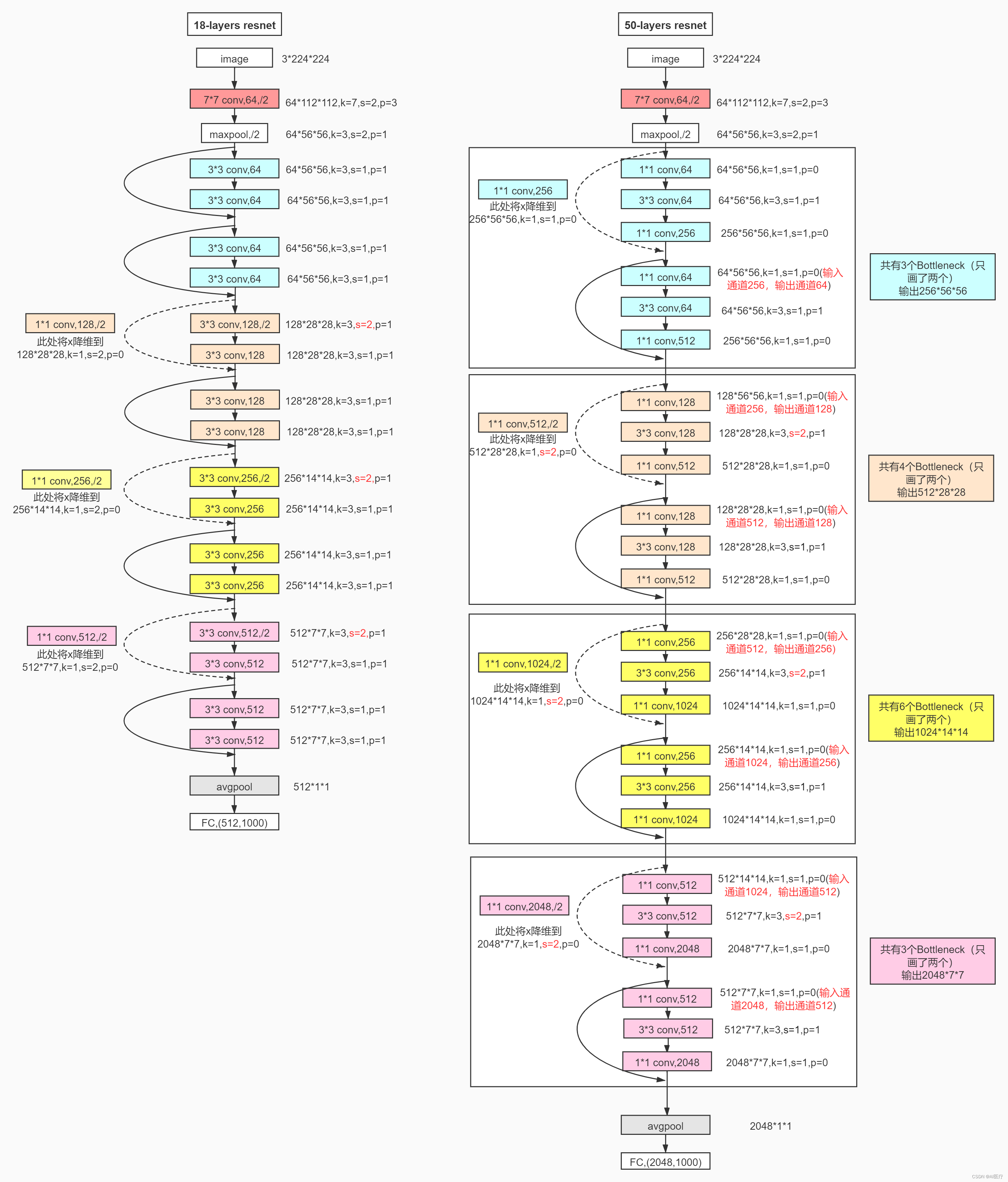
ResNet的经典网络结构有:ResNet-18、ResNet-34、ResNet-50、ResNet-101、ResNet-152几种,其中,ResNet-18和ResNet-34的基本结构相同,属于相对浅层的网络,后面3种属于更深层的网络,其中RestNet50最为常用。
残差网络是为了解决深度神经网络(DNN)隐藏层过多时的网络退化问题而提出。退化(degradation)问题是指:当网络隐藏层变多时,网络的准确度达到饱和然后急剧退化,而且这个退化不是由于过拟合引起的。

假设一个网络 A,训练误差为 x。在 A 的顶部添加几个层构建网络 B,这些层的参数对于 A 的输出没有影响,我们称这些层为 C。这意味着新网络 B 的训练误差也是 x。网络 B 的训练误差不应高于 A,如果出现 B 的训练误差高于 A 的情况,则使用添加的层 C 学习恒等映射(对输入没有影响)并不是一个平凡问题。
为了解决这个问题,上图中的模块在输入和输出之间添加了一个直连路径,以直接执行映射。这时,C 只需要学习已有的输入特征就可以了。由于 C 只学习残差,该模块叫作残差模块。
此外,和当年几乎同时推出的 GoogLeNet 类似,它也在分类层之后连接了一个全局平均池化层。通过这些变化,ResNet 可以学习 152 个层的深层网络。它可以获得比 VGGNet 和 GoogLeNet 更高的准确率,同时计算效率比 VGGNet 更高。ResNet-152 可以取得 95.51% 的 top-5 准确率。

RestNet18和RestNet50网络结构如下:
3 基于pytorch在CIFAR10数据下的RestNet50的实现
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, utils
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
from torchvision.transforms import transforms
import torch.nn.functional as F
import datetime
transform = transforms.Compose([ToTensor(),
transforms.Normalize(
mean=[0.5, 0.5, 0.5],
std=[0.5, 0.5, 0.5]
),
transforms.Resize((224, 224))
])
training_data = datasets.CIFAR10(
root="data",
train=True,
download=True,
transform=transform,
)
testing_data = datasets.CIFAR10(
root="data",
train=False,
download=True,
transform=transform,
)
class Bottleneck(nn.Module):
def __init__(self, in_channels, out_channels, stride=[1, 1, 1], padding=[0, 1, 0], first=False) -> None:
super(Bottleneck, self).__init__()
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], padding=padding[0], bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # 原地替换 节省内存开销
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride[1], padding=padding[1], bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), # 原地替换 节省内存开销
nn.Conv2d(out_channels, out_channels * 4, kernel_size=1, stride=stride[2], padding=padding[2], bias=False),
nn.BatchNorm2d(out_channels * 4)
)
# shortcut 部分
# 由于存在维度不一致的情况 所以分情况
self.shortcut = nn.Sequential()
if first:
self.shortcut = nn.Sequential(
# 卷积核为1 进行升降维
# 注意跳变时 都是stride==2的时候 也就是每次输出信道升维的时候
nn.Conv2d(in_channels, out_channels * 4, kernel_size=1, stride=stride[1], bias=False),
nn.BatchNorm2d(out_channels * 4)
)
def forward(self, x):
out = self.bottleneck(x)
out += self.shortcut(x)
out = F.relu(out)
return out
# 采用bn的网络中,卷积层的输出并不加偏置
class ResNet50(nn.Module):
def __init__(self, Bottleneck, num_classes=10) -> None:
super(ResNet50, self).__init__()
self.in_channels = 64
# 第一层作为单独的 因为没有残差快
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# conv2
self.conv2 = self._make_layer(Bottleneck, 64, [[1, 1, 1]] * 3, [[0, 1, 0]] * 3)
# conv3
self.conv3 = self._make_layer(Bottleneck, 128, [[1, 2, 1]] + [[1, 1, 1]] * 3, [[0, 1, 0]] * 4)
# conv4
self.conv4 = self._make_layer(Bottleneck, 256, [[1, 2, 1]] + [[1, 1, 1]] * 5, [[0, 1, 0]] * 6)
# conv5
self.conv5 = self._make_layer(Bottleneck, 512, [[1, 2, 1]] + [[1, 1, 1]] * 2, [[0, 1, 0]] * 3)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(2048, num_classes)
def _make_layer(self, block, out_channels, strides, paddings):
layers = []
# 用来判断是否为每个block层的第一层
flag = True
for i in range(0, len(strides)):
layers.append(block(self.in_channels, out_channels, strides[i], paddings[i], first=flag))
flag = False
self.in_channels = out_channels * 4
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.avgpool(out)
out = out.reshape(x.shape[0], -1)
out = self.fc(out)
return out
if __name__ == "__main__":
res50 = ResNet50(Bottleneck)
batch_size = 64
train_data = DataLoader(dataset=training_data, batch_size=batch_size, shuffle=True, drop_last=True)
test_data = DataLoader(dataset=testing_data, batch_size=batch_size, shuffle=True, drop_last=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = res50.to(device)
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
epochs = 10
for epoch in range(epochs):
running_loss = 0.0
running_correct = 0.0
model.train()
print(f"{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}, Epoch {epoch}/{epochs}")
for X_train, y_train in train_data:
X_train, y_train = X_train.to(device), y_train.to(device)
outputs = model(X_train)
_, pred = torch.max(outputs.data, 1)
optimizer.zero_grad()
loss = cost(outputs, y_train)
loss.backward()
optimizer.step()
running_loss += loss.item()
running_correct += torch.sum(pred == y_train.data)
testing_correct = 0
test_loss = 0
model.eval()
for X_test, y_test in test_data:
X_test, y_test = X_test.to(device), y_test.to(device)
outputs = model(X_test)
loss = cost(outputs, y_test)
_, pred = torch.max(outputs.data, 1)
testing_correct += torch.sum(pred == y_test.data)
test_loss += loss.item()
print("{}, Train Loss is:{:.4f}, Train Accuracy is:{:.4f}%, Test Loss is::{:.4f} Test Accuracy is:{:.4f}%".format(
datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
running_loss / len(training_data),
100 * running_correct / len(training_data),
test_loss / len(testing_data),
100 * testing_correct / len(testing_data)
))