前言
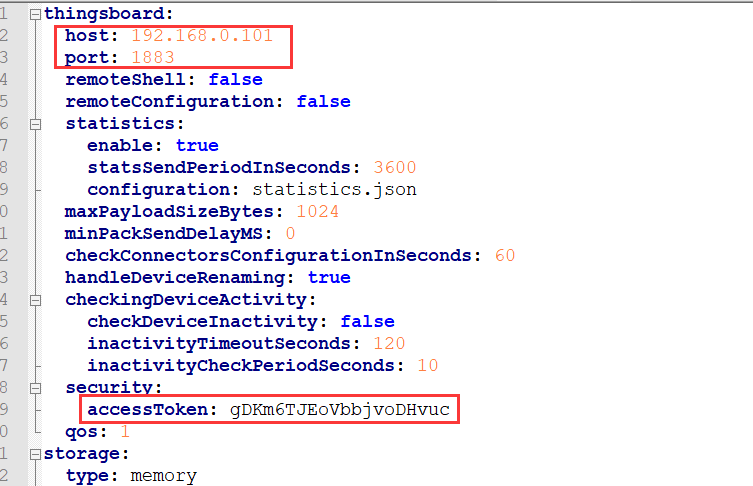
一、视觉-语言模型是什么?
二、视觉-语言模型可以用来做什么?
三、视觉-语言 预训练模型
3.1、模型架构
3.2、训练目标
3.2.1、图像-文本匹配损失(ITM)
3.2.2、掩码语言建模损失(MLM)
3.2.3、掩码视觉建模损失(MVM)
3.3、SOTA模型
四、视觉到语言的数字化转型——智能文档分析
4.1、智能文档分析的技术难题
4.2、智能文档图像处理新应用
4.2.1、手写板发光擦除
4.2.2、文档图像篡改检测
4.3、智能文档图像处理利器
最后
前言
最近,中国图像图形大会(CCIG 2023)在苏州成功结束。本次大会以“图像图形·向未来”为主题,由中国科学技术协会指导,中国图像图形学学会主办,苏州科技大学承办。论坛邀请了5位学术界🎓和产业界💼的专家做特邀报告,共同交流文档图像分析与处理的前沿学术进展、在典型行业的规模化应用情况,并探讨未来技术及产业发展趋势,本次大会,来自北京大学的邹月娴教授和合合信息的丁凯博士带来的报告令人印象深刻。
一、视觉-语言模型是什么?
视觉作为一种主要的感知模态,使我们能够感知和理解周围的世界,促使物体识别、运动感知和美景欣赏等能力的形成,是使我们能够与外部现实建立联系的一扇关键的窗口。
而语言则作为一种认知工具,是认知的媒介,用于思考、交流和表达。通过语言,我们使用抽象符号来表达概念、情感和思想,帮助我们组织和理解知识、推理和解决问题以及与他人进行沟通和合作。
在多模态领域中,视觉提供图像和视频的视觉信息,语言则提供文字和语音的语义信息,通过多模态输入的融合,模型能够从视觉与语言的相互关系中汲取灵感。通过结合视觉和语言信息,更全面地感知和认知世界,更好地理解和表达复杂的场景和任务。
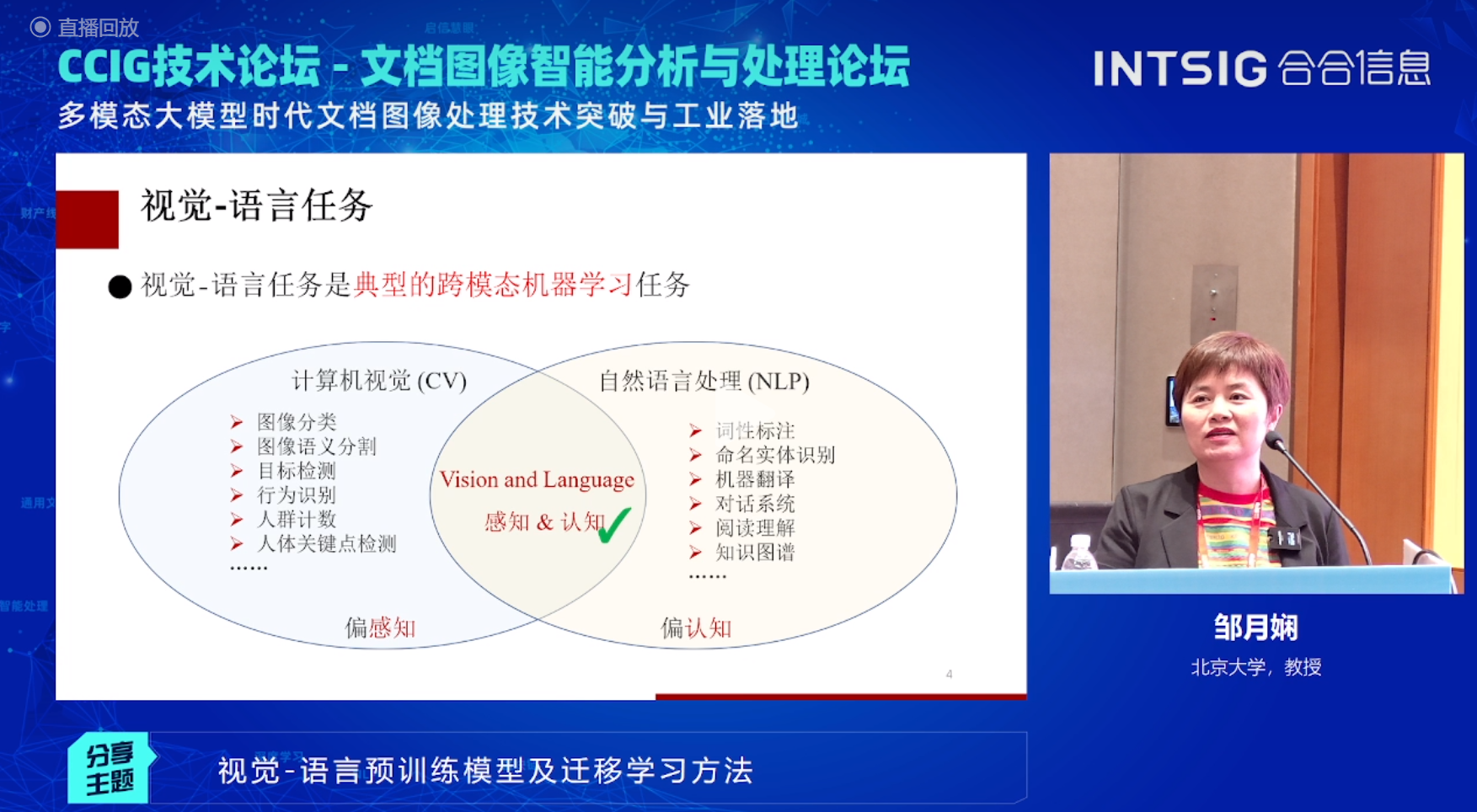
视觉-语言模型是一种结合了图像和文本信息的典型跨模态模型,其主要目的是学习图像和文本之间的语义关系。它可以用于多种视觉-语言任务,例如图像描述生成、图像问答、视觉推理等。
二、视觉-语言模型可以用来做什么?
视觉-语言模型可以帮助计算机更好地理解图像和文本之间的语义关系,从而实现更加智能化的视觉-语言交互,其中包括但不限于以下几个方面:图像描述生成、视频理解和摘要生成、视觉问答、跨模态检索、视觉语音合成。

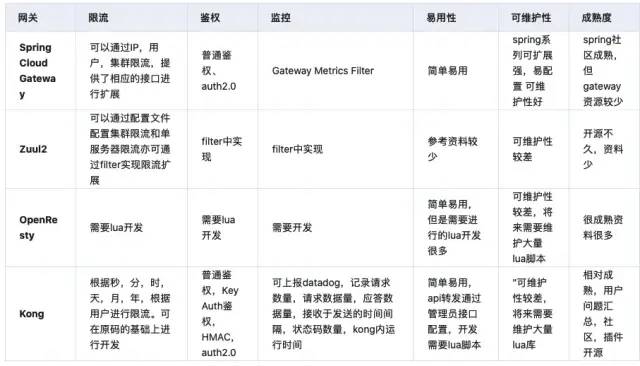
这里我列了一张表格,总结了视觉-语言中部分任务、数据集、评价指标及其主流模型:
类型 任务 输入 输出 数据集 评价指标 部分主流模型 生成 图像字幕 图像 句子 COCO 、Flickr30K 、Flickr8K 、CC3M 、CC12M 、SBU Captions BLEU、METEOR、ROUGE 、CIDEr ,SPICE m-RNN、BUTD、AoANet、AutoCaption、ORT、CPTR 生成 文本生成图像 文本 图像 COCO、CUB Inception Score、FID、R StackGAN、AttnGAN、DF-GAN 理解 视觉问答 图像+文本 短语 VQA、VQAv2、DAQUAR、COCO QA VQA Accuracy SAN、BUTD、MCB、MUTAN 理解 视觉推理 图像+文本+图形 文本 GQA、CLEVER、NLVR、VCR Accuracy NMN、N2NMN、PG+EE、TbD-net、NS-VQA、XNM-Det 检索 图像-文本检索、文本-图像检索 文本/图像 图像/文本 COCO、Flickr30k、Flickr8K Recall@K, Median r MNLM、m-CNN、m-RNN、SCAN、Deep Fragment
三、视觉-语言预训练模型
视觉-语言模型的训练通常分为两个阶段:预训练和微调。预训练阶段是在无监督的情况下,通过最大化某种预训练目标函数来学习模型参数。微调阶段是在有监督任务中对模型进行微调,以提高模型的表现能力。视觉-语言预训练模型是视觉-语言模型的一种预训练形式,旨在通过联合训练图像和文本数据,在无监督的情况下,通过最大化某种预训练目标函数来学习模型参数从而使计算机能够理解和表达视觉和语言之间的关联。这些模型通常使用大规模的视觉和语言数据集进行预训练,以学习图像和文本之间的对应关系和语义表示。
3.1、模型架构
视觉-语言预训练模型的典型架构是使用Transformer或类似的注意力机制模型。它由两个主要组件组成:视觉编码器和语言编码器。
- 视觉编码器负责处理图像数据,并将其转换为高维的视觉特征表示。这一过程通常通过卷积神经网络(CNN)来实现,将图像输入模型,并提取出图像的特征向量。这些特征向量捕捉了图像中的语义和结构信息。
- 语言编码器则用于处理文本数据,将文本转化为语义向量表示。常见的方法是使用循环神经网络(RNN)或Transformer模型,将文本序列输入模型,并将其编码为具有语义信息的固定长度向量。
从多模态融合的角度来看,视觉-语言预训练模型主要分为两种架构:单信息流体系结构和多信息流体系结构。
单流架构指将文本和视觉特征连接在一起,然后馈送到单个Transformer块中,如下图所示,单流结构利用合并的注意力来融合多模态输入。
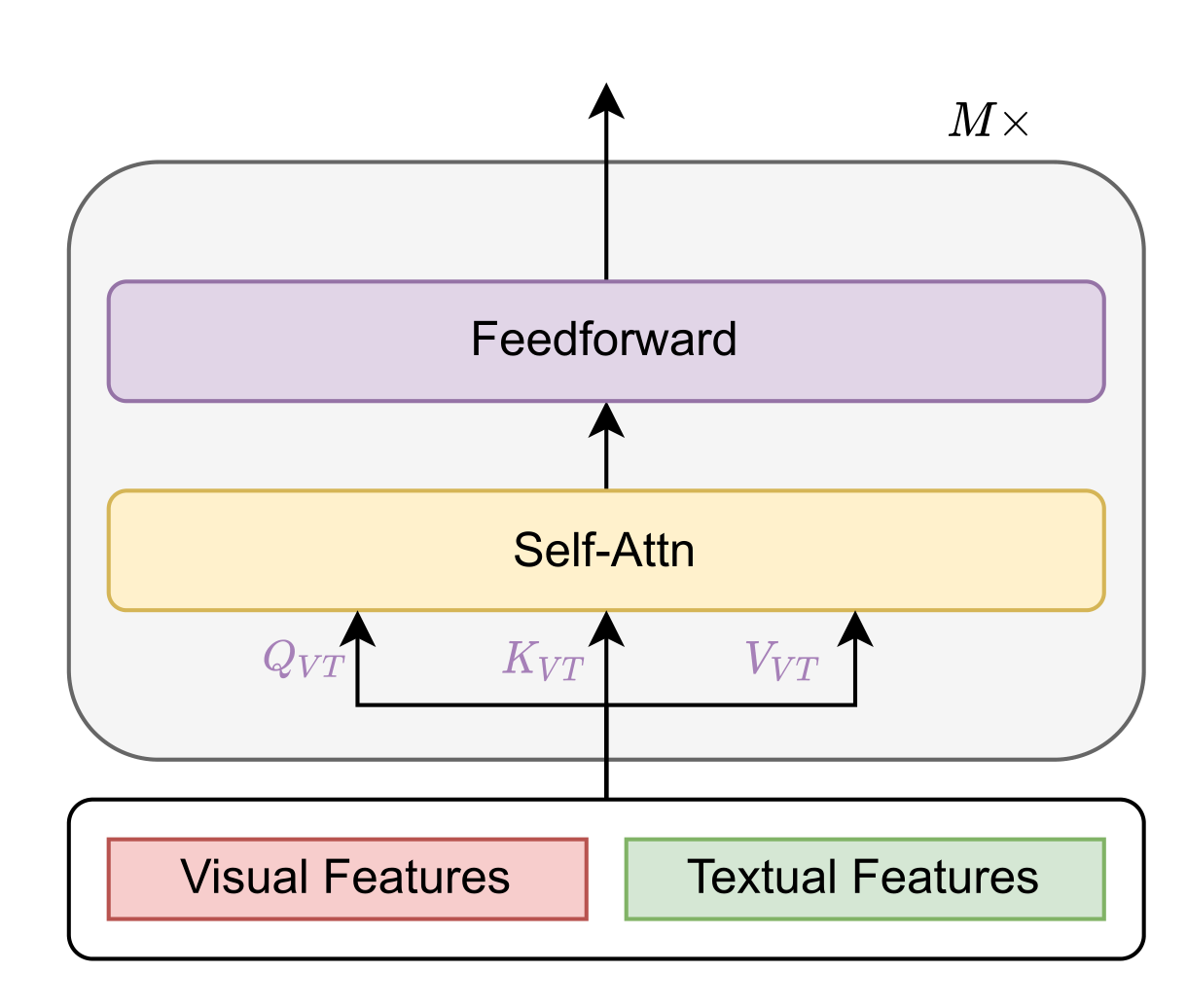
多信息流架构是指文本和视觉特征不连接在一起,而是单独发送到两个不同的Transformer块,如下图所示。这两个Transformer块不共享参数,而为了获得更高的性能,一般使用交叉注意来实现跨模态交互。
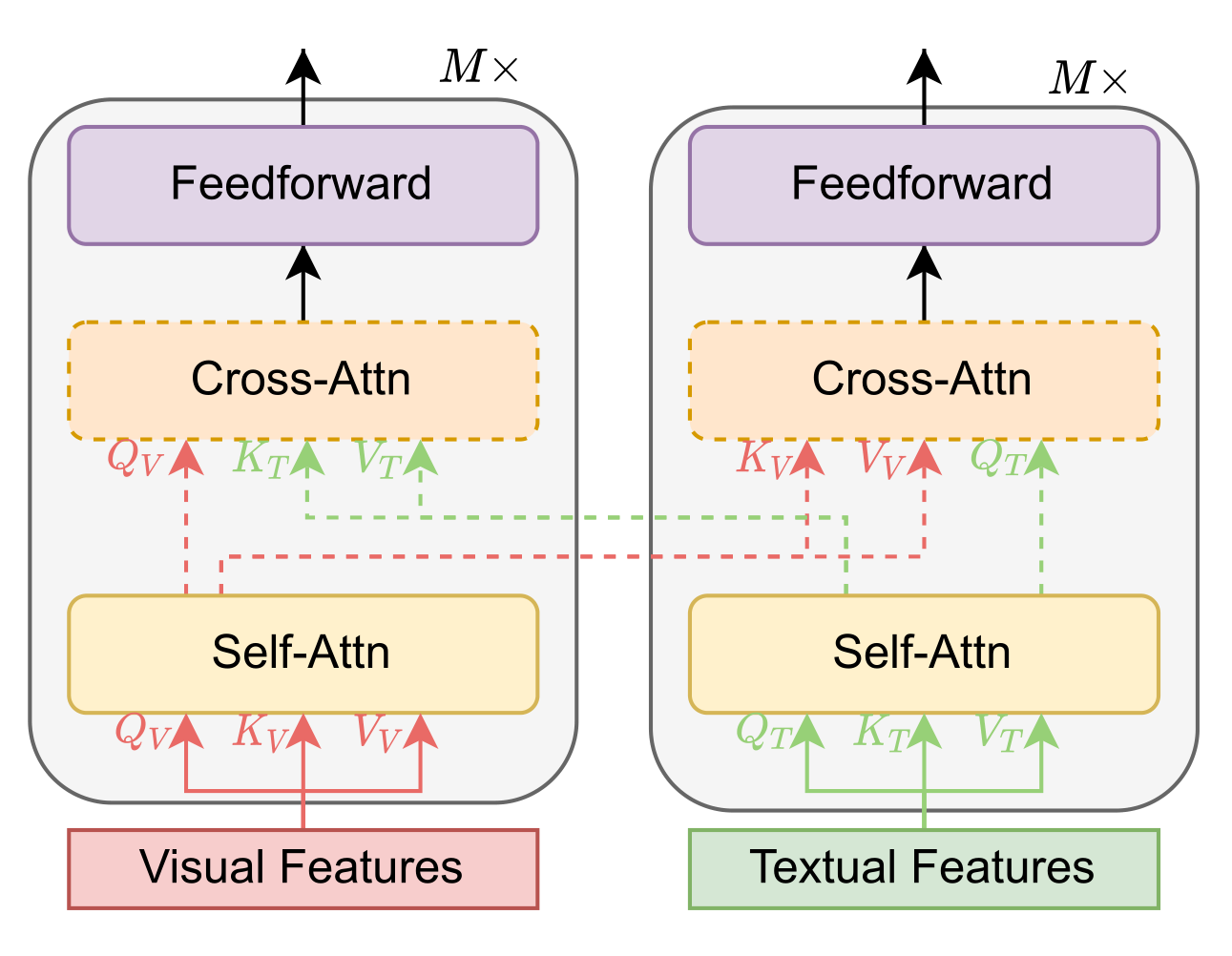
3.2、训练目标
为了学习视觉和语言的联合表示,视觉语言预训练方法通常使用几个自监督学习损失来在大数据集上预训练模型,预训练方法主要有三种,分别是图像文本匹配(Image Text Matching)、掩模语言建模(Masked Language Modeling)和掩模视觉建模(Masked Vision Modeling)。
3.2.1、图像-文本匹配损失(ITM)
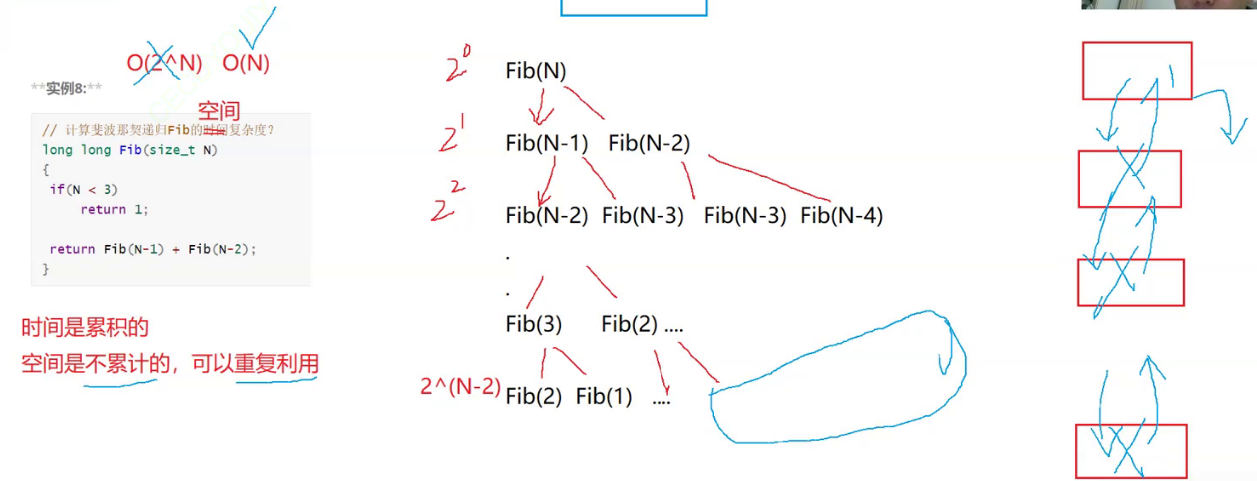
图像-文本匹配(Image-Text Matching,简称ITM)是指通过计算机视觉和自然语言处理技术,将图像和文本进行匹配和对齐的任务。其目标是衡量图像和文本之间的相似性或关联程度。ITM的目标是通过建立一个模型,能够将每个图像与其相关的文本进行匹配,以便衡量它们之间的相似性或相关性,其可以表述为一个二元分类任务:
其中,W表示文本符号序列,而V表示视觉内容,y=0时表示图像和文本匹配,y=1时表示图像和文本不匹配。
3.2.2、掩码语言建模损失(MLM)
掩码语言建模(Masked Language Modeling,MLM)损失是用于训练基于掩码语言建模任务的预训练模型的损失函数,被用来鼓励模型学习语言标记和视觉内容之间的隐式关系,其从已知的语言标记和视觉内容中重构被屏蔽的语言标记,使模型能够学习到单词的上下文表示和语义关联,可以被表述为:
其中,W\i表示没有第i个单词的句子,公式通过最大似然估计(MLE)计算掩码语言建模任务的损失,具体而言,其根据上下文W\i和可见特征V的信息,预测位置i的掩码单词wi的概率分布。然后,通过计算预测概率与真实值的交叉熵(取负号),得到对应位置的损失值。对整个数据集中的所有位置进行求和或平均,即可得到最终的MLM损失。
3.2.3、掩码视觉建模损失(MVM)
受MLM的启发,掩码视觉建模损失(Masked Vision Modeling,MVM)通过重构被屏蔽的视觉内容来学习语境化的视觉表示,其用于对图像中的掩模区域进行建模和预测,通过对图像中的一部分区域进行遮挡(或掩模),然后根据已知的图像信息预测被掩盖区域的内容。与具有词汇字典的语言模型类似,可视化建模与可视化字典(Visual Modeling with Visual Dictionary,MVMVD)需要一个视觉词汇字典(VD),而MVMVD的目标是重建被屏蔽的VD令牌,其可以被表述为:
其中,f()表示从图像网络到VD中可视标记的映射,j表示VD中掩码标记的索引。
3.3、SOTA模型
VisualBERT是第一个图像-文本预训练模型,它使用Faster R-CNN提取视觉特征,将提取出的视觉特征与文本嵌入连接起来,馈送到BERT初始化的单个转换器中。Unicoder-vl、UNITER、ImageBERT、VL-BERT等许多视觉-语言模型也采用了类似的特征提取和架构。
最近,VDBERT通过 迁移学习 对大规模图像-文本对进行预训练,对视觉和语言中的深层视觉-语言对齐进行建模。VLMO则利用图像的补丁嵌入和文本的单词嵌入,并将连接的嵌入与模态专家一起馈送到单个Transformer中,实现了令人印象深刻的性能。METER使用单模态预训练模型并提出了双流架构模型来处理多模型融合,从而实现了很好的性能。
四、视觉到语言的数字化转型——智能文档分析
随着数字化时代的到来,越来越多的企业和组织开始将纸质文档转化为数字文档,以提高工作效率和准确性。然而,随着文档数量的不断增加,如何高效地处理和分析这些文档成为了一个亟待解决的问题,丁凯博士为我们带来了智能文档处理技术的相关内容。
4.1、智能文档分析的技术难题

传统的文档处理方式往往需要大量的人力和时间,效率低下且容易出错。而智能文档分析是指利用人工智能技术对文档进行自动化处理和分析,例如文本分类、文本摘要、实体识别等。智能文档处理可以帮助人们更加高效地处理和管理文档,提高工作效率和准确性。
文档图像智能分析与处理是一个重要且极具挑战性的研究问题:
- 文档的场景和板式多样。不同的文档可能采用不同的排版方式和格式,这给文档的处理和分析带来了很大的挑战。
- 采集设备不确定,文档的来源和采集方式也会影响文档的质量和可处理性。
- 用户需求多样化,不同的用户可能对文档的处理和分析有不同的需求和要求。这就需要智能文档处理系统具备一定的灵活性和可定制性,以满足不同用户的需求。
- 文档图像质量退化严重。由于文档的保存时间和方式不同,文档图像可能会出现模糊、失真、噪声等问题,这会影响文档的识别和分析效果。
- 文字检测及版面分析。特别是对于复杂的文档,如手写文档、印刷体和手写体混合的文档等,文字检测和版面分析的难度更大。
- 非限定条件文字识别率低。由于文档中的文字可能出现各种字体、大小、颜色和方向,这会影响文字识别的准确率和效率。
- 结构化智能理解能力差。结构化智能理解即如何将文档中的信息进行结构化处理和分析,以便更好地理解和利用文档中的信息。因此,智能文档处理系统需要具备一定的结构化智能理解能力,以实现更加智能化的文档处理和分析。
4.2、智能文档图像处理新应用
作为一家专注于人工智能技术研发和应用的企业,合合信息一直致力于解决以上智能文档图像处理面临的各种技术难题,专注于智能文字识别、图像处理、自然语言处理(NLP)、知识图谱、大数据挖掘等技术。基于自主研发的领先的智能文字识别及商业大数据核心技术,还为全球C端用户和多元行业B端客户提供身份证、票据数字化、PS篡改检测等智能图像处理产品及服务。

4.2.1、手写板发光擦除
在拍摄黑板上的文字时,由于光线的反射和折射,会产生反光干扰,影响手写内容的识别和显示。合合信息在手写板反光抑制技术中使用了背景提取模块和信息融合模块。
背景提取模块会对手写板的背景进行提取,并将手写内容与背景进行分离。基于深度学习的分割方法是最常用的方法之一,其通过使用卷积神经网络等深度学习技术,自动学习图像中的特征,实现高效准确的图像分割并将图像分为前景和背景,常见的方法有基于U-Net的深度学习背景提取方法和基于Mask R-CNN的深度学习背景提取方法。信息融合模块会将手写内容与背景进行融合,并将结果显示在手写板上。通过这种方式,可以有效减少反光干扰,提高手写板的使用效果,为用户提供更好的使用体验。

4.2.2、文档图像篡改检测
在数字化时代,文档图像的篡改已经成为了一种常见的问题,文档图像篡改检测技术可以有效地保护文档图像的完整性和真实性。传统基于文件标记篡改检测方法通过在文件中添加特殊的标记,用于检测文件是否被篡改。当文件被篡改时,标记的信息也会被改变,从而可以检测出文件的篡改。但该方法很容易受到篡改攻击的影响,一些高级的篡改攻击可以绕过该方法的检测,一些第三方软件已经可以抹除文档的Exif信息,已经存在很大的安全隐患。

基于此问题,合合信息提出了一种图像篡改检测系统,其主要包括两个方面:特征提取和篡改检测。特征提取是指从文档图像中提取出包括纹理、颜色、形状等一系列特征。篡改检测是指通过比较文档图像的特征,检测文档图像是否被篡改。
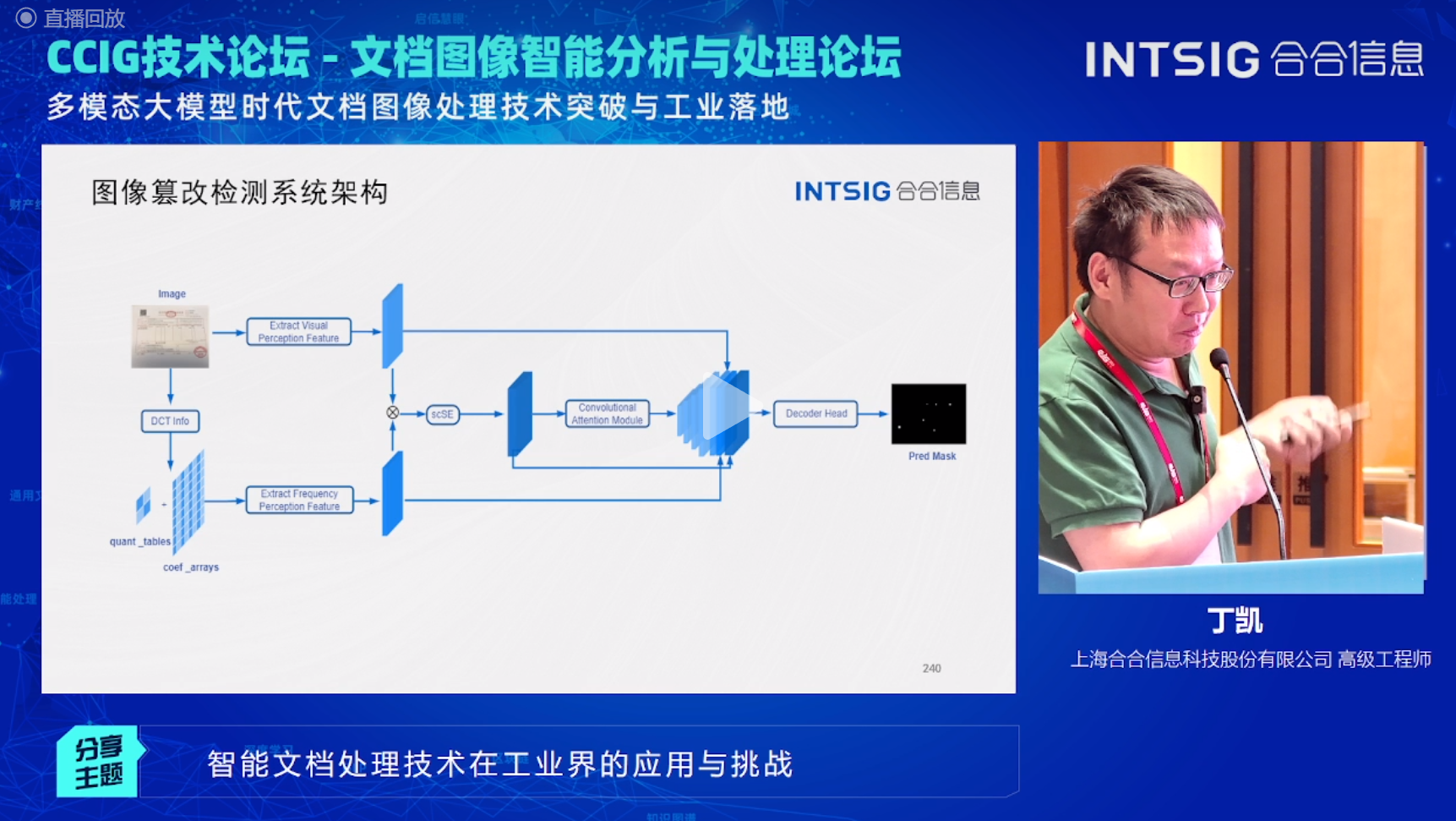
4.3、智能文档图像处理利器
合合信息 C 端产品方面的扫描全能王(智能扫描及文字识别 APP)、名片全能王(智能名片及人脉管理 APP)、启信宝(企业商业信息查询 APP)这些耳熟能详的产品覆盖了全球百余个国家和地区的亿级用户;

智能文字识别服务平台 TextIn,基于合合信息自主研发的领先的智能文字识别及商业大数据核心技术,也为面向企业客户提供以智能文字识别、商业大数据为核心的服务,形成了包括基础技术服务、标准化服务和场景化解决方案的业务矩阵,满足客户降本增效、风险管理、智能营销等多元需求。
合合信息专注于智能文字识别、图像处理、自然语言处理(NLP)、知识图谱、大数据挖掘等技术,很多产品已在银行、保险、制造业等多个行业得到了应用。
最后
本次大会,来自知名高校和企业的研究者们,围绕文档图像处理的前沿技术展开了“头脑风暴”,在文档图像处理领域的未来进阶方向上为我们带来了很多有意思的观点分析。
我认为在大模型时代,视觉-语言跨模态模型的研究已经成为一个重要趋势,它可以实现对图像和文本信息的联合建模和深度理解,从而提高文档图像处理的准确性和效率。在文档图像处理方面,其可以对图像和文本信息深度理解和分析,从而提高处理的准确性和效率。随着人工智能技术的不断发展和应用,我相信视觉-语言跨模态模型和文档图像处理技术将发挥越来越重要的作用。