目录
- 1.了解Java集合嘛,详细说一下Map?
- 2.为什么HashTable线程安全却不常用?
- 3.HashMap不是线程安全,多线程下会出现什么问题?
- 4.什么办法能解决HashMap线程不安全的问题呢
- 5.ConcurrentHashmap是怎么实现的?
- 6.为什么要废弃分段锁?
- 7.HashMap的底层实现原理,为什么要使用红黑树
- 8.为什么HashMap的容量是2的倍数呢?
- 9.为什么HashMap链表转红黑树的阈值为8呢?
- 10.Redis怎么实现短信验证登陆
- 11.Redis缓存击穿、缓存雪崩、缓存穿透
- 12.线程的多种实现方式?
- 13.线程池的基本概念
- 14.有哪几种常见的线程池
- 15.线程池的参数
- 16.线程池提交execute和submit有什么区别
- 17.线程池异常怎么处理知道吗?
- 18.SQL:找出库存量最大的类别的库存信息,不用MAX还能用什么
- 19.Leetcode70 爬楼梯
1.了解Java集合嘛,详细说一下Map?
Java中Map是一个接口,它不继承任何其他的接口,可以说它是java中所有Map的顶级父接口。
- Map存储是以k-v键值对的方式进行存储的,是双列的
- Map中的key具有唯一性,不可重复
- 每个key对应的value值是唯一的
2.为什么HashTable线程安全却不常用?
1:性能问题:Hashtable是一个同步的容器,它的所有公共方法都是同步的,这会导致在多线程环境下性能低下,因为同步需要大量的系统开销。
2:限制:Hashtable的键和值都不能为null,这在某些场景下可能不太方便。
3.HashMap不是线程安全,多线程下会出现什么问题?
JDK1.8 中,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
4.什么办法能解决HashMap线程不安全的问题呢
1、使用Collections.synchronizedMap(new HashMap<>());
2、使用 ConcurrentHashMap
5.ConcurrentHashmap是怎么实现的?
ConcurrentHashMap
JDK1.7ConcurrentHashMap底层实现原理:
数据结构:Segment(大数组) + HashEntry(小数组) + 链表,每个 Segment 对应一把锁,如果多个线程访问不同的 Segment,则不会冲突
JDK1.8ConcurrentHashMap底层实现原理:
数据结构:Node 数组 + 链表或红黑树,数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突。首次生成头节点时如果发生竞争,利用 cas 而非 syncronized,进一步提升性能
ConcurrentHashMap的整体架构
数据结构:Node 数组 + 链表或红黑树,数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突。首次生成头节点时如果发生竞争,利用 cas 而非 syncronized,进一步提升性能
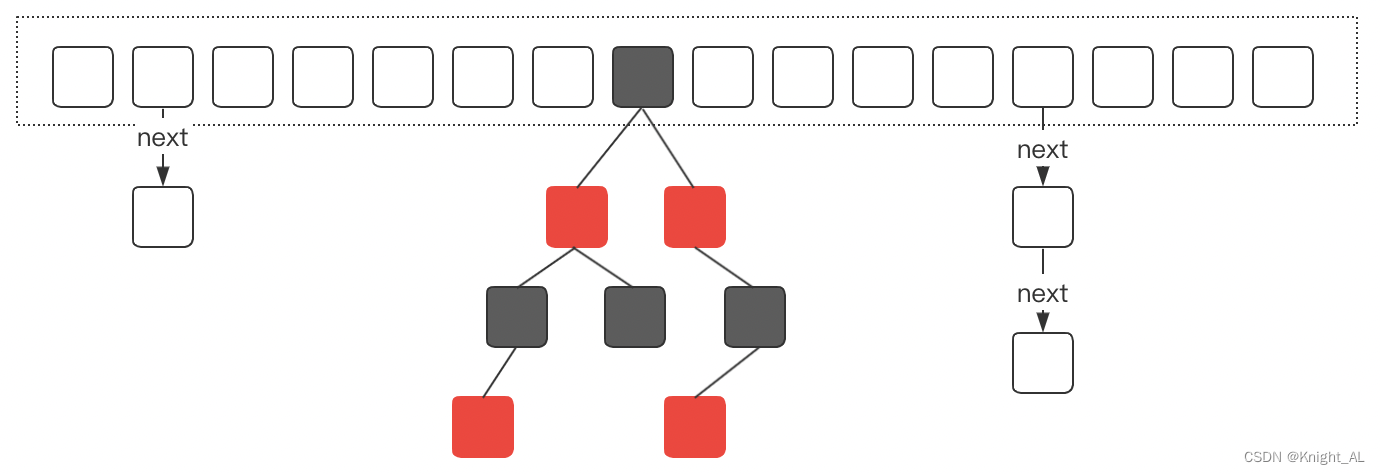
这个是ConcurrentHashMap在JDK1.8中的存储结构,它是由数组、单向链表、红黑树组成。
当我们初始化一个ConcurrentHashMap实例时,默认会初始化一个长度为16的数组。由于ConcurrentHashMap它的核心仍然是hash表,所以必然会存在hash冲突问题。
ConcurrentHashMap采用链式寻址法来解决hash冲突。
当hash冲突比较多的时候,会造成链表长度较长,这种情况会使得ConcurrentHashMap中数据元素的查询复杂度变成O(n)。因此在JDK1.8中,引入了红黑树的机制。
当数组长度大于64并且链表长度大于等于8的时候,单项链表就会转换为红黑树。
另外,随着ConcurrentHashMap的动态扩容,一旦链表长度小于8,红黑树会退化成单向链表。
ConcurrentHashMap的基本功能
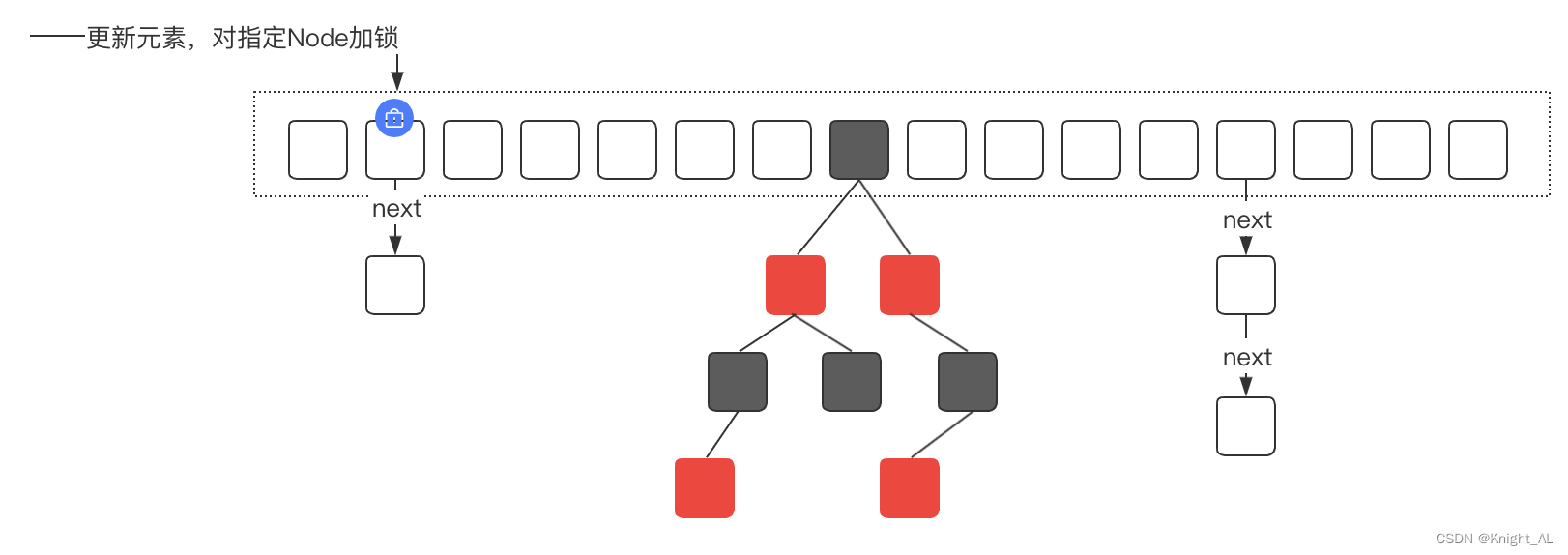
ConcurrentHashMap本质上是一个HashMap,因此功能和HashMap一样,但是ConcurrentHashMap在HashMap的基础上,提供了并发安全的实现。
并发安全的主要实现是通过对指定的Node节点加锁,来保证数据更新的安全性。
ConcurrentHashMap在性能方面做的优化
- 在JDK1.8中,ConcurrentHashMap锁的粒度是数组中的某一个节点,而在JDK1.7,锁定的是Segment,锁的范围要更大,因此性能上会更低。
- 引入红黑树,降低了数据查询的时间复杂度,红黑树的时间复杂度是O(logn)。
- 当数组长度不够时,ConcurrentHashMap需要对数组进行扩容,在扩容的实现上,ConcurrentHashMap引入了多线程并发扩容的机制,简单来说就是多个线程对原始数组进行分片后,每个线程负责一个分片的数据迁移,从而提升了扩容过程中数据迁移的效率。
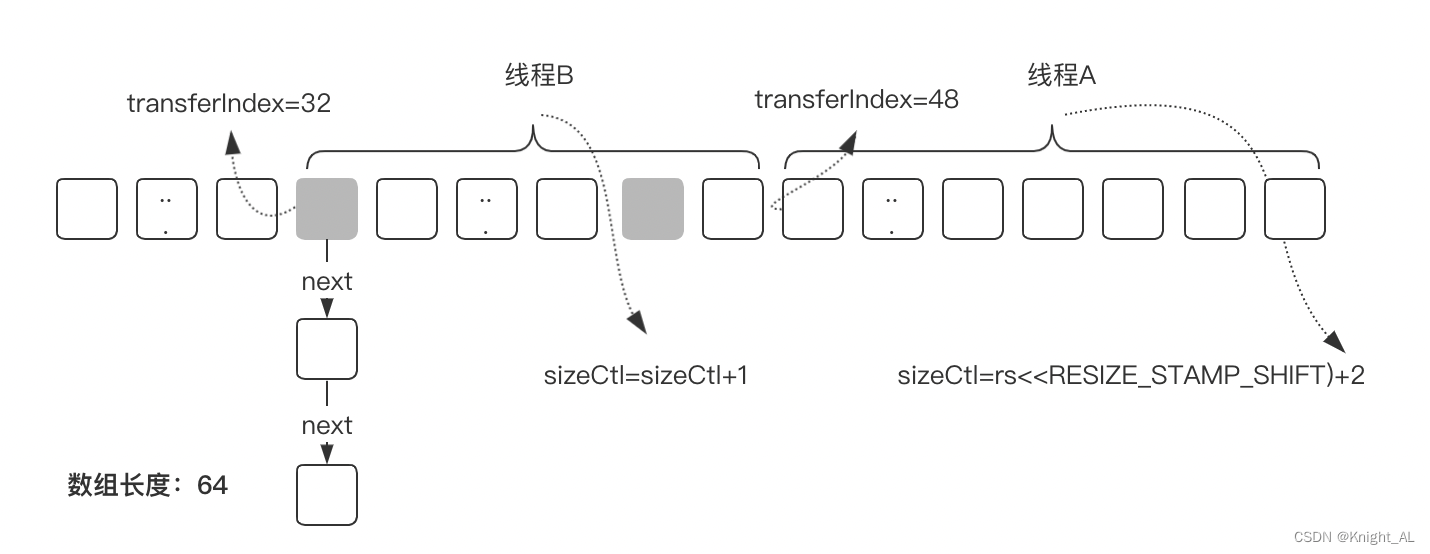
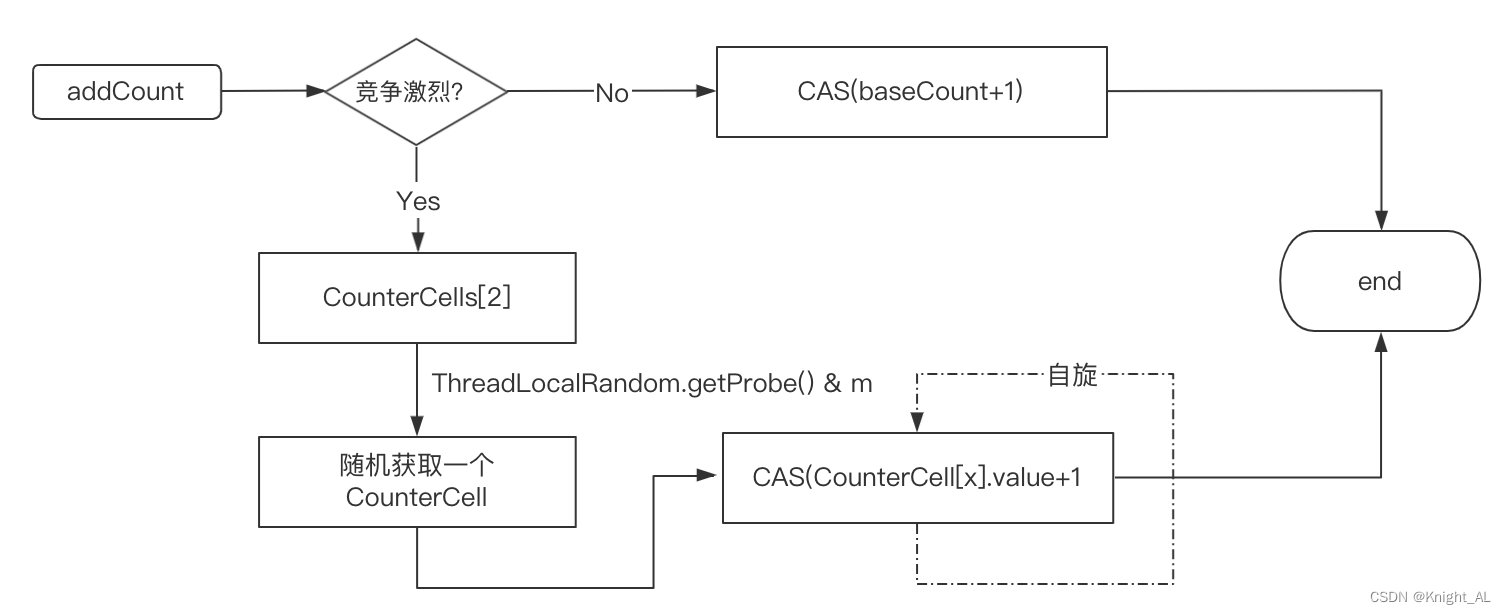
- ConcurrentHashMap中有一个size()方法来获取总的元素个数,而在多线程并发场景中,在保证原子性的前提下来实现元素个数的累加,性能是非常低的。ConcurrentHashMap在这个方面的优化主要体现在两个点:
- 当线程竞争不激烈时,直接采用CAS来实现元素个数的原子递增。
如果线程竞争激烈,使用一个数组来维护元素个数,如果要增加总的元素个数,则直接从数组中随机选择一个,再通过CAS实现原子递增。它的核心思想是引入了数组来实现对并发更新的负载。
为什么不用ReentrantLock而用synchronized ?
减少内存开销:如果使用ReentrantLock则需要节点继承AQS来获得同步支持,增加内存开销,而1.8中只有头节点需要进行同步。
内部优化:synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。
6.为什么要废弃分段锁?
- 加入多个分段锁浪费内存空间。(假设一个数据结构被划分为n个段,那么分段锁需要维护n个独立的锁对象。如果每个锁对象占用的内存空间为s,则分段锁的总内存开销为n*s。)
- 生产环境中, map 在放入时竞争同一个锁的概率非常小,分段锁反而会造成更新等操作的长时间等待。
- JDK1.7concurrentHashMap需要计算两次index值第一次Segment对象 第二次Segment中的HashEntry
JDK1.8concurrentHashMap只需要计算一次index值
7.HashMap的底层实现原理,为什么要使用红黑树
在 JDK 1.7 中,HashMap 使用的是数组 + 链表实现。
在 JDK 1.8 中使用的是数组 + 链表或红黑树实现的。
put实现原理
(1)先判断当前Node[]数组是不是为空,为空就新建,不为空就对hash值与容量-1做与运算得到数组下标
(2)然后会判断当前数组位置有没有元素,没有的话就把值插到当前位置,有的话就说明遇到了哈希碰撞
(3)遇到哈希碰撞后,如果Hash值相同且equals内容也相同,直接覆盖,就会看下当前链表是不是以红黑树的方式存储,是的话,就会遍历红黑树,看有没有相同key的元素,有就覆盖,没有就执行红黑树插入
(4)如果是普通链表,则按普通链表的方式遍历链表的元素,判断p.next = null的情况下,直接存放追加在next后面,然后我们要检查一下如果链表长度大于8且数组容量>=64链表转换成红黑树,否则查找到链表中是否存在该key,如果存在直接修改value值,如果没有继续遍历
(5)如果++size > threshold(阈值)就扩容
为什么要使用红黑树
每次遍历一个链表,平均查找的时间复杂度是 O(n),n 是链表的长度。红黑树有和链表不一样的查找性能,由于红黑树有自平衡的特点,可以防止不平衡情况的发生,所以可以始终将查找的时间复杂度控制在 O(logn)。最初链表还不是很长,所以可能 O(n) 和 O(log(n)) 的区别不大,但是如果链表越来越长,那么这种区别便会有所体现。所以为了提升查找性能,需要把链表转化为红黑树的形式。
为什么不一开始就用红黑树,反而要经历一个转换的过程呢?
JDK 的源码注释中已经对这个问题作了解释:

这段话的意思是:因为树节点(TreeNodes)所占的空间是普通节点Node的两倍,所以我们只有在桶中包含足够的节点时才使用树节点(请参阅TREEIFY_THRESHOLD)(只有在同一个哈希桶中的节点数量大于等于TREEIFY_THRESHOLD时,才会将该桶中原来的链式存储的节点转化为红黑树的树节点)。并且当桶中的节点数过少时 (由于移除或调整),树节点又会被转换回普通节点(当桶中的节点数量过少时,原来的红黑树树节点又会转化为链式存储的普通节点),以便节省空间。
8.为什么HashMap的容量是2的倍数呢?
当我们向 HashMap 中添加一个元素时,HashMap 会根据元素的哈希值计算出该元素在数组中的位置,计算公式为:(n - 1) & hash,其中 n 表示数组的长度,hash 表示元素的哈希值。由于 n 必须是 2 的幂次方,因此 n - 1 的二进制表示中所有位都是 1,这样就可以保证计算出的位置在数组的有效范围内。
9.为什么HashMap链表转红黑树的阈值为8呢?
通过查看源码可以发现,默认是链表长度达到 8 就转成红黑树,而当长度降到 6 就转换回去,这体现了时间和空间平衡的思想,最开始使用链表的时候,空间占用是比较少的,而且由于链表短,所以查询时间也没有太大的问题。可是当链表越来越长,需要用红黑树的形式来保证查询的效率。对于何时应该从链表转化为红黑树,需要确定一个阈值,这个阈值默认为 8,并且在源码中也对选择 8 这个数字做了说明,原文如下:

如果 hashCode 分布良好,也就是 hash 计算的结果离散好的话,那么红黑树这种形式是很少会被用到的,因为各个值都均匀分布,很少出现链表很长的情况。在理想情况下,桶(bins)中的节点数概率(链表长度)符合泊松分布,当桶中节点数(链表长度)为 8 的时候,概率仅为 0.00000006。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从链表向红黑树的转换。
10.Redis怎么实现短信验证登陆
Redis可以通过存储短信验证码来实现短信验证登录。具体实现步骤如下:
-
用户输入手机号码并点击发送验证码按钮,前端向后端发送请求,后端生成一个随机的验证码,并将其存储到Redis中,同时设置过期时间为一定的时间(例如5分钟)。
-
后端将验证码发送到用户的手机上。
-
用户输入收到的验证码并点击登录按钮,前端向后端发送请求,后端从Redis中获取该手机号码对应的验证码,与用户输入的验证码进行比对,如果一致,则认为验证通过,允许用户登录。
-
如果验证码过期或者用户输入的验证码不正确,则认为验证失败,不允许用户登录。
需要注意的是,为了保证安全性,验证码应该是一次性的,即每个验证码只能使用一次。可以在用户登录成功后,将Redis中存储的验证码删除,避免验证码被重复使用。
另外,为了防止恶意攻击,可以对同一个手机号码发送验证码的频率进行限制,例如每分钟只允许发送一次验证码。可以通过Redis的计数器来实现这个功能。
11.Redis缓存击穿、缓存雪崩、缓存穿透
缓存击穿
大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去
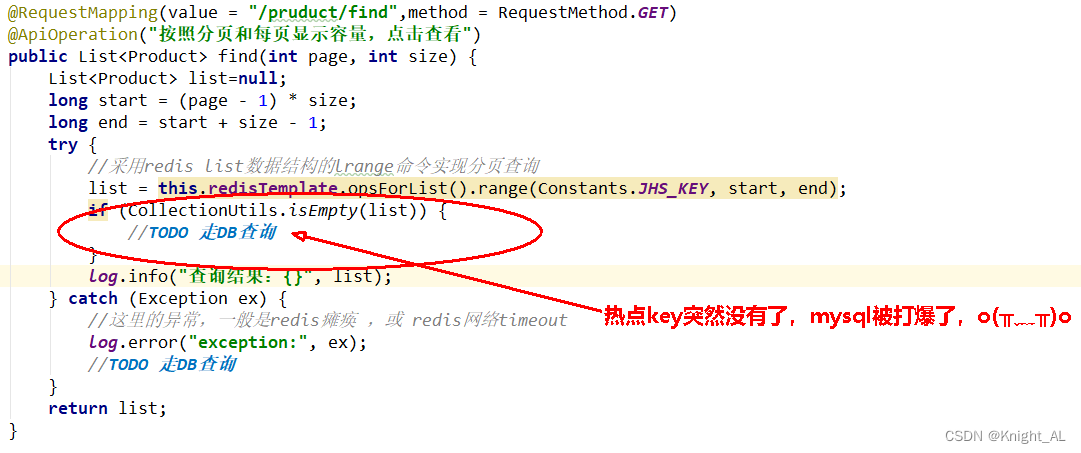
简单说就是热点key突然失效了,暴打mysql

方案1:对于访问频繁的热点key,干脆就不设置过期时间
互斥独占锁防止击穿
方案2:互斥独占锁防止击穿
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
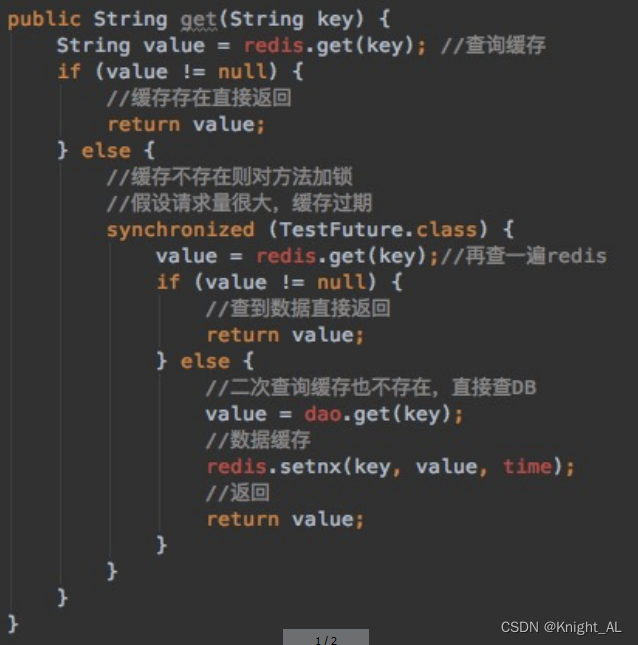
方案3:定时轮询,互斥更新,差异失效时间
举一个案例例子
QPS上1000后导致可怕的缓存击穿
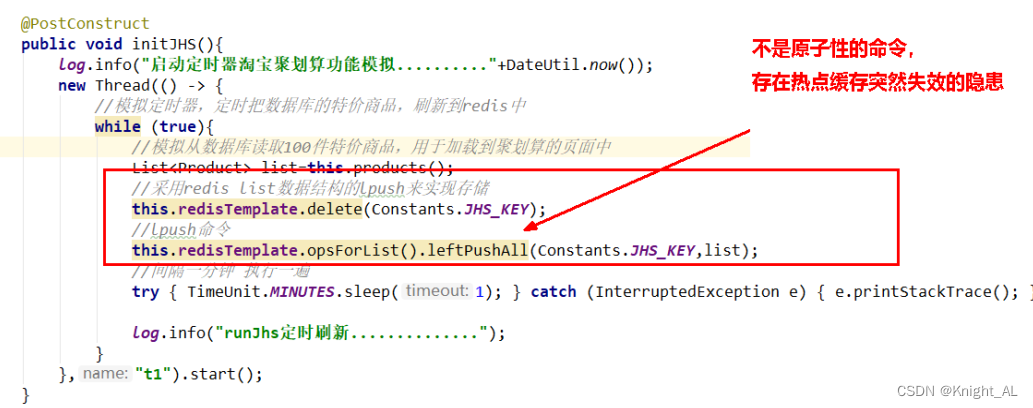
解决方法
定时轮询,互斥更新,差异失效时间

相当于B穿了一件防弹衣
我们先缓存B,然后在缓存A,设置B的过期时间要比A的长

我们先查询A,如果A为空,我们再查询B

缓存雪崩
Redis缓存雪崩是指在某个时间段内,缓存中的大量数据同时失效或者被清空,导致大量请求直接打到数据库上,从而导致数据库瞬时压力过大,甚至宕机的情况。
雪崩的处理办法
- 设置缓存过期时间时,可以采用随机时间,避免缓存同时失效。
- 使用Redis集群,将缓存数据分散到多个节点上,避免单点故障。
- 在缓存层增加限流措施,避免瞬时大量请求打到数据库上。
- 在应用层增加熔断机制,当缓存失效或者异常时,可以快速切换到备用方案,避免对数据库造成过大压力。
- 定期对缓存进行预热,避免缓存失效后,大量请求同时打到数据库上。(就是系统上线后,将相关的缓存数据直接加载到缓存系统。 这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!)
缓存穿透
1.是什么
请求去查询一条记录,先redis后mysql发现都查询不到该条记录,
但是请求每次都会打到数据库上面去,导致后台数据库压力暴增,这种现象我们称为缓存穿透,这个redis变成了一个摆设。。。。。。
简单说就是本来无一物,既不在Redis缓存中,也不在数据库中
2.解决方案
1.空对象缓存或者缺省值
一般OK

but
黑客或者恶意攻击
黑客会对你的系统进行攻击,拿一个不存在的id 去查询数据,会产生大量的请求到数据库去查询。
可能会导致你的数据库由于压力过大而宕掉
-
id相同打你系统
第一次打到mysql,空对象缓存后第二次就返回null了,
避免mysql被攻击,不用再到数据库中去走一圈了 -
id不同打你系统
由于存在空对象缓存和缓存回写(看自己业务不限死),
redis中的无关紧要的key也会越写越多(记得设置redis过期时间)
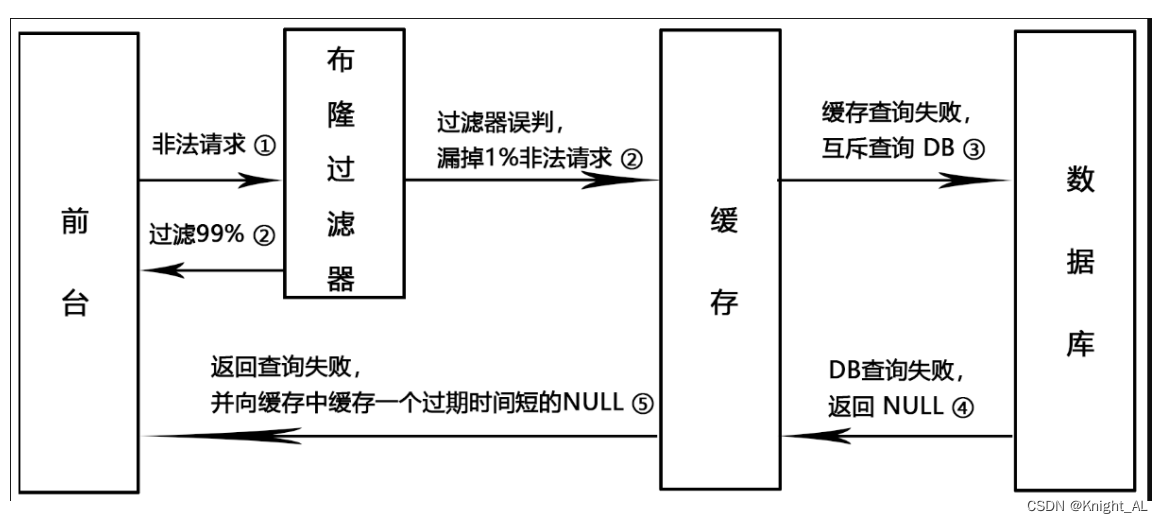
2.布隆过滤器
如果不熟悉可以看这篇
布隆过滤器BloomFilter
布隆过滤器优缺点
- 优点
高效地插入和查询,占用空间少 - 缺点
不能删除元素。因为删掉元素会导致误判率增加,因为hash冲突同一个位置可能存的东西是多个共有的,你删除一个元素的同时可能也把其它的删除了。
存在误判,不同的数据可能出来相同的hash值
结论:
有,是可能有
无,是肯定无
12.线程的多种实现方式?
- Thread
- Runnable
- Callable
- 线程池
13.线程池的基本概念
为什么要用线程池
例子:
10年前单核CPU电脑,假的多线程,像马戏团小丑玩多个球,CPU需要来回切换。
现在是多核电脑,多个线程各自跑在独立的CPU上,不用切换效率高。
线程池的优势:
线程池做的工作只要是控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
它的主要特点为: 线程复用;控制最大并发数;管理线程。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的销耗。
第二:提高响应速度。当任务到达时,任务可以不需要等待线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会销耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
14.有哪几种常见的线程池
Executors.newFixedThreadPool(10); 初始化线程池的大小.
Executors.newSingleThreadExecutor(); 一池,一线程!
Executors.newCachedThreadPool(); 执行异步短期任务,可扩容.
15.线程池的参数
1、corePoolSize:线程池中的常驻核心线程数
2、maximumPoolSize:线程池中能够容纳同时执行的最大线程数,此值必须大于等于1
3、keepAliveTime:多余的空闲线程的存活时间,当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁直到只剩下corePoolSize个线程为止
4、unit:keepAliveTime的单位
5、workQueue:任务队列,被提交但尚未被执行的任务
6、threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认的即可
7、handler:拒绝策略,表示当队列满了,并且工作线程大于等于线程池的最大线程数(maximumPoolSize)时如何来拒绝请求执行的runnable的策略
线程池的底层工作原理(扩展)
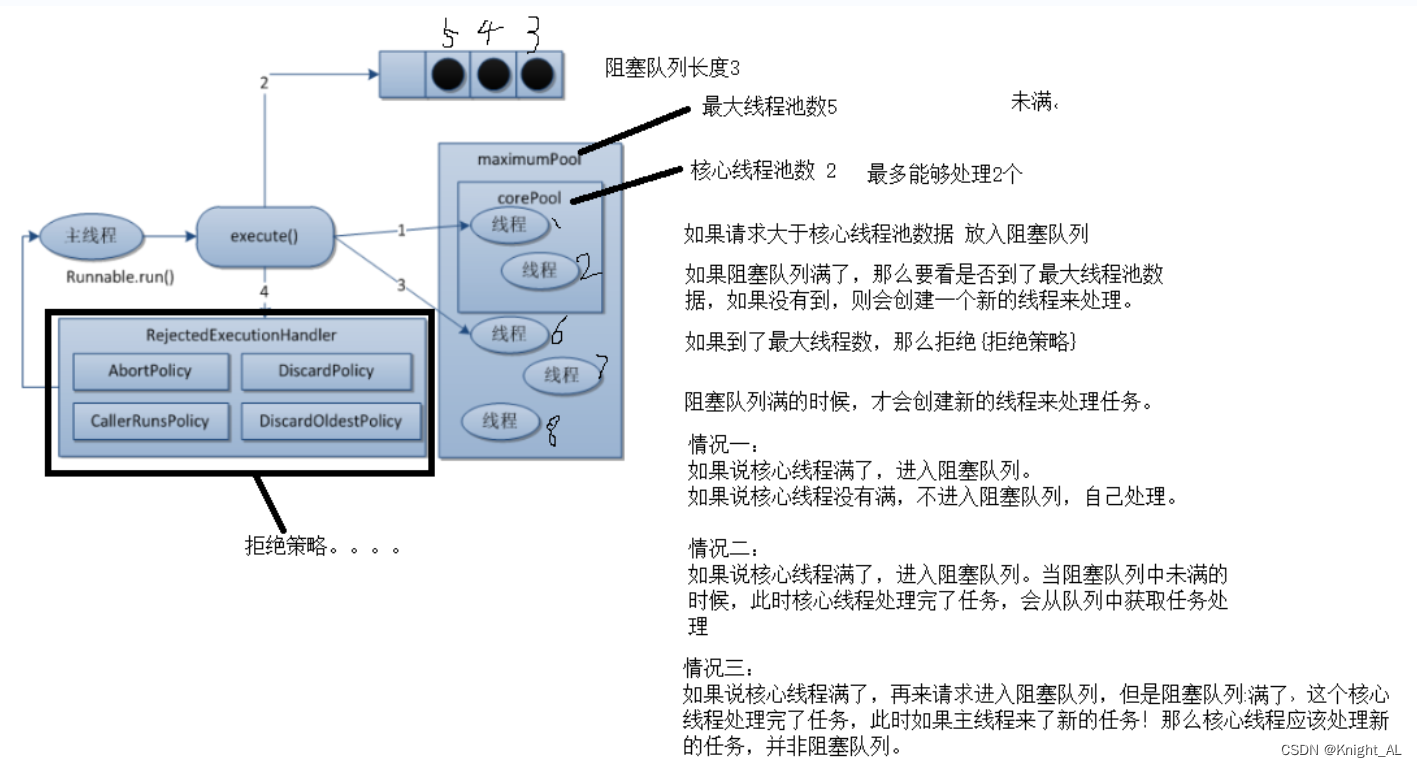
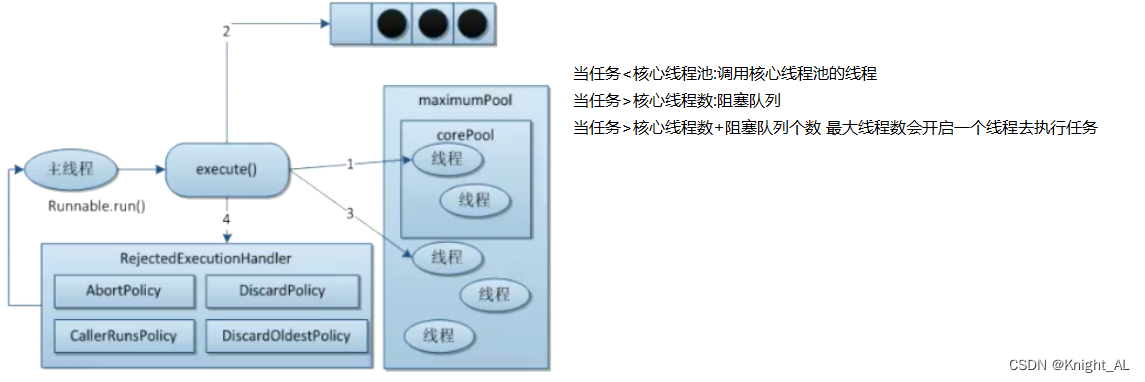
1.在创建了线程池后,等待提交过来的任务请求
2.当调用execute()方法添加一个请求任务时,线程池会做出如下判断
- 如果正在运行的线程池数量小于corePoolSize,那么马上创建线程运行这个任务
- 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列
- 如果这时候队列满了,并且正在运行的线程数量还小于maximumPoolSize,那么还是创建非核心线程立刻运行这个任务;
- 如果队列满了并且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行
3.当一个线程完成任务时,它会从队列中取下一个任务来执行
4.当一个线程无事可做操作一定的时间(keepAliveTime)时,线程池会判断:
- 如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉
- 所以线程池的所有任务完成后,它会最终收缩到corePoolSize的大小
16.线程池提交execute和submit有什么区别
- execute方法是ExecutorService接口的方法,用于提交一个Runnable对象作为一个单独的任务,并立即执行该任务。execute方法是无返回值的,即它不会返回任何结果。
- submit方法也是ExecutorService接口的方法,用于提交一个Callable或Runnable对象作为一个单独的任务,并返回一个Future对象,该对象可以用于检查任务的状态和获取结果。与execute方法不同的是,submit方法是有返回值的,即它会返回一个Future对象,该对象可以用于获取任务的执行结果。
17.线程池异常怎么处理知道吗?
1.AbortPolicy(默认):直接抛出RejectedExecutionException异常阻止系统正常运行
2.CallerRunsPolicy:“调用者运行”一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。
3.DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加人队列中尝试再次提交当前任务。
4.DiscardPolicy:该策略默默地丢弃无法处理的任务,不予任何处理也不抛出异常。如果允许任务丢失,这是最好的一种策略。
18.SQL:找出库存量最大的类别的库存信息,不用MAX还能用什么
除了使用MAX函数,还可以使用ORDER BY和LIMIT子句来找出库存量最大的类别的库存信息。
以下是一个示例语句:
SELECT category, inventory_count
FROM inventory
ORDER BY inventory_count DESC
LIMIT 1;
在上面的例SQL语句中我们使用ORDER BY子句将库存量按降序排列,然后使用LIMIT子句限制结果集只返回第一条记录,从而找出库存量最大的类别的库存信息。
19.Leetcode70 爬楼梯
入门级的动态规划问题
class Solution {
public int climbStairs(int n){
if(n <= 2){
return n;
}
int[] dp = new int[n+1];
dp[1] = 1;
dp[2] = 2;
for(int i = 3;i<dp.length;i++){
dp[i] = dp[i-1] + dp[i-2];
}
return dp[n];
}
}