BEVFusion有两篇文章,这里在一起分析下不同,分别是:
【1】BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework.
【2】BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation
先说结论,这俩虽然名字和网络结构图都挺像,但完全是不同的角度来进行融和特征,解决的问题也不一样。【1】主要让激光相机融合前独立运行,剥离依存关系。【2】主要解决融合时BEV特征统一性问题,并对该方式的运行效率做了优化。下面来看具体情况。
1.A Simple and Robust LiDAR-Camera Fusion Framework.
在工业界普遍使用的是后融合,因为这种方案比较灵活,鲁棒性也更好,不同模态的输出的结果通过人工设计的算法和规则进行整合,不同模态在不同情况下会有不同的使用优先级,因此能够更好的处理单一传感器失效时对系统的影响。但是后融合缺点也很多,一是信息的利用不是很充分,二是把系统链路变得更加复杂,链路越长,越容易出问题,三是当规则越堆叠越多之后维护代价会很高。学术界目前比较推崇的是前融合方案,能够更好的利用神经网络端到端的特性。但是前融合的方案少有能够直接上车的,原因我们认为是目前的前融合方案鲁棒性达不到实际要求, 尤其是当雷达信号出现问题时,目前的前融合方案几乎都无法处理。
1.1 文章概述
常见的前融合第一种如(a)中首先将雷达点,根据外参和相机内参投影到图像或图像提取的2D特征上去采样对应的视觉特征,然后拼接到点云上,后面就可以通过常用的点云3D检测算法进行处理,比如3DSSD[1], PointPillar[2], CenterPoint[3]等,目前PointPainting[4], PointAugment[5]就属于这类工作;
第二种如图1(b)所示,先对雷达点云进行特征提取,然后将特征或者初始预测值按照外参和相机内参投影到图像或图像提取的2D特征上去采样对应特征,然后拼接回来,再接上对应的任务头,目前MVXNet[6], TransFusion[9]就属于这种类型的工作。
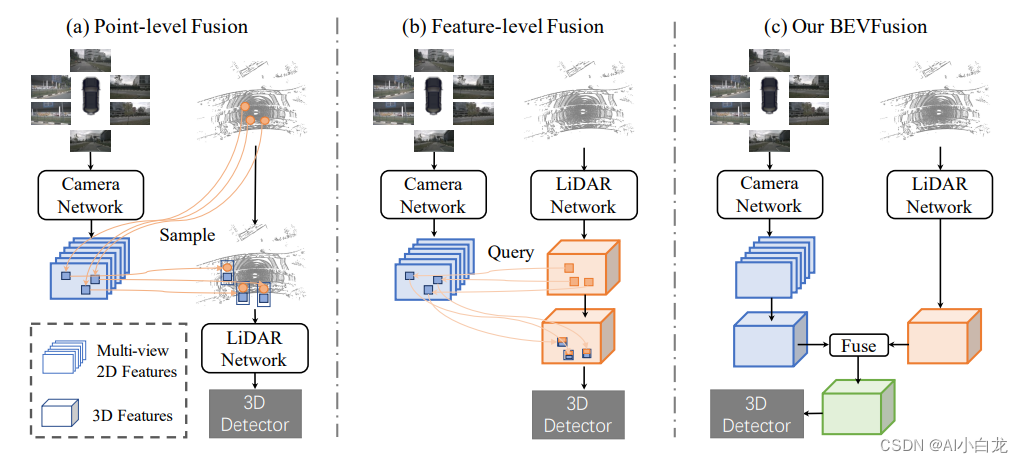
前融合算法对比
前两种的缺点在于:
1)雷达和相机的外参不准 由于校准问题或车辆运行时颠簸抖动,会造成外参不准,导致点云和图像直接的投影会出现偏差
2)相机噪声 比如镜头脏污遮挡,卡帧,甚至是某个相机损坏等, 导致点云投影到图像上找不到对应的特征或得到错误的特征
3)雷达噪声 除了脏污遮挡问题;对于一些低反的物体,雷达本身特性导致返回点缺失,我们就在实际场景中发现,在雨天黑色的车辆反射点就极少,另外对于某些车型,比如国内新发售的蔚来ET7,其激光雷达的FOV本来就只会覆盖到一个有限的角度;
就算是DeepFusion,可以一定程度兼容(1)(2)问题,但是对于问题(3)雷达噪声导致的点云缺失,都是无能为力的。因为这类方法都需要通过点云坐标去Query图像特性,一旦点云缺失,所有的手段都无法进行了。
文章提出了BEVFusion的框架,和之前的方法不同的是雷达点云的处理和图像的处理是独立进行的,利用神经网络进行编码,投射到统一的BEV空间,然后将二者在BEV空间上进行融合。这种情况下雷达和视觉没有了主次依赖,从而能够实现近似后融合的灵活性:单一模态可以独立进行完成任务,当增加多种模态后,性能会大幅提高,但是当某一模态缺失或者产生噪声,不会对整体产生破坏性结果。
1.2 具体方法
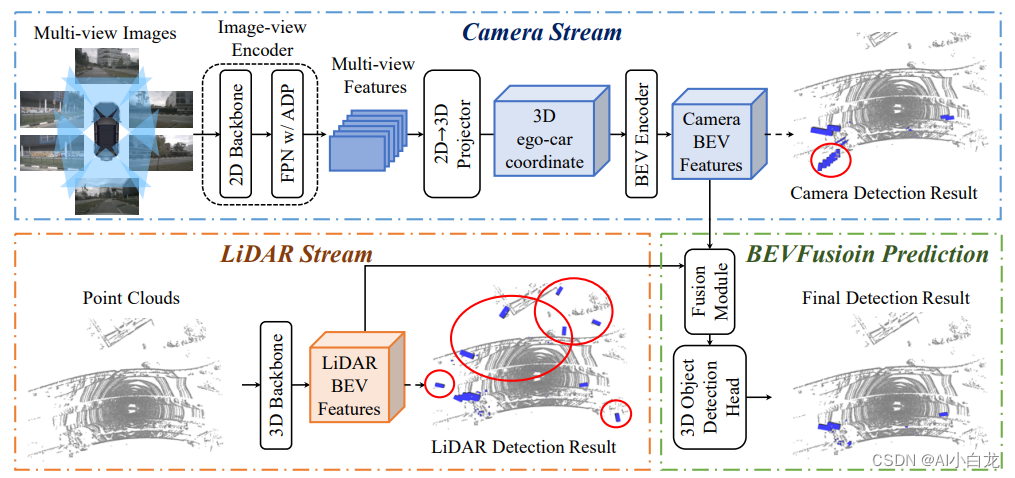
文章是如何BEV空间上进行融合的呢?
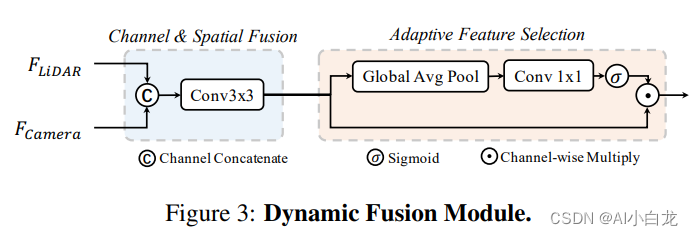
作为一个通用框架,雷达分支和视觉分支都可以采用多种不用的结构,雷达分支我们测试了基于Voxel和基于Pillar的编码方式,Camera分支是我们对Lift-Splat-Shoot[8]进行了改造,使其更加适合完成3D BBox检测任务,任务头我们测试了Anchor-based, Anchor-free, 以及TransFusion[9]里使用的基于Transformer的Header,并且我们对Fusion模块也进行了改进,使其能够更加有效的融合不同模态信息,如图4所示。
融合模块的改进如下:
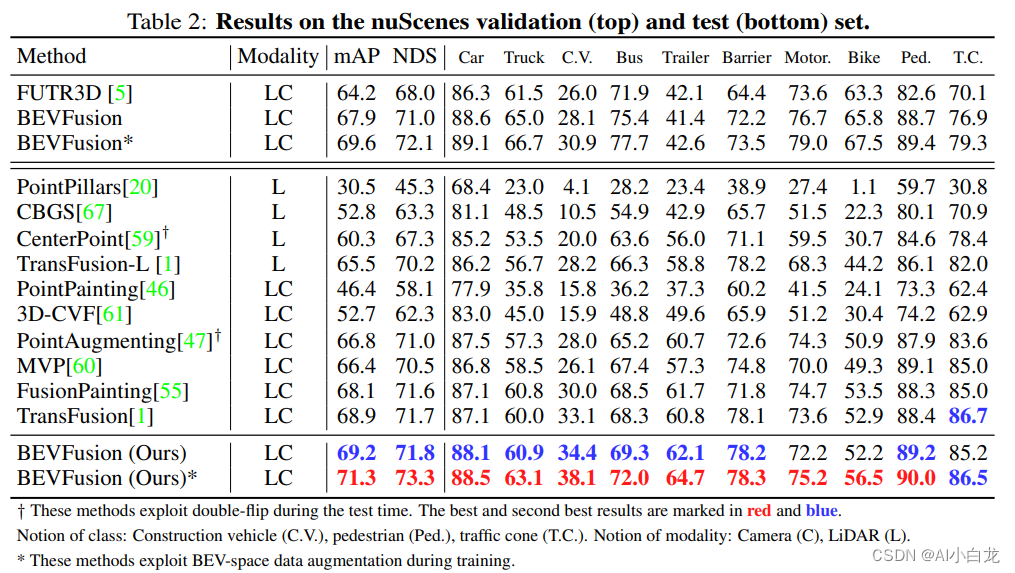
 指标结果如下:
指标结果如下:
2. Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation
将多传感器融合对于准确可靠的自动驾驶系统至关重要。最近提出的方法基于点级(point-level)融合:使用摄像头特征增强激光雷达点云。然而,摄像头到激光雷达的投影丢弃了摄像头特征的语义密度(semantic density),阻碍了此类方法的有效性,尤其是对于面向语义的任务(如3D场景分割)。文章特别指出:对于典型的32线激光雷达扫描,只有5%的摄像头特征与激光雷达点匹配,而其他所有特征都将被删除。对于更稀疏的激光雷达(或成像雷达),这种密度差异将变得更加剧烈。
2.1文章概述
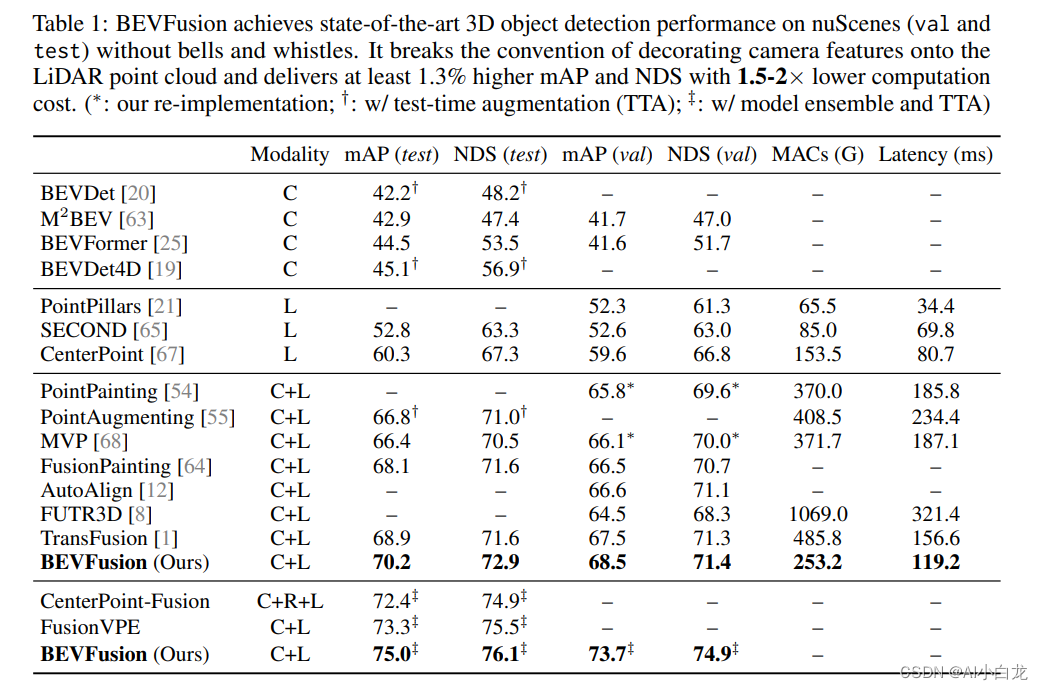
本文提出的BEVFusion是一种多任务多传感器融合框架,其统一BEV表征空间中的多模态特征,很好地保留了几何和语义信息。为实现这一点,优化BEV池化,诊断并解除视图转换中的关键效率瓶颈,将延迟减少了40倍。BEVFusion从根本上来说是任务无关的,无缝支持不同的3D感知任务,几乎没有架构的更改。
在nuScenes数据集的3D目标检测上实现1.3%的mAP和NDS提升,在BEV分割上实现了13.6%的mIoU提升,计算成本降低了1.9倍。代码将开源 https://github.com/mit-han-lab/
BEVFusion:给定不同的感知输入,首先应用特定于模态的编码器来提取其特征;将多模态特征转换为一个统一的BEV表征,其同时保留几何和语义信息;存在的视图转换效率瓶颈,可以通过预计算和间歇降低来加速BEV池化过程;然后,将基于卷积的BEV编码器应用到统一的BEV特征中,以缓解不同特征之间的局部偏准;最后,添加一些特定任务头支持不同的3D场景理解工作。主要网络结构如下:

2.2 具体实现
本文采用BEV作为融合的统一表征,该视图对几乎所有感知任务都很友好,因为输出空间也在BEV。更重要的是,到BEV的转换同时保持了几何结构(来自激光雷达特征)和语义密度(来自摄像头特征)。一方面,LiDAR到BEV投影将稀疏LiDAR特征沿高度维度(height dimension)展平,因此不会产生几何失真。另一方面,摄像头到BEV投影将每个摄像头特征像素投射回3D空间的一条光线中(ray casting),这可以生成密集的BEV特征图,并保留了摄像头的全部语义信息。
摄像头到BEV的变换非常重要,因为与每个摄像头图像特征像素关联的深度(depth)本质上是不明确的。根据LSS,明确预测每个像素的离散深度分布。然后,沿着摄像头光线将每个特征像素分散成D个离散点,并根据相应的深度概率重缩放(rescale)相关特征。这将生成大小为N*H*W*D的摄像头特征点云,其中N是摄像头数,(H,W)是摄像头特征图大小。此类3D特征点云沿x、y轴量化,步长为r(例如,0.4m)。用BEV池化操作来聚合每个r×r BEV网格内的所有特征,并沿z轴展平特征。
虽然简单,但BEV池化的效率和速度惊人地低,在RTX 3090 GPU上需要500毫秒以上(而模型的其余部分计算只需要100毫秒左右)。这是因为摄像头特征点云非常大,即典型的工作负载,每帧可能生成约200万个点,比激光雷达特征点云密度高两个数量级。为了消除这一效率瓶颈,建议通过预计算和间歇降低来优化BEV池化进程。
如图所示:摄像机到BEV变换(a)是在统一的BEV空间进行传感器融合的关键步骤。然而,现有的实现速度非常慢,单个场景可能需要2秒的时间。文章提出了有效的BEV池化方法(b),通过预计算使间歇降低和加快网格关联,视图转换模块(c,d)的执行速度提高了40倍。
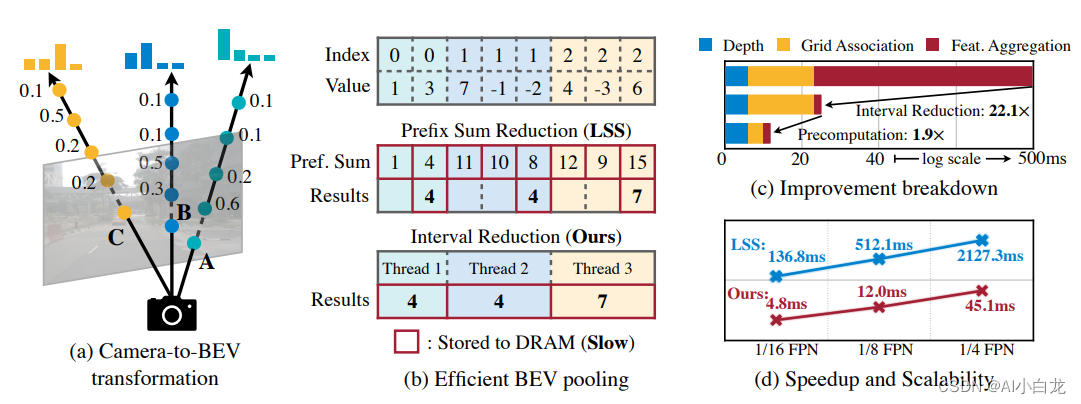
- 预计算
BEV池化的第一步是将摄像头特征点云的每个点与BEV网格相关联。与激光雷达点云不同,摄像头特征点云的坐标是固定的(只要摄像头内参外参保持不变,通常在适当标定后)。基于此,预计算每个点的3D坐标和BEV网格索引。还有,根据网格索引对所有点进行排序,并记录每个点排名。在推理过程中,只需要根据预计算的排序对所有特征点重排序。这种缓存机制可以将网格关联的延迟从17ms减少到4ms。
- 间歇降低
网格关联后,同一BEV网格的所有点将在张量表征中连续。BEV池化的下一步是通过一些对称函数(例如,平均值、最大值和求和)聚合每个BEV网格内的特征。现有的实现方法首先计算所有点的前缀和(prefix sum),然后减去索引发生变化的边界值。然而,前缀和操作,需要在GPU进行树缩减(tree reduction),并生成许多未使用的部分和(因为只需要边界值),这两种操作都是低效的。为了加速特征聚合,文章里实现一个专门的GPU内核,直接在BEV网格并行化:为每个网格分配一个GPU线程,该线程计算其间歇和(interval sum)并将结果写回。该内核消除输出之间的依赖关系(因此不需要多级树缩减),并避免将部分和写入DRAM,从而将特征聚合的延迟从500ms减少到2ms。
- 小结
通过优化的BEV池化,摄像头到BEV的转换速度提高了40倍:延迟从500ms减少到12ms(仅为模型端到端运行时间的10%),并且可以在不同的分特征辨率之间很好地扩展。在共享BEV表征中,这是统一多模态感知特征的关键促成因素。两项并行化工作也发现了纯摄像头3D检测的这一效率瓶颈。假设均匀深度分布,或截断每个BEV网格内的点,可以近似视图transformer计算。相比之下,该技术在没有任何近似的情况下是精确的,但仍然更快。
参考:BEVFusion: 基于统一BEV表征的多任务多传感器融合 - 知乎